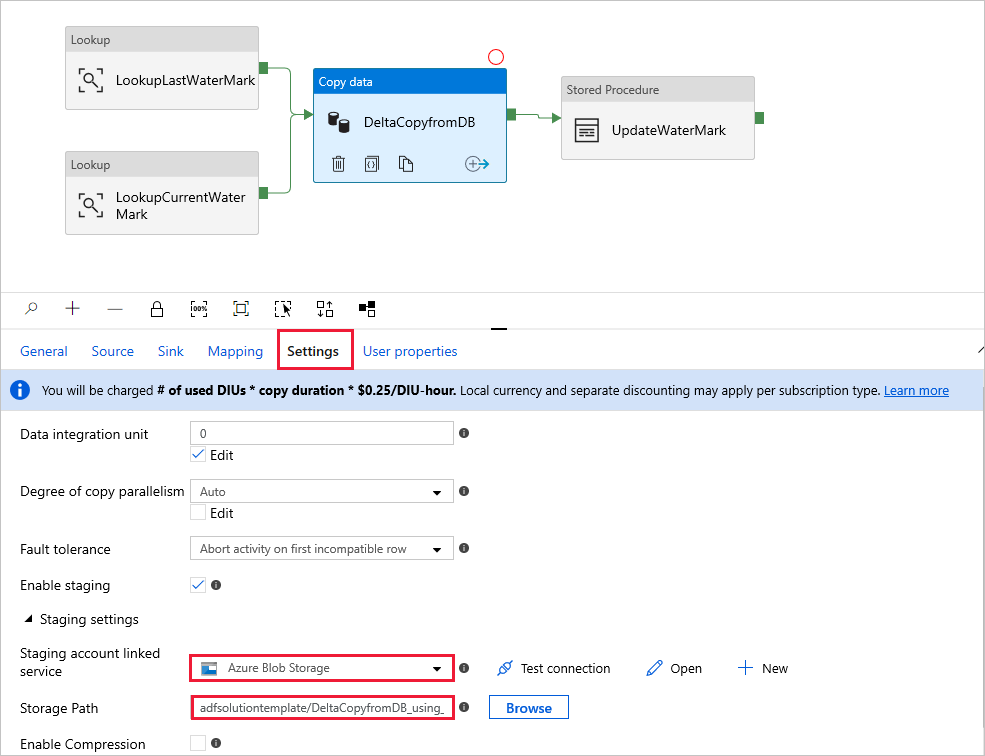
Copia differenziale da un database con una tabella di controllo
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo descrive un modello disponibile per caricare in modo incrementale righe nuove o aggiornate da una tabella di database in Azure usando una tabella di controllo esterna che archivia un valore limite elevato.
Questo modello richiede che lo schema del database di origine contenga una colonna timestamp o una chiave di incremento per identificare le righe nuove o aggiornate.
Nota
Se nel database di origine è presente una colonna timestamp per identificare le righe nuove o aggiornate, ma non si vuole creare una tabella di controllo esterna da usare per la copia differenziale, è invece possibile usare lo strumento Copia dati di Azure Data Factory per ottenere una pipeline. Questo strumento usa un'ora pianificata per trigger come variabile per leggere nuove righe dal database di origine.
Informazioni sul modello di soluzione
Questo modello recupera innanzitutto il valore limite precedente e lo confronta con il valore limite corrente. Successivamente, copia solo le modifiche dal database di origine, in base a un confronto tra i due valori limite. Infine, archivia il nuovo valore limite elevato in una tabella di controllo esterna per il caricamento successivo dei dati differenziali.
Il modello contiene quattro attività:
- La ricerca recupera il vecchio valore limite massimo archiviato in una tabella di controllo esterna.
- Un'altra attività lookup recupera il valore limite massimo corrente dal database di origine.
- Copia copia solo le modifiche dal database di origine all'archivio di destinazione. La query che identifica le modifiche nel database di origine è simile a "SELECT * FROM Data_Source_Table WHERE TIMESTAMP_Column > "last high-watermark" e TIMESTAMP_Column <= "current high-watermark"".
- SqlServerStoredProcedure scrive il valore limite massimo corrente in una tabella di controllo esterna per la copia delta la prossima volta.
Il modello definisce i parametri seguenti:
- Data_Source_Table_Name è la tabella nel database di origine da cui si desidera caricare i dati.
- Data_Source_WaterMarkColumn è il nome della colonna nella tabella di origine usata per identificare righe nuove o aggiornate. Il tipo di questa colonna è in genere datetime, INT o simile.
