Caricare dati in modo incrementale dall'istanza gestita di SQL di Azure in Archiviazione di Azure tramite la tecnologia Change Data Capture
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questa esercitazione illustra come creare una data factory di Azure con una pipeline che carica dati differenziali basati su informazioni di Change Data Capture nel database dell'istanza gestita di SQL di Azure di origine in una risorsa di archiviazione BLOB di Azure.
In questa esercitazione vengono completati i passaggi seguenti:
- Preparare l'archivio dati di origine.
- Creare una data factory.
- Creare servizi collegati.
- Creare set di dati di origine e sink.
- Creare, eseguire il debug ed eseguire la pipeline per verificare la presenza di dati modificati
- Modificare i dati nella tabella di origine
- Completare, eseguire e monitorare la pipeline di copia incrementale completa
Panoramica
È possibile usare la tecnologia Change Data Capture supportata da archivi dati come l'istanza gestita di SQL di Azure e SQL Server per identificare i dati modificati. Questa esercitazione descrive come usare Azure Data Factory con la tecnologia Change Data Capture SQL per caricare in modo incrementale dati differenziali dall'istanza gestita di SQL di Azure in Archiviazione BLOB di Azure. Per altre informazioni pratiche sulla tecnologia Change Data Capture SQL, vedere Change Data Capture in SQL Server.
Flusso di lavoro end-to-end
Ecco alcuni passaggi del flusso di lavoro end-to-end tipico per caricare dati in modo incrementale usando la tecnologia Change Data Capture.
Nota
Sia l'istanza gestita di SQL di Azure sia SQL Server supportano la tecnologia Change Data Capture. Questa esercitazione usa l'istanza gestita di SQL di Azure come archivio dati di origine. È anche possibile usare un database di SQL Server locale.
Soluzione di alto livello
In questa esercitazione verrà creata una pipeline che esegue le operazioni seguenti:
- Creare un'attività di ricerca per contare il numero di record modificati nella tabella CDC del database SQL e passarli a un'attività Condizione if.
- Creare una Condizione if per verificare se sono presenti record modificati e, in tal caso, richiamare l'attività di copia.
- Creare un'attività di copia per copiare i dati inseriti/aggiornati/eliminati dalla tabella CDC ad Archiviazione BLOB di Azure.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Istanza gestita di SQL di Azure. Usare il database come archivio dati di origine. Se non si ha un Istanza gestita di SQL di Azure, vedere l'articolo Creare un database SQL di Azure Istanza gestita per la procedura per crearne uno.
- Account di archiviazione di Azure. Usare l'archivio BLOB come archivio dati sink. Se non si ha un account di archiviazione di Azure, vedere l'articolo Creare un account di archiviazione per informazioni su come crearne uno. Creare un contenitore denominato raw.
Creare una tabella di origine dati nel database SQL di Azure
Avviare SQL Server Management Studio e connettersi al server delle istanze gestite di SQL di Azure.
In Esplora server fare clic con il pulsante destro del mouse sul database e scegliere Nuova query.
Eseguire questo comando SQL sul database delle istanze gestite di SQL di Azure per creare una tabella denominata
customerscome archivio dell'origine dati.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Abilitare il meccanismo Change Data Capture nel database e nella tabella di origine (customers) eseguendo la query SQL seguente:
Nota
- Sostituire il <nome dello schema di origine> con lo schema dell'istanza gestita di SQL di Azure contenente la tabella customers.
- Change Data Capture non esegue alcuna operazione come parte delle transazioni che modificano la tabella rilevata. Al contrario, le operazioni di inserimento, aggiornamento ed eliminazione vengono scritte nel log delle transazioni. Se non vengono eliminati in modo periodico e sistematico, i dati inseriti nelle tabelle delle modifiche aumenteranno notevolmente e non sarà più possibile gestirli. Per altre informazioni, vedere Abilitare Change Data Capture per un database
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Per inserire i dati nella tabella customers. eseguire questo comando:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Nota
Non vengono acquisite modifiche cronologiche apportate alla tabella prima dell'abilitazione di Change Data Capture.
Creare una data factory
Seguire la procedura descritta nell'articolo Avvio rapido: Creare una data factory usando il portale di Azure per creare una data factory se non ne è già disponibile una da usare.
Creare servizi collegati
Si creano servizi collegati in una data factory per collegare gli archivi dati e i servizi di calcolo alla data factory. In questa sezione verranno creati i servizi collegati all'account di archiviazione di Azure e all'istanza gestita di SQL di Azure.
Creare il servizio collegato Archiviazione di Azure.
In questo passaggio l'account di archiviazione di Azure viene collegato alla data factory.
Fare clic su Connessioni e quindi su + Nuovo.
Nella finestra New Linked Service (Nuovo servizio collegato) selezionare Archiviazione BLOB di Azure e fare clic su Continua.
Nella finestra New Linked Service (Nuovo servizio collegato) seguire questa procedura:
- Immettere AzureStorageLinkedService per Nome.
- Selezionare il proprio account di archiviazione di Azure per Nome account di archiviazione.
- Fare clic su Salva.
Creare un servizio collegato al database dell'istanza gestita di SQL di Azure.
In questo passaggio viene collegato il database dell'istanza gestita di SQL di Azure alla data factory.
Nota
Per coloro che usano l'istanza gestita di SQL, vedere qui per informazioni sull'accesso tramite un endpoint pubblico o un endpoint privato. Se si usa un endpoint privato, è necessario eseguire questa pipeline usando un runtime di integrazione self-hosted. Lo stesso vale per gli scenari in cui è in esecuzione SQL Server locale, in una macchina virtuale o in una rete virtuale.
Fare clic su Connessioni e quindi su + Nuovo.
Nella finestra Nuovo servizio collegato selezionare Istanza gestita di database SQL di Azure e fare clic su Continua.
Nella finestra New Linked Service (Nuovo servizio collegato) seguire questa procedura:
- Immettere AzureSqlMI1 nel campo Nome.
- Selezionare il server SQL in uso nel campo Nome server.
- Selezionare il database SQL in uso nel campo Nome database.
- Immettere il nome dell'utente nel campo Nome utente.
- Immettere la password dell'utente nel campo Password.
- Fare clic su Test connessione per testare la connessione.
- Fare clic su Salva per salvare il servizio collegato.
Creare i set di dati
In questo passaggio verranno creati i set di dati per rappresentare l'origine dati e la destinazione dati.
Creare un set di dati per rappresentare i dati di origine
In questo passaggio viene creato un set di dati per rappresentare i dati di origine.
Nella visualizzazione albero fare clic su + (segno più) e quindi su Set di dati.
Selezionare Istanza gestita di database SQL di Azure e fare clic su Continua.
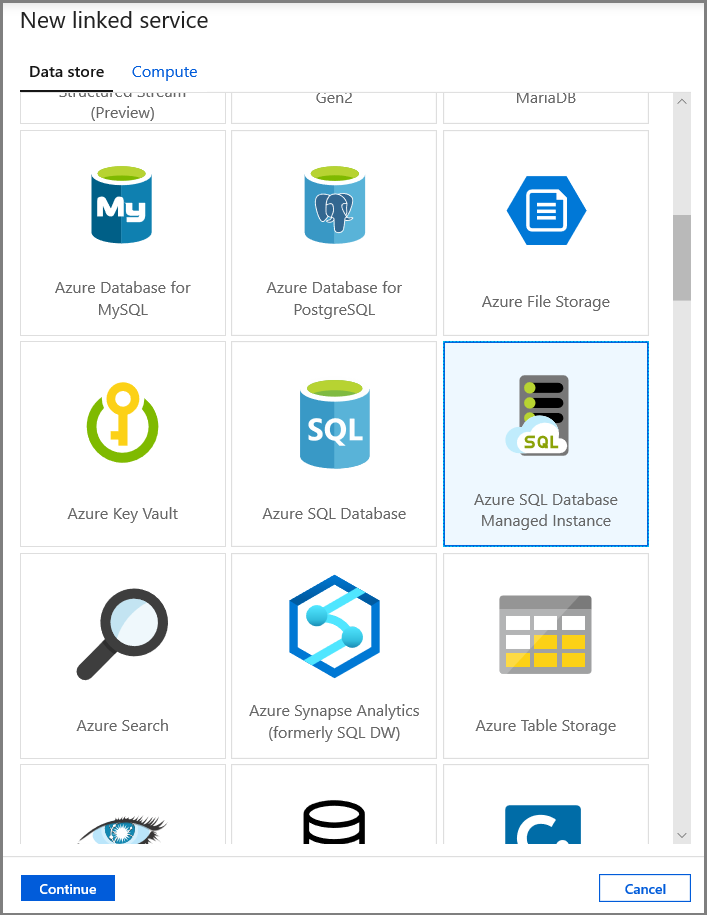
Nella scheda Imposta proprietà impostare il nome del set di dati e le informazioni di connessione:
- Selezionare AzureSqlMI1 per Servizio collegato.
