HorovodRunner: Deep Learning distribuito con Horovod
Importante
Horovod e HorovodRunner sono ora deprecati. Le versioni successive alla 15.4 LTS ML non avranno questo pacchetto preinstallato. Per l'apprendimento avanzato distribuito, Databricks consiglia di utilizzare TorchDistributor per il training distribuito con PyTorch o l'API tf.distribute.Strategy per il training distribuito con TensorFlow.
Informazioni su come eseguire il training distribuito dei modelli di Machine Learning utilizzando HorovodRunner per avviare processi di training Horovod come processi Spark in Azure Databricks.
Che cos'è HorovodRunner?
HorovodRunner è un'API generale per eseguire carichi di lavoro di Deep Learning distribuiti in Azure Databricks usando il framework Horovod . Integrando Horovod con la modalità barriera di Spark, Azure Databricks è in grado di garantire una maggiore stabilità per i processi di training di Deep Learning a esecuzione prolungata in Spark. HorovodRunner utilizza un metodo Python che contiene codice di training di Deep Learning con hook Horovod. HorovodRunner seleziona il metodo sul driver e lo distribuisce ai ruoli di lavoro Spark. Un processo MPI Horovod viene incorporato come processo Spark utilizzando la modalità di esecuzione della barriera. Il primo executor raccoglie gli indirizzi IP di tutti gli executor di attività utilizzando BarrierTaskContext e attiva un processo Horovod utilizzando mpirun. Ciascun processo MPI python carica il programma utente selezionato, lo deserializza ed esegue il programma.
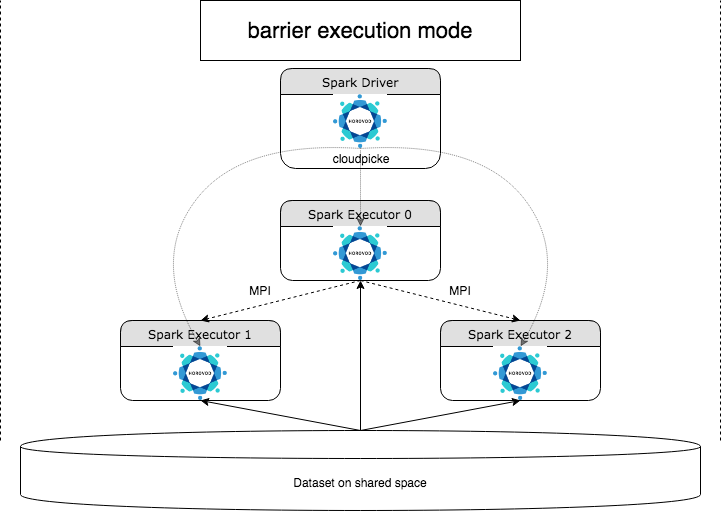
Training distribuito con HorovodRunner
HorovodRunner consente di avviare processi di training Horovod come processi Spark. L'API HorovodRunner supporta i metodi illustrati nella table. Per maggiori dettagli, si veda la documentazione dell'API di HorovodRunner.
| Metodo e firma | Descrizione |
|---|---|
init(self, np) |
Creare un'istanza di HorovodRunner. |
run(self, main, **kwargs) |
Eseguire un processo di training Horovod richiamando main(**kwargs). La funzione principale e gli argomenti della parola chiave vengono serializzati utilizzando cloudpickle e distribuiti ai ruoli di lavoro del cluster. |
L'approccio generale allo sviluppo di un programma di training distribuito con HorovodRunner è:
- Creare un'istanza
HorovodRunnerinizializzata con il numero di nodi. - Definire un metodo di training Horovod in base ai metodi descritti in Uso horovod, assicurandosi di aggiungere eventuali istruzioni import all'interno del metodo.
- Passare il metodo di training all'istanza
HorovodRunner.
Ad esempio:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Per eseguire HorovodRunner sul driver solo con n sottoprocessi, utilizzare hr = HorovodRunner(np=-n). Ad esempio, se nel nodo driver sono presenti 4 GPU, si può scegliere n fino a 4. Per maggiori dettagli sul parametro np, si veda la documentazione dell'API di HorovodRunner. Per informazioni dettagliate su come aggiungere una GPU per ogni sottoprocesso, vedere la guida all'utilizzo di Horovod.
Un errore comune è che gli oggetti TensorFlow non possono essere trovati o prelevati. Ciò si verifica quando le istruzioni di importazione della libreria non vengono distribuite ad altri executor. Per evitare questo problema, includere tutte le istruzioni import (ad esempio, import tensorflow as tf) sia all'inizio del metodo di training Horovod che all'interno di qualsiasi altra funzione definita dall'utente chiamata nel metodo di training Horovod.
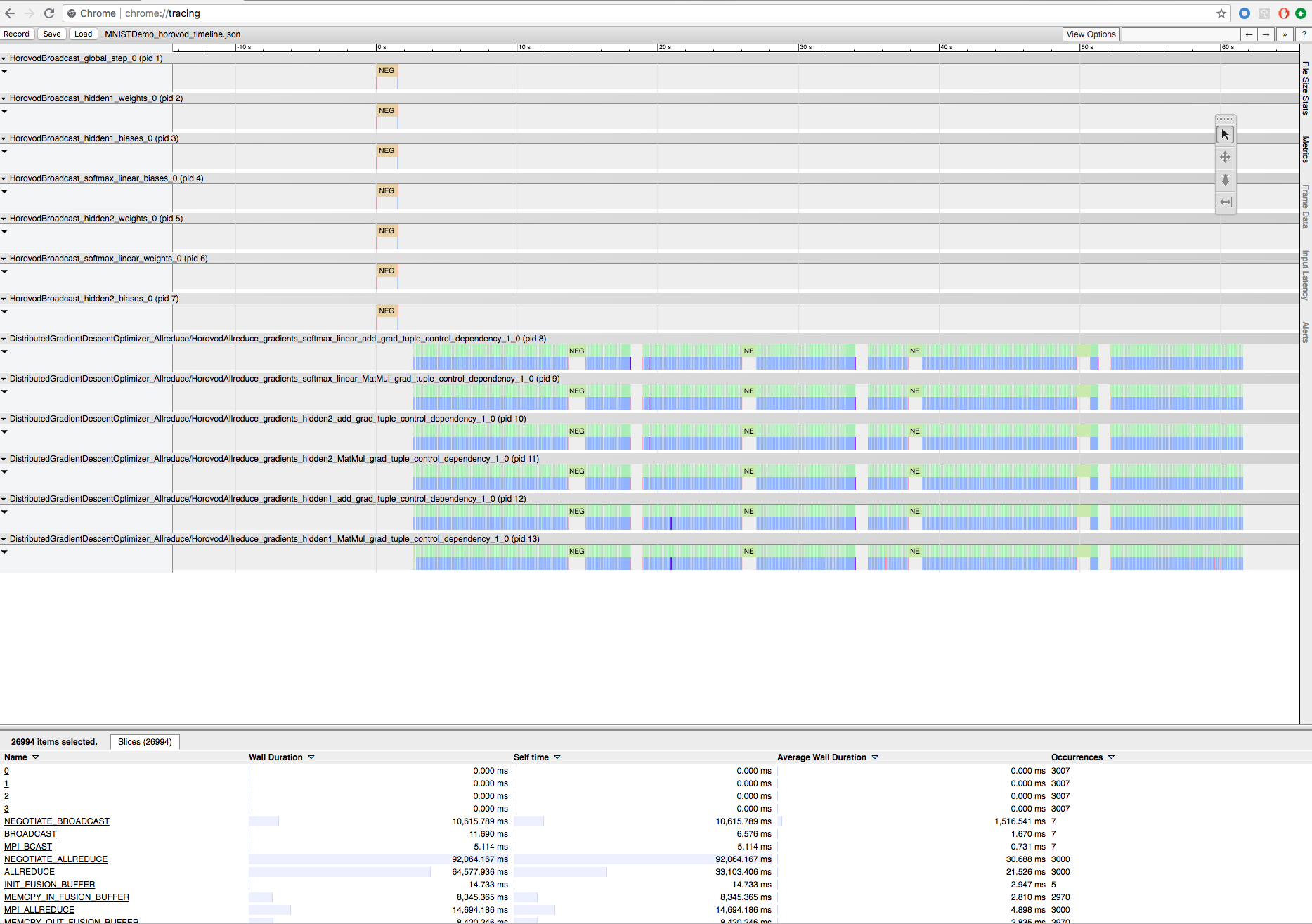
Registrare il training Horovod con la sequenza temporale Horovod
Horovod ha la possibilità di registrare la sequenza temporale della sua attività, chiamata Horovod Timeline.
Importante
Horovod Timeline ha un impatto significativo sulle prestazioni. La velocità effettiva di Inception3 può diminuire circa del 40% quando la Horovod Timeline è abilitata. Per velocizzare i processi HorovodRunner, non utilizzare Horovod Timeline.
Non è possibile visualizzare Horovod Timeline mentre è in corso il training.
Per registrare una sequenza temporale Horovod, set la variabile di ambiente HOROVOD_TIMELINE nel percorso where dove si desidera salvare il file della sequenza temporale. Databricks raccomanda di usare un percorso nell'archiviazione condivisa in modo che il file della sequenza temporale possa essere facilmente recuperato. Ad esempio, è possibile usare le API del file locale DBFS, come illustrato di seguito:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Poi Aggiungere il codice specifico della sequenza temporale all'inizio e alla fine della funzione di training. Il seguente notebook di esempio include un esempio di codice che può essere utilizzato come soluzione alternativa per visualizzare l'avanzamento del training.
Notebook di esempio di Horovod Timeline
Per scaricare il file della sequenza temporale, usare l'interfaccia della riga di comando di Databricks e poi usare la funzionalità chrome://tracing del browser Chrome per visualizzarla. Ad esempio:
Flusso di lavoro per lo sviluppo
Questi sono i passaggi generali della migrazione del codice di Deep Learning a nodo singolo al training distribuito. Gli esempi: Eseguire la migrazione all'apprendimento avanzato distribuito con HorovodRunner in questa sezione illustrano questi passaggi.
- Preparare il codice a nodo singolo: Preparare e testare il codice a nodo singolo con TensorFlow, Keras o PyTorch.
-
Eseguire la migrazione a Horovod: seguire le istruzioni dall'utilizzo di Horovod per eseguire la migrazione del codice con Horovod e testarlo sul driver:
- Aggiungere
hvd.init()per inizializzare Horovod. - Aggiungere una GPU del server da usare da questo processo utilizzando
config.gpu_options.visible_device_list. Con la configurazione tipica di una GPU per processo, questo può essere classificato come set al rango locale. In tal caso, il primo processo nel server verrà allocato alla prima GPU, il secondo processo alla seconda GPU e così via. - Includere una partizione del set di dati. Questo operatore del set di dati è molto utile quando si esegue il training distribuito, poiché consente a ogni ruolo di lavoro di leggere un subset univoco.
- Ridimensionare la frequenza di apprendimento in base al numero di ruoli di lavoro. Le dimensioni effettive del batch nel training distribuito sincrono vengono ridimensionate in base al numero di ruoli di lavoro. L'aumento della velocità di apprendimento permette di compensare l'aumento delle dimensioni del batch.
- Eseguire il wrapping dell'utilità di ottimizzazione in
hvd.DistributedOptimizer. L'utilità di ottimizzazione distribuita delega il calcolo dei gradienti all'ottimizzatore originale, calcola i gradienti medi usando allreduce o allgather e poi applica i gradienti mediati. - Aggiungere
hvd.BroadcastGlobalVariablesHook(0)per trasmettere gli stati iniziali delle variabili dal rango 0 a tutti gli altri processi. Questo è necessario per garantire l'inizializzazione coerente di tutti i ruoli di lavoro quando il training viene avviato con pesi casuali o ripristinato da un checkpoint. In alternativa, se non si usaMonitoredTrainingSession, è possibile eseguire l'operazionehvd.broadcast_global_variablesdopo l'inizializzazione delle variabili globali. - Modificare il codice per salvare i checkpoint solo sul ruolo di lavoro 0 per impedire ad altri ruoli di lavoro di danneggiarli.
- Aggiungere
- Eseguire la migrazione a HorovodRunner: HorovodRunner esegue il processo di training Horovod richiamando una funzione Python. Eseguire il wrapping della routine di training principale in una singola funzione Python. Poi sarà possibile testare HorovodRunner in modalità locale e distribuita.
Update le librerie di Deep Learning
Se si esegue l'aggiornamento o il downgrade di TensorFlow, Keras o PyTorch, è necessario reinstallare Horovod in modo che venga compilato nella libreria appena installata. Ad esempio, se si vuole aggiornare TensorFlow, Databricks raccomanda di utilizzare lo script init dalle istruzioni di installazione di TensorFlow e aggiungere il codice di installazione horovod specifico di TensorFlow seguente alla fine di esso. Si veda Istruzioni di installazione di Horovod per usare combinazioni diverse, ad esempio l'aggiornamento o il downgrade di PyTorch e altre librerie.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Esempi: eseguire la migrazione al Deep Learning distribuito con HorovodRunner
I seguenti esempi, basati sul set di dati MNIST, illustrano come eseguire la migrazione di un programma di Deep Learning a nodo singolo al deep learning distribuito con HorovodRunner.
- Deep Learning tramite TensorFlow con HorovodRunner per MNIST
- Adattare PyTorch su un singolo nodo al deep learning distribuito
Limiti
- Quando si usano i file dell'area di lavoro, HorovodRunner non funzionerà se
npè set a maggiore di 1 e le importazioni del notebook da altri file relativi. Prendere in considerazione l'uso di horovod.spark invece diHorovodRunner. - Se si verificano errori come
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer, questo indica un problema con la comunicazione di rete tra i nodi nel cluster. Per risolvere questo errore, aggiungere il seguente frammento di codice di training per usare l'interfaccia di rete primaria.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"