Configurare il gateway di intelligenza artificiale nei modelli che servono gli endpoint
Questo articolo illustra come configurare Mosaic AI Gateway in un endpoint di servizio del modello.
Requisiti
- Un'area di lavoro di Databricks in un'area supportata per modelli esterni o in un'area supportata per la velocità effettiva con provisioning .
- Endpoint di gestione di un modello.
- Per creare un endpoint per i modelli esterni, completare i passaggi 1 e 2 di Creare un modello esterno che gestisce l'endpoint.
- Per creare un endpoint per la velocità effettiva assegnata, vedere API dei modelli di base di velocità effettiva assegnata.
Configurare il gateway di intelligenza artificiale usando l'interfaccia utente
Questa sezione illustra come configurare il gateway di intelligenza artificiale durante la creazione dell'endpoint usando l'interfaccia utente di servizio. Se si preferisce eseguire questa operazione a livello di codice, vedere l'esempio notebook.
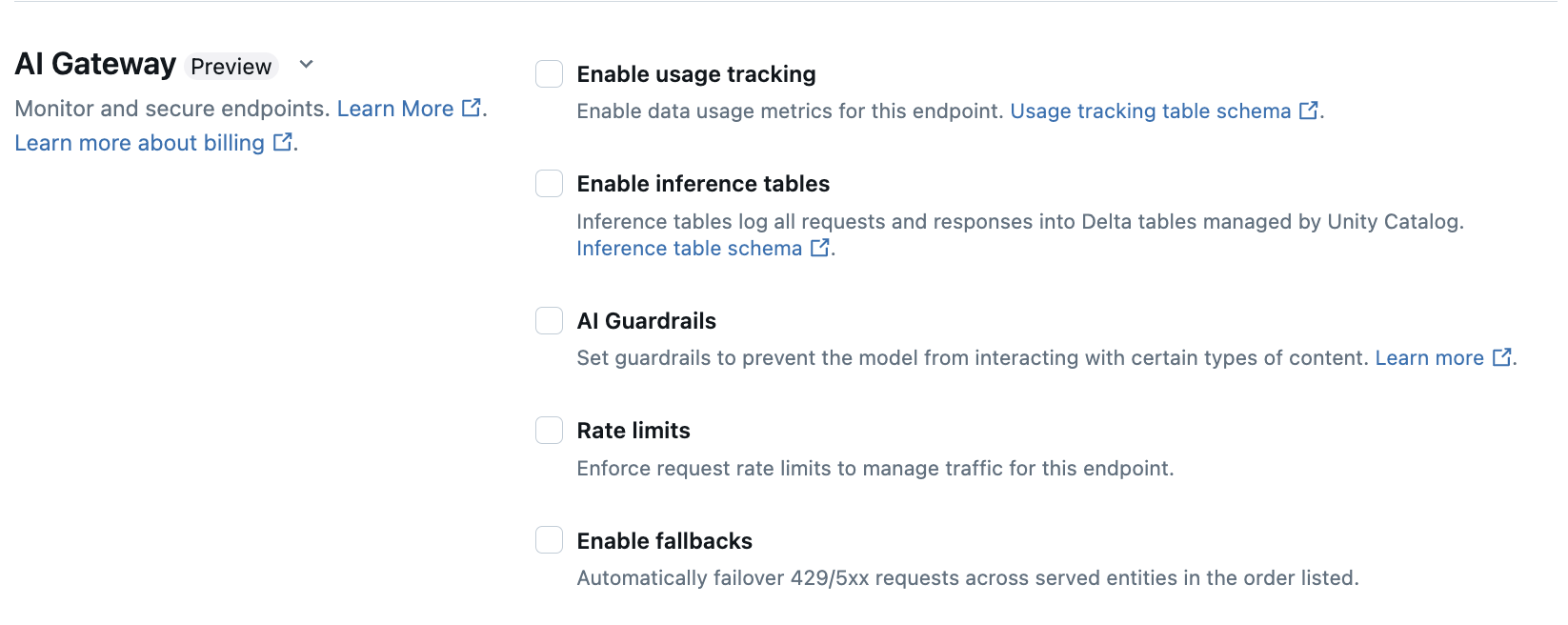
Nella sezione AI Gateway della pagina di creazione dell'endpoint, è possibile configurare singolarmente le funzionalità dell'AI Gateway. Consulta Funzionalità supportate per sapere quali funzionalità sono disponibili sugli endpoint di servizio di modelli esterni e sugli endpoint di throughput con provisioning.