- Selezionare [dbo].[dbo_customers_CT] per Nome tabella. Nota: questa tabella è stata creata automaticamente quando la funzionalità Change Data Capture è stata abilitata per la tabella customers. I dati modificati non vengono mai sottoposti a query direttamente da questa tabella, ma vengono invece estratti tramite le funzioni di Change Data Capture.
Creare un set di dati per rappresentare i dati copiati nell'archivio dati sink
In questo passaggio viene creato un set di dati per rappresentare i dati copiati dall'archivio dati di origine. Come parte dei prerequisiti è stato creato il contenitore data lake nell'archivio BLOB di Azure. Creare il contenitore se non esiste oppure impostare il nome di un contenitore esistente. In questa esercitazione il nome del file di output viene generato in modo dinamico usando l'ora di attivazione, che verrà configurata in seguito.
Nella visualizzazione albero fare clic su + (segno più) e quindi su Set di dati.
Selezionare Archiviazione BLOB di Azure e fare clic su Continua.

Selezionare DelimitedText e fare clic su Continua.

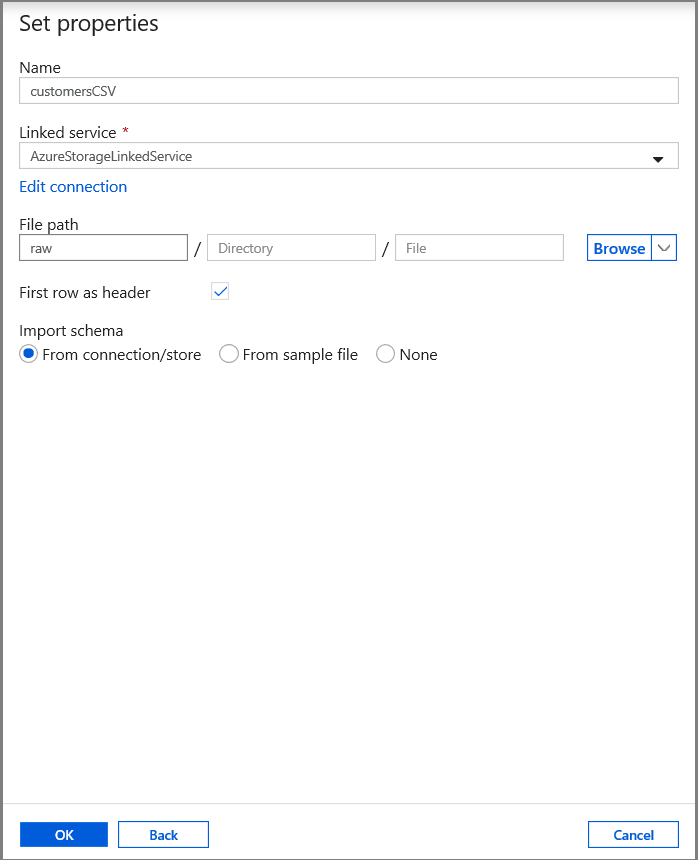
Nella scheda Imposta proprietà impostare il nome del set di dati e le informazioni di connessione:
- Selezionare AzureStorageLinkedService per Servizio collegato.
- Immettere raw per la parte container di filePath.
- Abilitare Prima riga come intestazione
- Fare clic su OK.
Creare una pipeline per copiare i dati modificati
In questo passaggio verrà creata una pipeline che controlla prima di tutto il numero di record modificati presenti nella tabella delle modifiche tramite un'attività di ricerca. Un'attività Condizione if controlla se il numero di record modificati è maggiore di zero ed esegue un'attività di copia per copiare i dati inseriti/aggiornati/eliminati dal database SQL di Azure alla risorsa di archiviazione BLOB di Azure. Infine, viene configurato un trigger di finestra a cascata e le ore di inizio e di fine verranno passate alle attività come parametri della finestra iniziale e finale.
Nell'interfaccia utente di Data Factory passare alla scheda Modifica . Fare clic su + (più) nel riquadro sinistro e fare clic su Pipeline.
Verrà visualizzata una nuova scheda per la configurazione della pipeline. La pipeline è riportata anche nella visualizzazione albero. Nella finestra Proprietà modificare il nome della pipeline in IncrementalCopyPipeline.
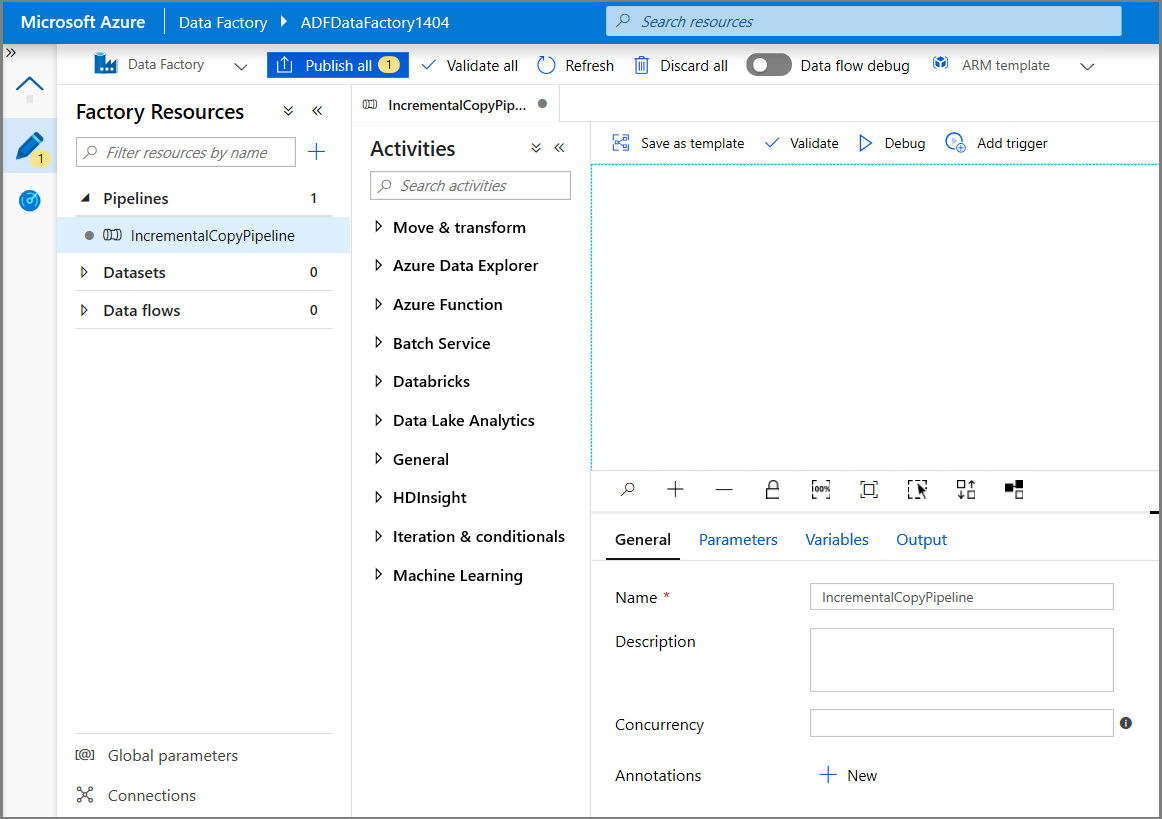
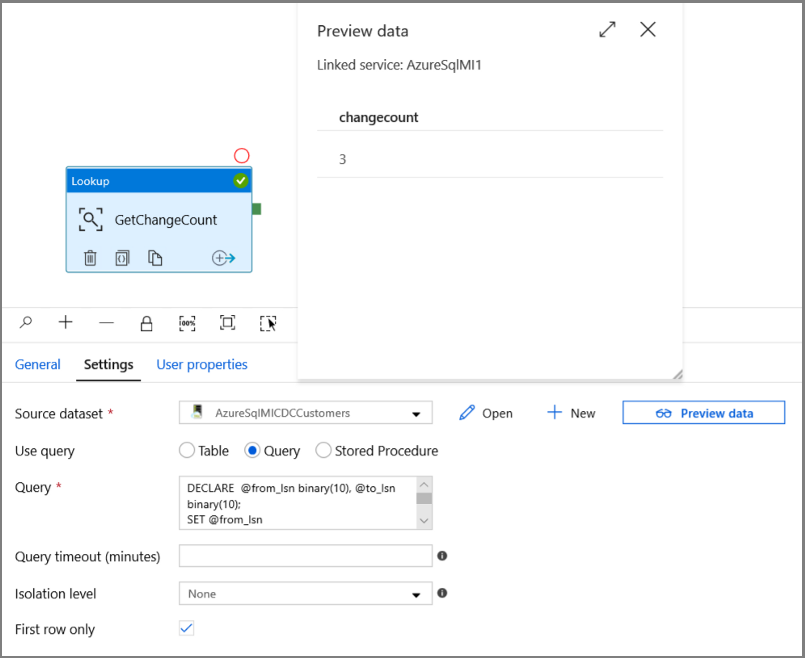
Espandere Generale nella casella degli strumenti Attività e trascinare l'attività Cerca nell'area di progettazione della pipeline. Impostare il nome dell'attività su GetChangeCount. Questa attività ottiene il numero di record nella tabella delle modifiche per un intervallo di tempo specificato.
