Procedure consigliate per la scrittura in file in data lake con flussi di dati
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Se non si ha familiarità con Azure Data Factory, vedere Introduzione ad Azure Data Factory.
In questa esercitazione verranno illustrate le procedure consigliate che possono essere applicate durante la scrittura di file in ADLS Gen2 o Archiviazione BLOB di Azure usando i flussi di dati. È necessario accedere a un account Archiviazione BLOB di Azure o azure Data Lake Store Gen2 per leggere un file Parquet e quindi archiviare i risultati nelle cartelle.
Prerequisiti
- Sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account Azure gratuito prima di iniziare.
- Account di archiviazione di Azure. Usare l'archivio ADSL come archivi dati di origine e sink. Se non si ha un account di archiviazione, vedere Creare un account di archiviazione di Azure per informazioni su come crearne uno.
I passaggi di questa esercitazione presuppongono che l'utente abbia
Creare una data factory
In questo passaggio si crea una data factory e si apre l'esperienza utente di Data Factory per creare una pipeline nella data factory.
Aprire Microsoft Edge o Google Chrome. L'interfaccia utente di Data Factory è attualmente supportata solo nei Web browser Microsoft Edge e Google Chrome.
Nel menu sinistro selezionare Crea una risorsa>Integrazione>Data factory
Nella pagina Nuova data factory immettere ADFTutorialDataFactory in Nome
Selezionare la sottoscrizione di Azure in cui creare la data factory.
In Gruppo di risorse eseguire una di queste operazioni:
a. Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
b. Selezionare Crea nuovo e immettere il nome di un gruppo di risorse. Per informazioni sui gruppi di risorse, vedere Usare i gruppi di risorse per gestire le risorse di Azure.
In Versione selezionare V2.
In Località selezionare una località per la data factory. Nell'elenco a discesa vengono mostrate solo le località supportate. Archivi dati (ad esempio, Archiviazione di Azure e il database SQL) e risorse di calcolo (ad esempio, Azure HDInsight) usati dalla data factory possono trovarsi in altre aree.
Seleziona Crea.
Al termine della creazione, la relativa notifica verrà visualizzata nel centro notifiche. Selezionare Vai alla risorsa per passare alla pagina della data factory.
Selezionare Crea e monitora per avviare l'interfaccia utente di Data Factory in una scheda separata.
Creare una pipeline con un'attività Flusso di dati
In questo passaggio si creerà una pipeline che contiene un'attività del flusso di dati.
Nella home page di Azure Data Factory selezionare Orchestrate .On the home page of Azure Data Factory, select Orchestrate.
Nella scheda Generale per la pipeline immettere DeltaLake per Nome della pipeline.
Nella barra superiore della factory scorrere il dispositivo di scorrimento Flusso di dati debug. La modalità di debug consente il test interattivo della logica di trasformazione rispetto a un cluster Spark live. L’avvio dei cluster Flusso di dati impiega 5-7 minuti e si consiglia di attivare prima il debug se si pianifica lo sviluppo del flusso di dati. Per altre informazioni, vedere Modalità di debug.

Nel riquadro Attività espandere l’accordion Sposta e trasforma. Trascinare e rilasciare l'attività Flusso di dati dal riquadro all'area di disegno della pipeline.
Nel popup Aggiungere flusso di dati selezionare Crea nuovo flusso di dati e assegnare al flusso di dati il nome DeltaLake. Fare clic su Fine al termine.
Compilare la logica di trasformazione nel canvas del flusso di dati
Verranno accettati dati di origine (in questa esercitazione si userà un'origine file Parquet) e si userà una trasformazione sink per trasferire i dati in formato Parquet usando i meccanismi più efficaci per data lake ETL.

Obiettivi dell'esercitazione
- Scegliere uno dei set di dati di origine in un nuovo flusso di dati 1. Usare i flussi di dati per partizionare in modo efficace il set di dati sink
- Trasferire i dati partizionati nelle cartelle di ADLS Gen2 Lake
Iniziare da un'area di disegno del flusso di dati vuota
Prima di tutto, configurare l'ambiente del flusso di dati per ognuno dei meccanismi descritti di seguito per i dati di destinazione in ADLS Gen2
- Fare clic sulla trasformazione di origine.
- Fare clic sul nuovo pulsante accanto al set di dati nel pannello inferiore.
- Scegliere un set di dati o crearne uno nuovo. Per questa demo si userà un set di dati Parquet denominato Dati utente.
- Aggiungere una trasformazione Colonna derivata. Verrà usato come modo per impostare i nomi delle cartelle desiderati in modo dinamico.
- Aggiungere una trasformazione sink.
