Copiare più tabelle in blocco con Azure Data Factory nel portale di Azure
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questa esercitazione illustra come copiare alcune tabelle dal database SQL di Azure in Azure Synapse Analytics. È possibile applicare lo stesso modello anche in altri scenari di copia, ad esempio per la copia di tabelle da SQL Server/Oracle in database SQL di Azure/Azure Synapse Analytics/archivio BLOB di Azure o la copia di percorsi diversi dall'archivio BLOB alle tabelle del database SQL di Azure.
Nota
Se non si ha familiarità con Azure Data Factory, vedere Introduzione ad Azure Data Factory.
A livello generale, questa esercitazione prevede la procedura seguente:
- Creare una data factory.
- Creare i servizi collegati Database SQL di Azure, Azure Synapse Analytics e Archiviazione di Azure.
- Creare set di dati di Database SQL di Azure e Azure Synapse Analytics.
- Creare una pipeline per cercare le tabelle da copiare e un'altra pipeline per eseguire l'operazione di copia effettiva.
- Avviare un'esecuzione della pipeline.
- Monitorare le esecuzioni di pipeline e attività.
Questa esercitazione usa il portale di Azure. Per informazioni sull'uso di altri strumenti/SDK per creare una data factory, vedere le Guide introduttive.
Flusso di lavoro end-to-end
In questo scenario il database SQL di Azure include alcune tabelle da copiare in Azure Synapse Analytics. Ecco la sequenza logica di passaggi nel flusso di lavoro che si verifica nelle pipeline:

- La prima pipeline cerca l'elenco di tabelle da copiare negli archivi dati sink. In alternativa è possibile mantenere una tabella di metadati che elenca tutte le tabelle da copiare nell'archivio dati sink. La pipeline attiva quindi un'altra pipeline, che esegue l'iterazione di ogni tabella nel database ed esegue l'operazione di copia dei dati.
- La seconda pipeline esegue la copia effettiva. Accetta l'elenco di tabelle come parametro. Per ogni tabella dell'elenco è necessario copiare quella specifica di Database SQL di Azure in quella corrispondente di Azure Synapse Analytics usando una copia in fasi tramite archiviazione BLOB e PolyBase per prestazioni ottimali. In questo esempio la prima pipeline passa l'elenco di tabelle come valore per il parametro.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Account di archiviazione di Azure. L'account di archiviazione di Azure viene usato come archivio BLOB di staging nell'operazione di copia in blocco.
- Database SQL di Azure. Questo database contiene i dati di origine. Creare un database in Database SQL con i dati dell'esempio Adventure Works LT, seguendo l'articolo Creare un database in Database SQL di Azure. Questa esercitazione copia tutte le tabelle da questo database di esempio in Azure Synapse Analytics.
- Azure Synapse Analytics. Questo data warehouse include i dati copiati dal database SQL. Se non è disponibile un'area di lavoro di Azure Synapse Analytics, vedere l'articolo Introduzione ad Azure Synapse Analytics per la procedura per crearne una.
Accesso dei servizi di Azure a SQL Server
Per Database SQL e Azure Synapse Analytics, consentire ai servizi di Azure di accedere a SQL Server. Assicurarsi che l'impostazione Consenti alle risorse e ai servizi di Azure di accedere a questo server sia attivata (ON) per il server. Questa impostazione consente al servizio Data Factory di leggere dati da Database SQL di Azure e di scriverli in Azure Synapse Analytics.
Per verificare e attivare questa impostazione, passare al server > Firewall di sicurezza > e reti > virtuali impostare Consenti ai servizi e alle risorse di Azure di accedere a questo server su ON.
Creare una data factory
Avviare il Web browser Microsoft Edge o Google Chrome. L'interfaccia utente di Data Factory è attualmente supportata solo nei Web browser Microsoft Edge e Google Chrome.
Vai al portale di Azure.
A sinistra del menu del portale di Azure selezionare Crea una risorsa>Integrazione>Data factory.
