Introduzione: Importare e visualizzare i dati CSV da un notebook
Questo articolo illustra come utilizzare un notebook di Azure Databricks per importare dati da un file CSV contenente i dati dei nomi dei bambini da health.data.ny.gov nel tuo volume del catalogo Unity utilizzando Python, Scala e R. Imparerai anche a modificare un nome di colonna, visualizzare i dati e salvarli in una tabella.
Requisiti
Per completare queste attività, è necessario soddisfare i requisiti seguenti:
- L'area di lavoro deve avere il Catalogo Unity abilitato. Per informazioni su come iniziare a usare Unity Catalog, vedere Configurare e gestire Il catalogo Unity.
- È necessario avere il privilegio
WRITE VOLUMEper un volume, il privilegioUSE SCHEMAper lo schema padre e il privilegioUSE CATALOGper il catalogo padre. - È necessario disporre dell'autorizzazione per usare una risorsa di calcolo esistente o creare una nuova risorsa di calcolo. Consulta Introduzione ad Azure Databricks o contatta il tuo amministratore di Databricks.
Suggerimento
Per un notebook completo relativo a questo articolo, consultare Importare e visualizzare i notebook di dati.
Passaggio 1: Creare un nuovo notebook
Per creare un Notebook nell'area di lavoro, fare clic su ![]() Nuovo nella barra laterale e quindi su Notebook. Viene aperto un Notebook vuoto nell'area di lavoro.
Nuovo nella barra laterale e quindi su Notebook. Viene aperto un Notebook vuoto nell'area di lavoro.
Per altre informazioni sulla creazione e la gestione dei Notebook, vedere Gestire i Notebook.
Passaggio 2: definire le variabili
In questo passaggio si definiscono le variabili da usare nel Notebook di esempio creato in questo articolo.
Copiare e incollare il codice seguente nella nuova cella vuota del Notebook. Sostituire
<catalog-name>,<schema-name>e<volume-name>con i nomi di catalogo, schema e volume per un volume di Unity Catalog. Facoltativamente, sostituire il valoretable_namecon un nome di tabella di propria scelta. I dati relativi al nome del bambino verranno salvati in questa tabella più avanti in questo articolo.Premere
Shift+Enterper eseguire la cella e creare una nuova cella vuota.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Step 3: importare il file CSV
In questo passaggio importa un file CSV contenente dati sui nomi di bambini da health.data.ny.gov nel volume di Unity Catalog.
Copiare e incollare il codice seguente nella nuova cella vuota del Notebook. Questo codice copia il file
rows.csvda health.data.ny.gov nel tuo volume di Unity Catalog usando il comando Databricks dbutils.Premere
Shift+Enterper eseguire la cella e poi passare alla cella successiva.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Step 4: Caricare dati CSV in un DataFrame
In questo passaggio si crea un dataframe denominato df dal file CSV caricato in precedenza nel volume del catalogo Unity usando il metodo spark.read.csv.
Copiare e incollare il codice seguente nella nuova cella vuota del Notebook. Questo codice carica i dati dei nomi de bambini nel DataFrame
dfdal file CSV.Premere
Shift+Enterper eseguire la cella e poi passare alla cella successiva.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
È possibile caricare i dati da molti formati di file supportati.
Step 5: Visualizzare i dati dal notebook
In questo passaggio si usa il metodo display() per mostrare il contenuto del DataFrame in una tabella nel notebook e quindi visualizzare i dati in un grafico a nuvola di parole nel notebook.
Copia e incolla il codice seguente nella nuova cella vuota del notebook, poi clicca Esegui cella per visualizzare i dati in una tabella.
Python
display(df)Scala
display(df)R
display(df)Esaminare i risultati nella tabella.
Accanto alla tab Tabella
, fare clic su e quindi su Visualizzazione .Nell'editor di visualizzazione fare clic su Tipo di visualizzazione e verificare che sia selezionata la nuvola di parole.
Nella colonna parole verificare che sia selezionato
First Name.In Limite frequenze, clicca su
35.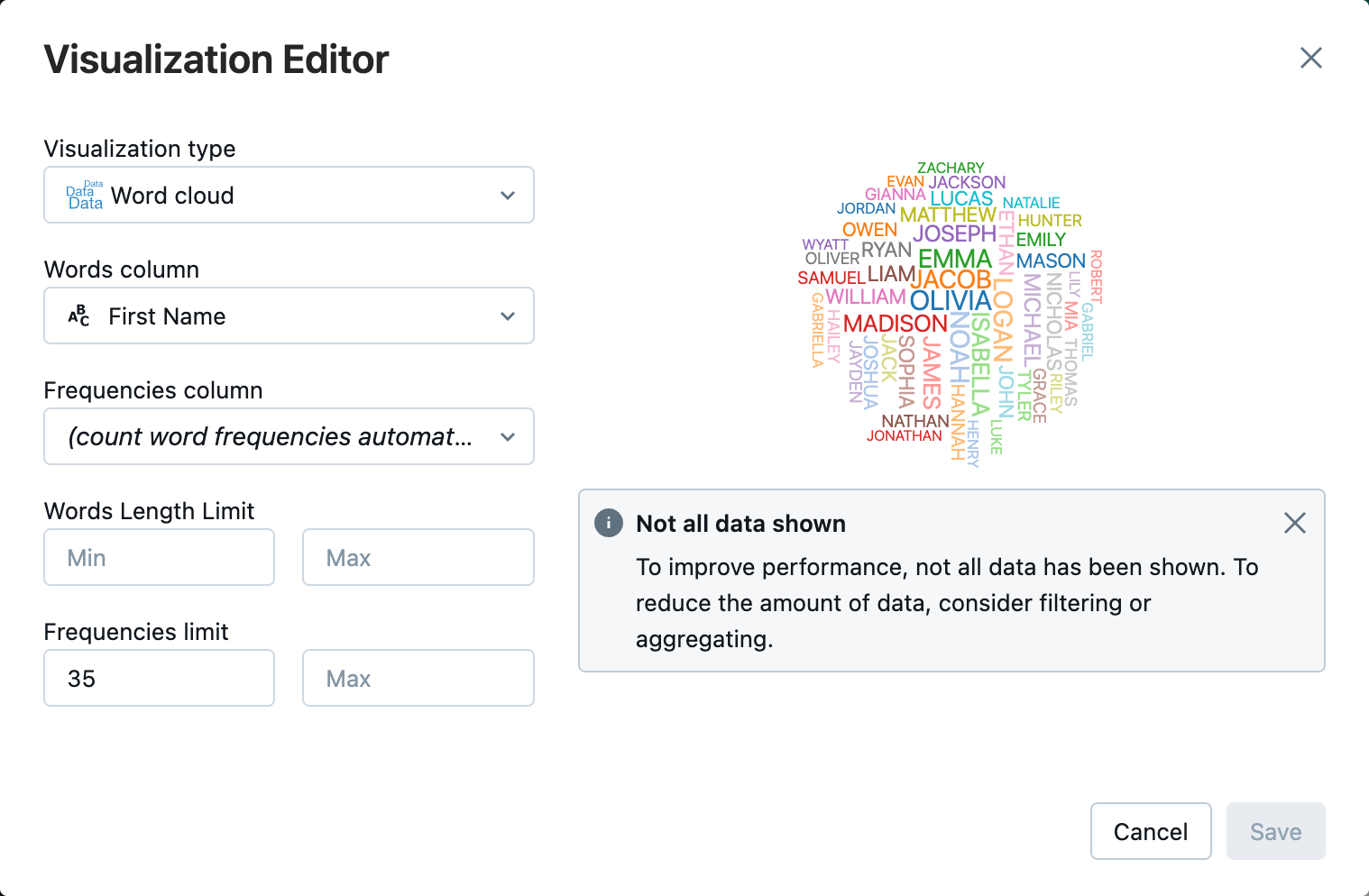
Fare clic su Salva.
Passaggio 6: Salvare il dataframe in una tabella
Importante
Per salvare il DataFrame in Unity Catalog, è necessario disporre di privilegi di tabella CREATE per il catalogo e lo schema. Per informazioni sulle autorizzazioni in Unity Catalog, vedere Privilegi e oggetti proteggibili in Unity Catalog e Gestione dei privilegi in Unity Catalog.
Copiare il codice seguente e incollarlo in una cella vuota del notebook. Questo codice sostituisce uno spazio nel nome della colonna. caratteri speciali, ad esempio gli spazi non sono consentiti nei nomi di colonna. Questo codice usa il metodo Apache Spark
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Copiare il codice seguente e incollarlo in una cella vuota del notebook. Questo codice salva il contenuto del dataframe in una tabella nel catalogo Unity usando la variabile nome tabella definita all'inizio di questo articolo.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Per verificare che la tabella sia stata salvata, fare clic su Catalogo nella barra laterale sinistra per aprire l'interfaccia utente di Esplora cataloghi. Aprire il catalogo e quindi lo schema per verificare che venga visualizzata la tabella.
Fare clic sulla tabella per visualizzare lo schema della tabella nella scheda panoramica .
Fare clic su dati di esempio per visualizzare 100 righe di dati dalla tabella.
Importare e visualizzare i notebook di dati
Usare uno dei Notebook seguenti per eseguire la procedura descritta in questo articolo. Sostituire <catalog-name>, <schema-name>e <volume-name> con i nomi di catalogo, schema e volume per un volume di Unity Catalog. Facoltativamente, sostituire il valore table_name con un nome di tabella di propria scelta.
Python
Importare dati da CSV usando Python
Scala
Importare dati da CSV usando Scala
R
Importare dati da CSV usando R
Passaggi successivi
- Per informazioni sull'aggiunta di dati aggiuntivi in una tabella esistente da un file CSV, vedere Introduzione: Inserire e inserire dati aggiuntivi.
- Per informazioni sulla pulizia e il miglioramento dei dati, vedere Introduzione: Migliorare e pulire i dati.
- Per informazioni sulle tecniche di analisi esplorativa dei dati (EDA), vedere Tutorial: tecniche EDA utilizzando i notebook di Databricks.