Copiare dati da e in Oracle usando Azure Data Factory o Azure Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività di copia in Azure Data Factory per copiare dati da e in un database Oracle. Si basa sulla panoramica dell'attività di copia.
Funzionalità supportate
Questo connettore Oracle è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (origine/sink) | 7.3 |
| Attività Lookup | 7.3 |
| Attività script | 7.3 |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini o sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
In particolare, il connettore Oracle supporta:
- Le versioni seguenti di un database Oracle:
- Oracle 19c R1 (19.1) e versioni successive
- Oracle 18c R1 (18.1) e versioni successive
- Oracle 12c R1 (12.1) e versioni successive
- Oracle 11g R1 (11.1) e versioni successive
- Oracle 10g R1 (10.1) e versioni successive
- Oracle 9i R2 (9.2) e versioni successive
- Oracle 8i R3 (8.1.7) e versioni successive
- Oracle Database Cloud Exadata Service
- Copia parallela da un'origine Oracle. Per informazioni dettagliate, vedere la sezione Copia parallela da Oracle.
Nota
Il server proxy Oracle non è supportato.
Prerequisiti
Se l'archivio dati si trova all'interno di una rete locale, una rete virtuale di Azure o un cloud privato virtuale di Amazon, è necessario configurare un runtime di integrazione self-hosted per connettersi.
Se l'archivio dati è un servizio dati del cloud gestito, è possibile usare Azure Integration Runtime. Se l'accesso è limitato solo agli indirizzi IP approvati nelle regole del firewall, è possibile aggiungere IP di Azure Integration Runtime nell'elenco Consentiti.
È anche possibile usare la funzionalitàruntime di integrazione della rete virtuale gestita in Azure Data Factory per accedere alla rete locale senza installare e configurare un runtime di integrazione self-hosted.
Per altre informazioni sui meccanismi di sicurezza di rete e sulle opzioni supportate da Data Factory, vedere strategie di accesso ai dati.
Il runtime di integrazione fornisce un driver Oracle incorporato. Non è pertanto necessario installare manualmente un driver quando si copiano dati da e in Oracle.
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato a Oracle usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Oracle nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Oracle e selezionare il connettore Oracle.
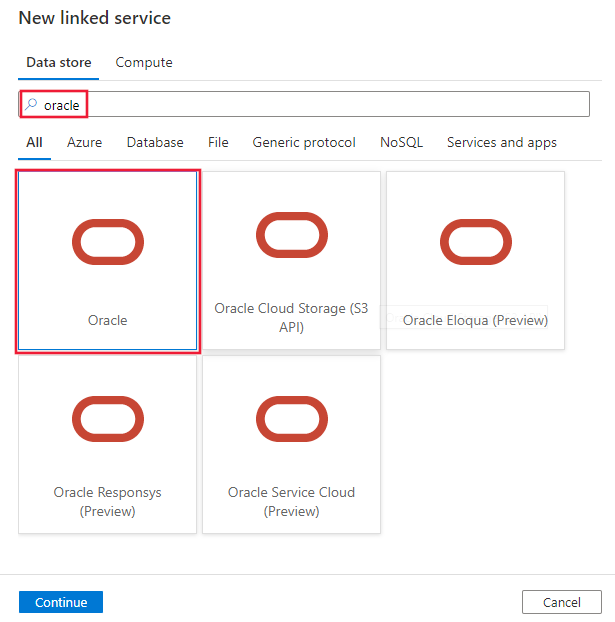
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
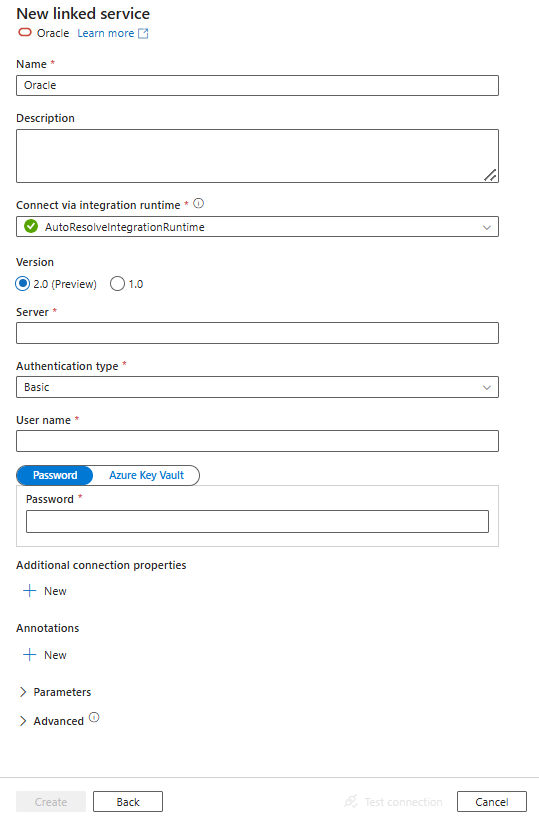
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà usate per definire entità specifiche del connettore Oracle.
Proprietà del servizio collegato
Il servizio collegato Oracle supporta le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su Oracle. | Sì |