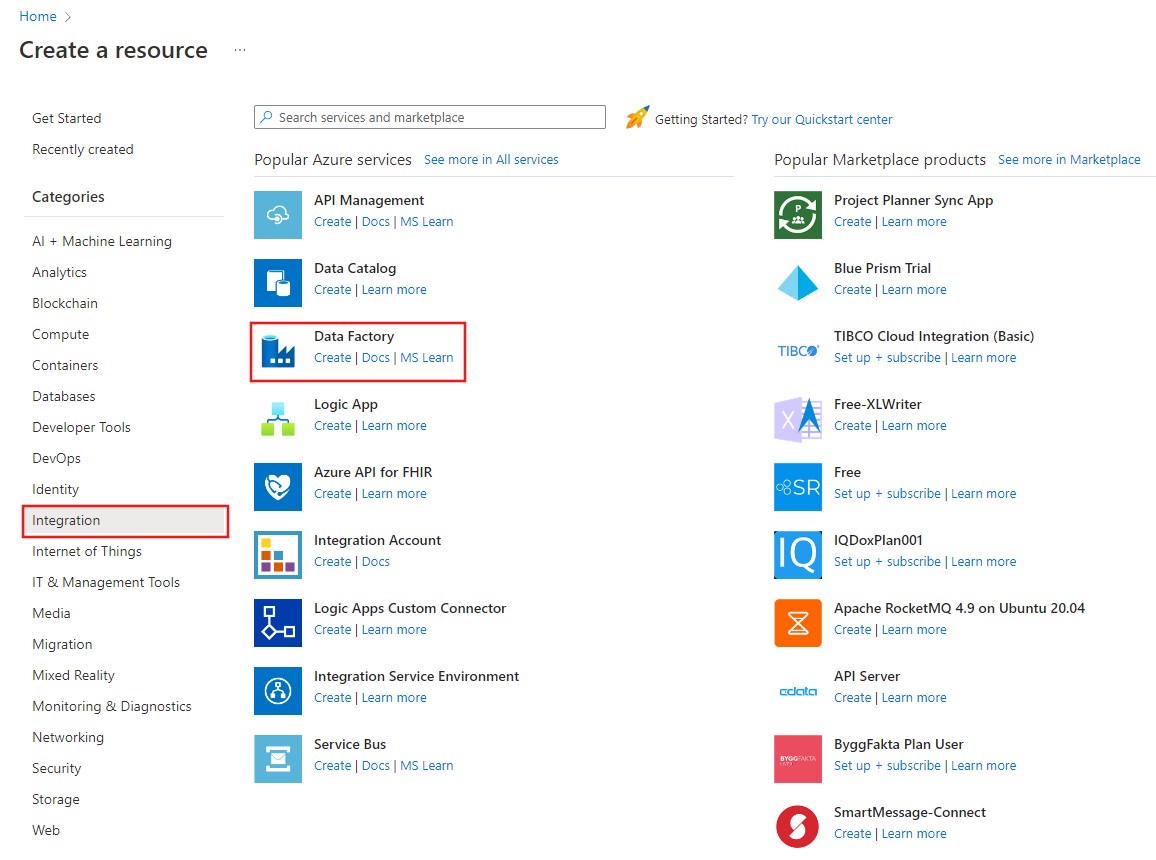
Nella pagina Nuova data factory immettere ADFTutorialBulkCopyDF per nome.
Il nome della data factory di Azure deve essere univoco a livello globale. Se viene visualizzato l'errore seguente per il campo Nome, modificare il nome della data factory, ad esempio, nomeutenteADFTutorialBulkCopyDF. Per informazioni sulle regole di denominazione per gli elementi di Data Factory, vedere l'articolo Data Factory - Regole di denominazione.
Data factory name "ADFTutorialBulkCopyDF" is not availableSelezionare la sottoscrizione di Azure in cui creare la data factory.
Per il gruppo di risorse, eseguire una di queste operazioni:
Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo relativo all'uso di gruppi di risorse per la gestione delle risorse di Azure.
Selezionare V2 per version.
Selezionare la località per la data factory. Per un elenco di aree di Azure in cui Data Factory è attualmente disponibile, selezionare le aree di interesse nella pagina seguente, quindi espandere Analytics per individuare Data Factory: Prodotti disponibili in base all'area. Gli archivi dati (Archiviazione di Azure, database SQL di Azure e così via) e le risorse di calcolo (HDInsight e così via) usati dalla data factory possono trovarsi in altre aree.
Cliccare su Crea.
Al termine della creazione, selezionare Vai alla risorsa per passare alla pagina Data Factory.
Selezionare Apri nel riquadro Apri Azure Data Factory Studio per avviare l'applicazione dell'interfaccia utente di Data Factory in una scheda separata.
Creare servizi collegati
Si creano servizi collegati per collegare gli archivi dati e le risorse di calcolo a una data factory. Un servizio collegato include le informazioni di connessione usate dal servizio Data Factory per connettersi all'archivio dati in fase di esecuzione.
In questa esercitazione gli archivi dati del database SQL di Azure, di Azure Synapse Analytics e dell'Archiviazione BLOB di Azure vengono collegati alla data factory. Il database SQL di Azure è l'archivio dati di origine. Azure Synapse Analytics è l'archivio dati del sink/di destinazione. L'Archiviazione BLOB di Azure consente di eseguire lo staging dei dati prima del caricamento dei dati in Azure Synapse Analytics tramite PolyBase.
