Google BigQuery
Questo articolo descrive come leggere e scrivere nelle tabelle di Google BigQuery in Azure Databricks.
Importante
Le configurazioni descritte in questo articolo sono sperimentali. Le caratteristiche sperimentali vengono fornite come sono e non sono supportate da Databricks tramite il supporto tecnico del cliente. Per ottenere il supporto completo della federazione delle query, è consigliabile usare invece Lakehouse Federation, che consente agli utenti di Azure Databricks di sfruttare la sintassi di Unity Catalog e gli strumenti di governance dei dati.
È necessario connettersi a BigQuery usando l'autenticazione basata su chiave.
Autorizzazioni
I progetti devono disporre di autorizzazioni Google specifiche per la lettura e la scrittura tramite BigQuery.
Nota
Questo articolo illustra le visualizzazioni materializzate di BigQuery. Per informazioni dettagliate, vedere l'articolo di Google Introduzione alle visualizzazioni materializzate. Per altre informazioni sulla terminologia di BigQuery e sul modello di sicurezza BigQuery, vedere la documentazione di Google BigQuery.
La lettura e la scrittura di dati con BigQuery dipendono da due progetti Google Cloud:
- Progetto (
project): ID del progetto Google Cloud da cui Azure Databricks legge o scrive la tabella BigQuery. - Progetto principale (
parentProject): ID del progetto principale, ovvero l'ID progetto Google Cloud da fatturare per la lettura e la scrittura. Impostare questa opzione sul progetto Google Cloud associato all'account del servizio Google per cui verranno generate le chiavi.
È necessario specificare in modo esplicito i valori project e parentProject nel codice che accede a BigQuery. Usare un codice simile al seguente:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Le autorizzazioni necessarie per i progetti Google Cloud dipendono dal fatto che project e parentProject siano uguali. Nelle sezioni seguenti sono elencate le autorizzazioni necessarie per ciascuno scenario.
Autorizzazioni necessarie se project e parentProject corrispondono
Se gli ID per project e parentProject sono uguali, usare la tabella seguente per determinare le autorizzazioni minime:
| Task Azure Databricks | Autorizzazioni Google necessarie nel progetto |
|---|---|
| Leggere una tabella BigQuery senza vista materializzata | Nel progetto project:- Utente sessione di lettura BigQuery - Visualizzatore dati BigQuery (facoltativamente concedere questo valore a livello di set di dati/tabella anziché a livello di progetto) |
| Leggere una tabella BigQuery con vista materializzata | Nel progetto project:- Utente processo BigQuery - Utente sessione di lettura BigQuery - Visualizzatore dati BigQuery (facoltativamente concedere questo valore a livello di set di dati/tabella anziché a livello di progetto) Nel progetto di materializzazione: - Editor dati BigQuery |
| Scrivere una tabella BigQuery | Nel progetto project:- Utente processo BigQuery - Editor dati BigQuery |
Autorizzazioni necessarie se project e parentProject sono diversi
Se gli ID per project e parentProject sono diversi, usare la tabella seguente per determinare le autorizzazioni minime:
| Task Azure Databricks | Autorizzazioni obbligatorie di Google |
|---|---|
| Leggere una tabella BigQuery senza vista materializzata | Nel progetto parentProject:- Utente sessione di lettura BigQuery Nel progetto project:- Visualizzatore dati BigQuery (facoltativamente concedere questo valore a livello di set di dati/tabella anziché a livello di progetto) |
| Leggere una tabella BigQuery con vista materializzata | Nel progetto parentProject:- Utente sessione di lettura BigQuery - Utente processo BigQuery Nel progetto project:- Visualizzatore dati BigQuery (facoltativamente concedere questo valore a livello di set di dati/tabella anziché a livello di progetto) Nel progetto di materializzazione: - Editor dati BigQuery |
| Scrivere una tabella BigQuery | Nel progetto parentProject:- Utente processo BigQuery Nel progetto project:- Editor dati BigQuery |
Passaggio 1: configurare Google Cloud
Abilitare l'API di archiviazione BigQuery
L'API di archiviazione BigQuery è abilitata per impostazione predefinita nei nuovi progetti Google Cloud in cui è abilitato BigQuery. Tuttavia, se si dispone di un progetto esistente e l'API di archiviazione BigQuery non è abilitata, abilitarla seguendo la procedura descritta in questa sezione.
È possibile abilitare l'API di archiviazione BigQuery usando la CLI di Google Cloud o Google Cloud Console.
