Esercitazione: Eseguire Python in un cluster e come processo usando l'estensione Databricks per Visual Studio Code
Questa esercitazione illustra come configurare l'estensione Databricks per Visual Studio Code e quindi eseguire Python in un cluster Azure Databricks e come processo di Azure Databricks nell'area di lavoro remota. Si veda Che cosa è l'estensione Databricks per Visual Studio Code?.
Requisiti
Per questa esercitazione è necessario:
- È stata installata l'estensione Databricks per Visual Studio Code. Vedere Installare l'estensione Databricks per Visual Studio Code.
- Si dispone di un cluster Azure Databricks remoto da usare. Prendere nota del nome del cluster. Per visualizzare i cluster disponibili, nella barra laterale dell'area di lavoro di Azure Databricks fare clic su Calcolo. Vedere Ambiente di calcolo.
Passaggio 1: Creare un nuovo progetto Databricks
In questo passaggio si crea un nuovo progetto Databricks e si configura la connessione con l'area di lavoro remota di Azure Databricks.
- Avviare Visual Studio Code, quindi fare clic su File > Apri cartella e aprire una cartella vuota nel computer di sviluppo locale.
- Sulla barra laterale fare clic sull'icona del logo di Databricks . Verrà aperta l'estensione Databricks.
- Nella visualizzazione Configurazione fare clic su Crea configurazione.
- Viene aperto il riquadro comandi per configurare l'area di lavoro di Databricks. Per
- Selezionare un profilo di autenticazione per il progetto. Vedere Configurare l'autorizzazione per l'estensione Databricks per Visual Studio Code.
Passaggio 2: Aggiungere informazioni sul cluster all'estensione Databricks e avviare il cluster
Con la visualizzazione Configurazione già aperta, fare clic su Seleziona un cluster o fare clic sull'icona a forma di ingranaggio (Configura cluster).
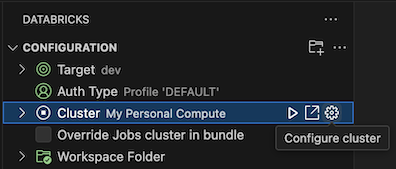
Nel riquadro comandi selezionare il nome del cluster creato in precedenza.
Fare clic sull'icona di riproduzione (Avvia cluster) se non è già stata avviata.
Passaggio 3: Creare ed eseguire codice Python
Creare un file di codice Python locale: sulla barra laterale fare clic sull'icona della cartella (Explorer).