Creare il servizio collegato database SQL di Azure di origine
In questo passaggio viene creato un servizio per collegare il database in Database SQL di Azure alla data factory.
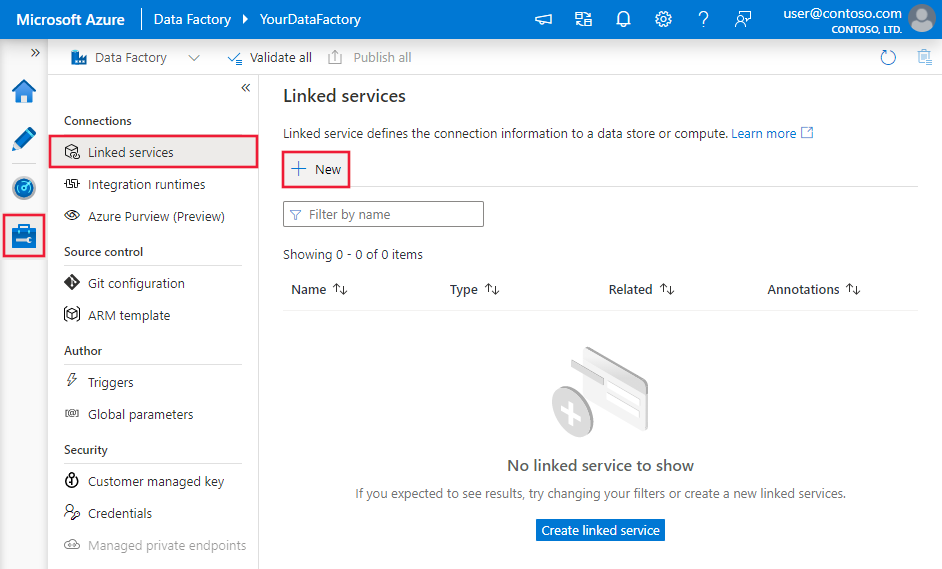
Aprire la scheda Gestisci nel riquadro sinistro.
Nella pagina Servizi collegati selezionare +Nuovo per creare un nuovo servizio collegato.
Nella finestra New Linked Service (Nuovo servizio collegato) selezionare Database SQL di Azure e fare clic su Continua.
Nella finestra New Linked Service (Azure SQL Database) (Nuovo servizio collegato - Database SQL di Azure), procedere come segue:
a. Immettere AzureSqlDatabaseLinkedService per Nome.
b. Selezionare il server per Nome server
c. Selezionare il database nel campo Nome database.
d. Immettere il nome dell'utente da connettere al database.
e. Immettere la password per l'utente.
f. Per testare la connessione al database con le informazioni specificate, fare clic su Test connessione.
g. Fare clic su Crea per salvare il servizio collegato.
Creare il servizio collegato del sink di Azure Synapse Analytics
Nella scheda Connessioni fare di nuovo clic su + Nuovo sulla barra degli strumenti.
Nella finestra New Linked Service (Nuovo servizio collegato) selezionare Azure Synapse Analytics e fare clic su Continua.
Nella finestra New Linked Service (Azure Synapse Analytics) (Nuovo servizio collegato - Azure Synapse Analytics), procedere come segue:
a. Immettere AzureSqlDWLinkedService per Nome.
b. Selezionare il server per Nome server
c. Selezionare il database nel campo Nome database.
d. Immettere il Nome utente da connettere al database.
e. Immettere la Password per l'utente.
f. Per testare la connessione al database con le informazioni specificate, fare clic su Test connessione.
g. Cliccare su Crea.
Creare il servizio collegato di staging Archiviazione di Azure
In questa esercitazione l'archivio BLOB di Azure viene usato come area di staging intermedia per abilitare PolyBase per ottimizzare le prestazioni della copia.
Nella scheda Connessioni fare di nuovo clic su + Nuovo sulla barra degli strumenti.
Nella finestra New Linked Service (Nuovo servizio collegato) selezionare Archiviazione BLOB di Azure e fare clic su Continua.
Nella finestra New Linked Service (Azure Blog Storage) (Nuovo servizio collegato - Archiviazione BLOB di Azure), procedere come segue:
a. Immettere AzureStorageLinkedService per Nome.
b. Selezionare l'Account di archiviazione di Azure per Nome account di archiviazione.c. Cliccare su Crea.
Creare i set di dati
In questa esercitazione vengono creati i set di dati di origine e sink, che specificano la posizione in cui vengono archiviati i dati.
Il set di dati di input AzureSqlDatabaseDataset fa riferimento ad AzureSqlDatabaseLinkedService. Il servizio collegato specifica la stringa di connessione per la connessione al database. Il set di dati specifica il nome del database e la tabella che contiene i dati di origine.
