Trasformare i dati in delta lake con i flussi di dati per mapping
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Se non si ha familiarità con Azure Data Factory, vedere Introduzione ad Azure Data Factory.
In questa esercitazione si usa l'area di disegno del flusso di dati per creare flussi di dati che consentono di analizzare e trasformare i dati in Azure Data Lake Storage (ADLS) Gen2 e archiviarli in Delta Lake.
Prerequisiti
- Sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account Azure gratuito prima di iniziare.
- Account di archiviazione di Azure. Usare l'archivio ADSL come archivi dati di origine e sink. Se non si ha un account di archiviazione, vedere Creare un account di archiviazione di Azure per informazioni su come crearne uno.
Il file che si sta trasformando in questa esercitazione è MoviesDB.csv, disponibile qui. Per recuperare il file da GitHub, copiare il contenuto in un editor di testo di propria scelta per salvare localmente come file .csv. Per caricare il file nell'account di archiviazione, vedere Caricare BLOB con il portale di Azure. Gli esempi fanno riferimento a un contenitore denominato "sample-data".
Creare una data factory
In questo passaggio si crea una data factory e si apre l'esperienza utente di Data Factory per creare una pipeline nella data factory.
Aprire Microsoft Edge o Google Chrome. L'interfaccia utente di Data Factory è attualmente supportata solo nei Web browser Microsoft Edge e Google Chrome.
Nel menu sinistro selezionare Crea una risorsa>Integrazione>Data factory
Nella pagina Nuova data factory immettere ADFTutorialDataFactory in Nome
Selezionare la sottoscrizione di Azure in cui creare la data factory.
In Gruppo di risorse eseguire una di queste operazioni:
a. Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
b. Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo su come usare gruppi di risorse per gestire le risorse di Azure.
In Versione selezionare V2.
In Località selezionare una località per la data factory. Nell'elenco a discesa vengono mostrate solo le località supportate. Archivi dati (ad esempio, Archiviazione di Azure e il database SQL) e risorse di calcolo (ad esempio, Azure HDInsight) usati dalla data factory possono trovarsi in altre aree.
Seleziona Crea.
Al termine della creazione, la relativa notifica verrà visualizzata nel centro notifiche. Selezionare Vai alla risorsa per passare alla pagina della data factory.
Selezionare Crea e monitora per avviare l'interfaccia utente di Data Factory in una scheda separata.
Creare una pipeline con un'attività Flusso di dati
In questo passaggio si crea una pipeline che contiene un'attività del flusso di dati.
Nella home page selezionare Esegui orchestrazione.
Nella scheda Generale per la pipeline immettere DeltaLake per Nome della pipeline.
Nel riquadro Attività espandere l’accordion Sposta e trasforma. Trascinare e rilasciare l'attività Flusso di dati dal riquadro all'area di disegno della pipeline.
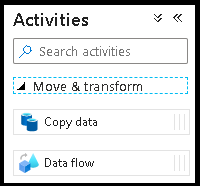
Nel popup Aggiungere flusso di dati selezionare Crea nuovo flusso di dati e assegnare al flusso di dati il nome DeltaLake. Al termine, selezionare Fine.