| connectionString | Specifica le informazioni necessarie per la connessione all'istanza del database Oracle. È anche possibile inserire una password in Azure Key Vault ed eseguire il pull della configurazione password dalla stringa di connessione. Per altri dettagli, vedere gli esempi seguenti e Archiviare le credenziali in Azure Key Vault. Tipo di connessione supportato: è possibile usare l'ID di sicurezza Oracle o il nome del servizio Oracle per identificare il database: - Se si usa il SID: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;- Se si usa il nome del servizio: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;Per le opzioni avanzate di connessione nativa Oracle, è possibile scegliere di aggiungere una voce nel file TNSNAMES. ORA nel computer in cui è installato il runtime di integrazione self-hosted e nel servizio collegato Oracle scegliere di usare il tipo di connessione Oracle Service Name e configurare il nome del servizio corrispondente. |
Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. Per altre informazioni, vedere la sezione Prerequisiti. Se questa proprietà non è specificata, viene usato il tipo Azure Integration Runtime predefinito. | No |
Suggerimento
Se viene visualizzato un errore, "ORA-01025: il parametro UPI non compreso nell'intervallo" e la versione di Oracle è 8i, aggiungere WireProtocolMode=1 alla stringa di connessione. Quindi riprovare.
Se si dispone di più istanze Oracle per lo scenario di failover, è possibile creare il servizio collegato Oracle e compilare l'host primario, la porta, il nome utente, la password e così via e aggiungere una nuova "Proprietà di connessione aggiuntive" con nome di proprietà AlternateServers e valore (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>) - non dimenticare le parentesi quadre e prestare attenzione ai due punti (:) come separatore. Ad esempio, il valore seguente di server alternativi definisce due server di database alternativi per il failover di connessione: (HostName=AccountingOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Altre proprietà di connessione che è possibile impostare nella stringa di connessione in base al caso:
| Proprietà | Descrizione | Valori consentiti |
|---|---|---|
| ArraySize | Numero di byte che il connettore può recuperare in un singolo round trip di rete. Ad esempio, ArraySize=10485760.I valori più grandi aumentano la velocità effettiva riducendo il numero di volte in cui recuperare i dati in rete. I valori più piccoli aumentano il tempo di risposta, in quanto si verifica un ritardo in attesa che il server trasmetta i dati. |
Numero intero compreso tra 1 e 4294967296 (4 GB). Il valore predefinito è 60000. Il valore 1 non definisce il numero di byte, ma indica l'allocazione dello spazio per esattamente una riga di dati. |
Per abilitare la crittografia sulla connessione Oracle, sono disponibili due opzioni:
Per usare Triple-DES Encryption (3DES) e Advanced Encryption Standard (AES), sul lato server Oracle, passare a Oracle Advanced Security (OAS) e configurare le impostazioni di crittografia. Per informazioni dettagliate, vedere la documentazione Oracle. Il connettore Oracle Application Development Framework (ADF) negozia automaticamente il metodo di crittografia per usare quello configurato in OAS quando si stabilisce una connessione a Oracle.
