Controllo di accesso con granularità fine sull'elaborazione dedicata (in precedenza elaborazione per singolo utente)
Questo articolo presenta la funzionalità di filtro dei dati che consente un controllo dell'accesso granulare sulle query eseguite su calcolo dedicato (uso generico o processi configurati con modalità di accesso dedicata). Vedere Modalità di accesso usata.
Questo filtro dei dati viene eseguito in background usando l'ambiente di calcolo serverless.
Perché alcune query sull'ambiente di calcolo dedicato richiedono il filtro dei dati?
Unity Catalog consente di controllare l'accesso ai dati tabulari a livello di colonna e di riga (noto anche come controllo di accesso con granularità fine) usando le funzionalità seguenti:
Quando gli utenti eseguono query sulle viste che escludono dati da tabelle di riferimento o tabelle di query che applicano filtri e maschere, possono usare una delle risorse di calcolo seguenti senza limitazioni:
- Magazzini SQL
- Calcolo standard (in precedenza calcolo condiviso)
Tuttavia, se si usa un calcolo dedicato per eseguire tali query, il calcolo e l'area di lavoro devono soddisfare requisiti specifici:
La risorsa di calcolo dedicata deve trovarsi in Databricks Runtime 15.4 LTS o versione successiva.
L'area di lavoro deve essere abilitata per il calcolo serverless per processi, notebook e DLT.
Per verificare che l'area di lavoro della regione supporti il calcolo serverless, vedere Funzionalità con disponibilità limitata a livello di area.
Se la risorsa di calcolo dedicata e l'area di lavoro soddisfano questi requisiti, il filtro dei dati viene eseguito automaticamente ogni volta che si eseguono query su una vista o una tabella che usa un controllo di accesso con granularità fine.
supporto per viste materializzate, tabelle di streaming e viste standard
Oltre alle visualizzazioni dinamiche, ai filtri di riga e alle maschere di colonna, il filtro dei dati abilita anche le query sulle viste e le tabelle seguenti che non sono supportate in un ambiente di calcolo dedicato che esegue Databricks Runtime 15.3 e versioni successive:
Nell'ambiente di calcolo dedicato che esegue Databricks Runtime 15.3 e versioni successive, l'utente che esegue la query nella vista deve avere SELECT sulle tabelle e sulle viste a cui fa riferimento la vista, il che significa che non è possibile usare le viste per fornire un controllo di accesso con granularità fine. Con il Databricks Runtime 15.4 e il filtraggio dei dati, l'utente che interroga la vista non ha bisogno di avere accesso alle tabelle e alle viste di riferimento.
Come funziona il filtro dei dati sul calcolo dedicato?
Ogni volta che una query accede agli oggetti di database seguenti, la risorsa di calcolo dedicata passa la query al calcolo serverless per eseguire il filtro dei dati:
- Viste costruite su tabelle sulle quali l'utente non dispone del privilegio
SELECT - Visualizzazioni dinamiche
- Tabelle con filtri di riga o maschere di colonna definite
- Viste materializzate e tabelle di streaming
Nel diagramma seguente, un utente ha SELECT su table_1, view_2 e table_w_rls, ai quali sono applicati filtri di riga. L'utente non dispone di SELECT su table_2, a cui view_2 fa riferimento.

La query su table_1 viene gestita interamente dalla risorsa di calcolo dedicata, perché non è necessario alcun filtro. Le query su view_2 e table_w_rls richiedono il filtro dei dati per restituire i dati a cui l'utente ha accesso. Queste query vengono gestite dalla funzionalità di filtro dei dati nell'ambiente di calcolo serverless.
Quali costi sono sostenuti?
I clienti vengono addebitati i costi per le risorse di calcolo serverless usate per eseguire operazioni di filtro dei dati. Per informazioni sui prezzi, vedere Livelli di piattaforma e componenti aggiuntivi.