Abilitare l'API di archiviazione BigQuery usando la CLI di Google Cloud
gcloud services enable bigquerystorage.googleapis.com
Abilitare l'API di archiviazione BigQuery con Google Cloud Console
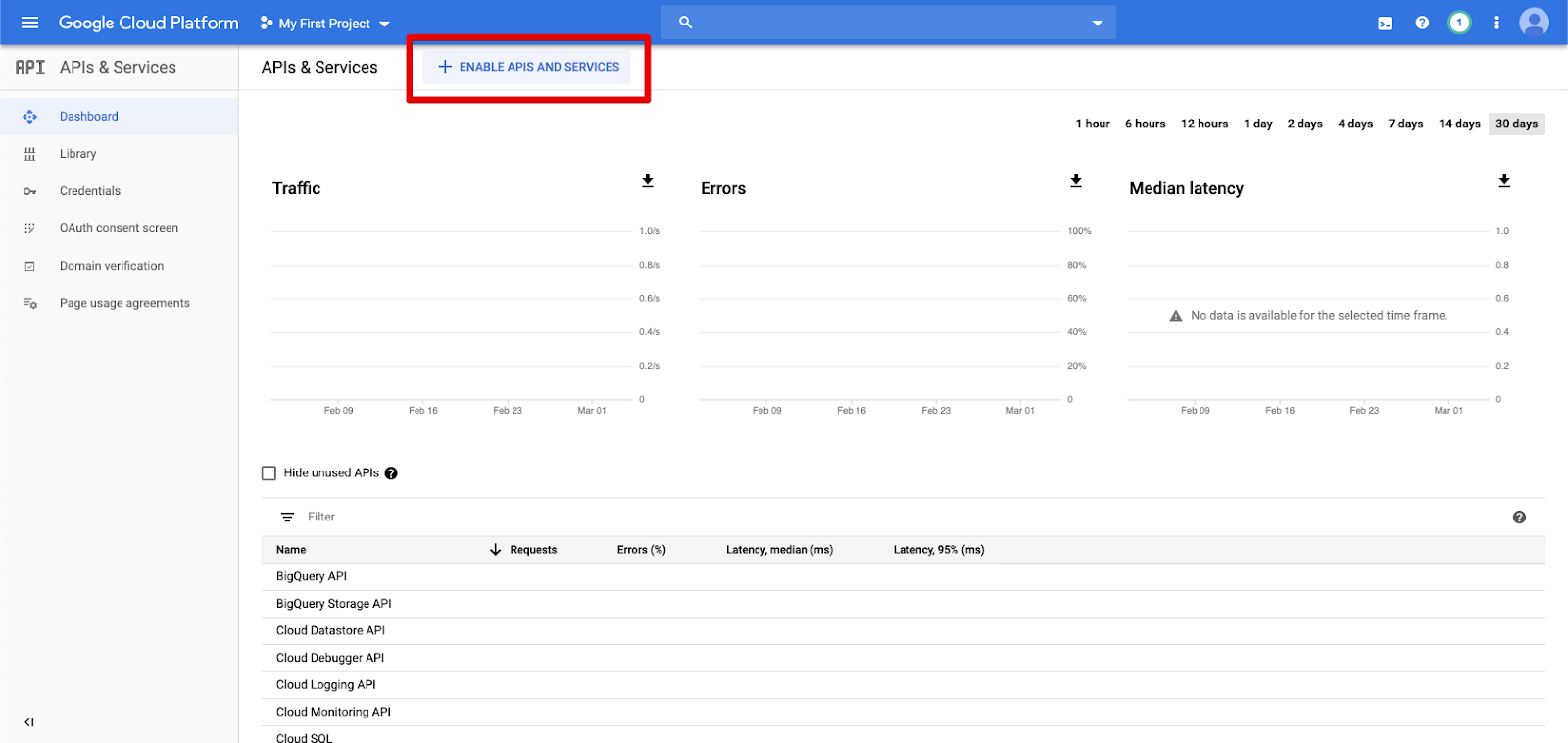
Nel riquadro di spostamento a sinistra fare clic su API e servizi.
Fare clic sul pulsante ABILITA API E SERVIZI.
