Connettersi a Google Cloud Storage
Questo articolo descrive come configurare una connessione da Azure Databricks per leggere e scrivere tabelle e dati archiviati in Google Cloud Storage (GCS).
Per leggere o scrivere da un bucket GCS, è necessario creare un account del servizio collegato e associare il bucket all'account del servizio. Connettersi al bucket direttamente con una chiave generata per l'account del servizio.
Accedere direttamente a un bucket GCS con una chiave dell'account del servizio Google Cloud
Per leggere e scrivere direttamente in un bucket, configurare una chiave definita nella configurazione di Spark.
Passaggio 1: Configurare l'account del servizio Google Cloud con Google Cloud Console
È necessario creare un account del servizio per il cluster Azure Databricks. Databricks consiglia di assegnare a questo servizio i privilegi minimi necessari per eseguire i task.
Nel pannello di navigazione a sinistra, fare clic su Admin.
Fare clic su Account del servizio.
Fare clic su + CREA ACCOUNT DEL SERVIZIO.
Immettere un nome e una descrizione per l’account del servizio.
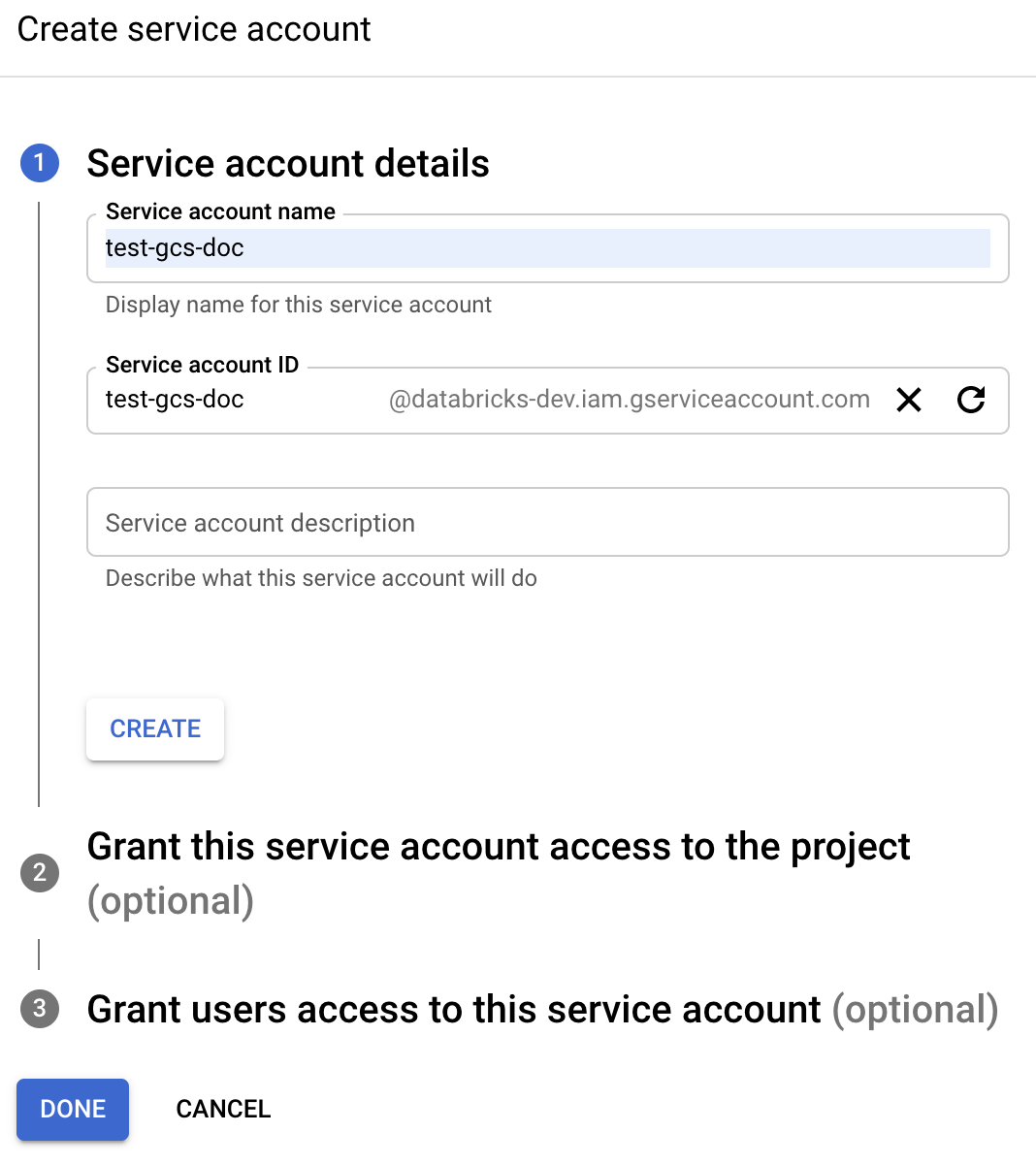
Fare clic su Crea.