Passare a Impostazioni nella finestra Proprietà:
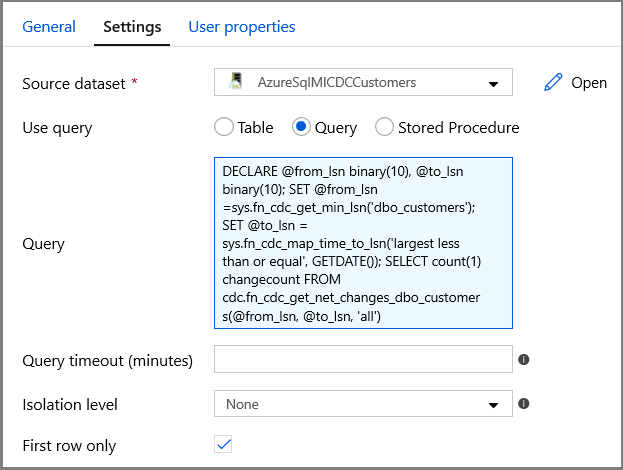
Specificare il nome del set di dati dell'istanza gestita di SQL per il campo Set di dati di origine.
Selezionare l'opzione Query e immettere quanto segue nella casella query:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Abilitare Solo prima riga
Fare clic sul pulsante Anteprima dati per assicurarsi che l'attività di ricerca restituisca un output valido
Nella casella degli strumenti Attività espandere Iterazione e condizionali e trascinare l'attività Condizione if nell'area di progettazione della pipeline. Impostare il nome dell'attività su HasChangedRows.
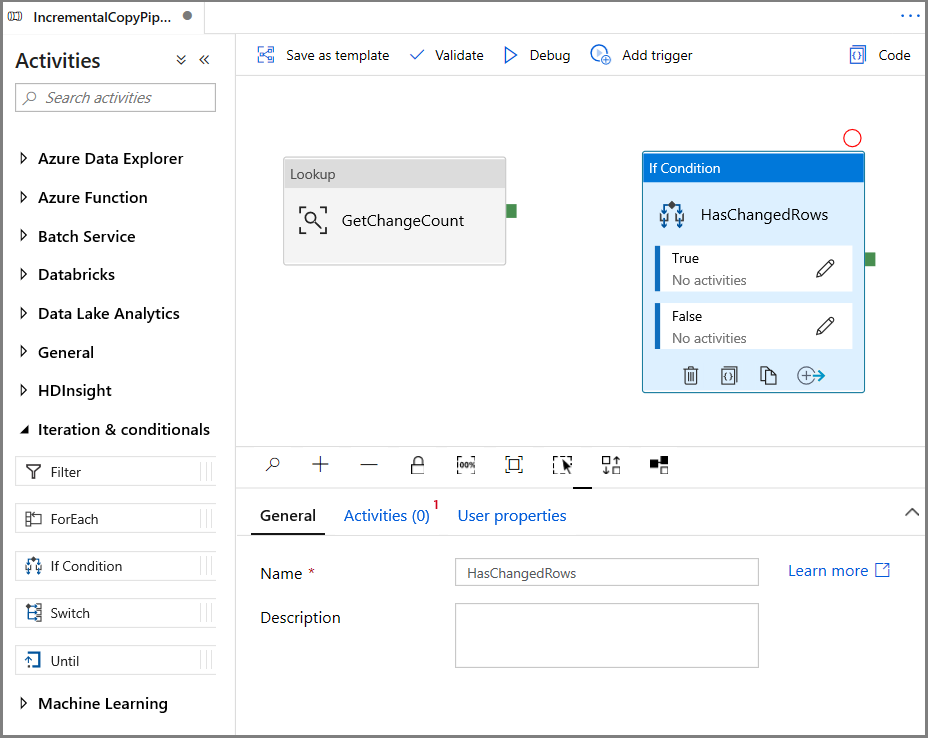
Passare ad Attività nella finestra Proprietà:
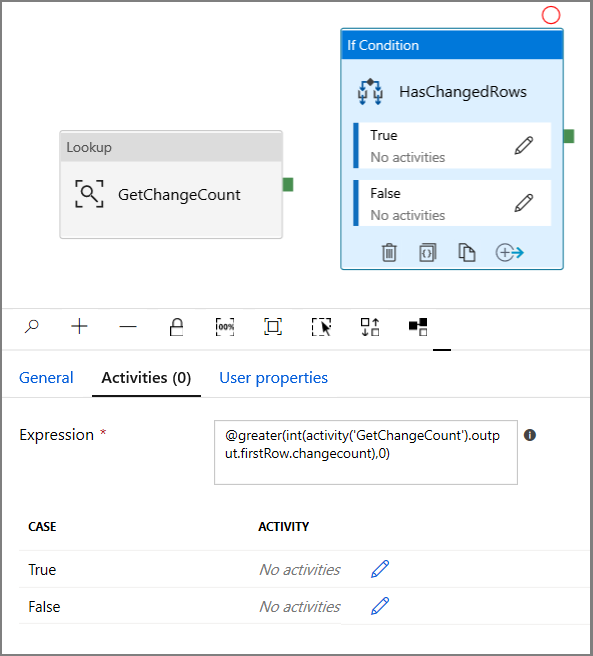
- Immettere l'Espressione seguente
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Fare clic sull'icona a forma di matita per modificare la condizione True.
- Espandere Generali nella casella degli strumenti Attività e trascinare un'attività Attendi nell'area di progettazione della pipeline. Si tratta di un'attività temporanea per eseguire il debug della condizione if e verrà modificata più avanti nell'esercitazione.
