Creare un'esecuzione di training usando l'API di ottimizzazione del modello Foundation
Importante
Questa funzionalità è disponibile in anteprima pubblica nelle aree seguenti: centralus, eastus, eastus2, northcentralus, e westus.
Questo articolo descrive come creare e configurare un'esecuzione di training utilizzando l'API Foundation Model Fine-tuning (ora parte dell'API Mosaic AI Model Training) e descrive tutte le parameters utilizzate nella chiamata API. È anche possibile creare un'esecuzione usando l'interfaccia utente. Per istruzioni, vedere Creare un'esecuzione di training usando l'interfaccia utente di ottimizzazione del modello foundation.
Fabbisogno
Vedere Requisiti.
Creare un set di training
Per creare esecuzioni di training a livello di codice, usare la create() funzione. Questa funzione esegue il training di un modello nel set di dati fornito e converte il checkpoint Composer finale in un checkpoint formattato Hugging Face per l'inferenza.
Gli input necessari sono il modello di cui si vuole eseguire il training, la posizione del set di dati di training e where per registrare il modello. Sono inoltre disponibili parameters facoltative che permettono di effettuare la valutazione e modificare gli iperparametri dell'esecuzione del programma.
Al termine dell'esecuzione, l'esecuzione completata e il checkpoint finale vengono salvati, il modello viene clonato e tale clone viene registrato in Unity Catalog come versione del modello per l'inferenza.
Il modello dall'esecuzione completata, non la versione del modello clonata in Unity Cataloge i relativi checkpoint Composer e Hugging Face vengono salvati in MLflow. I checkpoint Composer possono essere usati per attività di ottimizzazione continua.
Per informazioni dettagliate sugli argomenti per la funzione, vedere Configurare un'esecuzione di create() training.
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Configurare una esecuzione di training
Nell'table seguente viene riepilogato il parameters per la funzione foundation_model.create().
| Parametro | Richiesto | Type | Descrizione |
|---|---|---|---|
model |
x | str | Il nome del modello da utilizzare. Vedere Modelli supportati. |
train_data_path |
x | str | La posizione dei dati di training. Può trattarsi di una posizione in Unity Catalog (<catalog>.<schema>.<table> o dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) o in un set di dati HuggingFace.Per INSTRUCTION_FINETUNE, i dati devono essere formattati con ogni riga contenente un prompt e response campo.Per CONTINUED_PRETRAIN, si tratta di una cartella di .txt file. Vedere Preparare i dati per l'ottimizzazione del modello foundation per i formati di dati accettati e Dimensioni dei dati consigliate per il training dei modelli per le raccomandazioni relative alle dimensioni dei dati. |
register_to |
x | str | Il Catalogcatalog Unity e schema (<catalog>.<schema> o <catalog>.<schema>.<custom-name>) where il modello viene registrato dopo il training per semplificare la distribuzione. Se custom-name non è definito, per impostazione predefinita viene usato il nome del progetto. |
data_prep_cluster_id |
str | ID cluster del cluster da usare per l'elaborazione dei dati Spark. Questo è necessario per le attività di formazione delle istruzioni where i dati di formazione si trovano in un Delta table. Per informazioni su come trovare l'ID cluster, vedere Get ID cluster. | |
experiment_path |
str | Il percorso verso l'esperimento MLflow where dove viene salvato l'output dell'esecuzione del training (metriche e checkpoint). L'impostazione predefinita è il nome di esecuzione all'interno dell'area di lavoro personale dell'utente (ad esempio /Users/<username>/<run_name>). |
|
task_type |
str | Il tipo di task da eseguire. Può essere CHAT_COMPLETION (impostazione predefinita), CONTINUED_PRETRAINo INSTRUCTION_FINETUNE. |
|
eval_data_path |
str | Posizione remota dei dati di valutazione (se presenti). Deve seguire lo stesso formato di train_data_path. |
|
eval_prompts |
