Trasformare i dati eseguendo un'attività JAR in Azure Databricks
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
L'attività Jar di Azure Databricks in una pipeline esegue un file Jar Spark nel cluster Azure Databricks. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate. Azure Databricks è una piattaforma gestita per l'esecuzione di Apache Spark.
Per un'introduzione di undici minuti e una dimostrazione di questa funzionalità, guardare il video seguente:
Aggiungere un'attività Jar per Azure Databricks a una pipeline con l'interfaccia utente
Per usare un'attività Jar per Azure Databricks in una pipeline, seguire questa procedura:
Cercare Jar nel riquadro Attività pipeline e trascinare un'attività Jar nell'area di disegno della pipeline.
Selezionare la nuova attività Jar nell'area di disegno, se non è già selezionata.
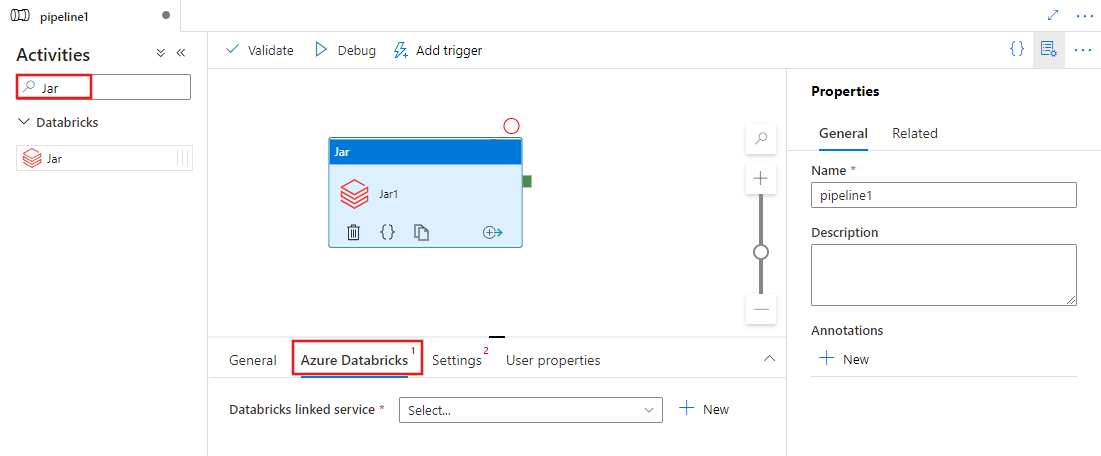
Selezionare la scheda Azure Databricks per selezionare o creare un nuovo servizio collegato di Azure Databricks che eseguirà l'attività Jar.
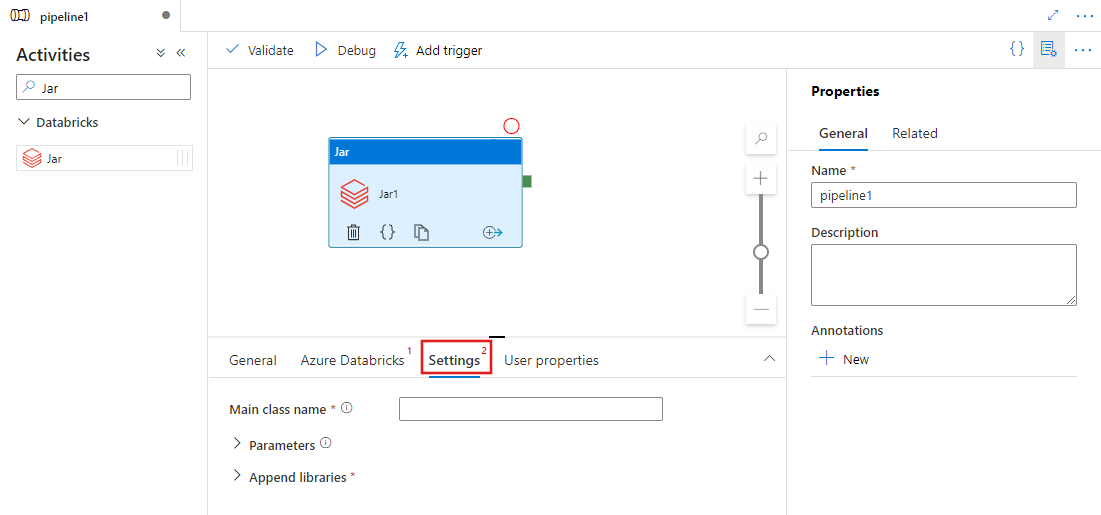
Selezionare la scheda Impostazioni e specificare un nome di classe da eseguire in Azure Databricks, parametri facoltativi da passare al file Jar e librerie da installare nel cluster per eseguire il processo.
Definizione di attività JAR di Databricks
Ecco la definizione JSON di esempio di un'attività Jar di Databricks:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Proprietà dell'attività JAR di Databricks
La tabella seguente fornisce le descrizioni delle proprietà JSON usate nella definizione JSON:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'attività nella pipeline. | Sì |
| description | Testo che descrive l'attività. | No |
| type | Per l'attività JAR di Databricks il tipo di attività è DatabricksSparkJar. | Sì |
| linkedServiceName | Nome del servizio collegato Databricks su cui è in esecuzione l'attività JAR. Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| mainClassName | Il nome completo della classe che contiene il metodo Main deve essere eseguito. Questa classe deve essere contenuta in un file JAR fornito come libreria. Un file JAR può contenere più classi. Ognuna delle classi può contenere un metodo main. | Sì |
| parameters | Parametri che verranno passati al metodo Main. Questa proprietà è una matrice di stringhe. | No |
| libraries | Un elenco di librerie da installare nel cluster che eseguirà il processo. Può essere una matrice di <stringhe, oggetto> | Sì (almeno una che contiene il metodo mainClassName) |
Nota
Problema noto: quando si usa lo stesso cluster interattivo per l'esecuzione di attività Jar simultanee di Databricks (senza riavvio del cluster), si verifica un problema noto in Databricks in cui nei parametri dell'attività 1° verranno usati anche le attività seguenti. Di conseguenza, i parametri non corretti vengono passati ai processi successivi. Per attenuare questo problema, usare invece un cluster processo.
Librerie supportate per le attività di databricks
Nella definizione precedente dell'attività Databricks sono stati specificati questi tipi di libreria: jar, eggmaven, , pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Per altre informazioni, consultare la documentazione di Databricks sui tipi di libreria.
Come caricare una libreria in Databricks
È possibile usare l'interfaccia utente dell'area di lavoro:
Usare l'interfaccia utente dell'area di lavoro di Databricks
Per ottenere il percorso dbfs della libreria aggiunto tramite l'interfaccia utente, è possibile usare l'interfaccia della riga di comando di Databricks.
In genere le librerie Jar sono archiviate in dbfs:/FileStore/jars quando si usa l'interfaccia utente. È possibile elencarle tutte tramite l'interfaccia della riga di comando: databricks fs ls dbfs:/FileStore/job-jars
In alternativa, è possibile usare l'interfaccia della riga di comando di Databricks:
Seguire Copiare la libreria usando l'interfaccia della riga di comando di Databricks
Usare l'interfaccia della riga di comando di Databricks (procedura di installazione)
Ad esempio, per copiare un file JAR in dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Contenuto correlato
Per un'introduzione di undici minuti e una dimostrazione di questa funzionalità, guardare il video.