| Funzionalità | Abilitazione | Dettagli |
|---|---|---|
| Monitoraggio dell'utilizzo | Selezionare Abilitare il rilevamento dell'utilizzo per abilitare il rilevamento e il monitoraggio delle metriche di utilizzo dei dati. | - È necessario che Unity Catalog sia abilitato. - Gli amministratori degli account devono abilitare lo schema della tabella di sistema di gestione prima di usare le tabelle di sistema: system.serving.endpoint_usage che acquisisce i conteggi dei token per ogni richiesta all'endpoint e system.serving.served_entities che archivia i metadati per ogni modello di base.- Vedere Schemi delle tabelle di rilevamento dell'utilizzo - Solo gli amministratori dell'account hanno l'autorizzazione per visualizzare o eseguire query sulla tabella served_entities o endpoint_usage, anche se l'utente che gestisce l'endpoint deve abilitare il monitoraggio dell'uso. Vedere Concedere l'accesso alle tabelle di sistema- Il numero di token di input e di output viene stimato come ( text_length+1)/4 se il numero di token non viene restituito dal modello. |
| Registrazione del payload | Selezionare Abilitare le tabelle di inferenza per registrare automaticamente le richieste e le risposte dall'endpoint nelle tabelle Delta gestite da Unity Catalog. | - È necessario che Unity Catalog sia abilitato e che si disponga dell'accesso CREATE_TABLE nello schema del catalogo specificato.- tabelle di inferenza abilitate dal gateway AI hanno uno schema diverso rispetto a tabelle di inferenza create per gestire endpoint che servono modelli personalizzati. Consultare schema della tabella di inferenza abilitata dal gateway AI. - I dati di registrazione del payload popolano queste tabelle meno dell'ora dopo l'esecuzione di query sull'endpoint. - I payload maggiori di 1 MB non vengono registrati. - Il payload della risposta aggrega la risposta di tutti i blocchi restituiti. - Lo streaming è supportato. Negli scenari di streaming, il payload della risposta aggrega la risposta dei blocchi restituiti. |
| Guardrail di IA | Vedere Configurare guardrail di IA nell'interfaccia utente. | - Guardrail impedisce al modello di interagire con contenuto non sicuro e dannoso rilevato negli input e negli output del modello. - Le protezioni di output non sono supportate né per gli incorporamenti di modelli, né per lo streaming. |
| Limiti di richieste inviate al bot | È possibile applicare i limiti di frequenza delle richieste per gestire il traffico per l'endpoint in base all'utente e per ogni endpoint | - I limiti di frequenza sono definiti nelle query al minuto (QPM). - Il valore predefinito è Nessun limite per utente e per endpoint. |
| instradamento del traffico | Per configurare il routing del traffico nell'endpoint, vedere Gestire più modelli esterni a un endpoint. |
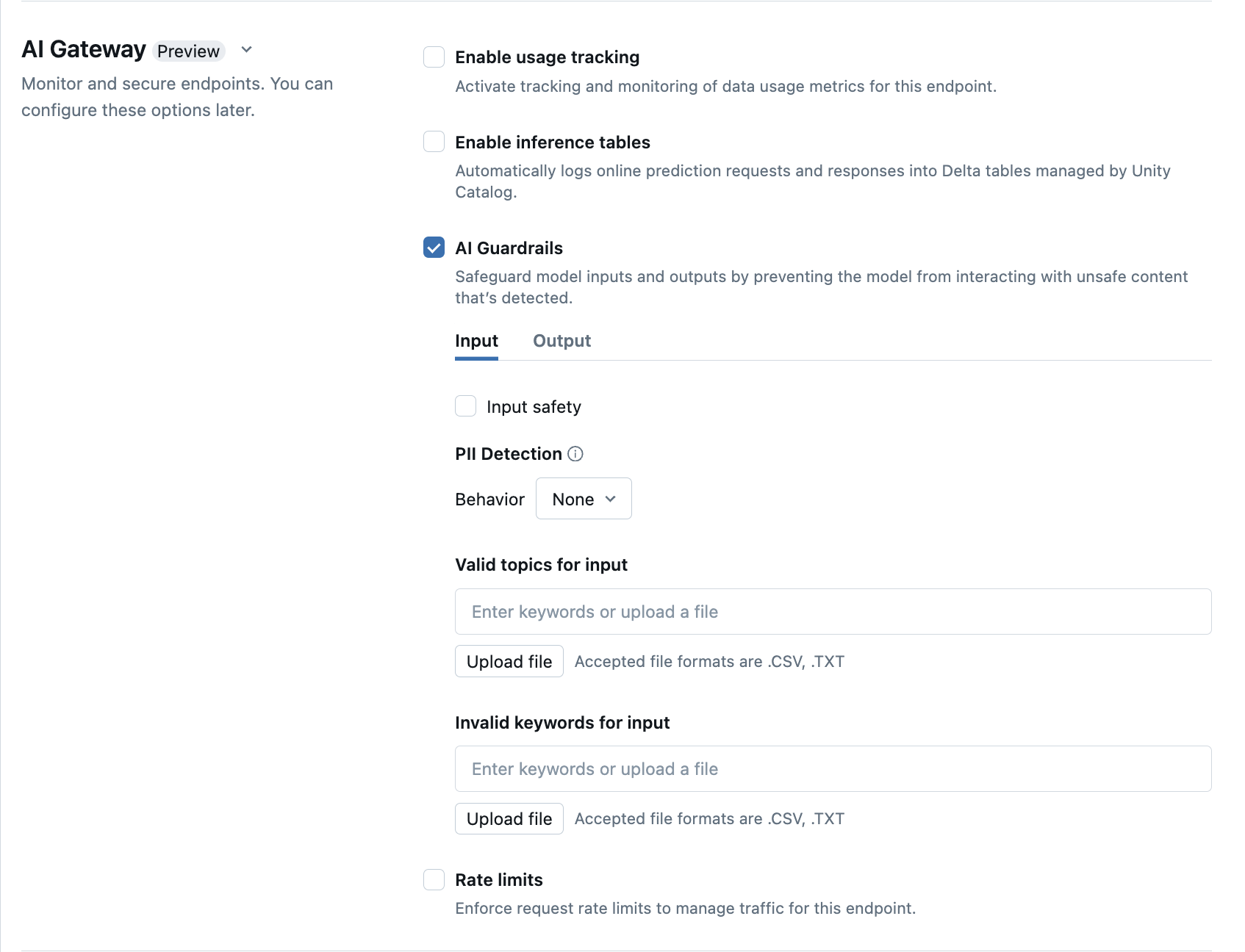
Configurare guardrail di IA nell'interfaccia utente
Nella tabella seguente viene illustrato come configurare le protezioni supportate .
| Protezione | Abilitazione | Dettagli |
|---|---|---|
| Sicurezza | Selezionare Safety per abilitare misure di sicurezza per impedire al modello di interagire con contenuto non sicuro e dannoso. | |
| Rilevamento delle informazioni personali | Selezionare rilevamento delle informazioni personali per rilevare dati personali, ad esempio nomi, indirizzi, numeri di carta di credito. | |