È possibile consultare la tabella di utilizzo della fatturazione del sistema per vedere quanto è stato addebitato. Ad esempio, la query seguente suddivide i costi di calcolo per utente:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Visualizzare le prestazioni delle query quando viene attivato il filtro dei dati
L'interfaccia utente di Spark per il calcolo dedicato visualizza le metriche che è possibile usare per comprendere le prestazioni delle query. Per ogni query eseguita nella risorsa di calcolo, nella scheda SQL/Dataframe viene visualizzata la rappresentazione del grafo della query. Se una query è stata coinvolta nel filtro dei dati, l'interfaccia utente visualizza un nodo dell'operatore RemoteSparkConnectScan nella parte inferiore del grafico. Tale nodo visualizza le metriche che è possibile usare per analizzare le prestazioni delle query. Vedere Visualizzare le informazioni di calcolo nell'interfaccia utente di Apache Spark.
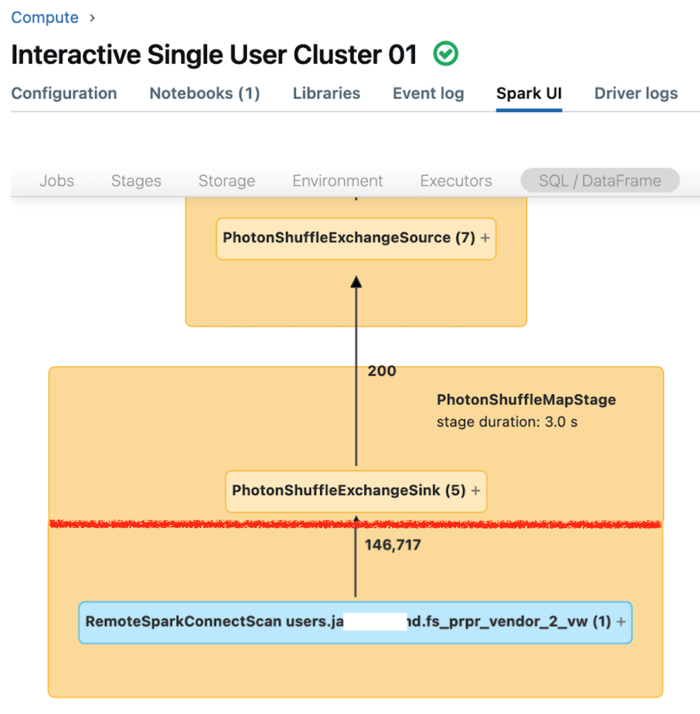
Espandere il nodo dell'operatore RemoteSparkConnectScan per visualizzare le metriche che rispondono a queste domande:
- Quanto tempo è stato necessario per il filtro dei dati? Visualizzare il "tempo totale di esecuzione remota".
- Quante righe sono rimaste dopo il filtro dei dati? Vedi "output righe".
- Quanti dati (in byte) sono stati restituiti dopo il filtro dei dati? Visualizzare le "dimensioni di output delle righe".
- Quanti file di dati sono stati esclusi dalla partizione e non hanno dovuto essere letti dalla memoria di archiviazione? Visualizzare "File eliminati" e "Dimensioni dei file eliminati".
- Quanti file di dati non potevano essere eliminati e dovevano essere letti dalla risorsa di archiviazione? Visualizzare "File letti" e "Dimensioni dei file letti".
- Dei file da leggere, quanti erano già presenti nella cache? Visualizzare "Dimensioni riscontri cache" e "Dimensioni mancate cache".
Limiti
Nessun supporto per operazioni di scrittura o aggiornamento delle tabelle nelle tabelle con filtri di riga o maschere di colonna applicati.
In particolare, le operazioni DML, ad esempio
INSERT,DELETE,UPDATEREFRESH TABLE, eMERGE, non sono supportate. È possibile leggere (SELECT) solo da queste tabelle.I self-join vengono bloccati per impostazione predefinita quando viene chiamato il filtro dei dati, ma è possibile consentirli impostando
spark.databricks.remoteFiltering.blockSelfJoinssu false nel calcolo in cui si eseguono questi comandi.Prima di abilitare i self-join in una risorsa di calcolo dedicata, tenere presente che una query self-join gestita dalla funzionalità di filtro dei dati potrebbe restituire snapshot diversi della stessa tabella remota.
- Nessun supporto nelle immagini Docker.
- Se l'area di lavoro è stata distribuita con un firewall prima di novembre 2024, è necessario aprire le porte 8443 e 8444 per abilitare il controllo di accesso con granularità fine nel calcolo dedicato. Vedere Regole del gruppo di sicurezza di rete.