Digitare
bigquery storage apinella barra di ricerca e selezionare il primo risultato.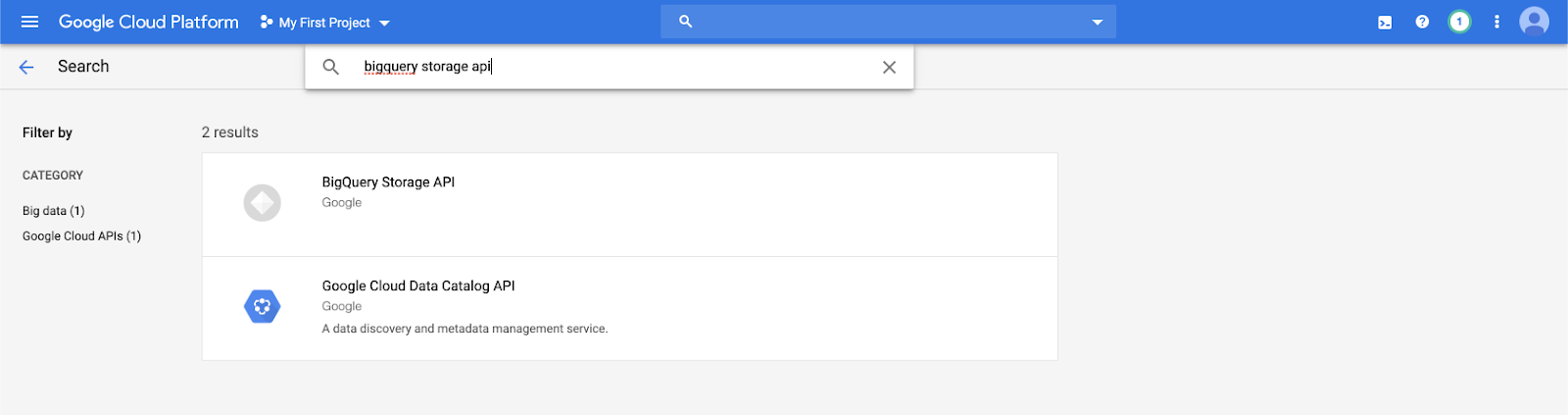
Assicurarsi che l'API di archiviazione BigQuery sia abilitata.
Creare un account del servizio Google per Azure Databricks
Creare un account del servizio per il cluster Azure Databricks. Databricks consiglia di assegnare a questo servizio i privilegi minimi necessari per eseguire i task. Consultare Ruoli e autorizzazioni BigQuery.
È possibile creare un account del servizio usando la CLI di Google Cloud o Google Cloud Console.
Creare un account del servizio Google usando la CLI di Google Cloud
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Creare le chiavi per l'account del servizio:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Creare un account del servizio Google con Google Cloud Console
Per creare l'account:
Nel pannello di navigazione a sinistra, fare clic su Admin.
Fare clic su Account del servizio.
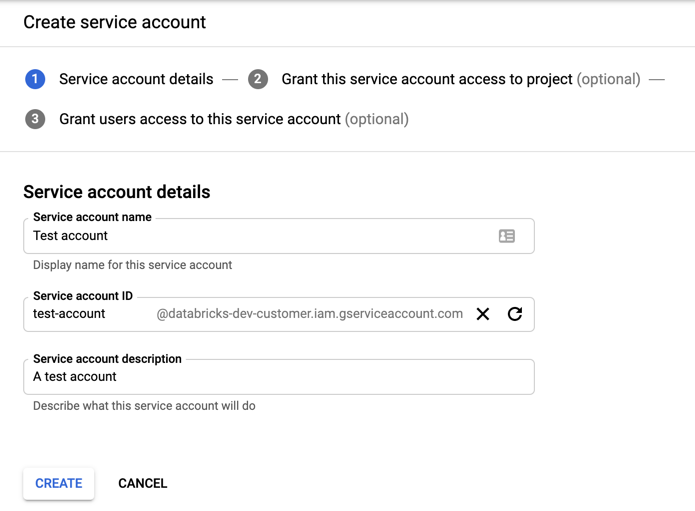
Fare clic su + CREA ACCOUNT DEL SERVIZIO.
Immettere un nome e una descrizione per l’account del servizio.
Fare clic su Crea.