Per usare TLS, configurare
truststoreper l'autenticazione del server SSL applicando uno dei tre metodi seguenti:Metodo 1 (scelta consigliata):
Installare il certificato TLS/SSL importandolo nell'archivio certificati locale. Il driver Oracle predefinito è in grado di caricare il certificato necessario dall'archivio certificati.
Nel servizio configurare la stringa di connessione Oracle con
EncryptionMethod=1.
Metodo 2:
Ottenere le informazioni sul certificato TLS/SSL. Ottenere le informazioni sui certificati con codifica DER (Distinguished Encoding Rules) o con codifica PEM (Privacy Enhanced Mail) del certificato TLS/SSL.
openssl x509 -inform (DER|PEM) -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -textNel servizio configurare la stringa di connessione Oracle con
EncryptionMethod=1e con il valoreTrustStorecorrispondente. Ad esempio,Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore= data:// -----BEGIN CERTIFICATE-----<certificate content>-----END CERTIFICATE-----Nota
- Il valore del campo
TrustStoredeve essere preceduto dadata://. - Quando si specifica il contenuto per più certificati, specificare il contenuto di ogni certificato tra
-----BEGIN CERTIFICATE-----e-----END CERTIFICATE-----. Il numero di trattini (-----) deve essere lo stesso prima e dopo siaBEGIN CERTIFICATEcheEND CERTIFICATE. Ad esempio:
-----BEGIN CERTIFICATE-----<certificate content 1>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 2>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate content 3>-----END CERTIFICATE----- - Il campo
TrustStoresupporta il contenuto fino a 8192 caratteri.
- Il valore del campo
Metodo 3:
Creare il file
truststorecon crittografie complesse come AES256.openssl pkcs12 -in [Full Path to the DER/PEM Certificate including the name of the DER/PEM Certificate] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -keypbe AES-256-CBC -certpbe AES-256-CBC -nokeys -exportPosizionare il file
truststorenel computer del runtime di integrazione self-hosted. Ad esempio, posizionare il file inC:\MyTrustStoreFile.Nel servizio configurare la stringa di connessione Oracle con
EncryptionMethod=1e il valoreTrustStore/TrustStorePasswordcorrispondente. Ad esempio:Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Esempio:
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: archiviare la password in Azure Key Vault
{
"name": "OracleLinkedService",
"properties": {
"type": "Oracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Questa sezione presenta un elenco delle proprietà supportate dal set di dati Oracle. Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati.
Per copiare dati da e in Oracle, impostare la proprietà type del set di dati su OracleTable. Sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su OracleTable. |
Sì |
| schema | Nome dello schema. | No per l'origine, Sì per il sink |
| table | Nome della tabella/vista. | No per l'origine, Sì per il sink |
| tableName | Nome della tabella/vista con schema. Questa proprietà è supportata per garantire la compatibilità con le versioni precedenti. Per i nuovi carichi di lavoro, usare schema e table. |
No per l'origine, Sì per il sink |
Esempio:
{
"name": "OracleDataset",
"properties":
{
"type": "OracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink Oracle. Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline.
Oracle come origine
Suggerimento
Per caricare i dati da Oracle in modo efficiente usando il partizionamento dei dati, vedere Copia parallela da Oracle.