Il set di dati di output AzureSqlDWDataset fa riferimento ad AzureSqlDWLinkedService. Il servizio collegato specifica la stringa di connessione per la connessione ad Azure Synapse Analytics. Il set di dati specifica il database e la tabella in cui vengono copiati i dati.
In questa esercitazione le tabelle SQL di origine e di destinazione non sono hardcoded nelle definizioni del set di dati. L'attività ForEach passa invece il nome della tabella in fase di esecuzione all'attività di copia.
Creare un set di dati per il database SQL di origine
Selezionare la scheda Crea dal riquadro sinistro.
Selezionare + (segno più) nel riquadro sinistro e selezionare Set di dati.
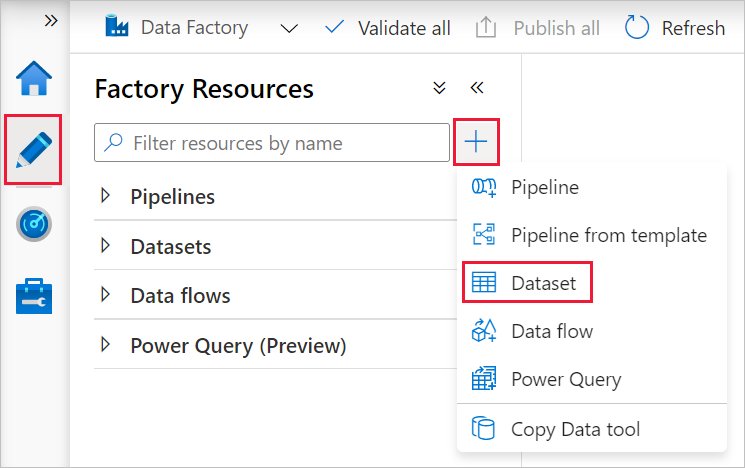
Nella finestra Nuovo set di dati selezionare Database SQL di Azure e quindi fare clic su Fine.
Nella finestra Imposta proprietà, in Nome, immettere AzureSqlDatabaseDataset. In Servizio collegato selezionare AzureSqlDatabaseLinkedService. Quindi fare clic su OK.
Passare alla scheda Connessione e selezionare una tabella per Tabella. Questa è una tabella fittizia. Specificare una query sul set di dati di origine quando si crea una pipeline. La query viene usata per estrarre dati dal database. In alternativa è possibile selezionare la casella di controllo Modifica e immettere dbo.dummyName come nome della tabella.
Creare un set di dati per il sink di Azure Synapse Analytics
Fare clic su + (segno più) nel riquadro a sinistra e quindi su Set di dati.
Nella finestra New Dataset (Nuovo set di dati) selezionare Azure Synapse Analytics e quindi fare clic su Continua.
Nella finestra Imposta proprietà, in Nome, immettere AzureSqlDWDataset. In Servizio collegato selezionare AzureSqlDWLinkedService. Quindi fare clic su OK.
Passare alla scheda Parametri, fare clic su + Nuovo e immettere DWTableName come nome del parametro. Fare di nuovo clic su + Nuovo e immettere DWSchema come nome del parametro. Se si copia/incolla questo nome dalla pagina, assicurarsi che non siano presenti spazi finali dopo DWTableName e DWSchema.
Passare alla scheda Connessione.
Per Tabella selezionare l'opzione Modifica. Selezionare la prima casella di input e fare clic sul collegamento Aggiungi contenuto dinamico al di sotto. Nella pagina Aggiungi contenuto dinamico fare clic su DWSchema in Parametri per popolare automaticamente la casella di testo dell'espressione
@dataset().DWSchemanella parte superiore, quindi fare clic su Fine.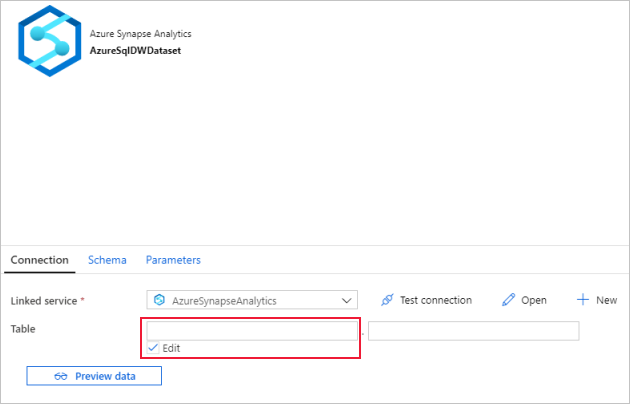
Selezionare la seconda casella di input e fare clic sul collegamento Aggiungi contenuto dinamico al di sotto. Nella pagina Aggiungi contenuto dinamico fare clic su DWTAbleName in Parametri per popolare automaticamente la casella di testo dell'espressione
@dataset().DWTableNamenella parte superiore, quindi fare clic su Fine.La proprietà tableName del set di dati è impostata sui valori passati come argomenti per i parametri DWSchema e DWTableName. L'attività ForEach esegue l'iterazione di un elenco di tabelle e le passa una alla volta all'attività di copia.