Output della cartella gerarchica
È molto comune usare valori univoci nei dati per creare gerarchie di cartelle per partizionare i dati nel lake. Si tratta di un modo molto ottimale per organizzare ed elaborare i dati nel lake e in Spark (il motore di calcolo dietro i flussi di dati). Tuttavia, ci sarà un costo ridotto per le prestazioni per organizzare l'output in questo modo. Prevedere una riduzione ridotta delle prestazioni complessive della pipeline usando questo meccanismo nel sink.
- Tornare alla finestra di progettazione del flusso di dati e modificare il flusso di dati creato in precedenza. Fare clic sulla trasformazione sink.
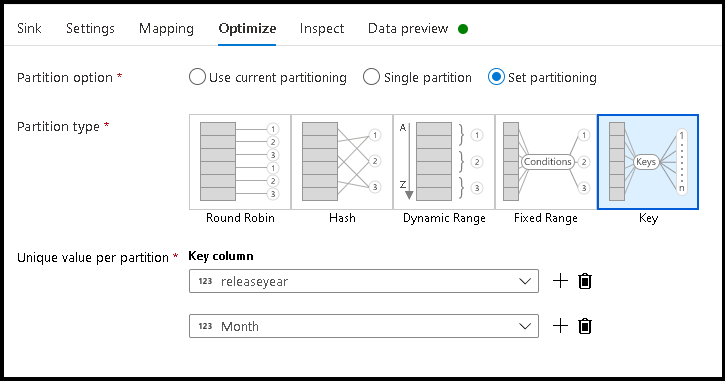
- Fare clic su Ottimizza > imposta chiave di > partizionamento
- Selezionare le colonne da usare per impostare la struttura di cartelle gerarchica.
- Si noti che l'esempio seguente usa year e month come colonne per la denominazione delle cartelle. I risultati saranno cartelle del modulo
releaseyear=1990/month=8. - Quando si accede alle partizioni di dati in un'origine del flusso di dati, si punterà solo alla cartella di primo livello precedente
releaseyeare si userà un criterio con caratteri jolly per ogni cartella successiva, ad esempio:**/**/*.parquet - Per modificare i valori dei dati o anche se è necessario generare valori sintetici per i nomi delle cartelle, usare la trasformazione Colonna derivata per creare i valori da usare nei nomi delle cartelle.
Cartella nome come valori di dati
Una tecnica sink con prestazioni leggermente migliori per i dati lake tramite ADLS Gen2 che non offre lo stesso vantaggio del partizionamento chiave/valore, è Name folder as column data. Mentre lo stile di partizionamento delle chiavi della struttura gerarchica consentirà di elaborare più facilmente le sezioni di dati, questa tecnica è una struttura di cartelle bidimensionale in grado di scrivere più rapidamente i dati.
- Tornare alla finestra di progettazione del flusso di dati e modificare il flusso di dati creato in precedenza. Fare clic sulla trasformazione sink.
- Fare clic su Ottimizza > set di partizionamento > Usa partizionamento corrente.
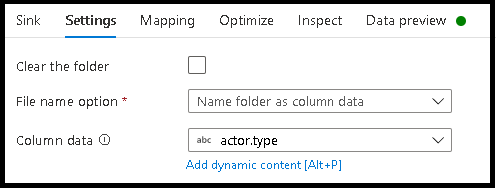
- Fare clic su Cartella Nome impostazioni > come dati di colonna.
- Selezionare la colonna da usare per generare nomi di cartelle.
- Per modificare i valori dei dati o anche se è necessario generare valori sintetici per i nomi delle cartelle, usare la trasformazione Colonna derivata per creare i valori da usare nei nomi delle cartelle.
Nome file come valori di dati
Le tecniche elencate nelle esercitazioni precedenti sono casi d'uso validi per la creazione di categorie di cartelle nel data lake. Lo schema di denominazione dei file predefinito usato da queste tecniche consiste nell'usare l'ID processo dell'executor Spark. A volte è possibile impostare il nome del file di output in un sink di testo del flusso di dati. Questa tecnica è consigliata solo per l'uso con file di piccole dimensioni. Il processo di unione dei file di partizione in un singolo file di output è un processo a esecuzione prolungata.
- Tornare alla finestra di progettazione del flusso di dati e modificare il flusso di dati creato in precedenza. Fare clic sulla trasformazione sink.
- Fare clic su Ottimizza > imposta partizionamento > singola. Si tratta di questo requisito di singola partizione che crea un collo di bottiglia nel processo di esecuzione man mano che i file vengono uniti. Questa opzione è consigliata solo per i file di piccole dimensioni.
- Fare clic su File nome impostazioni > come dati di colonna.
- Selezionare la colonna da usare per generare nomi di file.
- Per modificare i valori dei dati o anche se è necessario generare valori sintetici per i nomi di file, usare la trasformazione Colonna derivata per creare i valori da usare nei nomi di file.
Contenuto correlato
Altre informazioni sui sink del flusso di dati.