- Data_Destination_Container è il percorso radice della posizione in cui i dati sono copiati nell'archivio di destinazione.
- Data_Destination_Directory è il percorso della directory nella radice della posizione in cui i dati sono copiati nell'archivio di destinazione.
- Data_Destination_Table_Name è la posizione in cui i dati vengono copiati nell'archivio di destinazione (applicabile quando "Azure Synapse Analytics" è selezionato come Destinazione dati).
- Data_Destination_Folder_Path è la posizione in cui i dati vengono copiati nell'archivio di destinazione (applicabile quando "File System" o "Azure Data Lake Storage Gen1" è selezionato come Destinazione dati).
- Control_Table_Table_Name è la tabella di controllo esterna che archivia il valore limite massimo.
- Control_Table_Column_Name è la colonna nella tabella di controllo esterna in cui è archiviato il valore limite massimo.
Come usare questo modello di soluzione
Esplorare la tabella di origine che si vuole caricare e definire la colonna limite massimo che può essere usata per identificare le righe nuove o aggiornate. Il tipo di questa colonna potrebbe essere datetime, INT o simile. Il valore di questa colonna aumenta man mano che vengono aggiunte nuove righe. Dalla tabella di origine di esempio seguente (data_source_table), è possibile usare la colonna LastModifytime come colonna filigrana elevata.
PersonID Name LastModifytime 1 aaaa 2017-09-01 00:56:00.000 2 bbbb 2017-09-02 05:23:00.000 3 cccc 2017-09-03 02:36:00.000 4 dddd 2017-09-04 03:21:00.000 5 eeee 2017-09-05 08:06:00.000 6 fffffff 2017-09-06 02:23:00.000 7 gggg 2017-09-07 09:01:00.000 8 hhhh 2017-09-08 09:01:00.000 9 iiiiiiiii 2017-09-09 09:01:00.000Creare una tabella di controllo in SQL Server o database SQL di Azure per archiviare il valore limite massimo per il caricamento dei dati differenziali. Nell'esempio seguente il nome della tabella di controllo è watermarktable. In questa tabella WatermarkValue è la colonna che archivia il valore limite massimo e il relativo tipo è datetime.
create table watermarktable ( WatermarkValue datetime, ); INSERT INTO watermarktable VALUES ('1/1/2010 12:00:00 AM')Creare una stored procedure nella stessa istanza di SQL Server o database SQL di Azure usata per creare la tabella di controllo. La stored procedure viene usata per scrivere il nuovo valore limite massimo nella tabella di controllo esterna per il caricamento successivo dei dati differenziali.
CREATE PROCEDURE update_watermark @LastModifiedtime datetime AS BEGIN UPDATE watermarktable SET [WatermarkValue] = @LastModifiedtime ENDPassare al modello Copia differenziale dal modello database . Creare una nuova connessione al database di origine da cui si vuole copiare i dati.
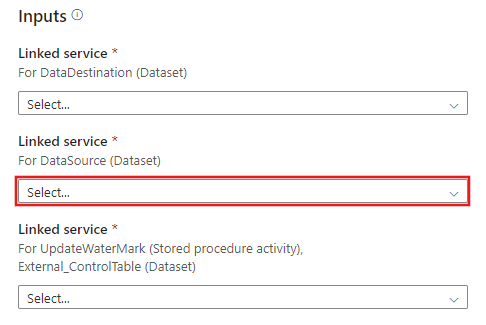
Creare una nuova connessione all'archivio dati di destinazione in cui copiare i dati.
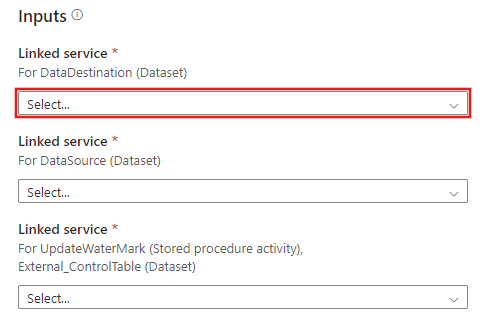
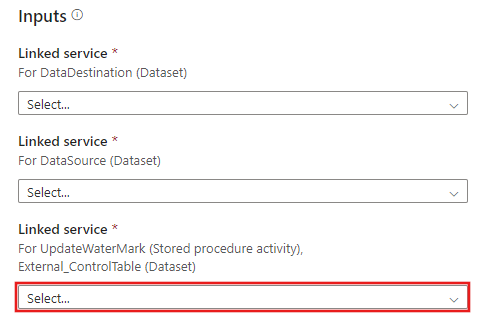
Creare una nuova connessione alla tabella di controllo esterna e alla stored procedure create nei passaggi 2 e 3.