Per copiare dati da Oracle, impostare il tipo di origine nell'attività di copia su OracleSource. Nella sezione source dell'attività di copia sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su OracleSource. |
Sì |
| oracleReaderQuery | Usare la query SQL personalizzata per leggere i dati. Un esempio è "SELECT * FROM MyTable".Quando si abilita il carico partizionato, è necessario associare tutti i parametri di partizione predefiniti corrispondenti nella query. Per gli esempi, vedere la sezione Copia parallela da Oracle. |
No |
| convertDecimalToInteger | Il tipo Oracle NUMBER con scala zero o non specificata verrà convertito in un numero intero corrispondente. I valori consentiti sono true e false (impostazione predefinita). | No |
| partitionOptions | Specifica le opzioni di partizionamento dei dati usate per caricare i dati da Oracle. Valori consentiti: None (predefinito), PhysicalPartitionsOfTable e DynamicRange. Quando un'opzione di partizione è abilitata (ovvero non None), il grado di parallelismo per caricare simultaneamente i dati da un database Oracle è controllato dall'impostazione parallelCopies nell'attività di copia. |
No |
| partitionSettings | Specifica il gruppo di impostazioni per il partizionamento dei dati. Applicare quando l'opzione di partizione non è None. |
No |
| partitionNames | Elenco di partizioni fisiche da copiare. Si applica quando l'opzione di partizione è PhysicalPartitionsOfTable. Se si usa una query per recuperare i dati di origine, associare ?AdfTabularPartitionName nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle. |
No |
| partitionColumnName | Specifica il nome della colonna di origine nel tipo Integer che verrà usata dal partizionamento dell'intervallo per la copia parallela. Se non specificato, la chiave primaria della tabella viene rilevata automaticamente e usata come colonna di partizione. Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?AdfRangePartitionColumnName nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle. |
No |
| partitionUpperBound | Valore massimo della colonna di partizione da cui copiare i dati. Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?AdfRangePartitionUpbound nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle. |
No |
| partitionLowerBound | Valore minimo della colonna di partizione da cui copiare i dati. Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?AdfRangePartitionLowbound nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle. |
No |
Esempio: copiare i dati usando una query di base senza partizione
"activities":[
{
"name": "CopyFromOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "OracleSource",
"convertDecimalToInteger": false,
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Oracle come sink
Per copiare dati in Oracle, impostare il tipo di sink nell'attività di copia su OracleSink. Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività di copia deve essere impostata su OracleSink. |
Sì |
| writeBatchSize | Inserisce i dati nella tabella SQL quando le dimensioni del buffer raggiunge writeBatchSize.I valori consentiti sono integer (numero di righe). |
No (il valore predefinito è 10.000) |
| writeBatchTimeout | Tempo di attesa per l'operazione di inserimento batch da completare prima del timeout. I valori consentiti sono un intervallo di tempo. Ad esempio "00:30:00" (30 minuti). |
No |
| preCopyScript | Specificare una query SQL per l'attività di copia da eseguire prima di scrivere i dati in Oracle in ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati. | No |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
Esempio:
"activities":[
{
"name": "CopyToOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Oracle output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "OracleSink"
}
}
}
]
Copia parallela da Oracle
Il connettore Oracle fornisce il partizionamento dei dati predefinito per copiare dati da Oracle in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività di copia.

Quando si abilita la copia partizionata, il servizio esegue query parallele sull'origine Oracle per caricare i dati in base alle partizioni. Il grado di parallelismo è controllato dall'impostazione parallelCopies sull'attività di copia. Ad esempio, se si imposta parallelCopies su quattro, il servizio genera ed esegue simultaneamente quattro query in base all'opzione e alle impostazioni di partizione specificate e ogni query recupera una porzione di dati dal database Oracle.