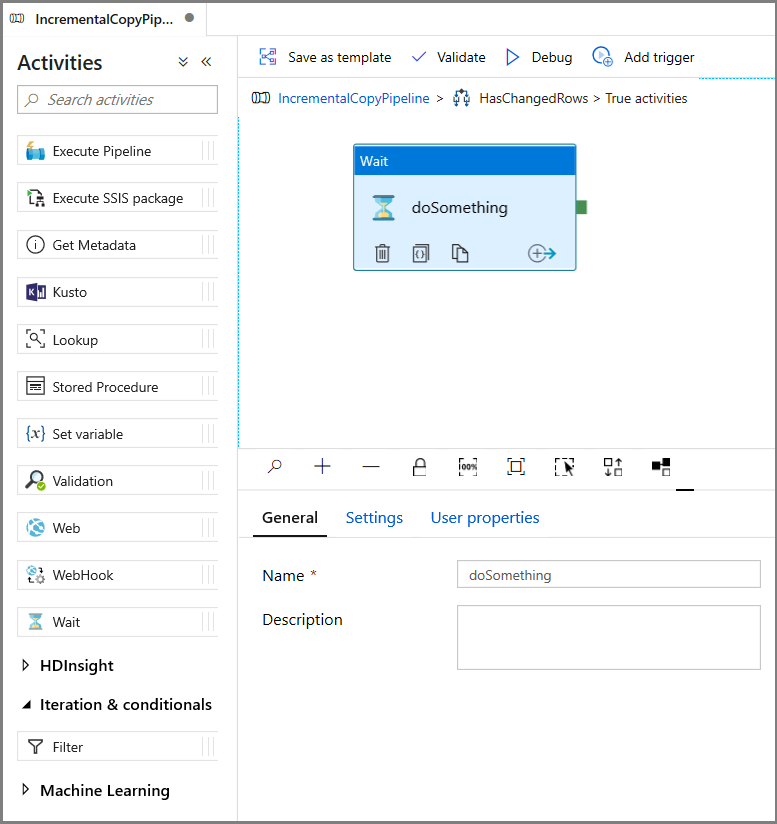
- Fare clic sulla barra di navigazione IncrementalCopyPipeline per tornare alla pipeline principale.
Eseguire la pipeline in modalità Debug per verificare che la pipeline venga eseguita correttamente.
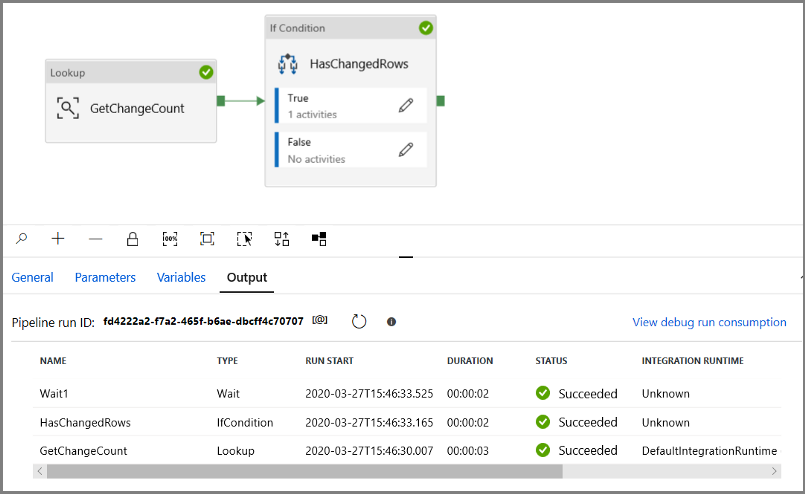
Tornare quindi al passaggio relativo alla condizione True ed eliminare l'attività Attendi. Nella casella degli strumenti Attività espandere Sposta e trasforma e trascinare l'attività Copia nell'area di progettazione della pipeline. Impostare il nome dell'attività su IncrementalCopyActivity.
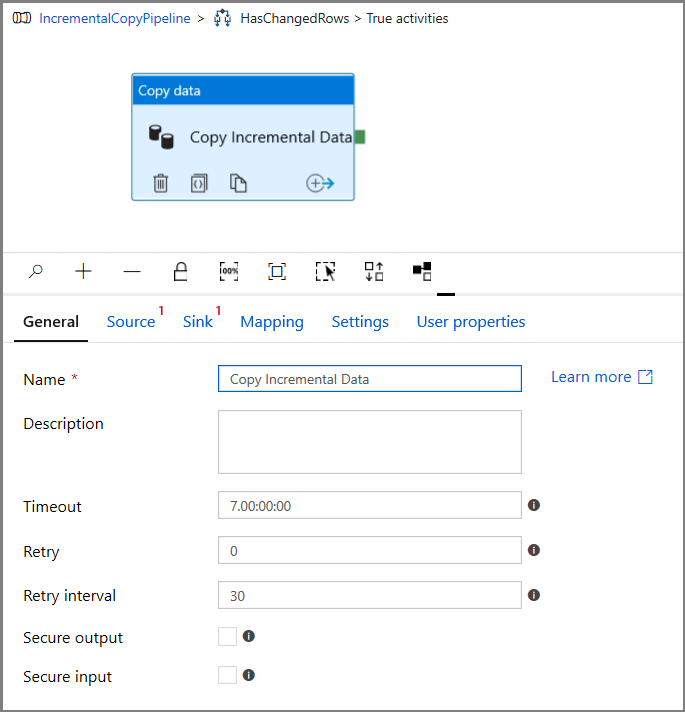
Passare alla scheda Origine nella finestra Proprietà e seguire questa procedura:
Specificare il nome del set di dati dell'istanza gestita di SQL per il campo Set di dati di origine.
Selezionare Query per Use Query (Usa query).
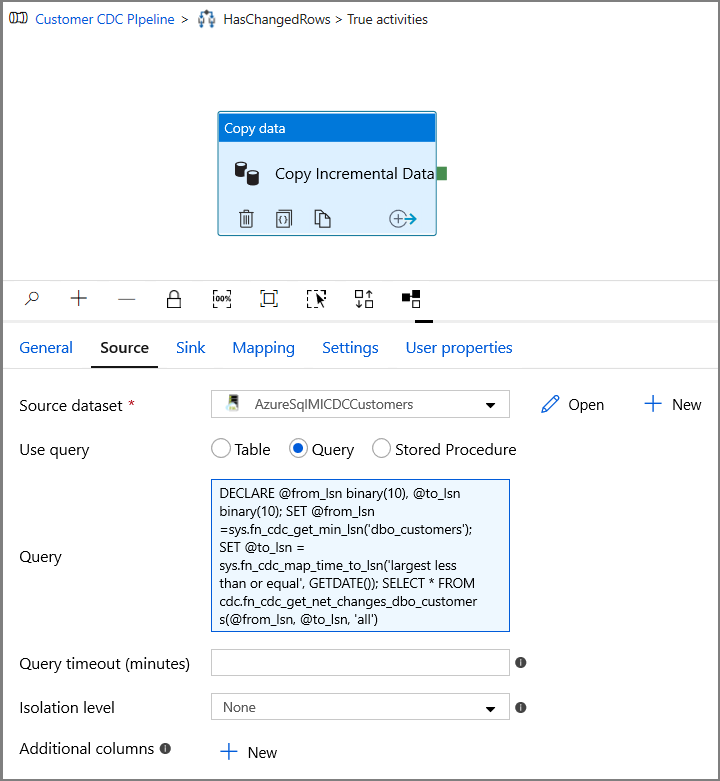
In Query immettere quanto segue.
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
Fare clic su Anteprima per verificare che la query restituisca correttamente le righe modificate.
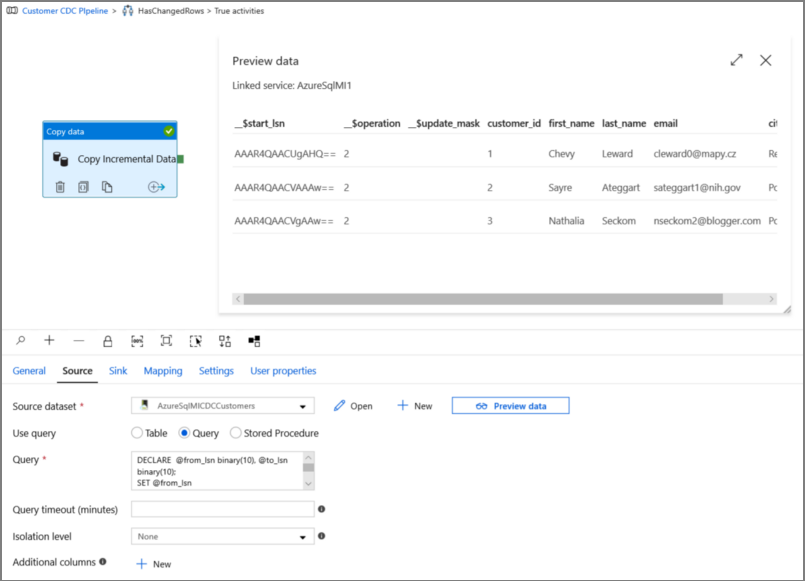
Passare alla scheda Sink e specificare il set di dati di archiviazione di Azure per il campo Set di dati sink.