Creare le pipeline
In questa esercitazione vengono create due pipeline: IterateAndCopySQLTables e GetTableListAndTriggerCopyData.
La pipeline GetTableListAndTriggerCopyData esegue due azioni:
- Ricerca della tabella di sistema del database SQL di Azure per ottenere l'elenco di tabelle da copiare.
- Attivazione della pipeline IterateAndCopySQLTables per l'esecuzione della copia effettiva dei dati.
La pipeline IterateAndCopySQLTables accetta un elenco di tabelle come parametro. Per ogni tabella dell'elenco, copia i dati dalla tabella di Database SQL di Azure ad Azure Synapse Analytics usando una copia in fasi e PolyBase.
Creare la pipeline IterateAndCopySQLTables
Nel riquadro a sinistra fare clic su + (segno più) e quindi su Pipeline.
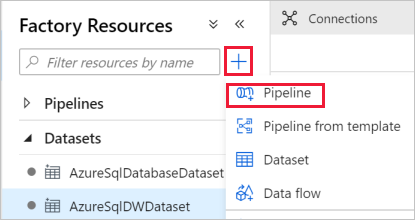
Nel pannello Generale in Proprietà specificare IterateAndCopySQLTables per Nome. Comprimere quindi il pannello facendo clic sull'icona Proprietà nell'angolo in alto a destra.
Passare alla scheda Parametri ed eseguire le azioni seguenti:
a. Fare clic su + Nuovo.
b. Immettere tableList per il Nome del parametro.
c. Selezionare Matrice per Tipo.
Nella casella degli strumenti Attività espandere Iteration & Conditions (Iterazione e condizioni) e trascinare l'attività ForEach sull'area di progettazione della pipeline. È anche possibile eseguire una ricerca di attività nella casella degli strumenti Attività.
a. Nella scheda Generale nella parte inferiore della schermata immettere IterateSQLTables per Nome.
b. Passare alla scheda Impostazioni, fare clic sulla casella di input Elementi, quindi fare clic sul collegamento Aggiungi contenuto dinamico.
c. Nella pagina Aggiungi contenuto dinamico comprimere le sezioni Variabili di sistema e Funzioni, fare clic su tableList in Parametri per popolare automaticamente la casella di testo dell'espressione come
@pipeline().parameter.tableListnella parte superiore. Fare quindi clic su Fine.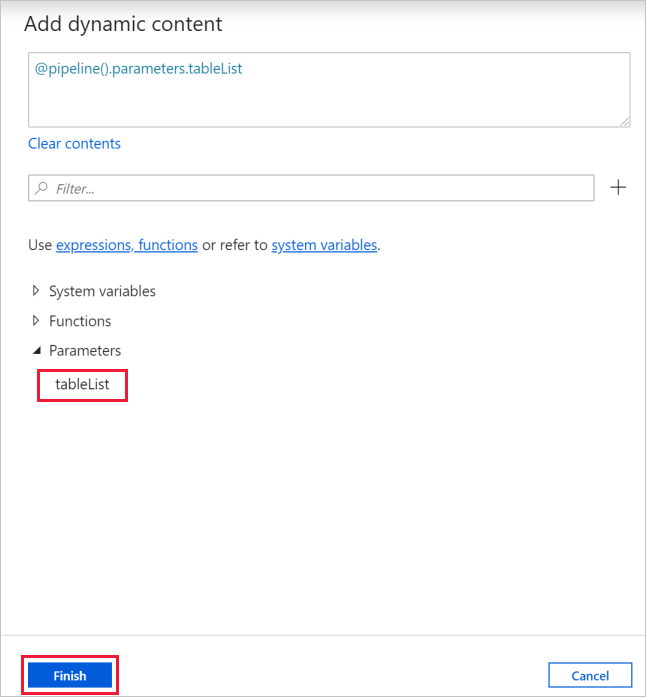
d. Passare alla scheda Attività, fare clic sull'icona a forma di matita per aggiungere un'attività figlio all'attivitàForEach.