| Argomenti validi | È possibile digitare argomenti direttamente in questo campo. Se sono presenti più voci, assicurarsi di premere invio dopo ogni argomento. In alternativa, è possibile caricare un file .csv o .txt. |
È possibile specificare un massimo di 50 argomenti validi. Ogni argomento non può superare i 100 caratteri |
| Parole chiave non valide | È possibile digitare argomenti direttamente in questo campo. Se sono presenti più voci, assicurarsi di premere invio dopo ogni argomento. In alternativa, è possibile caricare un file .csv o .txt. |
È possibile specificare un massimo di 50 parole chiave non valide. La lunghezza di ciascuna chiave non può superare i 100 caratteri. |
schemi della tabella di rilevamento dell'utilizzo
La tabella del sistema di rilevamento dell'utilizzo system.serving.served_entities presenta lo schema seguente:
| Nome colonna | Descrizione | Tipo |
|---|---|---|
served_entity_id |
ID univoco dell’entità dell'evento. | STRING |
account_id |
ID dell'account cliente per la condivisione Delta. | STRING |
workspace_id |
ID dell'area di lavoro del cliente dell'endpoint di servizio. | STRING |
created_by |
ID del creatore. | STRING |
endpoint_name |
Nome dell'endpoint dell’endpoint di servizio. | STRING |
endpoint_id |
ID univoco dell'endpoint di servizio. | STRING |
served_entity_name |
Nome dell’entità servita. | STRING |
entity_type |
Tipo dell'entità servita. Può essere FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL o CUSTOM_MODEL |
STRING |
entity_name |
Nome sottostante dell'entità. Diverso da quello served_entity_name che è un nome specificato dall'utente. Ad esempio, entity_name è il nome del modello del catalogo Unity. |
STRING |
entity_version |
Versione dell'entità servita. | STRING |
endpoint_config_version |
Versione della configurazione dell'endpoint. | INT |
task |
Tipo di attività. Può essere llm/v1/chat, llm/v1/completions o llm/v1/embeddings. |
STRING |
external_model_config |
Configurazioni per i modelli esterni. Ad esempio, {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Configurazioni per i modelli di base. Ad esempio, {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
Configurazioni per i modelli personalizzati. Ad esempio, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Configurazioni per le specifiche delle caratteristiche. Ad esempio, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Data e ora della modifica per l'entità servita. | TIMESTAMP |
endpoint_delete_time |
Data e ora dell'eliminazione dell'entità. L'endpoint è il contenitore per l'entità servita. Dopo l'eliminazione dell'endpoint, viene eliminata anche l'entità servita. | TIMESTAMP |
La tabella del sistema di rilevamento dell'utilizzo system.serving.endpoint_usage presenta lo schema seguente:
| Nome colonna | Descrizione | Tipo |
|---|---|---|
account_id |
Numero dell’ID account cliente. | STRING |
workspace_id |
ID dell'area di lavoro del cliente dell'endpoint di servizio. | STRING |
client_request_id |
Identificatore di richiesta fornito dall'utente che può essere specificato nel corpo della richiesta di gestione del modello. | STRING |
databricks_request_id |