Scegliere File > Nuovo file dal menu principale e scegliere un file Python. Assegnare al file il nome demo.py e salvarlo nella radice del progetto.
Aggiungere il codice seguente al file e quindi salvarlo. Questo codice crea e visualizza il contenuto di un dataframe PySpark di base:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Fare clic sull'icona Esegui in Databricks accanto all'elenco delle schede dell'editor e quindi fare clic su Carica ed esegui file. L'output viene visualizzato nella visualizzazione Console di debug.
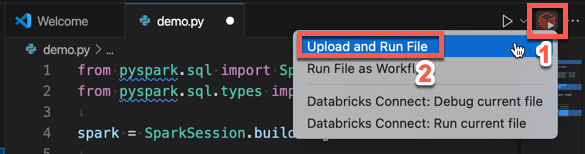
In alternativa, nella visualizzazione Explorer fare clic con il pulsante destro del mouse sul
demo.pyfile e quindi scegliere Esegui in Databricks>Carica ed esegui file.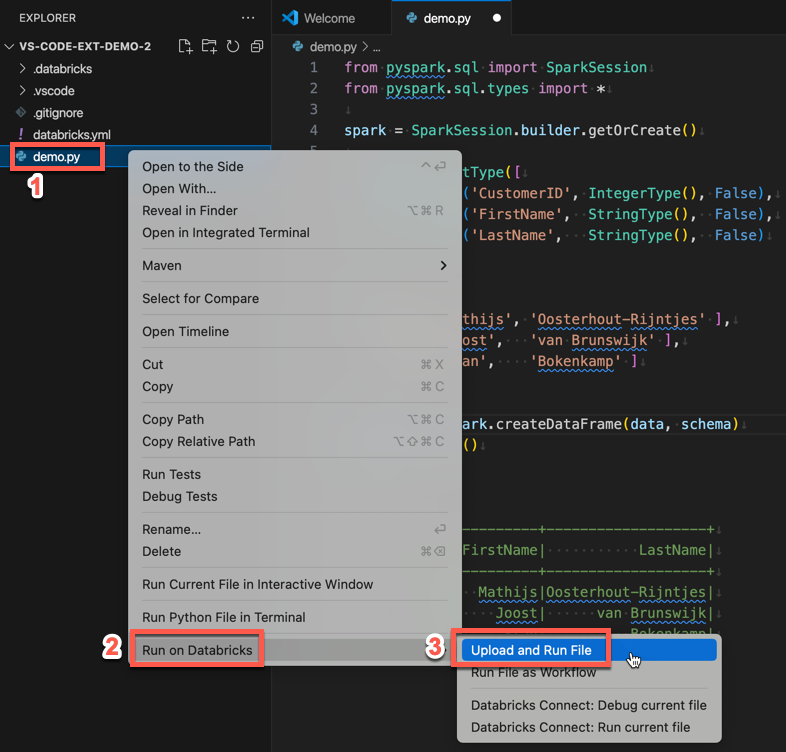
Passaggio 4: Eseguire il codice come processo
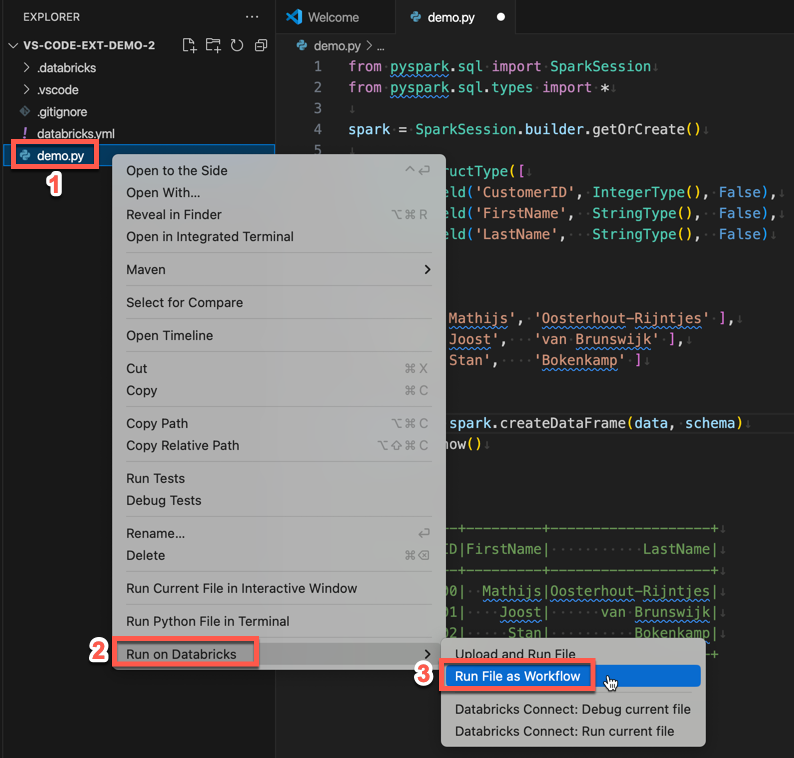
Per eseguire demo.py come processo, fare clic sull'icona Esegui in Databricks accanto all'elenco delle schede dell'editor e quindi fare clic su Esegui file come flusso di lavoro. L'output viene visualizzato in una scheda editor separata accanto all'editor di demo.py file.
![]()
In alternativa, fare clic con il pulsante destro del mouse sul demo.py file nel pannello Esplora risorse, quindi scegliere
Passaggi successivi
Ora che è stata usata correttamente l'estensione Databricks per Visual Studio Code per caricare un file Python locale ed eseguirlo in remoto, è anche possibile:
- Esplorare le risorse e le variabili dei bundle di asset di Databricks usando l'interfaccia utente dell'estensione. Vedere Funzionalità di estensione bundle di asset di Databricks.
- Eseguire o eseguire il debug di codice Python con Databricks Connect. Si veda Eseguire il debug del codice con Databricks Connect per l'estensione Databricks per Visual Studio Code.
- Eseguire un file o un notebook come processo di Azure Databricks. Vedere Eseguire un file in un cluster o in un file o un notebook come processo in Azure Databricks usando l'estensione Databricks per Visual Studio Code.
- Eseguire test con
pytest. Si veda Eseguire test con pytest usando l'estensione Databricks per Visual Studio Code.