List[str] | Un list di stringhe di richiesta per generate risposte durante la valutazione. Il valore predefinito è None (non generate prompt). I risultati vengono registrati nell'esperimento ogni volta che viene eseguito il checkpoint del modello. Le generazioni si verificano in ogni checkpoint del modello con la generazione seguente parameters: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
str | Posizione remota di un checkpoint del modello personalizzato per il training. L’impostazione predefinita è None, ovvero l'esecuzione inizia dai pesi con training preliminare originali del modello scelto. Se vengono forniti pesi personalizzati, vengono usati questi pesi anziché i pesi pre-addestrati originali del modello. Questi pesi devono essere un checkpoint Composer e devono corrispondere all'architettura dell'oggetto model specificato. Vedere Build on custom model weights (Compilazione in base ai pesi del modello personalizzati) |
|
training_duration |
str | Durata totale dell'esecuzione. L’impostazione predefinita è un periodo o 1ep. Può essere specificato in periodi (10ep) o token (1000000tok). |
|
learning_rate |
str | Frequenza di apprendimento per il training del modello. Per tutti i modelli diversi da Llama 3.1 405B Instruct, la frequenza di apprendimento predefinita è 5e-7. Per Llama 3.1 405B Instruct, la frequenza di apprendimento predefinita è 1.0e-5. L'ottimizzatore è DecoupledLionW con beta di 0,99 e 0,95 e nessun decadimento del peso. L'utilità di pianificazione della frequenza di apprendimento è LinearWithWarmupSchedule con un riscaldamento del 2% della durata totale del training e un moltiplicatore di frequenza di apprendimento finale pari a 0. |
|
context_length |
str | Lunghezza massima della sequenza di un campione di dati. Viene usato per troncare tutti i dati troppo lunghi e per creare un pacchetto di sequenze più brevi per garantire l'efficienza. L’impostazione predefinita è 8192 token o la durata massima del contesto per il modello fornito, a condizione che sia inferiore. È possibile usare questo parametro per configurare la lunghezza del contesto, ma la configurazione oltre la lunghezza massima del contesto di ogni modello non è supportata. Vedere Modelli supportati per la durata massima supportata del contesto di ogni modello. |
|
validate_inputs |
Booleano | Indica se convalidare l'accesso ai percorsi di input prima di inviare il processo di training. Il valore predefinito è True. |
Build su pesi del modello personalizzati
L'ottimizzazione del modello di base supporta l'aggiunta di pesi personalizzati usando il parametro custom_weights_path facoltativo per eseguire il training e personalizzare un modello.
Per avviare get, setcustom_weights_path al percorso del checkpoint da una precedente esecuzione di addestramento. I percorsi del checkpoint sono disponibili nella scheda Artefatti di un'esecuzione MLflow precedente. Il nome della cartella del checkpoint corrisponde al batch e all'epoca di uno snapshot specifico, ad esempio ep29-ba30/.

- Per fornire il checkpoint più recente da un'esecuzione precedente al checkpoint di Composer, set
custom_weights_path. Ad esempio:custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Per fornire un checkpoint precedente, indirizza set
custom_weights_patha un percorso di una cartella che contiene i file.distcpcorrispondenti al checkpoint desiderato, comecustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Successivamente, update il parametro model in modo che corrisponda al modello di base del checkpoint passato a custom_weights_path.
Nell'esempio seguente è un'esecuzione precedente che consente di tunes.in the following example ift-meta-llama-3-1-70b-instruct-ohugkq is a previous run that fine-tunes meta-llama/Meta-Llama-3.1-70B. Per ottimizzare il checkpoint più recente da ift-meta-llama-3-1-70b-instruct-ohugkq, set le variabili di model e custom_weights_path come indicato di seguito:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Consulta configurare un'esecuzione di training per configurare altri parameters nella tua corsa di ottimizzazione fine.
ID cluster Get
Riprendere l'ID cluster:
Nella barra di spostamento sinistra dell'area di lavoro di Databricks cliccare su Calcolo.
Nella table, clicca sul nome del tuo cluster.
Fare clic sul pulsante
 nell'angolo superiore destro e selezionare Visualizza JSON select dal menu a discesa.