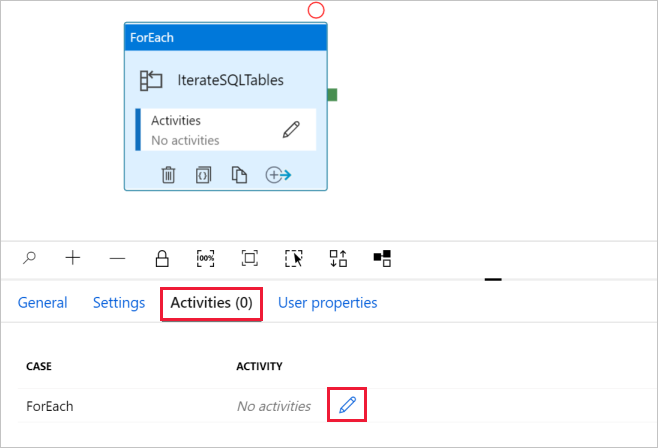
Nella casella degli strumenti Attività espandere Move & Transfer (Sposta e trasferisci) e trascinare l'attività Copia dati nell'area di progettazione della pipeline. Si noti il menu di navigazione nella parte superiore della schermata. IterateAndCopySQLTable è il nome della pipeline e IterateSQLTables è il nome dell'attività ForEach. La finestra di progettazione rientra nell'ambito dell'attività. Per tornare all'editor di pipeline dall'editor di ForEach, fare clic sul collegamento nel menu di navigazione.
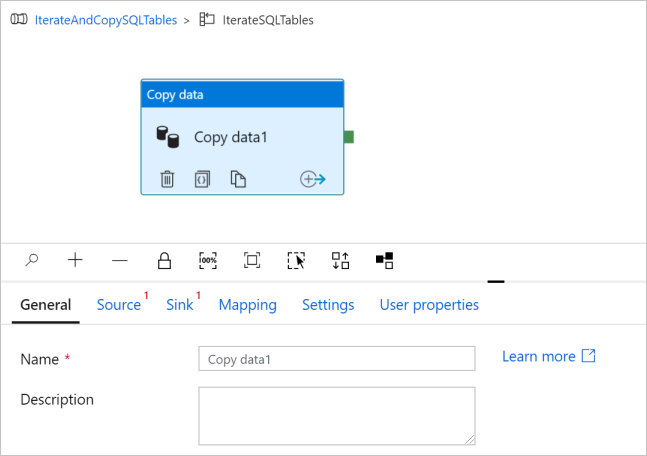
Passare alla scheda Origine e seguire questa procedura:
Selezionare AzureSqlDatabaseDataset per Source Dataset (Set di dati di origine).
Selezionare l'opzione Query per Use query (Usa query).
Fare clic sulla casella Input query :> selezionare Aggiungi contenuto dinamico di seguito.> Immettere l'espressione seguente per Query -> selezionare Fine.
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Passare alla scheda Sink e seguire questa procedura:
Selezionare AzureSqlDWDataset per Sink Dataset (Set di dati sink).
Fare clic sulla casella di input per il valore del parametro DWTableName.> Selezionare l'opzione Aggiungi contenuto dinamico di seguito, immettere
@item().TABLE_NAMEl'espressione come script,> quindi selezionare Fine.Fare clic sulla casella di input per il valore del parametro DWSchema.> Selezionare aggiungi contenuto dinamico di seguito, immettere
@item().TABLE_SCHEMAl'espressione come script,> quindi selezionare Fine.Per metodo di copia selezionare PolyBase.
Deselezionare l'opzione Use type default (Tipo di uso predefinito).
Per l'opzione Tabella, l'impostazione predefinita è "Nessuna". Se non sono presenti tabelle create in precedenza nel sink di Azure Synapse Analytics, abilitare l'opzione Crea tabella automaticamente. L'attività di copia creerà quindi automaticamente le tabelle in base ai dati di origine. Per informazioni dettagliate, vedere Creazione automatica di tabelle del sink.
Fare clic sulla casella pre-copia input script -> selezionare aggiungi contenuto dinamico di seguito -> immettere l'espressione seguente come script -> selezionare Fine.
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]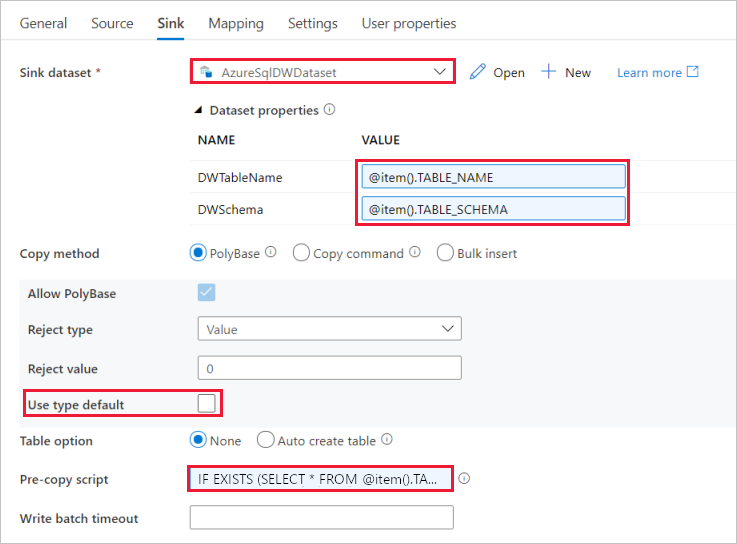
Passare alla scheda Impostazioni e seguire questa procedura:
- Selezionare la casella di controllo Enable staging (Abilita staging).