Fare clic per tornare all'area di disegno della pipeline principale e connettere l'attività Ricerca all'attività Condizione if una alla volta. Trascinare il pulsante verde associato all'attività Ricerca sull'attività Condizione if.
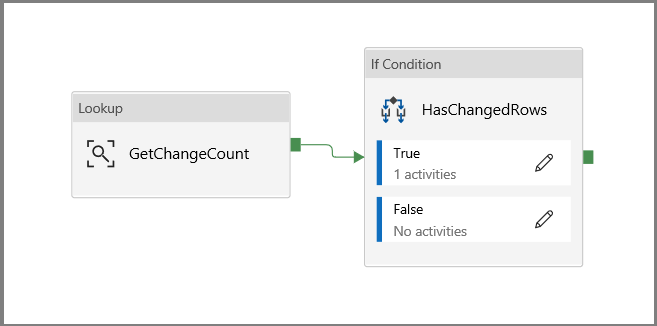
Fare clic su Convalida sulla barra degli strumenti. Verificare che non siano presenti errori di convalida. Chiudere la finestra del report di convalida della pipeline facendo clic su >>.
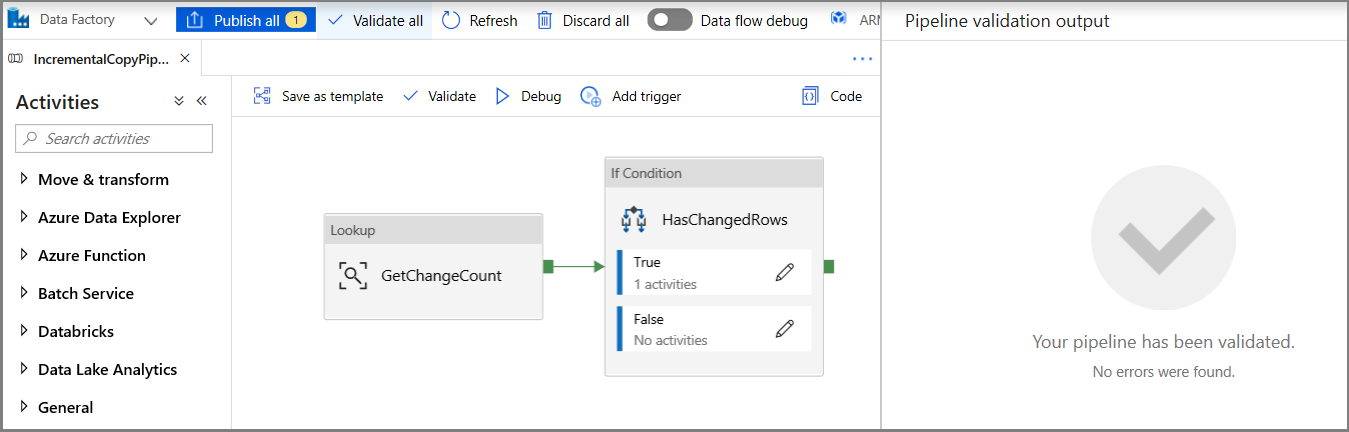
Fare clic su Debug per testare la pipeline e verificare che nella posizione di archiviazione sia stato generato un file.
Per pubblicare le entità (servizi collegati, set di dati e pipeline) nel servizio Data Factory, fare clic sul pulsante Pubblica tutti. Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita.
Configurare il trigger di finestra a cascata e i parametri della finestra di Change Data Capture
In questo passaggio verrà creato un trigger di finestra a cascata per eseguire il processo in base a una pianificazione frequente. Verranno usate le variabili di sistema WindowStart e WindowEnd del trigger di finestra a cascata che saranno passate come parametri alla pipeline da usare nella query di Change Data Capture.
Passare alla scheda Parametri della pipeline IncrementalCopyPipeline e usare il pulsante + Nuovo per aggiungere alla pipeline due parametri (triggerStartTime e triggerEndTime), che rappresenteranno l'ora di inizio e di fine della finestra a cascata. Ai fini del debug, aggiungere i valori predefiniti nel formato AAAA-MM-GG HH24:MI:SS.FFF e assicurarsi che triggerStartTime non sia precedente all'ora di abilitazione di Change Data Capture nella tabella, perché in caso contrario verrà generato un errore.