Selezionare Usa questo modello.
Viene visualizzata la pipeline disponibile, come illustrato nell'esempio seguente:
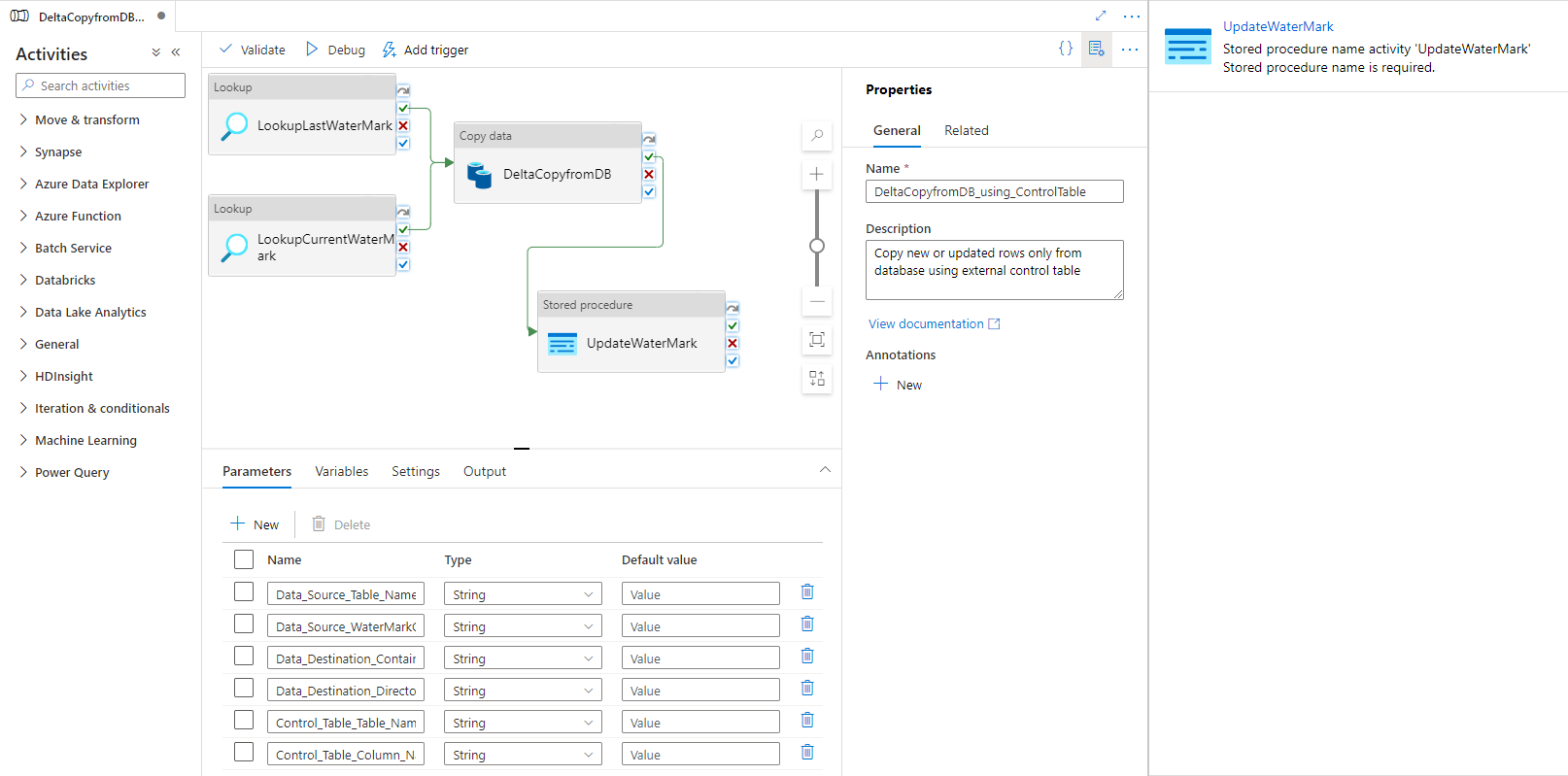
Selezionare Stored procedure. Per Nome stored procedure scegliere [dbo].[ update_watermark]. Selezionare Importa parametro e quindi Aggiungi contenuto dinamico.
