Eseguire progetti MLflow in Azure Databricks
Nota
I progetti MLflow non sono più supportati.
Questa documentazione è stata ritirata e potrebbe non essere aggiornata. I prodotti, i servizi o le tecnologie menzionati in questo contenuto non sono più supportati.
Un MLflow Project è un formato per la creazione di pacchetti di codice di data science in modo riutilizzabile e riproducibile. Il componente MLflow Projects include un'API e strumenti da riga di comando per l'esecuzione di progetti, che si integrano anche con il componente Rilevamento per registrare automaticamente i parametri e il commit Git del codice sorgente per la riproducibilità.
Questo articolo descrive il formato di un progetto MLflow e come eseguire un progetto MLflow in remoto nei cluster Azure Databricks usando l'interfaccia della riga di comando di MLflow, che semplifica la scalabilità verticale del codice di data science.
Formato del progetto MLflow
Qualsiasi directory locale o repository Git può essere considerato come un progetto MLflow. Le convenzioni seguenti definiscono un progetto:
- Il nome del progetto è il nome della directory.
- L'ambiente software, se presente, viene specificato in
python_env.yaml. Se non è presente alcun filepython_env.yaml, MLflow usa un ambiente virtualenv contenente solo Python (in particolare, la versione più recente di Python disponibile per virtualenv) durante l'esecuzione del progetto. - Qualsiasi
.pyo.shfile nel progetto può essere un punto di ingresso, senza parametri dichiarati in modo esplicito. Quando si esegue un comando di questo tipo con un set di parametri, MLflow passa ogni parametro nella riga di comando usando la sintassi--key <value>.
È possibile specificare altre opzioni aggiungendo un file MLproject, ovvero un file di testo nella sintassi YAML. Un file MLproject di esempio è simile al seguente:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Per Databricks Runtime 13.0 ML e versioni successive, MLflow Projects non può essere eseguito correttamente all'interno di un cluster del tipo di processo Databricks. Per eseguire la migrazione di progetti MLflow esistenti in Databricks Runtime 13.0 ML e versioni successive, vedere formato di progetto processo Spark di MLflow Databricks.
formato di progetto processo Spark di MLflow Databricks
Il progetto di lavoro Spark di MLflow Databricks è un tipo di progetto MLflow introdotto in MLflow 2.14. Questo tipo di progetto supporta l'esecuzione di progetti MLflow dall'interno di un cluster Spark Jobs e può essere eseguito solo usando il backend databricks.
I progetti di attività di Databricks Spark devono impostare databricks_spark_job.python_file o entry_points. Se non si specifica alcuna impostazione o si specificano entrambe, viene generata un'eccezione.
Di seguito è riportato un esempio di file MLproject che usa l'impostazione databricks_spark_job.python_file. Questa impostazione prevede l'uso di un percorso fisso per il file di esecuzione di Python e i relativi argomenti.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
Di seguito è riportato un esempio di file MLproject che usa l'impostazione entry_points:
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
L'impostazione entry_points consente di passare parametri che usano parametri della riga di comando, ad esempio:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
Per i progetti di job Spark di Databricks si applicano le seguenti limitazioni:
- Questo tipo di progetto non supporta la specifica delle sezioni seguenti nel file di
MLproject:docker_env,python_envoconda_env. - Le dipendenze del tuo progetto devono essere specificate nel campo
python_librariesdella sezionedatabricks_spark_job. Le versioni di Python non possono essere personalizzate con questo tipo di progetto. - L'ambiente in esecuzione deve usare l'ambiente di runtime del driver Spark principale per l'esecuzione in cluster di processi che usano Databricks Runtime 13.0 o versione successiva.
- Analogamente, tutte le dipendenze Python definite come necessarie per il progetto devono essere installate come dipendenze del cluster Databricks. Questo comportamento è diverso dai comportamenti di esecuzione del progetto precedenti in cui le librerie devono essere installate in un ambiente separato.
Eseguire un progetto MLflow
Per eseguire un progetto MLflow in un cluster Azure Databricks nell'area di lavoro predefinita, usare il comando :
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
dove <uri> è un URI o una cartella del repository Git contenente un progetto MLflow e <json-new-cluster-spec> è un documento JSON contenente una struttura new_cluster. L'URI Git deve essere nel formato https://github.com/<repo>#<project-folder>.