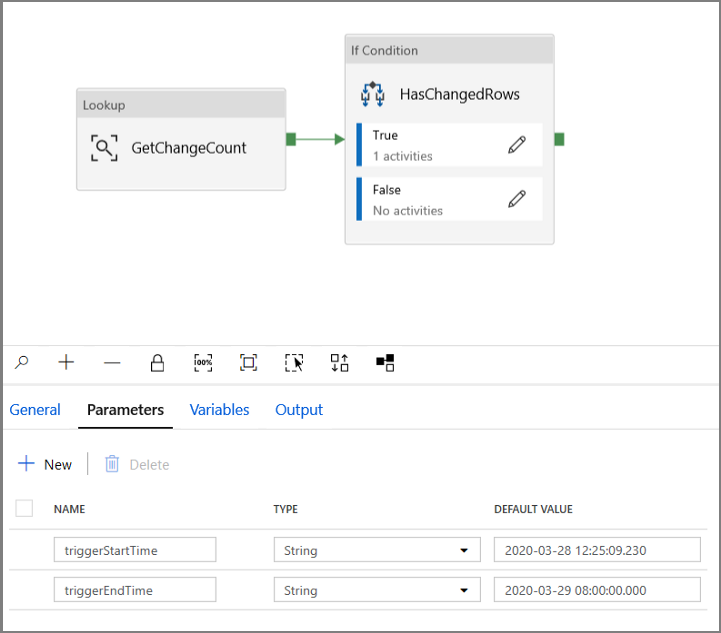
Fare clic sulla scheda Impostazioni dell'attività Ricerca e configurare la query per l'utilizzo dei parametri relativi all'ora iniziale e all'ora finale. Copiare quanto segue nella query:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Passare all'attività Copia nel caso True dell'attività Condizione If e fare clic sulla scheda Origine . Copiare quanto segue nella query:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Fare clic sulla scheda Sink dell'attività Copia e fare clic su Apri per modificare le proprietà del set di dati. Fare clic sulla scheda Parametri e aggiungere un nuovo parametro denominato triggerStart
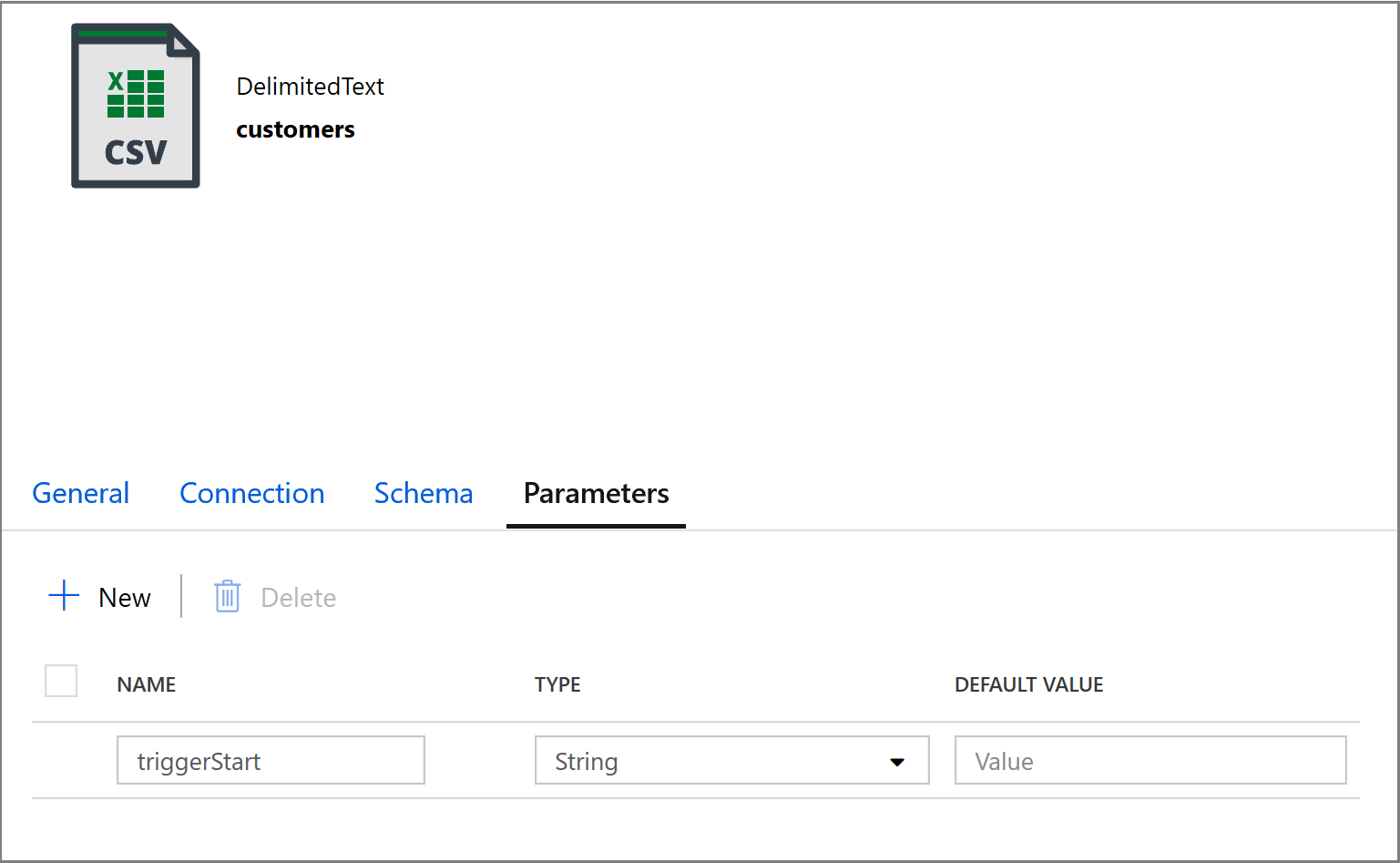
Configurare quindi le proprietà del set di dati per archiviare i dati in una sottodirectory customers/incremental con le partizioni basate su data.
Fare clic sulla scheda Connessione delle proprietà del set di dati e aggiungere contenuto dinamico per le sezioni Directory e File.
Immettere l'espressione seguente nella sezione Directory facendo clic sul collegamento al contenuto dinamico nella casella di testo:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Immettere l'espressione seguente nella sezione File. In questo modo i nomi dei file verranno creati in base alla data e all'ora di inizio del trigger, a cui verrà aggiunto un suffisso con l'estensione csv:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')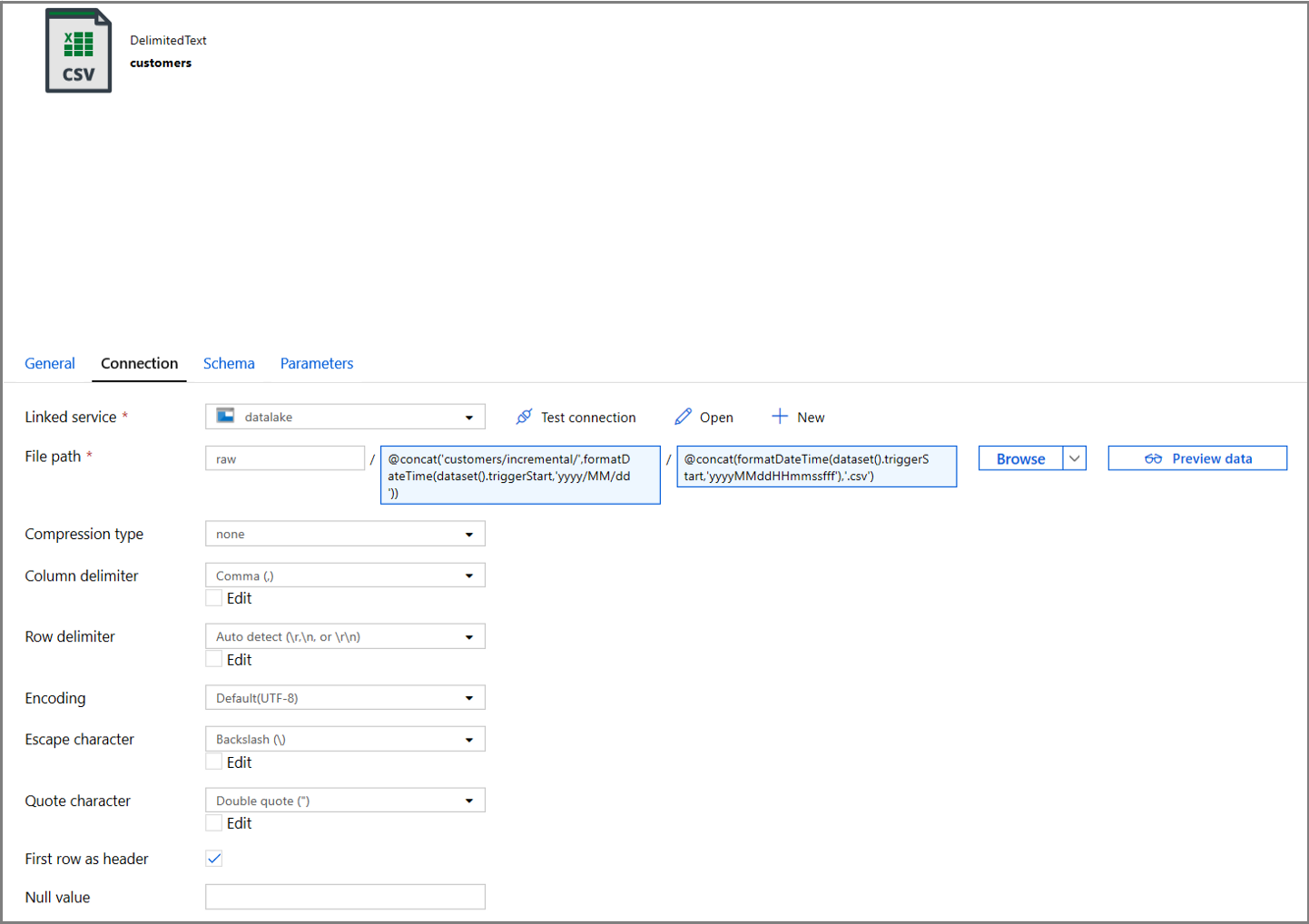
Tornare alle impostazioni del Sink nell'attività Copia facendo clic sulla scheda IncrementalCopyPipeline.
