Creare e usare tabelle di output in Databricks Clean Rooms
Questo articolo presenta le tabelle di output, che sono tabelle temporanee di sola lettura generate da un'esecuzione del notebook e condivise nel metastore del catalogo Unity dello strumento di esecuzione del notebook. Questo articolo descrive come usare un notebook per creare tabelle di output e come i collaboratori possono leggere queste tabelle di output nel metastore del catalogo Unity.
Panoramica delle tabelle di output
Le tabelle di output consentono di salvare temporaneamente l'output dei notebook eseguiti in una stanza pulita in un catalogo di output nel metastore di Unity Catalog, in cui è possibile rendere disponibili i dati ai membri del team che non hanno la possibilità di eseguire i notebook stessi. È anche possibile usare i processi di Azure Databricks per eseguire notebook ed eseguire attività nelle tabelle di output. In combinazione con il tipo di attività notebook Clean Room e il supporto per i valori delle attività, le tabelle di output consentono di creare flussi di lavoro complessi che dipendono dai notebook della sala pulita.
Le tabelle di output sono di sola lettura.
Solo l'entità specifica (utente, gruppo o entità servizio) che esegue il notebook ha accesso in lettura predefinito alla tabella di output. Non esiste alcun accesso in scrittura. Un amministratore del metastore può concedere l'accesso in lettura ad altre entità nell'account Azure Databricks usando i privilegi standard di Unity Catalog.
Le tabelle di output vengono archiviate per 30 giorni nella posizione di archiviazione predefinita della sala pulita centrale e condivise nel metastore del collaboratore usando la condivisione delta. Se si vuole mantenere una tabella di output per più di 30 giorni, è necessario copiarla nella risorsa di archiviazione locale.
Ogni esecuzione del notebook crea un nuovo schema nel catalogo di output. Le nuove esecuzioni non possono aggiungere una tabella di output esistente.
Importante
Le tabelle di output sono supportate solo quando la sala pulita centrale è ospitata in AWS o Azure. Tuttavia, i collaboratori in Databricks in tutti e tre i cloud, AWS, Azure e Google Cloud, possono condividere notebook che creano tabelle di output e possono leggere le tabelle di output generate quando eseguono notebook condivisi. I collaboratori di Google Cloud devono essere partecipanti all'anteprima privata di Clean Rooms.
Creare una tabella di output
Per creare una tabella di output, usare i cr_output_catalog parametri e cr_output_schema nello spazio dei nomi della tabella in tre parti. Ogni esecuzione del notebook produce un nuovo schema.
Nell'esempio seguente, la cella del notebook crea una tabella di output denominata overlapping_users nel catalogo di output del collborator che elenca gli utenti il cui indirizzo di posta elettronica viene visualizzato in entrambe le collaborator.advertiser.profiles tabelle e creator.publisher.profiles .
CREATE TABLE identifier(:cr_output_catalog || '.' || :cr_output_schema || '.overlapping_users') AS
SELECT collab_profiles.*
FROM collaborator.advertiser.profiles AS collab_profiles
JOIN creator.publisher.profiles AS creator_profiles
ON collab_profiles.email = creator_profiles.email
Leggere una tabella di output
Le tabelle di output vengono visualizzate in un catalogo condiviso nel metastore dello strumento di esecuzione del notebook. Nel riquadro Catalogo esplora cataloghi vengono visualizzati nell'elenco Cataloghi condivisi .
La lettura di una tabella di output è simile alla lettura di qualsiasi altra tabella nel catalogo unity. È necessario avere SELECT nella tabella, USE CATALOG nel catalogo di output condiviso e USE SCHEMA nello schema generato automaticamente. L'utente che ha eseguito il notebook che ha creato la tabella dispone di queste autorizzazioni per impostazione predefinita.
Prima di iniziare
Questa sezione descrive i requisiti di cloud, configurazione e calcolo per la lettura delle tabelle di output.
Requisiti del cloud
Anche se la sala pulita centrale deve essere in AWS per supportare le tabelle di output, le aree di lavoro dei collaboratori possono trovarsi in uno dei tre cloud: AWS, Azure o Google Cloud. I collaboratori di Google Cloud devono essere partecipanti all'anteprima privata di Clean Rooms.