- Selezionare AzureStorageLinkedService per Staging Account Linked Service (Servizio collegato dell'account di staging).
Per convalidare le impostazioni della pipeline, fare clic su Convalida sulla barra degli strumenti superiore. Verificare che non sia presente alcun errore di convalida. Per chiudere Pipeline Validation Report (Report di convalida della pipeline), fare clic sulle doppie parentesi angolari >>.
Creare la pipeline GetTableListAndTriggerCopyData
Questa pipeline esegue due azioni:
- Ricerca della tabella di sistema del database SQL di Azure per ottenere l'elenco di tabelle da copiare.
- Attivazione della pipeline "IterateAndCopySQLTables" per l'esecuzione della copia effettiva dei dati.
Ecco la procedura per creare la pipeline:
Nel riquadro a sinistra fare clic su + (segno più) e quindi su Pipeline.
Nella scheda Generale in Proprietà cambiare il nome della pipeline in GetTableListAndTriggerCopyData.
Nella casella degli strumenti Attività espandere Generale, trascinare l'attività Cerca nell'area di progettazione della pipeline e seguire questa procedura:
- Immettere LookupTableList per Nome.
- Immettere Retrieve the table list from Azure SQL database (Recuperare l'elenco di tabelle dal database) per Descrizione.
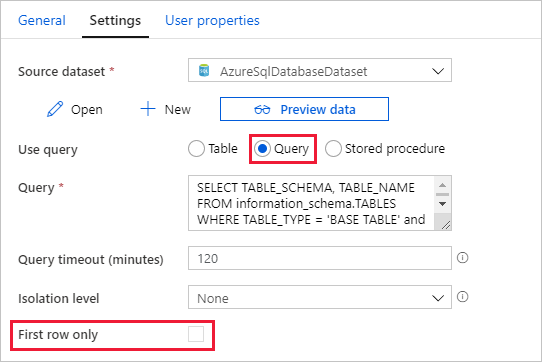
Passare alla scheda Impostazioni e seguire questa procedura:
Selezionare AzureSqlDatabaseDataset per Source Dataset (Set di dati di origine).
Selezionare Query per Use query (Usa query).
Immettere la query SQL seguente per Query.
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'Deselezionare la casella di controllo per il campo First row only (Solo prima riga).
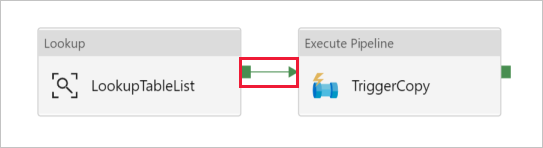
Trascinare l'attività Execute Pipeline (Esegui pipeline) dalla casella degli strumenti Attività nell'area di progettazione della pipeline e impostare il nome su TriggerCopy.
Connettere l'attività Cerca all'attività Execute Pipeline (Esegui pipeline) trascinando la casella verde collegata all'attività Cerca a sinistra dell'attività Execute Pipeline.
Passare alla scheda Impostazioni dell'attività Execute Pipeline (Esegui pipeline) e seguire questa procedura:
Selezionare IterateAndCopySQLTables per Invoked pipeline (Pipeline richiamata).
Deselezionare la casella di controllo Attendi completamento.
Nella sezione Parametri fare clic sulla casella di input in VALORE -> selezionare il valore Aggiungi contenuto dinamico di seguito -> immettere
@activity('LookupTableList').output.valuecome valore del nome tabella -> selezionare Fine. L'elenco dei risultati dall'attività Cerca viene configurato come input per la seconda pipeline. L'elenco dei risultati contiene l'elenco di tabelle i cui dati devono essere copiati nella destinazione.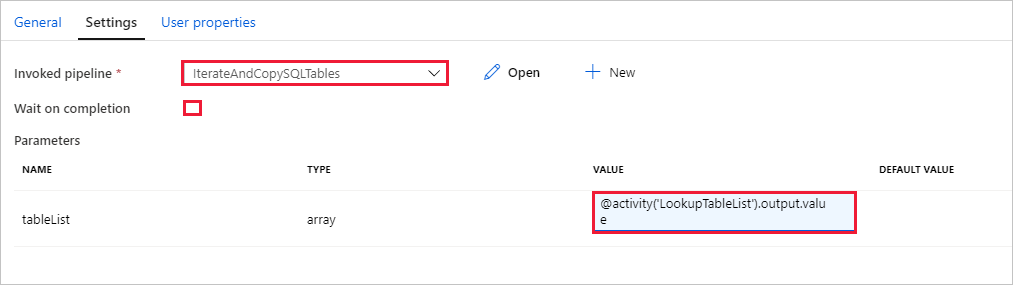
Per convalidare la pipeline, fare clic su Convalida sulla barra degli strumenti. Verificare che non siano presenti errori di convalida. Per chiudere il Pipeline Validation Report (Report di convalida della pipeline) fare clic su >>.