È consigliabile abilitare la copia parallela con il partizionamento dei dati, soprattutto quando si caricano grandi quantità di dati dal database Oracle. Di seguito sono riportate le configurazioni consigliate per i diversi scenari. Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come file multipli (specificare solo il nome della cartella); in tal caso, le prestazioni risultano migliori rispetto alla scrittura in un singolo file.
| Scenario | Impostazioni consigliate |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni, con partizioni fisiche. |
Opzione di partizione: partizioni fisiche della tabella. Durante l'esecuzione, il servizio rileva automaticamente le partizioni fisiche e copia i dati in base alle partizioni. |
| Caricamento completo da una tabella di grandi dimensioni, senza partizioni fisiche, con una colonna di numeri interi per il partizionamento dei dati. |
Opzioni di partizione: partizione a intervalli dinamici. Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. Se non è specificato, viene usata la colonna della chiave primaria. |
| Caricare una grande quantità di dati usando una query personalizzata, con partizioni fisiche. |
Opzione di partizione: partizioni fisiche della tabella. Query: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>.Nome partizione: specificare i nomi della partizione da cui copiare i dati. Se non specificato, il servizio rileva automaticamente le partizioni fisiche nella tabella specificata nel set di dati Oracle. Durante l'esecuzione, il servizio sostituisce ?AdfTabularPartitionName con il nome effettivo della partizione e lo invia a Oracle. |
| Caricare una grande quantità di dati usando una query personalizzata, senza partizioni fisiche, con una colonna integer per il partizionamento dei dati. |
Opzioni di partizione: partizione a intervalli dinamici. Query: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. È possibile partizionare la colonna con il tipo di dati Integer. Limite superiore della partizione e limite inferiore della partizione: specificare se si desidera filtrare in base alla colonna di partizione per recuperare i dati solo tra l'intervallo inferiore e quello superiore. Durante l'esecuzione, il servizio sostituisce ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound e ?AdfRangePartitionLowbound con il nome della colonna e gli intervalli di valori effettivi per ogni partizione e li invia a Oracle. Ad esempio, se la colonna di partizione "ID" è impostata con il limite inferiore su 1 e il limite superiore su 80, con la copia parallela impostata su 4, il servizio recupera i dati di 4 partizioni. Gli ID sono rispettivamente compresi tra [1, 20], [21, 40], [41, 60] e [61, 80]. |
Suggerimento
Quando si copiano dati da una tabella non partizionata, è possibile usare l'opzione di partizione "Intervallo dinamico" per eseguire il partizionamento su una colonna integer. Se i dati di origine non hanno tale tipo di colonna, è possibile sfruttare la funzione ORA_HASH nella query di origine per generare una colonna e usarla come colonna di partizione.
Esempio: eseguire una query con partizione fisica
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Esempio: query con partizione a intervalli dinamici
"source": {
"type": "OracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Mapping dei tipi di dati per Oracle
Quando si copiano dati da e in Oracle, vengono usati i mapping dei tipi di dati provvisori seguenti all'interno del servizio. Per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink, vedere Mapping dello schema e del tipo di dati.
| Tipo di dati Oracle | Tipo di dati provvisorio |
|---|---|
| BFILE | Byte[] |
| BLOB | Byte[] (supportato solo in Oracle 10g e versioni successive) |
| CHAR | String |
| CLOB | String |
| DATE | Data/Ora |
| FLOAT | Decimal, String (se precisione > 28) |
| INTEGER | Decimal, String (se precisione > 28) |
| LONG | String |
| LONG RAW | Byte[] |
| NCHAR | String |
| NCLOB | String |
| NUMBER (p,s) | Decimal, String (se p > 28) |
| NUMBER senza precisione e scala | Double |
| NVARCHAR2 | String |
| RAW | Byte[] |
| ROWID | String |
| TIMESTAMP | Data/Ora |
| TIMESTAMP WITH LOCAL TIME ZONE | String |
| TIMESTAMP WITH TIME ZONE | String |
| UNSIGNED INTEGER | Numero |
| VARCHAR2 | String |
| XML | String |
Nota
I tipi di dati INTERVAL YEAR TO MONTH e INTERVAL DAY TO SECOND non sono supportati.
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati supportati.