Una specifica del cluster di esempio è:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Se è necessario installare librerie sul nodo di lavoro, usare il formato "specifiche del cluster". Si noti che i file della rotellina Python devono essere caricati in DBFS e specificati come dipendenze pypi. Per esempio:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Importante
- Le dipendenze
.egge.jarnon sono supportate per i progetti MLflow. - L'esecuzione per i progetti MLflow con ambienti Docker non è supportata.
- È necessario usare una nuova specifica del cluster quando si esegue un progetto MLflow in Databricks. L'esecuzione di progetti su cluster esistenti non è supportata.
Uso di SparkR
Per usare SparkR in un'esecuzione del progetto MLflow, il codice del progetto deve prima installare e importare SparkR come indicato di seguito:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Il progetto può quindi inizializzare una sessione SparkR e usare SparkR come di consueto:
sparkR.session()
...
Esempio di
Questo esempio illustra come creare un esperimento, eseguire il progetto tutorial MLflow in un cluster Azure Databricks, visualizzare l'output dell'esecuzione del processo e analizzare l'esecuzione nell'esperimento.
Requisiti
- Installare MLflow usando
pip install mlflow. - Installare e configurare la CLI di Databricks . Il meccanismo di autenticazione dell'interfaccia della riga di comando di Databricks è necessario per eseguire processi in un cluster di Azure Databricks.
Passaggio 1: Creare un esperimento