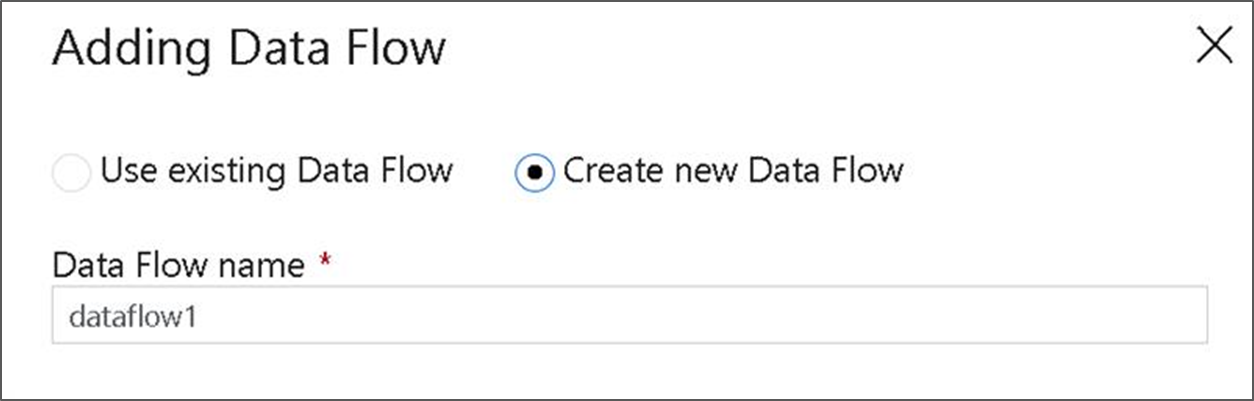
Nella barra superiore dell'area di disegno della pipeline scorrere il dispositivo di scorrimento Debug del flusso di dati. La modalità di debug consente il test interattivo della logica di trasformazione rispetto a un cluster Spark live. L’avvio dei cluster Flusso di dati impiega 5-7 minuti e si consiglia di attivare prima il debug se si pianifica lo sviluppo del flusso di dati. Per altre informazioni, vedere Modalità di debug.

Compilare la logica di trasformazione nel canvas del flusso di dati
In questa esercitazione vengono generati due flussi di dati. Il primo flusso di dati è un'origine semplice da sink per generare un nuovo Delta Lake dal file CSV dei film. Infine, si crea la progettazione del flusso che segue per aggiornare i dati in Delta Lake.

Obiettivi dell'esercitazione
- Usare l'origine del set di dati MoviesCSV dai prerequisiti e formare un nuovo Delta Lake.
- Creare la logica per aggiornare le classificazioni per i film del 1988 a '1'.
- Eliminare tutti i film dal 1950.
- Inserire nuovi film per il 2021 duplicando i film dal 1960.
Iniziare da un'area di disegno del flusso di dati vuota
Selezionare la trasformazione di origine nella parte superiore della finestra dell'editor del flusso di dati e quindi selezionare + Nuovo accanto alla proprietà Set di dati nella finestra Impostazioni origine:
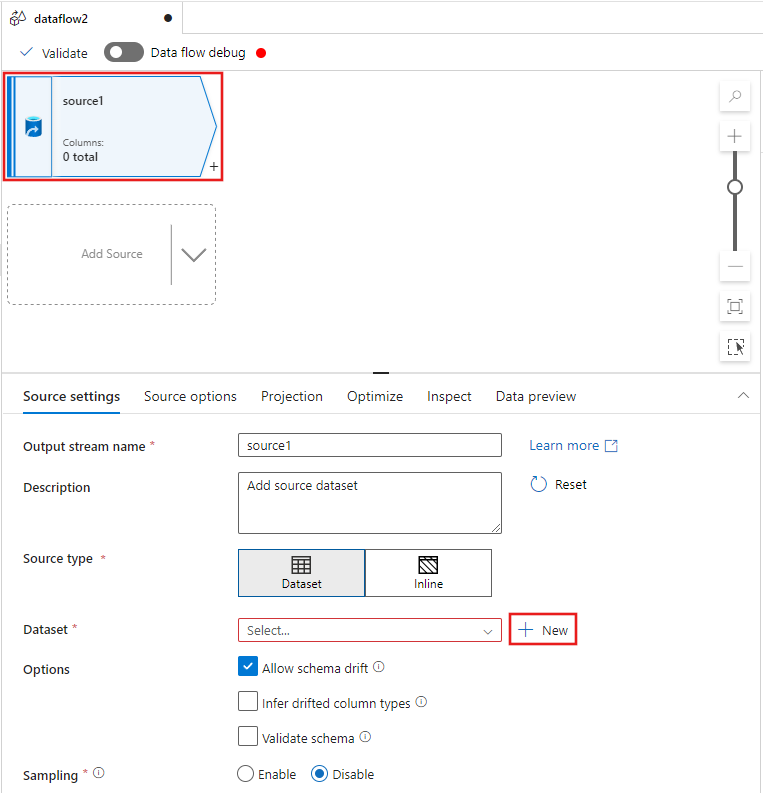
Selezionare Azure Data Lake Storage Gen2 nella finestra Nuovo set di dati visualizzato e quindi selezionare Continua.
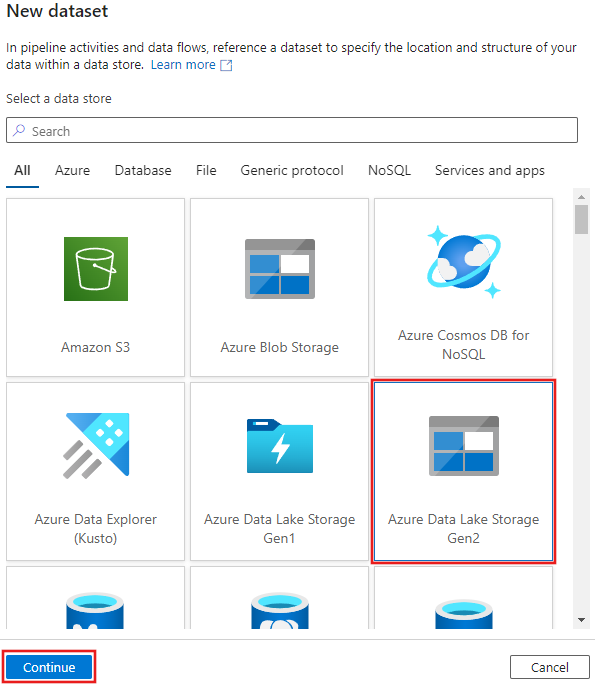
Scegliere DelimitedText per il tipo di set di dati e selezionare di nuovo Continua.

Assegnare al set di dati il nome “MoviesCSV” e selezionare + Nuovo in Servizio collegato per creare un nuovo servizio collegato al file.
Specificare i dettagli per l'account di archiviazione creato in precedenza nella sezione Prerequisiti e selezionare il file MoviesCSV caricato.
Dopo aver aggiunto il servizio collegato, selezionare la casella di controllo Prima riga come intestazione, quindi selezionare OK per aggiungere l'origine.
Passare alla scheda Proiezione della finestra delle impostazioni del flusso di dati e quindi selezionare Rilevare i tipi di dati.
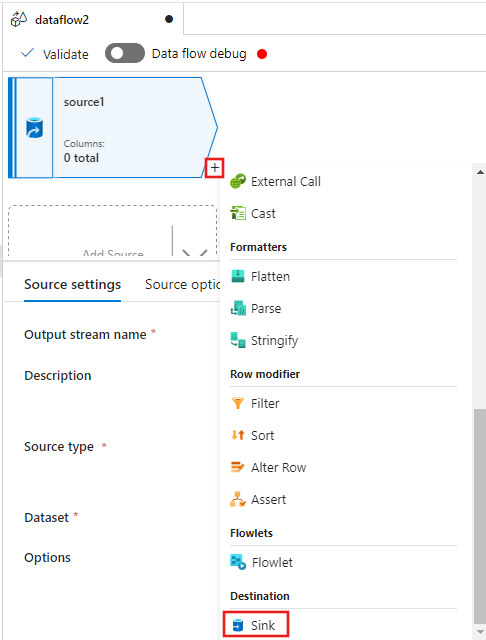
Selezionare ora il + dopo l'origine nella finestra dell'editor del flusso di dati e scorrere verso il basso per selezionare Sink nella sezione Destinazione, aggiungendo un nuovo sink al flusso di dati.
Nella scheda Sink per le impostazioni sink visualizzate dopo l'aggiunta del sink selezionare Inline per il tipo di sinke quindi Delta per il tipo di set di dati inline. Selezionare quindi Azure Data Lake Storage Gen2 per il servizio collegato.
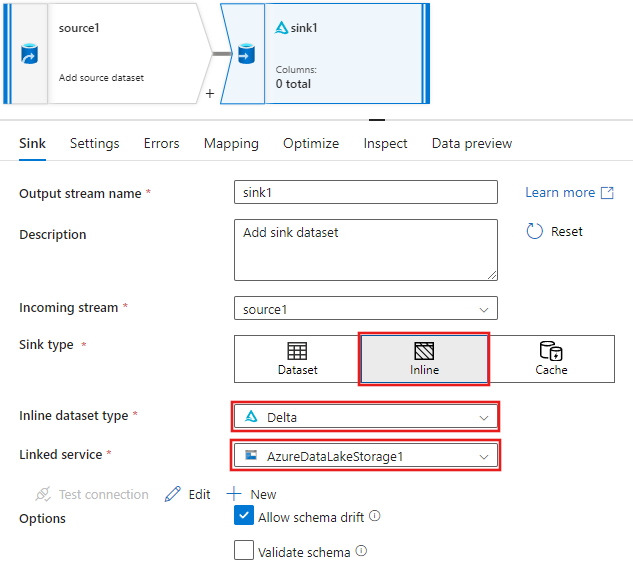
Scegliere un nome di cartella nel contenitore di archiviazione in cui si vuole creare il servizio Delta Lake.
Infine, tornare alla finestra di progettazione della pipeline e selezionare Debug per eseguire la pipeline in modalità di debug con solo questa attività del flusso di dati nell'area di disegno. Questo genera il nuovo Delta Lake in Azure Data Lake Storage Gen2.
A questo momento, dal menu Risorse factory a sinistra della schermata selezionare + per aggiungere una nuova risorsa e quindi selezionare Flusso di dati.
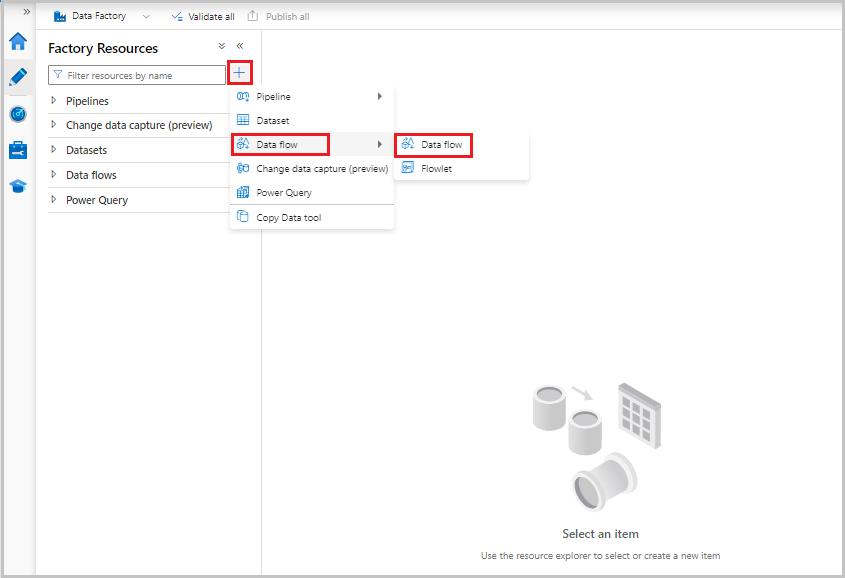
Come in precedenza, selezionare di nuovo il file MoviesCSV come origine e quindi selezionare Rileva tipi di dati di nuovo nella scheda Proiezione.
Questa volta, dopo aver creato l'origine, selezionare il + nella finestra dell'editor del flusso di dati e aggiungere una trasformazione Filtro all'origine.