Fare clic su CONTINUA.
Fare clic su FATTO.
Passaggio 2: creare una chiave per accedere direttamente al bucket GCS
Avviso
La chiave JSON generata per l'account del servizio è una chiave privata che deve essere condivisa solo con gli utenti autorizzati perché controlla l'accesso ai set di dati e alle risorse nell'account Google Cloud.
- Nell'elenco degli account del servizio della console Google Cloud fare clic sull'account appena creato.
- Nella sezione Chiavi fare clic su AGGIUNGI CHIAVE > Crea nuova chiave.
- Accettare il tipo di chiave JSON.
- Fare clic su Crea. Il file della chiave verrà scaricato nel computer.
Passaggio 3: configurare il bucket GCS
Creazione bucket
Se non si ha già un bucket, crearne uno:
Nel riquadro di spostamento a sinistra fare clic su Archiviazione.
Fare clic su CREA BUCKET.
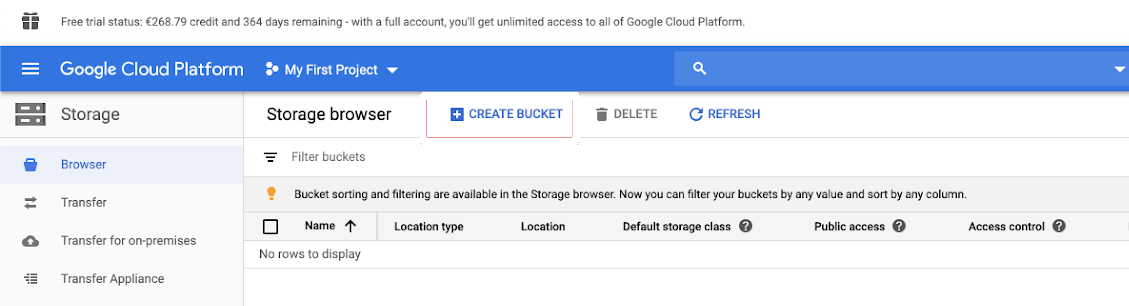
Fare clic su Crea.
Configurare il bucket
Configurare i dettagli del bucket.
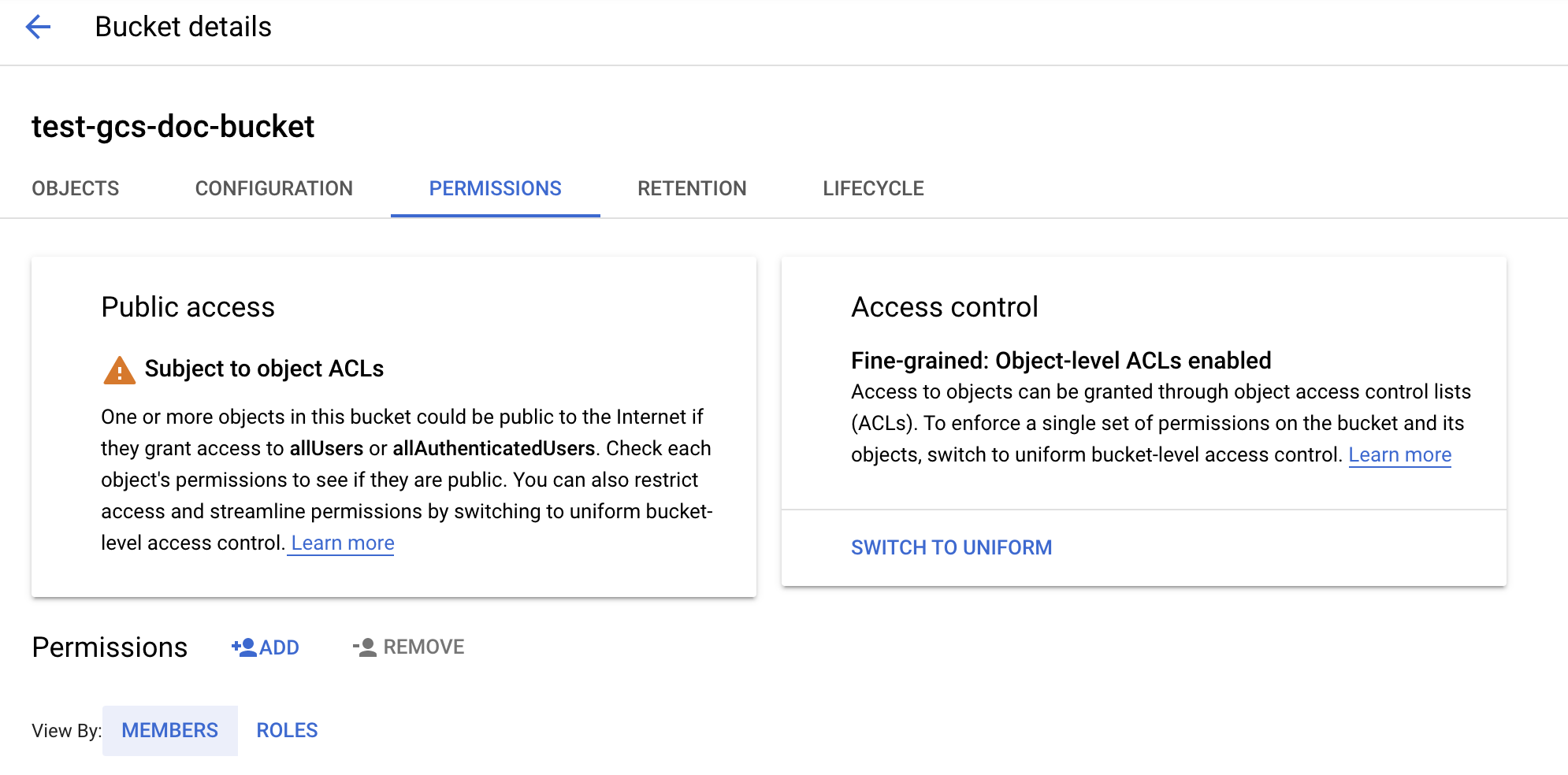
Fare clic sulla scheda Permessi.
Accanto all'etichetta Autorizzazioni fare clic su AGGIUNGI.
Fornire l'autorizzazione di amministratore dell’archiviazione all'account del servizio nel bucket dai ruoli di Archiviazione cloud.
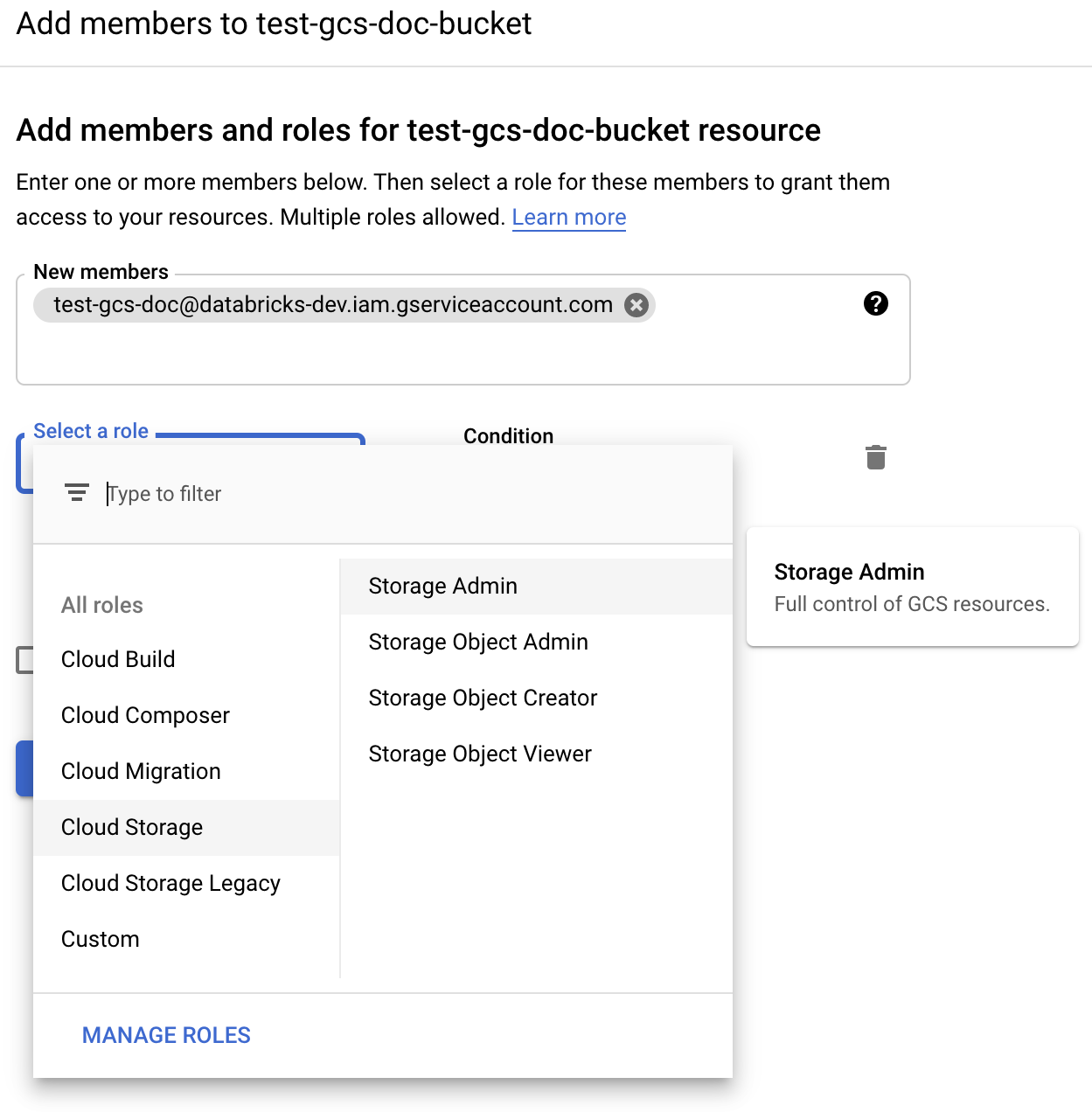