Requisito del catalogo di output condiviso
Prima di poter leggere le tabelle di output, un utente deve creare il catalogo che li contiene. Questa operazione deve essere eseguita una sola volta per ogni camera pulita. Il proprietario della stanza pulita ha l'autorizzazione per leggere e gestire il catalogo di output per impostazione predefinita.
Autorizzazioni necessarie: EXECUTE_CLEAN_ROOM_TASK
- Nell'area di lavoro di Azure Databricks fare clic su
 Catalogo.
Catalogo. - Nella pagina Accesso rapido fare clic sul pulsante Clean Rooms .On the Quick access page, click the Clean Rooms > button.
- Selezionare l’ambiente pulito dall'elenco.
- Nel riquadro destro, in Output fare clic su Crea catalogo.
- Immettere un nome catalogo di output o accettare l'impostazione predefinita, ovvero
<clean-room-name>_output.
Il catalogo di output viene visualizzato nell'elenco dei cataloghi condivisi nel riquadro Catalogo di Esplora cataloghi . Ogni stanza pulita a cui si partecipa può avere un catalogo di output condiviso nel metastore.
Requisiti di calcolo
Le query sulle tabelle di output richiedono un calcolo serverless. Vedere Connettersi al calcolo serverless.
Autorizzazioni necessarie per leggere una tabella di output
L'utente che ha eseguito il notebook che ha creato la tabella di output e il proprietario della sala pulita hanno l'autorizzazione per leggere e gestire la tabella di output per impostazione predefinita. A tutti gli altri utenti devono essere concesse le autorizzazioni seguenti:
-
SELECTsulla tabella -
USE CATALOGnel catalogo di output -
USE SCHEMAnello schema di output
Eseguire il notebook
Per generare tabelle di output condivise nel catalogo di output, un utente con accesso alla sala pulita deve eseguire il notebook. Vedere Eseguire notebook in clean rooms. Ogni esecuzione del notebook crea un nuovo schema di output e una tabella.
Suggerimento
È possibile usare i processi di Azure Databricks per eseguire notebook ed eseguire attività nelle tabelle di output, abilitando flussi di lavoro complessi. Vedere Usare i flussi di lavoro di Azure Databricks per eseguire notebook della sala pulita.
Trovare e visualizzare una tabella di output
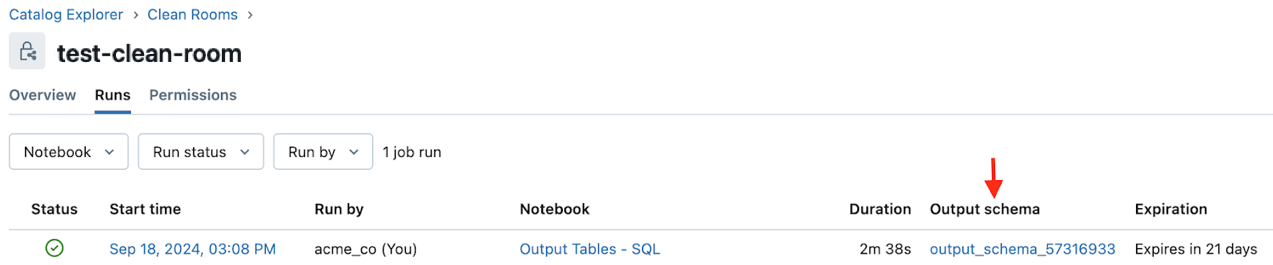
L'utente che esegue il notebook che crea la tabella di output può trovare un collegamento alla tabella di output nella cronologia di esecuzione del notebook ed eseguire le pagine dei dettagli nell'interfaccia utente di Clean Rooms . In entrambi i casi, il collegamento si trova nel campo Schema di output. Vedere Monitorare le esecuzioni dei notebook della sala pulita.