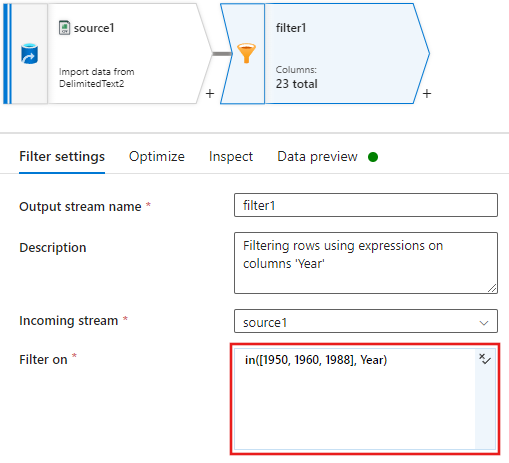
Aggiungere una condizione Filtra per condizione nella finestra Impostazioni filtro che consente solo le righe di film corrispondenti a 1950, 1960 e 1988.
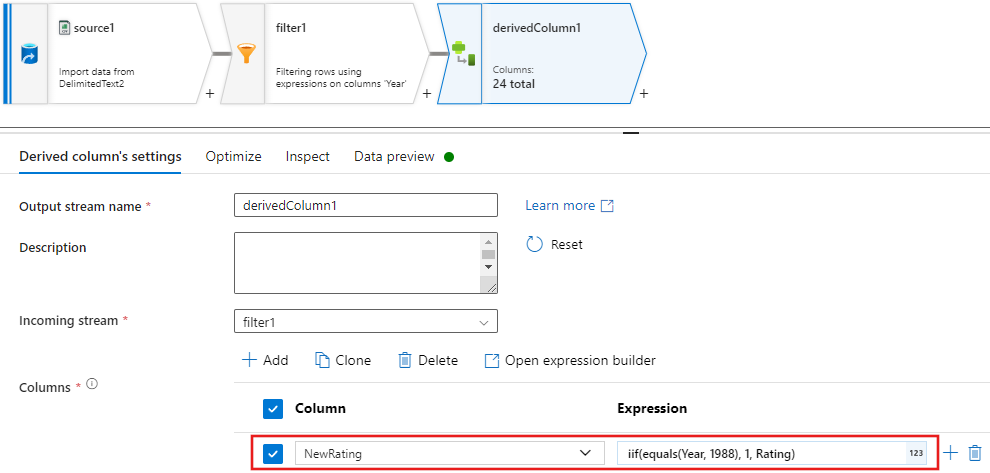
Aggiungere ora una trasformazione colonna derivata per aggiornare le classificazioni per ogni film del 1988 a '1'.
Update, insert, delete, and upsertcriteri vengono creati nella trasformazione alter Row. Aggiungere una trasformazione alter row dopo la colonna derivata.I criteri di modifica delle righe dovrebbero essere simili al seguente.

Dopo aver impostato i criteri appropriati per ogni tipo di riga di modifica, verificare che le regole di aggiornamento appropriate siano state impostate nella trasformazione sink
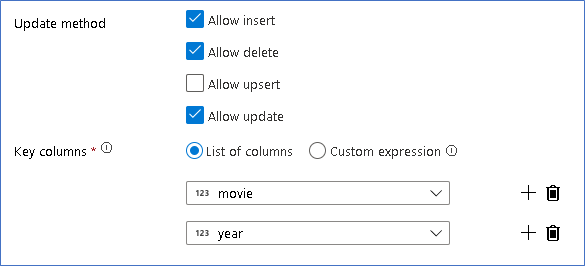
In questo caso si usa il sink Delta Lake nel data lake di Azure Data Lake Storage Gen2 e vengono consentiti inserimenti, aggiornamenti ed eliminazioni.
Si noti che le colonne chiave sono una chiave composta costituita dalla colonna chiave primaria Movie e dalla colonna anno. Questo è perché abbiamo creato film falsi 2021 duplicando le righe del 1960. In questo modo si evitano conflitti durante la ricerca delle righe esistenti fornendo un'univocità.
Scaricare l'esempio completato
Ecco una soluzione di esempio per la pipeline Delta con un flusso di dati per le righe di aggiornamento/eliminazione nel lake.
Contenuto correlato
Altre informazioni sul Linguaggio delle espressioni del flusso di dati.