Specificare i ruoli per l'account del servizio. Nell'elenco a discesa Selezionare un ruolo digitare
BigQuerye aggiungere i ruoli seguenti: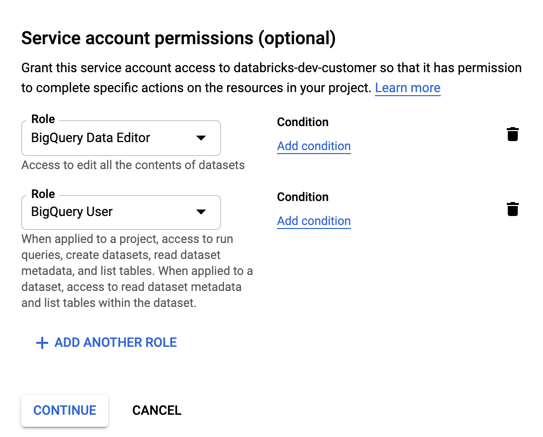
Fare clic su CONTINUA.
Fare clic su FATTO.
Per creare chiavi per l'account del servizio:
Nell'elenco degli account del servizio fare clic sull'account appena creato.
Nella sezione Chiavi selezionare AGGIUNGI CHIAVE > e Crea nuova chiave.
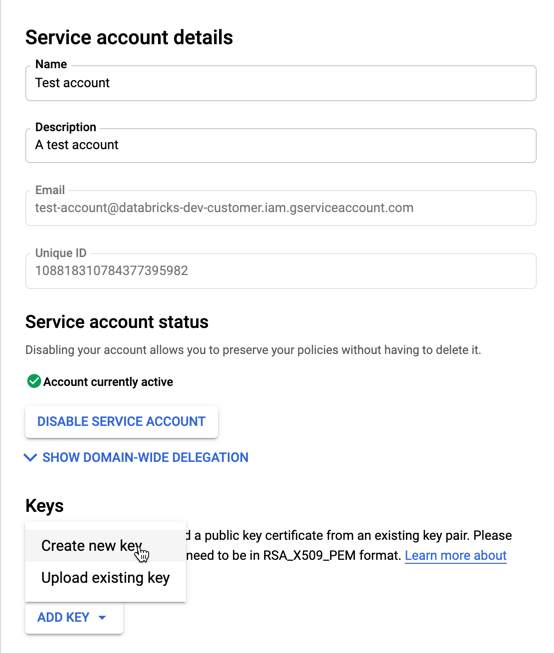
Accettare il tipo di chiave JSON.
Fare clic su Crea. Il file della chiave JSON viene scaricato sul computer.
Importante
Il file di chiave JSON generato per l'account del servizio è una chiave privata che deve essere condivisa solo con utenti autorizzati, perché controlla l'accesso ai set di dati e alle risorse nell'account Google Cloud.
Creare un bucket GCS (Google Cloud Storage) per l'archiviazione temporanea
Per scrivere dati in BigQuery, l'origine dati deve accedere a un bucket GCS.
Nel riquadro di spostamento a sinistra fare clic su Archiviazione.
Fare clic su CREA BUCKET.
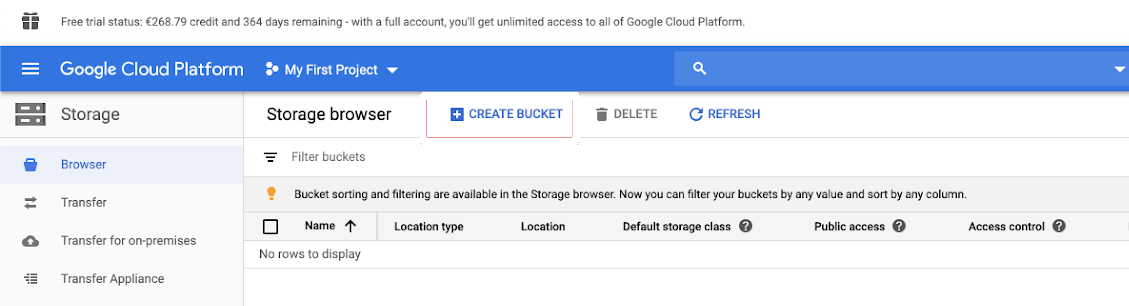
Configurare i dettagli del bucket.
Fare clic su Crea.
Fare clic sulla scheda Autorizzazioni e Aggiungi membri.
Specificare le autorizzazioni seguenti per l'account del servizio nel bucket.
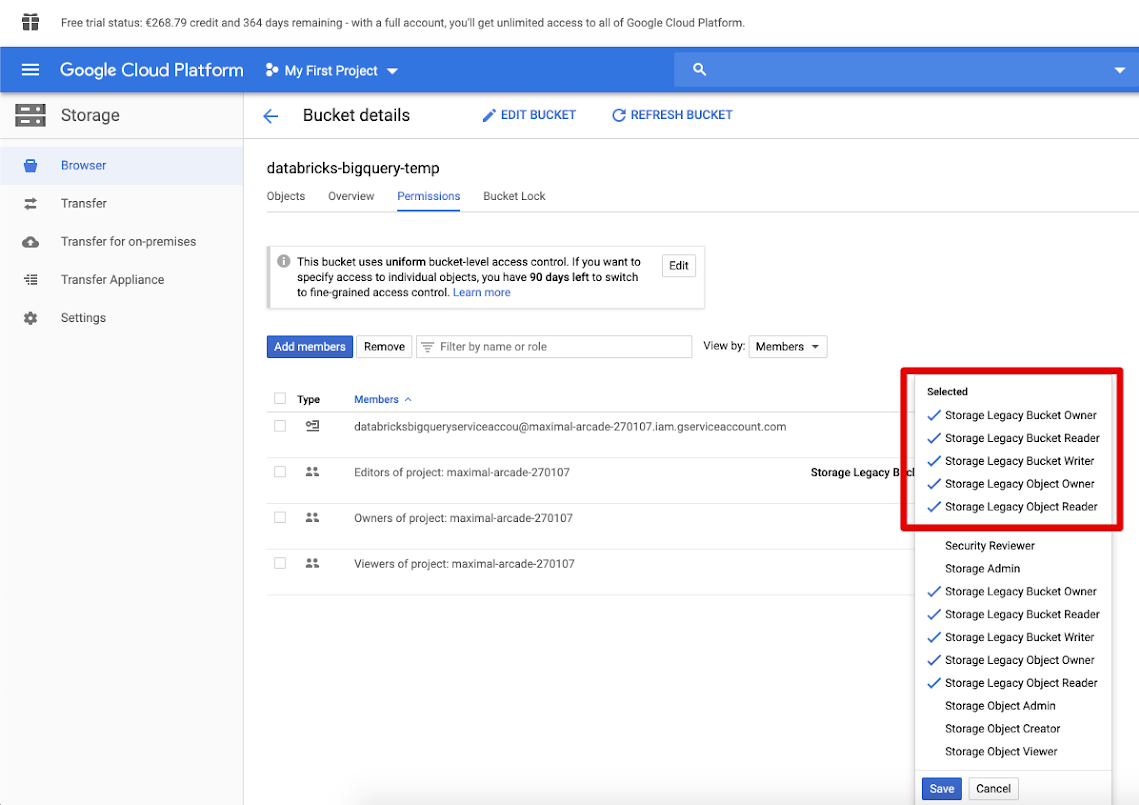
Fare clic su SALVA.
Passaggio 2: configurare Azure Databricks
Per configurare un cluster per accedere alle tabelle BigQuery, è necessario specificare il file di chiave JSON come configurazione Spark. Utilizzare uno strumento locale per codificare in Base64 il file chiave JSON. Per motivi di sicurezza non usare uno strumento basato sul Web o remoto che può accedere alle chiavi.
Quando si configura il cluster:
Nella scheda Configurazione Spark, aggiungere la configurazione spark seguente. Sostituire <base64-keys> con la stringa del file di chiave JSON con codifica Base64. Sostituire gli altri elementi tra parentesi quadre (ad esempio <client-email>) con i valori di tali campi dal file di chiave JSON.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Leggere e scrivere in una tabella BigQuery
Per leggere una tabella BigQuery, specificare
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Per scrivere in una tabella BigQuery, specificare
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
dove <bucket-name> è il nome del bucket creato in Creare un bucket GCS (Google Cloud Storage) per l'archiviazione temporanea. Per informazioni sui requisiti per i valori e <project-id>, vedere <parent-id>.
Creare una tabella esterna da BigQuery
Importante
Questa funzionalità non è supportata da Unity Catalog.
È possibile dichiarare una tabella non gestita in Databricks che leggerà i dati direttamente da BigQuery:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Esempio di Notebook Python: Caricare una tabella Google BigQuery in un DataFrame
Il Notebook Python seguente carica una tabella Google BigQuery in un DataFrame di Azure Databricks.
Notebook di esempio di Google BigQuery Python
Esempio di Notebook Scala: Caricare una tabella Google BigQuery in un DataFrame
Il Notebook Scala seguente carica una tabella Google BigQuery in un DataFrame di Azure Databricks.