Espandere le proprietà del set di dati e immettere il contenuto dinamico nel valore del parametro triggerStart con l'espressione seguente:
@pipeline().parameters.triggerStartTime
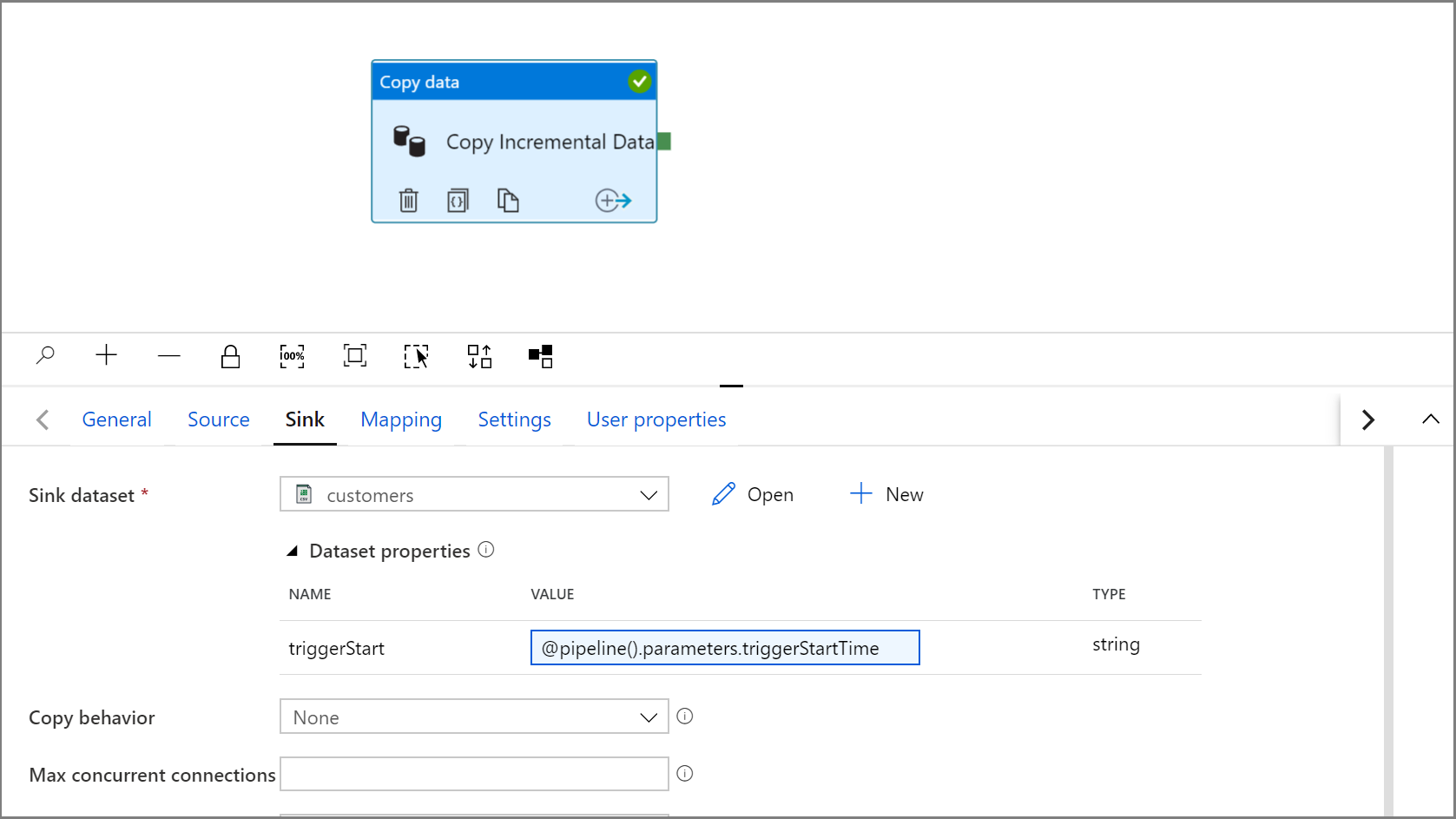
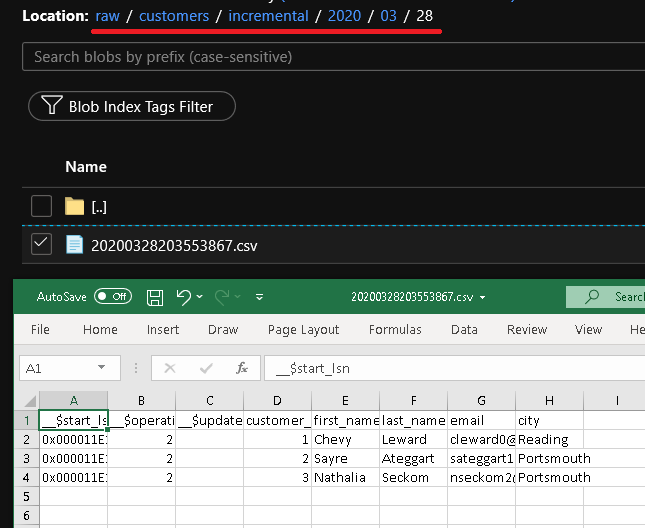
Fare clic su Debug per testare la pipeline e verificare che la struttura di cartelle e il file di output vengano generati come previsto. Scaricare e aprire il file per verificarne il contenuto.
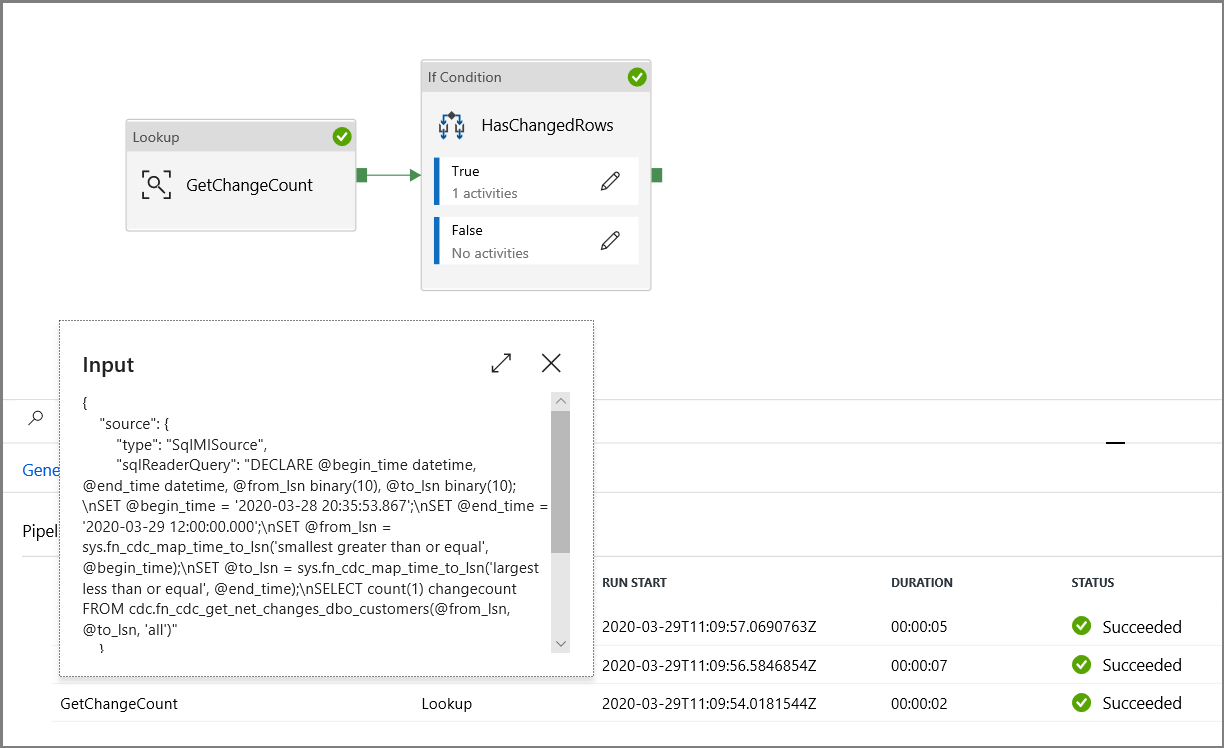
Verificare che i parametri vengano inseriti nella query esaminando i parametri di input dell'esecuzione della pipeline.
Per pubblicare le entità (servizi collegati, set di dati e pipeline) nel servizio Data Factory, fare clic sul pulsante Pubblica tutti. Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita.
Infine, configurare un trigger di finestra a cascata per eseguire la pipeline a intervalli regolari e impostare i parametri dell'ora di inizio e di fine.