Nell'area di lavoro, selezionare Crea > Esperimento MLflow.
Nel campo Nome immettere
Tutorial.Fare clic su Crea. Prendere nota dell'ID esperimento. In questo esempio è
14622565.
Passaggio 2: Esegui il progetto tutorial di MLflow
I passaggi seguenti configurano la variabile di ambiente MLFLOW_TRACKING_URI ed eseguono il progetto, registrano i parametri di training, le metriche e il modello sottoposto a training nell'esperimento annotato nel passaggio precedente:
Impostare la variabile di ambiente
MLFLOW_TRACKING_URIsull'area di lavoro di Azure Databricks.export MLFLOW_TRACKING_URI=databricksEseguire il progetto di esercitazione MLflow e addestrare un modello di vino . Sostituire
<experiment-id>con l'ID esperimento annotato nel passaggio precedente.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Copiare l'URL
https://<databricks-instance>#job/<job-id>/run/1nell'ultima riga dell'output dell'esecuzione di MLflow.
Passaggio 3: Visualizzare l'esecuzione del processo di Azure Databricks
Aprire l'URL copiato nel passaggio precedente in un browser per visualizzare l'output dell'esecuzione del processo di Azure Databricks:
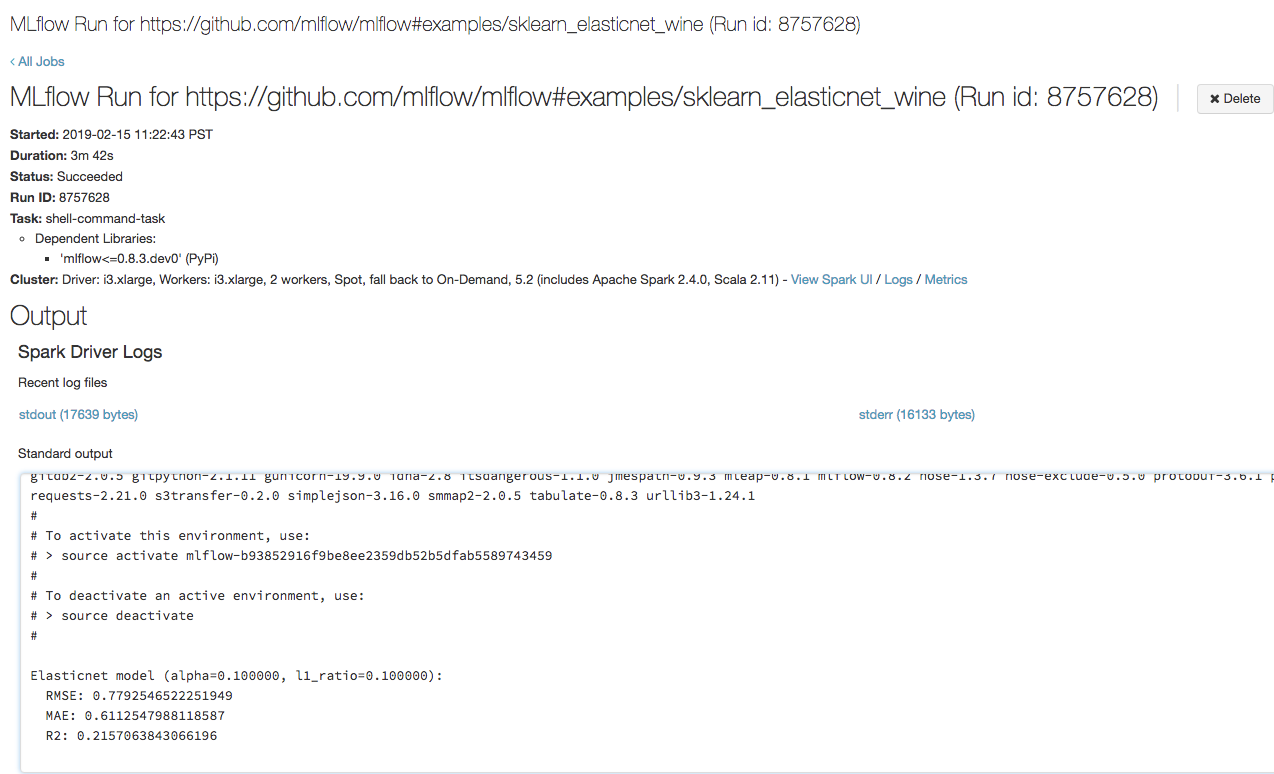
Passaggio 4: Visualizzare i dettagli dell'esperimento e dell'esecuzione di MLflow
Passare all'esperimento nell'area di lavoro di Azure Databricks.
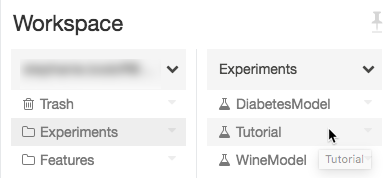
Fare clic sull'esperimento.
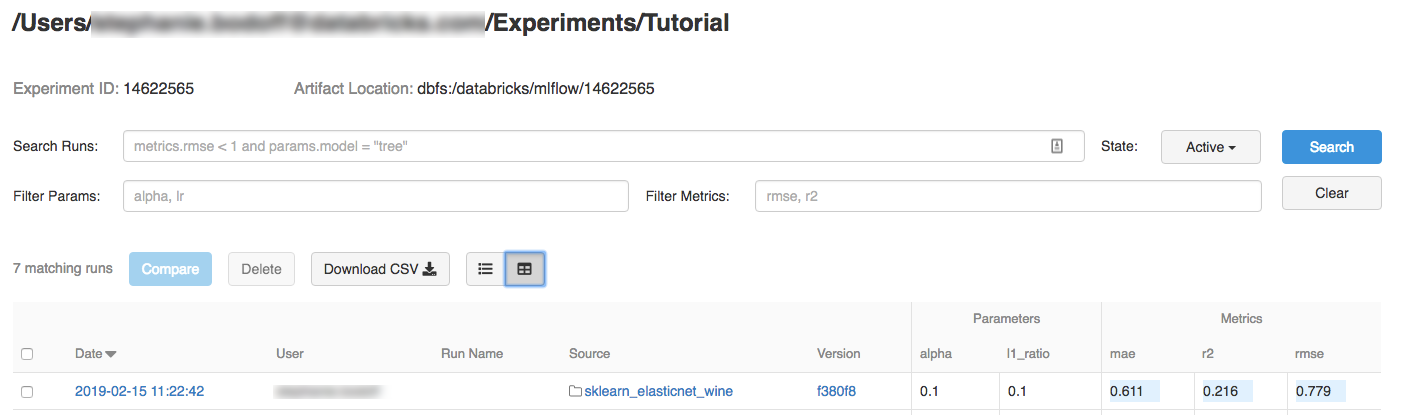
Per visualizzare i dettagli dell'esecuzione, fare clic su un collegamento nella colonna Data.