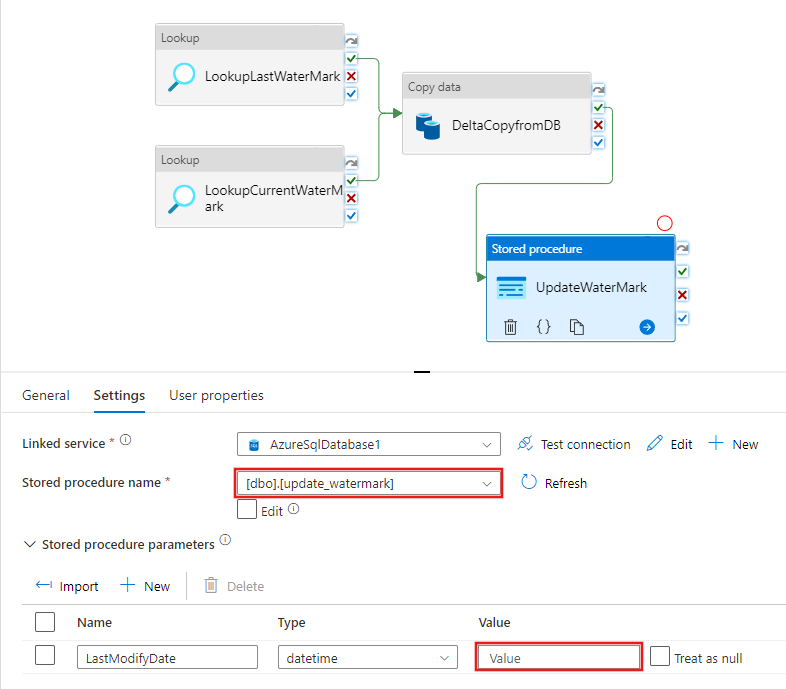
Scrivere il contenuto @{activity('LookupCurrentWaterMark').output.firstRow.NewWatermarkValue}, quindi selezionare Fine.
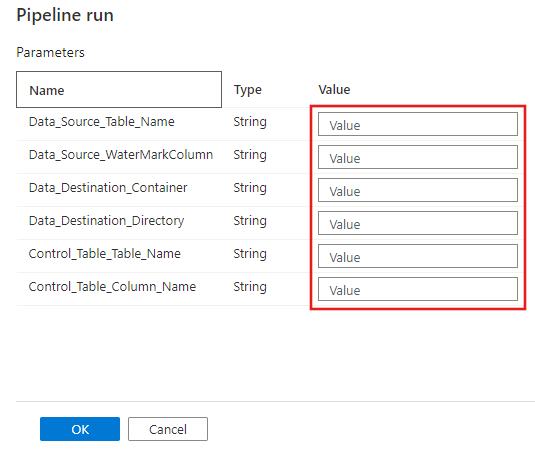
Selezionare Debug, immettere i valori in Parametri e quindi selezionare Fine.
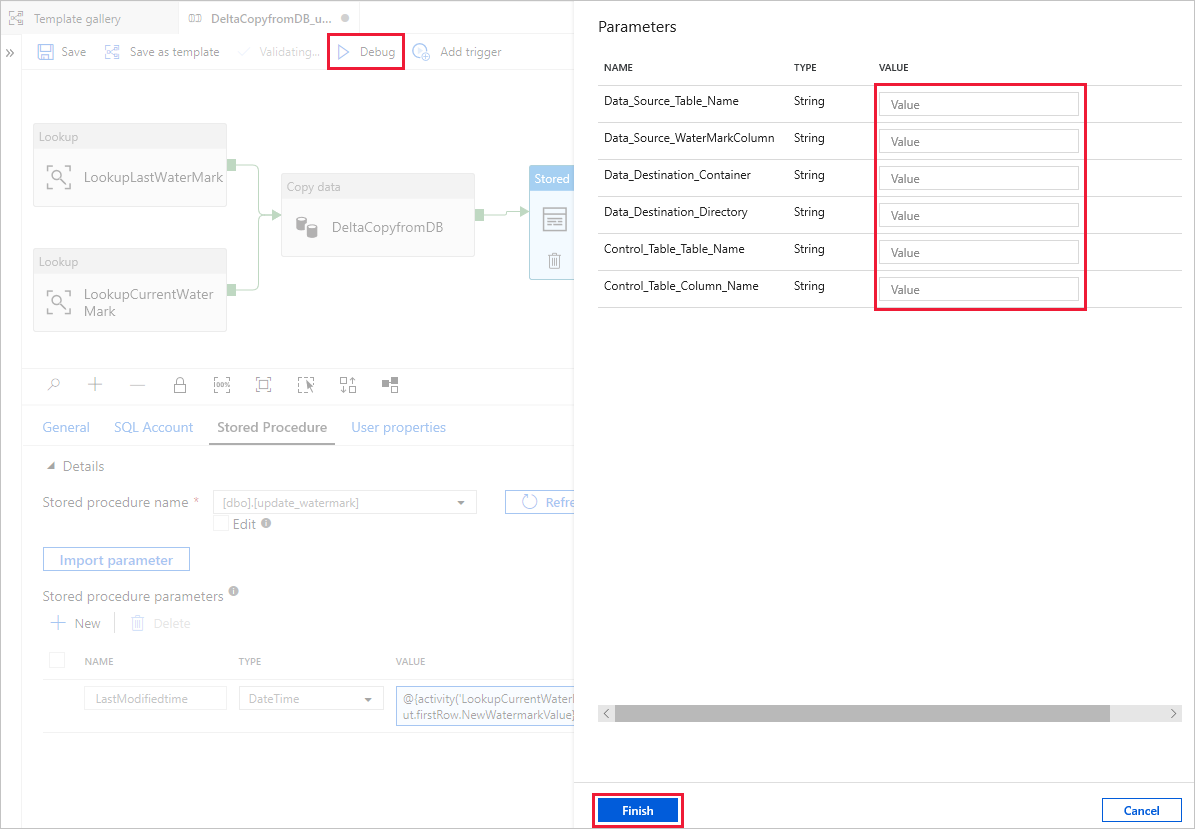
Vengono visualizzati risultati simili all'esempio seguente:
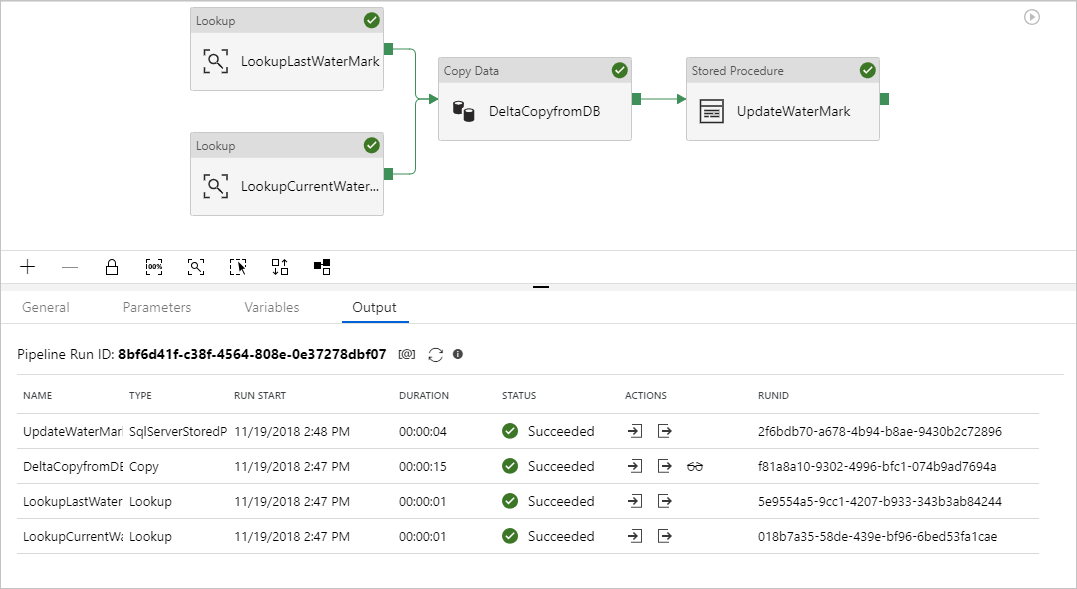
È possibile creare nuove righe nella tabella di origine. Di seguito è riportato un linguaggio SQL di esempio per creare nuove righe:
INSERT INTO data_source_table VALUES (10, 'newdata','9/10/2017 2:23:00 AM') INSERT INTO data_source_table VALUES (11, 'newdata','9/11/2017 9:01:00 AM')Per eseguire di nuovo la pipeline, selezionare Debug, immettere i parametri e quindi selezionare Fine.
Si noterà che solo le nuove righe sono state copiate nella destinazione.
(Facoltativo:) Se si seleziona Azure Synapse Analytics come destinazione dati, è anche necessario fornire una connessione all'archivio BLOB di Azure per la gestione temporanea, richiesta da Polybase di Azure Synapse Analytics. Il modello genererà automaticamente un percorso del contenitore. Dopo l'esecuzione della pipeline, verificare se il contenitore è stato creato nell'archivio BLOB.