Identificatore di richiesta generato da Azure Databricks associato a tutte le richieste di gestione del modello. | STRING |
requester |
ID dell'utente o dell'entità servizio le cui autorizzazioni vengono usate per la richiesta di chiamata dell'endpoint di servizio. | STRING |
status_code |
Codice di stato HTTP restituito dal modello. | INTEGER |
request_time |
La data e l'ora in cui è stata ricevuta la richiesta. | TIMESTAMP |
input_token_count |
Il numero dei token di input. | LONG |
output_token_count |
Il numero dei token di output. | LONG |
input_character_count |
Numero di caratteri della stringa di input o della richiesta. | LONG |
output_character_count |
Numero di caratteri della stringa di output della risposta. | LONG |
usage_context |
Mappa fornita dall'utente contenente gli identificatori dell'utente finale o dell'applicazione del cliente che effettua la chiamata all'endpoint. Si veda Altre informazioni su come definire l'utilizzo con usage_context. | MAP |
request_streaming |
Indica se la richiesta è in modalità streaming. | BOOLEAN |
served_entity_id |
ID univoco utilizzato per effettuare un join con la tabella di dimensioni system.serving.served_entities per cercare informazioni sull'endpoint e sull'entità servita. |
STRING |
Definire ulteriormente l'utilizzo con usage_context
Quando si esegue una query su un modello esterno con il rilevamento dell'utilizzo abilitato, è possibile fornire il usage_context parametro con il tipo Map[String, String]. Il mapping del contesto di utilizzo viene visualizzato nella tabella di rilevamento dell'utilizzo nella colonna usage_context. Le dimensioni della usage_context mappa non possono superare 10 KiB.
Gli amministratori dell'account possono aggregare righe diverse in base al contesto di utilizzo per ottenere informazioni dettagliate e aggiungere queste informazioni alle informazioni nella tabella di registrazione del payload. Ad esempio, è possibile aggiungere end_user_to_charge a usage_context per tenere traccia dell'attribuzione dei costi per gli utenti finali.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Aggiornare le funzionalità del gateway di intelligenza artificiale sugli endpoint
È possibile aggiornare le funzionalità del gateway di intelligenza artificiale nei modelli che servono gli endpoint che in precedenza li avevano abilitati e gli endpoint che non lo erano. Gli aggiornamenti alle configurazioni del gateway di IA richiedono circa 20-40 secondi per l’applicazione, ma gli aggiornamenti della limitazione della frequenza possono richiedere fino a 60 secondi.
Di seguito viene illustrato come aggiornare le funzionalità del gateway di intelligenza artificiale in un endpoint di servizio del modello usando l'interfaccia utente di gestione.
Nella sezione Gateway della pagina endpoint è possibile visualizzare le caratteristiche abilitate. Per aggiornare queste funzionalità, fare clic su Modifica gateway di intelligenza artificiale.

Esempio di notebook
Il notebook seguente illustra come abilitare e usare a livello di codice le funzionalità di Databricks Mosaic AI Gateway per gestire e gestire i modelli dai provider. Per informazioni dettagliate sull'API REST, vedere quanto segue:
Abilitare il Notebook delle caratteristiche di Databricks Mosaic AI Gateway
Prendi il notebook