Cronologia di esecuzione:
Dettagli esecuzione:
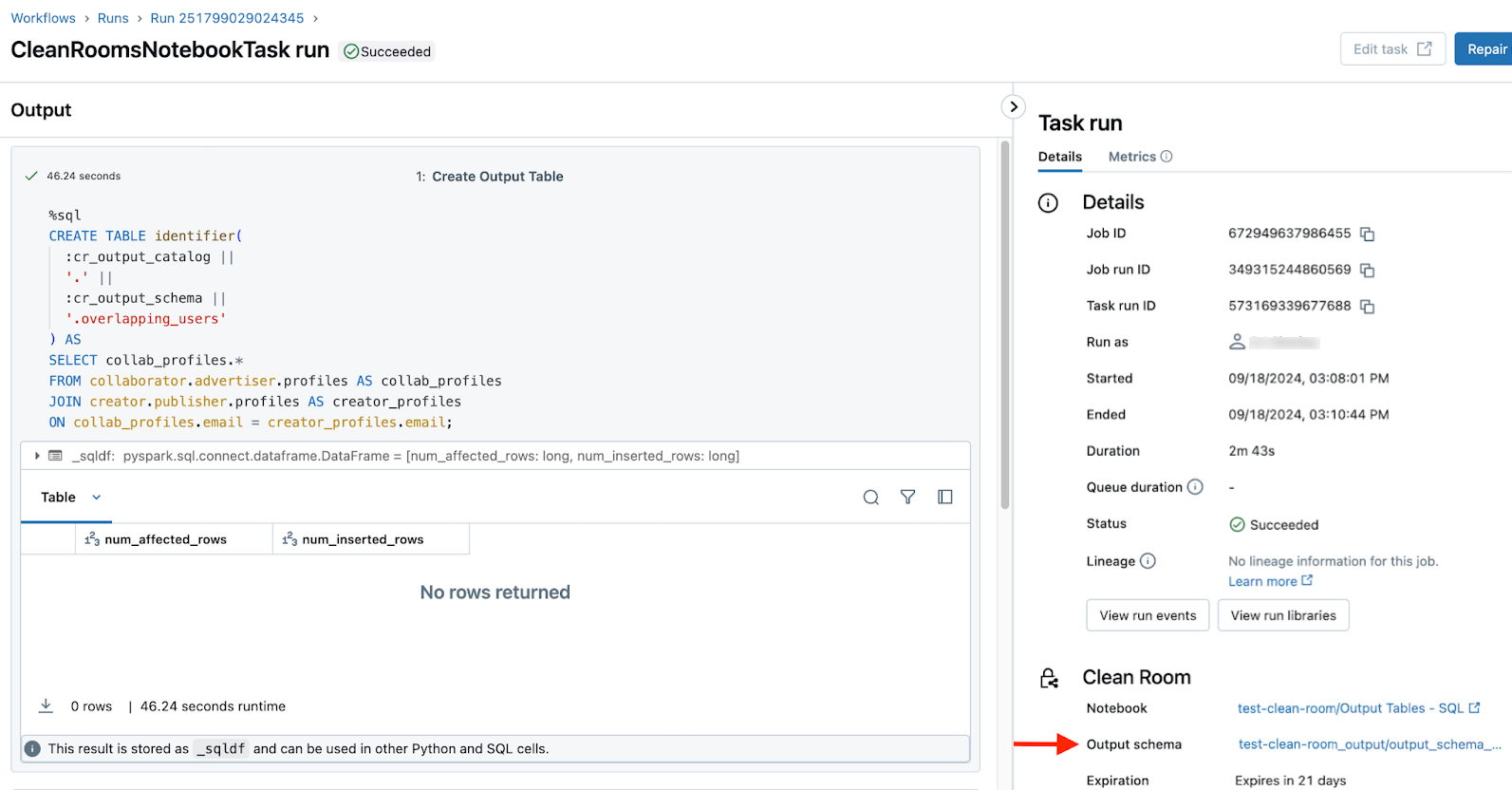
È anche possibile trovare il catalogo di output nell'elenco cataloghi condivisi nel riquadro Catalogo di Esplora cataloghi .
Limiti
Oltre ai requisiti elencati in Panoramica delle tabelle di output e Prima di iniziare, le tabelle di output presentano le limitazioni seguenti:
- Le tabelle di output sono supportate solo quando la stanza pulita centrale è ospitata in AWS o Azure e quando la stanza pulita è stata creata dopo il rilascio della funzionalità della tabella di output.
- Sono supportate solo le tabelle. I volumi e le visualizzazioni, ad esempio, non sono.
- È possibile creare fino a 100 tabelle di output per notebook.