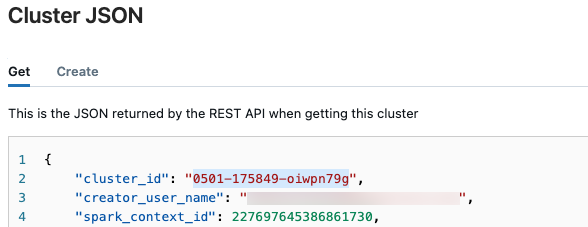
nell'angolo superiore destro e selezionare Visualizza JSON select dal menu a discesa.Viene visualizzato il file JSON del Cluster. Copiare l'ID cluster, ovvero la prima riga del file.
Get stato di una corsa
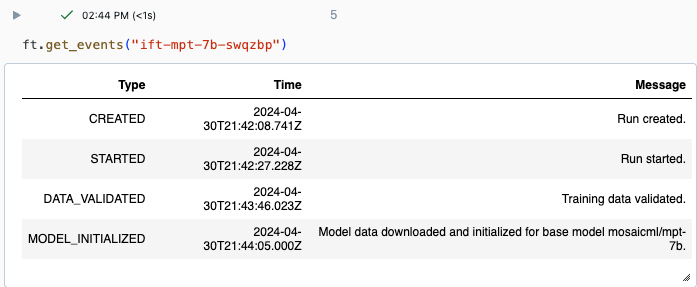
È possibile tenere traccia dello stato di avanzamento di un'esecuzione usando la pagina Esperimento nell'interfaccia utente di Databricks o usando il comando get_events()API . Per informazioni dettagliate, vedere Visualizzare, gestire e analizzare le esecuzioni di ottimizzazione del modello di base.
Output di esempio da get_events():
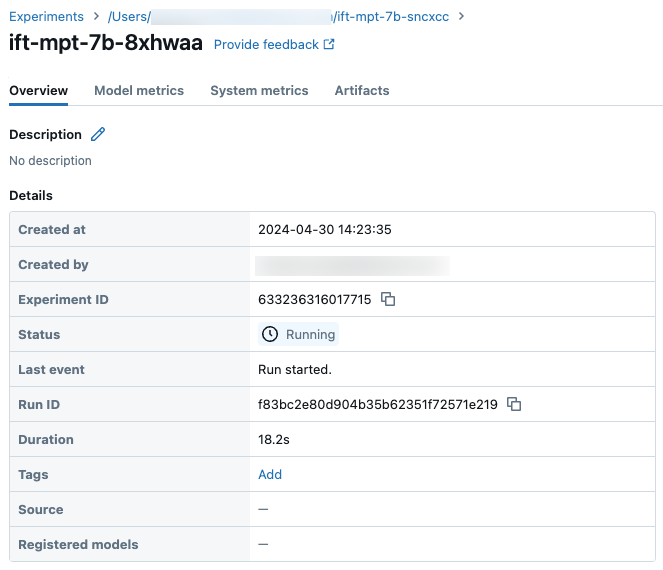
Campione dei dettagli dell'esecuzione nella pagina Esperimento:
Passaggi successivi
Dopo il completamento dell'esecuzione del training, è possibile esaminare le metriche in MLflow e distribuire il modello per l'inferenza. Vedere i passaggi da 5 a 7 dell'esercitazione : Creare e distribuire un'esecuzione di ottimizzazione del modello di base.
Per un esempio di ottimizzazione dettagliata dei dati, vedere il notebook demo di ottimizzazione delle istruzioni: Riconoscimento entità denominata per un esempio di ottimizzazione dei dati che illustra la preparazione dei dati, la configurazione di esecuzione e la distribuzione dell'esecuzione del training.
Esempio di notebook
Il notebook seguente illustra un esempio di come generate dati sintetici usando il modello Meta Llama 3.1 405B Instruct e usarli per ottimizzare un modello:
Generate dati sintetici usando il notebook Llama 3.1 405B Instruct
Risorse aggiuntive
- Ottimizzazione del modello di base
- Esercitazione: Creare e distribuire un'esecuzione di ottimizzazione del modello Foundation
- Creare un'esecuzione di training usando l'interfaccia utente di ottimizzazione del modello foundation
- Visualizzare, gestire e analizzare le esecuzioni di ottimizzazione del modello foundation
- Preparare i dati per l'ottimizzazione del modello foundation