Fare clic su Salva.
Passaggio 4: inserire la chiave dell'account del servizio nei segreti di Databricks
Databricks consiglia di usare ambiti segreti per l'archiviazione di tutte le credenziali. È possibile inserire la chiave privata e l'ID chiave privata dal file JSON della chiave negli ambiti dei segreti di Databricks. È possibile concedere agli utenti, alle entità servizio e ai gruppi nell'area di lavoro l'accesso per leggere gli ambiti dei segreti. Ciò protegge la chiave dell'account del servizio consentendo agli utenti di accedere a GCS. Per creare un ambito segreto, vedere Gestire i segreti.
Passaggio 5: configurare un cluster di Azure Databricks
Nella scheda Configurazione Spark configurare una configurazione globale o una configurazione per-bucket. Gli esempi seguenti impostano le chiavi usando i valori archiviati come segreti di Databricks.
Nota
Usare il controllo di accesso del cluster e il controllo di accesso dei notebook insieme per proteggere l'accesso all'account del servizio e ai dati nel bucket GCS. Vedere Autorizzazioni di calcolo e Collaborazione con i Notebook di Databricks.
Configurazione globale
Usare questa configurazione se le credenziali specificate devono essere usate per accedere a tutti i bucket.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Sostituire <client-email>, <project-id> con i valori di questi nomi di campo esatti dal file JSON della chiave.
Configurazione per-bucket
Se è necessario configurare le credenziali per bucket specifici, usare questa configurazione. La sintassi per la configurazione per-bucket aggiunge il nome del bucket alla fine di ogni configurazione, come nell'esempio seguente.
Importante
Le configurazioni per-bucket possono essere usate in aggiunta alle configurazioni globali. Se specificato, le configurazioni per-bucket prevalgono sulle configurazioni globali.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Sostituire <client-email>, <project-id> con i valori di questi nomi di campo esatti dal file JSON della chiave.
Passaggio 6: leggere da GCS
Per leggere dal bucket GCS, usare un comando di lettura Spark in qualsiasi formato supportato, ad esempio:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Per scrivere nel bucket GCS, usare un comando di scrittura Spark in qualsiasi formato supportato, ad esempio:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Sostituire <bucket-name> con il nome del bucket creato nel passaggio 3: configurare il bucket GCS.