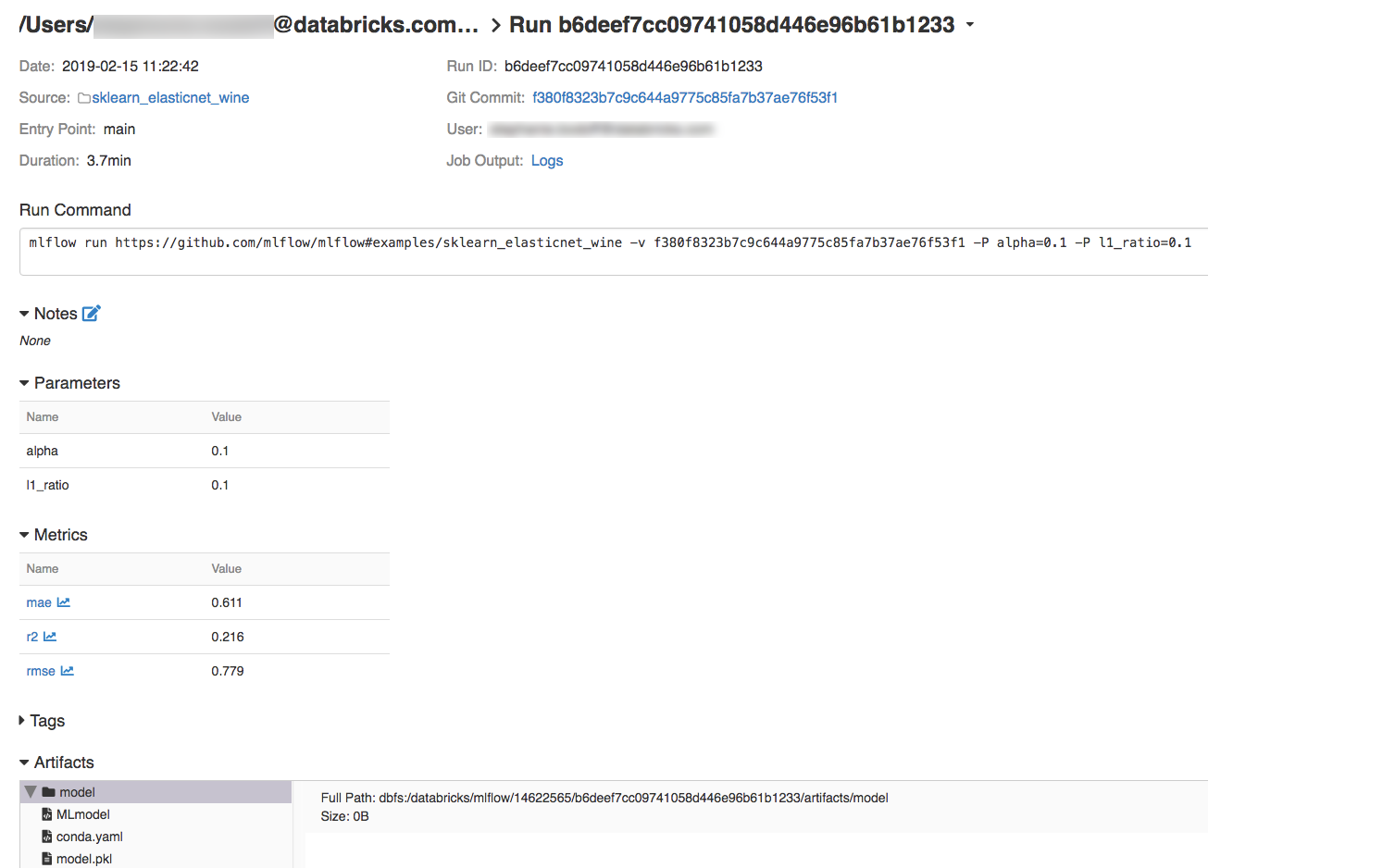
Puoi visualizzare i log della tua esecuzione facendo clic sul collegamento Logs nel campo Output del processo.
Risorse
Per alcuni progetti MLflow di esempio, vedere la libreria di app MLflow, che contiene un repository di progetti pronti per l'esecuzione volti a semplificare l'inclusione delle funzionalità di Machine Learning nel codice.