- Fare clic sul pulsante Aggiungi trigger e selezionare Nuova/Modifica
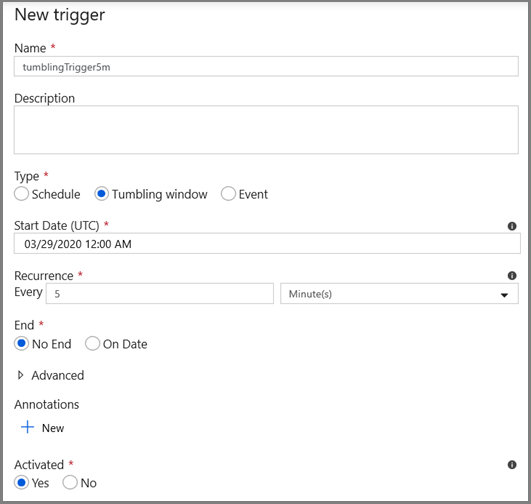
- Immettere un nome di trigger e specificare un'ora di inizio, che è uguale all'ora di fine della finestra di debug precedente.
Nella schermata successiva specificare rispettivamente i valori seguenti per i parametri di inizio e di fine.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')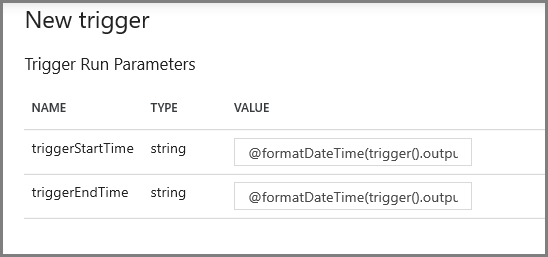
Nota
Il trigger verrà eseguito solo dopo la pubblicazione. Inoltre, il comportamento previsto della finestra a cascata prevede l'esecuzione di tutti gli intervalli cronologici dalla data di inizio fino a questo momento. Altre informazioni sui trigger di finestra a cascata sono disponibili qui.
In SQL Server Management Studio apportare alcune modifiche aggiuntive alla tabella customer eseguendo il codice SQL seguente:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Fare clic sul pulsante Pubblica tutti. Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita.
Dopo alcuni minuti la pipeline sarà stata attivata e un nuovo file sarà stato caricato in Archiviazione di Azure
Monitorare la pipeline di copia incrementale
Fare clic sulla scheda Monitoraggio a sinistra. L'esecuzione della pipeline verrà visualizzata nell'elenco con il relativo stato. Per aggiornare l'elenco, fare clic su Aggiorna. Passare il puntatore del mouse accanto al nome della pipeline per accedere all'azione Riesegui e al report sull'utilizzo.
Per visualizzare le esecuzioni attività associate a questa esecuzione della pipeline, fare clic sul nome della pipeline. Se sono stati rilevati dati modificati, saranno presenti tre attività, inclusa l'attività di copia, in caso contrario saranno presenti solo due voci nell'elenco. Per tornare alla visualizzazione delle esecuzioni di pipeline, fare clic sul collegamento Tutte le pipeline in alto.
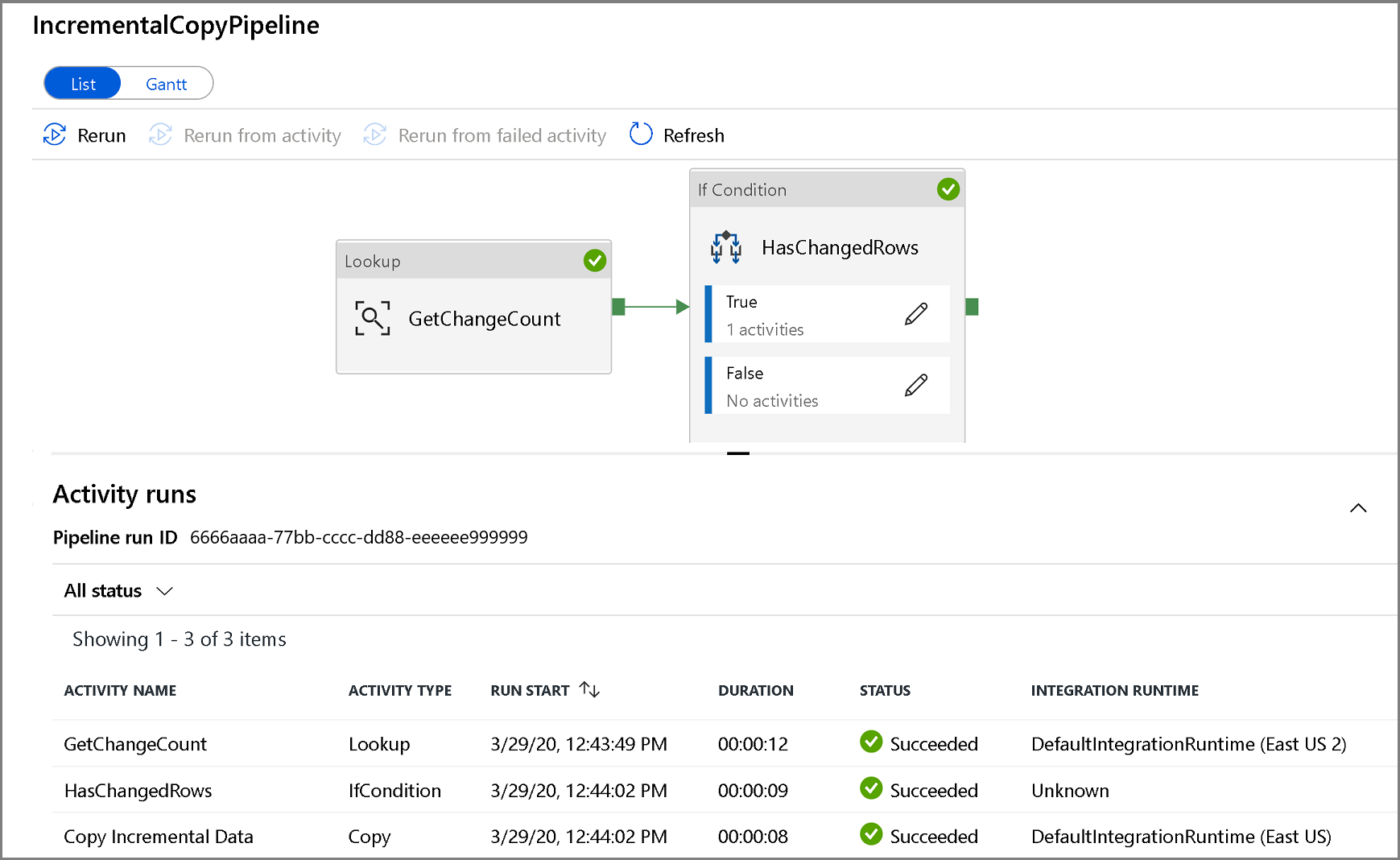
Esaminare i risultati
Il secondo file viene visualizzato nella cartella customers/incremental/YYYY/MM/DD del contenitore raw.
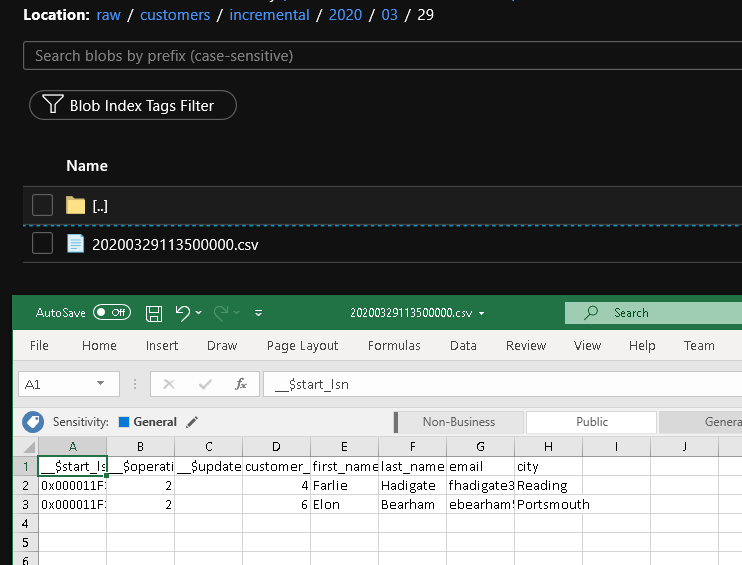
Contenuto correlato
Passare all'esercitazione successiva per informazioni sulla copia di file nuovi e modificati solo in base a LastModifiedDate: