Formato Parquet in Azure Data Factory e Azure Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Seguire questo articolo quando si vogliono analizzare i file Parquet o scrivere i dati in formato Parquet.
Il formato Parquet è supportato per i connettori seguenti:
- Amazon S3
- Archiviazione compatibile con Amazon S3
- BLOB di Azure
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- File di Azure
- File system
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Archiviazione in Oracle Cloud
- SFTP
Per un elenco delle funzionalità supportate per tutti i connettori disponibili, vedere l'articolo Panoramica dei connettori.
Uso del runtime di integrazione self-hosted
Importante
Per la copia abilitata dal runtime di integrazione self-hosted, ad esempio tra archivi dati locali e cloud, se non si copiano i file Parquet così come sono, è necessario installare JRE 8 (Java Runtime Environment), JDK 23 (Java Development Kit) o OpenJDK nel computer del runtime di integrazione. Controllare il paragrafo seguente con altri dettagli.
Per la copia in esecuzione nel runtime di integrazione self-hosted con la serializzazione/deserializzazione dei file Parquet, il servizio individua il runtime Java eseguendo in primo luogo una ricerca di JRE nel registro (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome); se non viene trovato, in secondo luogo esegue una ricerca di OpenJDK nella variabile di sistema JAVA_HOME.
- Per usare JRE: il runtime di integrazione a 64 bit richiede JRE a 64 bit. disponibile qui.
-
Per usare JDK: il runtime di integrazione a 64 bit richiede JDK 23 a 64 bit. disponibile qui. Assicurarsi di aggiornare la
JAVA_HOMEvariabile di sistema alla cartella radice dell'installazione di JDK 23, ad esempioC:\Program Files\Java\jdk-23, e aggiungere il percorso a entrambe leC:\Program Files\Java\jdk-23\bincartelle eC:\Program Files\Java\jdk-23\bin\serverallaPathvariabile di sistema. - Per usare OpenJDK: è supportato a partire dalla versione 3.13 del runtime di integrazione. Creare il pacchetto dell'jvm.dll con tutti gli altri assembly necessari di OpenJDK nel computer del runtime di integrazione self-hosted e impostare la variabile di ambiente di sistema JAVA_HOME di conseguenza, quindi riavviare il runtime di integrazione self-hosted per rendere effettivo immediatamente. Per scaricare Microsoft Build of OpenJDK, vedere Microsoft Build of OpenJDK™.
Suggerimento
Se si copiano i dati nel/dal formato Parquet usando il runtime di integrazione self-hosted e si verifica l'errore "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space" (Errore durante la chiamata di Java, messaggio: java.lang.OutOfMemoryError: spazio dell'heap di Java), è possibile aggiungere una variabile di ambiente _JAVA_OPTIONS nel computer che ospita il runtime di integrazione self-hosted per regolare le dimensioni min/max dell'heap per JVM e poter ottimizzare la copia, quindi eseguire di nuovo la pipeline.
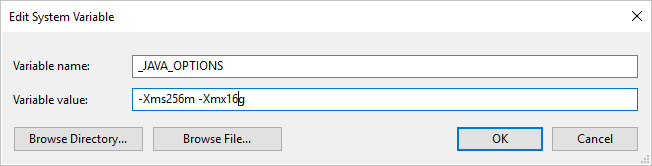
Esempio: impostare la variabile _JAVA_OPTIONS con il valore -Xms256m -Xmx16g. Il flag Xms specifica il pool di allocazione della memoria iniziale per Java Virtual Machine (JVM), mentre Xmx specifica il pool di allocazione della memoria massima. JVM verrà quindi avviato con una quantità di memoria pari a Xms e potrà usare una quantità massima di memoria pari a Xmx. Per impostazione predefinita, il servizio usa min 64 MB e max 1G.
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. In questa sezione viene fornito un elenco delle proprietà supportate dal set di dati Parquet.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su Parquet. | Sì |
| location | Impostazioni di posizione dei file. Ogni connettore basato su file ha il proprio tipo di percorso e le proprietà supportate in location.
Vedere i dettagli nell'articolo del connettore -> sezione Proprietà del set di dati. |
Sì |
| compressionCodec | Codec di compressione da usare per la scrittura in file Parquet. Durante la lettura da file Parquet, Data Factory determina automaticamente il codec di compressione in base ai metadati del file. I tipi supportati sono "none", "gzip", "snappy" (impostazione predefinita) e "lzo". Nota attualmente attività Copy non supporta LZO quando i file Parquet di lettura/scrittura. |
No |
Nota
Lo spazio vuoto nel nome della colonna non è supportato per i file Parquet.
Di seguito è riportato un esempio di set di dati Parquet in Archiviazione BLOB di Azure:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. In questa sezione viene fornito un elenco delle proprietà supportate dall'origine e dal sink Parquet.
Parquet come origine
Nella sezione *source* dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su ParquetSource. | Sì |
| storeSettings | Gruppo di proprietà su come leggere i dati da un archivio dati. Ogni connettore basato su file dispone di impostazioni di lettura proprie supportate in storeSettings.
Vedere i dettagli nell'articolo del connettore -> sezione Proprietà dell'attività Copy. |
No |
Parquet come sink
Nella sezione *sink* dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività di copia deve essere impostata su ParquetSink. | Sì |
| formatSettings | Gruppo di proprietà. Fare riferimento alla tabella delle impostazioni di scrittura Parquet di seguito. | No |
| storeSettings | Gruppo di proprietà su come scrivere i dati in un archivio dati. Ogni connettore basato su file dispone di impostazioni di scrittura supportate in storeSettings.
Vedere i dettagli nell'articolo del connettore -> sezione Proprietà dell'attività Copy. |
No |
Impostazioni di scrittura Parquet supportate in formatSettings:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | Il tipo di formatSettings deve essere impostato su ParquetWriteSettings. | Sì |
| maxRowsPerFile | Quando si scrivono dati in una cartella, è possibile scegliere di scrivere in più file e specificare il numero massimo di righe per file. | No |
| fileNamePrefix | Applicabile quando maxRowsPerFile è configurato.Specificare il prefisso del nome file durante la scrittura di dati in più file ha dato luogo a questo motivo: <fileNamePrefix>_00000.<fileExtension>. Se non specificato, il prefisso del nome file verrà generato automaticamente. Questa proprietà non si applica quando l'origine è l'archivio basato su file o archivio dati abilitato per l'opzione di partizione. |
No |
Proprietà del flusso di dati per mapping
Nei flussi di dati di mapping è possibile leggere e scrivere in formato parquet negli archivi dati seguenti: Archiviazione BLOB di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 e SFTP ed è possibile leggere il formato parquet in Amazon S3.
Proprietà di origine
Nella tabella seguente sono elencate le proprietà supportate da un'origine Parquet. È possibile modificare queste proprietà nella scheda Opzioni origine.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Formato | Il formato deve essere parquet |
yes | parquet |
format |
| Percorsi con caratteri jolly | Verranno elaborati tutti i file corrispondenti al percorso con caratteri jolly. Esegue l'override della cartella e del percorso del file impostato nel set di dati. | no | String[] | wildcardPaths |
| Partition Root Path (Percorso radice partizione) | Per i dati dei file partizionati, è possibile immettere un percorso radice della partizione per leggere le cartelle partizionate come colonne | no | String | partitionRootPath |
| Elenco di file | Indica se l'origine punta a un file di testo che elenca i file da elaborare | no |
true oppure false |
fileList |
| Colonna in cui archiviare il nome file | Creare una nuova colonna con il nome e il percorso del file di origine | no | String | rowUrlColumn |
| Dopo il completamento | Eliminare o spostare i file dopo l'elaborazione. Il percorso del file inizia dalla radice del contenitore | no | Eliminare: true o false Spostare: [<from>, <to>] |
purgeFiles moveFiles |
| Filtra per data ultima modifica | Scegliere di filtrare i file in base all'ultima modifica | no | Timestamp: | modifiedAfter modifiedBefore |
| Consenti nessun file trovato | Se true, un errore non viene generato se non vengono trovati file | no |
true oppure false |
ignoreNoFilesFound |
Esempio di origine
L'immagine seguente è un esempio di configurazione di origine Parquet nei flussi di dati di mapping.
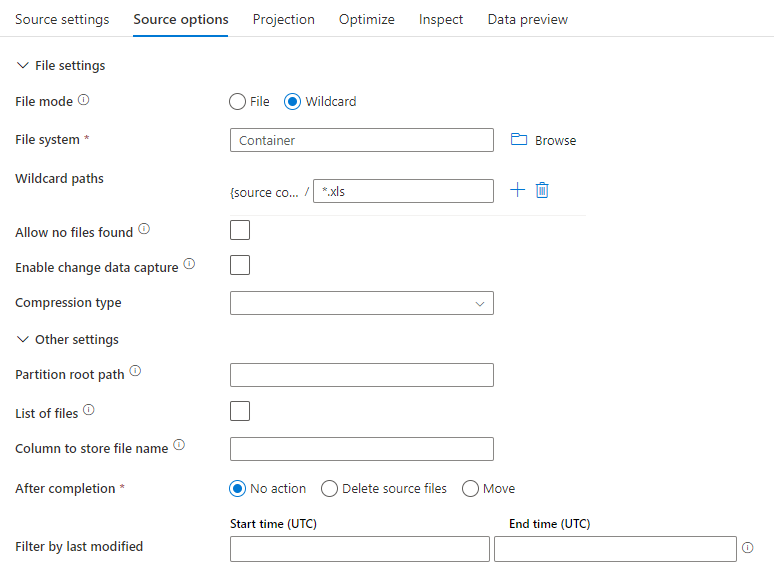
Lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Proprietà sink
Nella tabella seguente sono elencate le proprietà supportate da un sink Parquet. È possibile modificare queste proprietà nella scheda Impostazioni.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Formato | Il formato deve essere parquet |
yes | parquet |
format |
| Cancellare la cartella | Se la cartella di destinazione viene cancellata prima della scrittura | no |
true oppure false |
truncate |
| Opzione Nome file | Formato di denominazione dei dati scritti. Per impostazione predefinita, un file per partizione in formato part-#####-tid-<guid> |
no | Motivo: Stringa Per partizione: Stringa[] Come dati nella colonna: Stringa Output in un singolo file: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Esempio di sink
L'immagine seguente è un esempio di configurazione sink parquet nei flussi di dati di mapping.
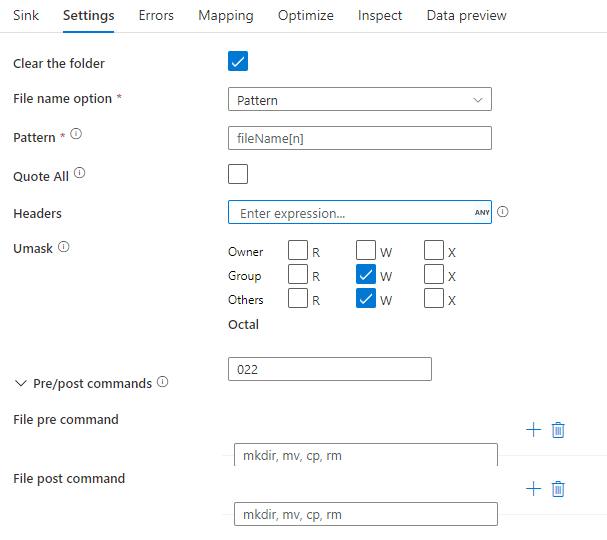
Lo script del flusso di dati associato è:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Supporto dei tipi di dati
I tipi di dati complessi Parquet (ad esempio MAP, LIST, STRUCT) sono attualmente supportati solo in Flusso di dati, non nell'attività di copia. Per usare tipi complessi nei flussi di dati, non importare lo schema del file nel set di dati, lasciando vuoto lo schema nel set di dati. Quindi, nella trasformazione Origine, importare la proiezione.