Per pubblicare le entità (set di dati, pipeline e così via) nel servizio Data Factory, fare clic su Pubblica tutti nella parte superiore della finestra. Attendere fino al completamento della pubblicazione.
Attivare un'esecuzione della pipeline
Passare alla pipeline GetTableListAndTriggerCopyData, fare clic su Aggiungi trigger sulla barra degli strumenti superiore della pipeline e quindi su Trigger Now (Attiva adesso).
Confermare l'esecuzione nella pagina Esecuzione della pipeline, quindi selezionare Fine.
Monitorare l'esecuzione della pipeline
Passare alla scheda Monitoraggio . Fare clic su Aggiorna fino a visualizzare le esecuzioni per entrambe le pipeline nella soluzione. Continuare ad aggiornare l'elenco fino a visualizzare lo stato Operazione completata.
Per visualizzare le esecuzioni di attività associate alla pipeline GetTableListAndTriggerCopyData, fare clic sul collegamento del nome della pipeline. Dovrebbero essere visualizzate due esecuzioni di attività per questa esecuzione di pipeline.
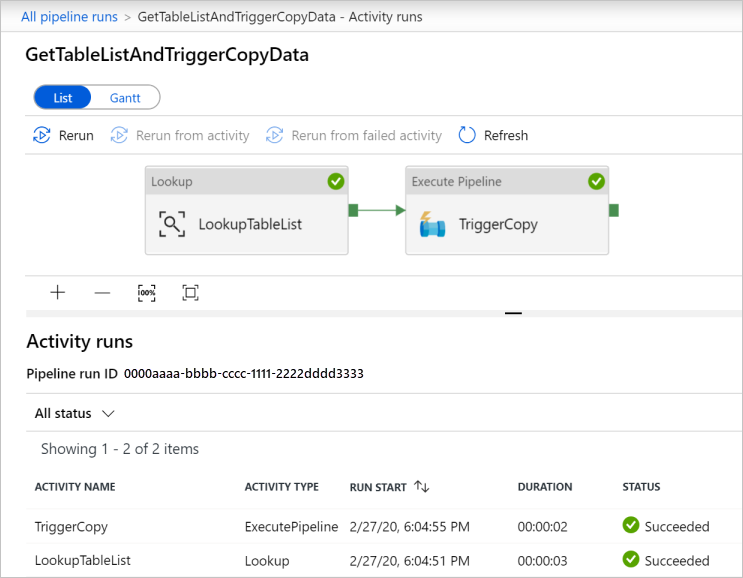
Per visualizzare l'output dell'attività Lookup, fare clic sul collegamento Output accanto all'attività nella colonna ACTIVITY NAME. È possibile ingrandire e ripristinare la finestra Output. Dopo la verifica, fare clic su X per chiudere la finestra Output.
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }Per tornare alla visualizzazione Esecuzioni della pipeline, fare clic sul collegamento Tutte le esecuzioni della pipeline nella parte superiore del menu di navigazione. Fare clic sul collegamento IterateAndCopySQLTables (nella colonna PIPELINE NAME) per visualizzare le esecuzioni attività della pipeline. Si noti che è presente un'esecuzione attività Copia per ogni tabella nell'output dell'attività Cerca.
Verificare che i dati siano stati copiati nell'istanza di Azure Synapse Analytics di destinazione usata in questa esercitazione.
Contenuto correlato
In questa esercitazione sono stati eseguiti i passaggi seguenti:
- Creare una data factory.
- Creare i servizi collegati Database SQL di Azure, Azure Synapse Analytics e Archiviazione di Azure.
- Creare set di dati di Database SQL di Azure e Azure Synapse Analytics.
- Creare una pipeline per cercare le tabelle da copiare e un'altra pipeline per eseguire l'operazione di copia effettiva.
- Avviare un'esecuzione della pipeline.
- Monitorare le esecuzioni di pipeline e attività.
Passare all'esercitazione successiva per ottenere informazioni sulla copia incrementale di dati da un'origine a una destinazione: