Copiare dati in o da Esplora dati di Azure usando Azure Data Factory o Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo descrive come usare l'attività Copy nelle pipeline di Azure Data Factory e Synapse Analytics per copiare dati da o verso Esplora dati di Azure. Si basa sull'articolo di panoramica dell'attività Copy, che presenta informazioni generali sull'attività Copy.
Suggerimento
Per altre informazioni sull'integrazione generale di Esplora dati di Azure con il servizio, vedere Integrare Esplora dati di Azure.
Funzionalità supportate
Questo connettore Esplora dati di Azure è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (origine/sink) | 7.3 |
| Flusso di dati per mapping (origine/sink) | 1 |
| Attività Lookup | 7.3 |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
È possibile copiare dati da qualsiasi archivio dati di origine supportato in Esplora dati di Azure. È anche possibile copiare dati da Esplora dati di Azure in un qualsiasi archivio dati sink supportato. Per un elenco di archivi dati supportati dall'attività Copy come origini o sink, vedere la tabella Archivi dati supportati.
Nota
La copia di dati da o verso Esplora dati di Azure tramite un archivio dati locale con il runtime di integrazione self-hosted è supportata nella versione 3.14 e successive.
Con il connettore Esplora dati di Azure è possibile eseguire le operazioni seguenti:
- Copiare i dati usando l'autenticazione del token dell'applicazione Microsoft Entra con un'entità servizio.
- Come origine, recupero di dati tramite una query KQL (Kusto).
- Come sink, accodamento di dati a una tabella di destinazione.
Introduzione
Suggerimento
Per informazioni dettagliate sul connettore Esplora dati di Azure, vedere Copiare dati da e verso Esplora dati di Azure e Copia bulk da un database a Esplora dati di Azure.
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato a Esplora dati di Azure usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Esplora dati di Azure nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
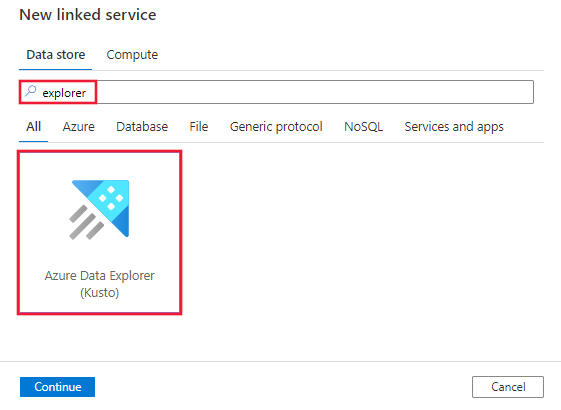
Cercare Esplora e selezionare il connettore Esplora dati di Azure (Kusto).
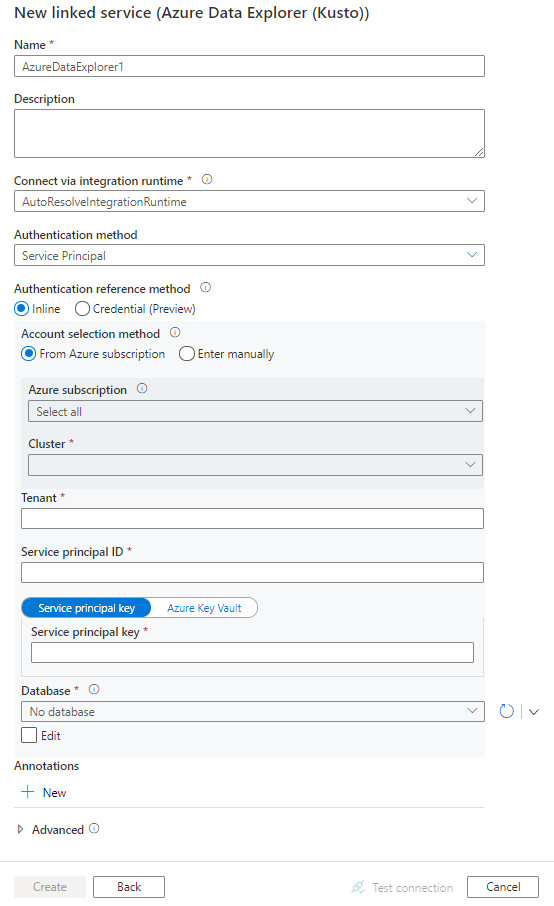
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti offrono informazioni dettagliate sulle proprietà usate per definire entità specifiche per il connettore di Esplora dati di Azure.
Proprietà del servizio collegato
Il connettore Esplora dati di Azure supporta i tipi di autenticazione seguenti. Per informazioni dettagliate, vedere le sezioni corrispondenti:
- Autenticazione di un'entità servizio
- Autenticazione dell'identità gestita assegnata dal sistema
- Autenticazione dell'identità gestita assegnata dall'utente
Autenticazione dell'entità servizio
Per usare l'autenticazione dell'entità servizio, seguire questa procedura per ottenere un'entità servizio e concedere le autorizzazioni:
Registrare un'applicazione con Microsoft Identity Platform. Per informazioni sulla procedura, vedere Avvio rapido: Registrare un'applicazione in Microsoft Identity Platform. Prendere nota di questi valori che si usano per definire il servizio collegato:
- ID applicazione
- Chiave applicazione
- ID tenant
Concedere all'entità servizio le autorizzazioni corrette in Esplora dati di Azure. Vedere Gestire le autorizzazioni del database di Esplora dati di Azure per informazioni dettagliate su ruoli e autorizzazioni e sulla gestione delle autorizzazioni. In generale, è necessario:
- Come origine, concedere almeno il ruolo Visualizzatore di database al database
- Come sink, concedere almeno il ruolo Utente database al database
Nota
Quando si usa l'interfaccia utente per la creazione, per impostazione predefinita viene usato l'account utente di accesso per elencare cluster, database e tabelle di Esplora dati di Azure. È possibile scegliere di elencare gli oggetti usando l'entità servizio facendo clic sull'elenco a discesa accanto al pulsante di aggiornamento oppure immettendo manualmente il nome se non si ha l'autorizzazione per queste operazioni.
Per il servizio collegato Esplora dati di Azure sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureDataExplorer. | Sì |
| endpoint | URL dell'endpoint del cluster di Esplora dati di Azure con il formato https://<clusterName>.<regionName>.kusto.windows.net. |
Sì |
| database | Nome del database. | Sì |
| tenant | Specificare le informazioni sul tenant (nome di dominio o ID tenant) in cui si trova l'applicazione. Questa operazione è nota come "ID autorità" in Stringa di connessione Kusto. Recuperarlo passando il puntatore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
| servicePrincipalId | Specificare l'ID client dell'applicazione. Questa proprietà è nota come "ID client dell'applicazione Microsoft Entra" in Stringa di connessione Kusto. | Sì |
| servicePrincipalKey | Specificare la chiave dell'applicazione. Questa proprietà è nota come "Chiave dell'applicazione Microsoft Entra" in Stringa di connessione Kusto. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a dati sicuri archiviati in Azure Key Vault. | Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio: usare l'autenticazione con chiave dell'entità servizio
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Autenticazione dell'identità gestita assegnata dal sistema
Per altre informazioni sulle identità gestite per le risorse di Azure, vedere Identità gestite per le risorse di Azure.
Per usare l'autenticazione con identità gestita assegnata dal sistema, seguire questa procedura per concedere le autorizzazioni:
Recuperare le informazioni relative all'identità gestita copiando il valore di ID oggetto dell'identità gestita generato con la factory o workspace Synapse.
Concedere all'identità gestita le autorizzazioni corrette in Esplora dati di Azure. Vedere Gestire le autorizzazioni del database di Esplora dati di Azure per informazioni dettagliate su ruoli e autorizzazioni e sulla gestione delle autorizzazioni. In generale, è necessario:
- Come origine, concedere il ruolo Visualizzatore di database al database.
- Come sink, concedere al database i ruoli Inseritore database e Visualizzatore di database al database.
Nota
Quando si usa l'interfaccia utente per la creazione, viene usato l'account utente di accesso per elencare cluster, database e tabelle di Esplora dati di Azure. Immettere manualmente il nome se non si ha l'autorizzazione per queste operazioni.
Per il servizio collegato Esplora dati di Azure sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureDataExplorer. | Sì |
| endpoint | URL dell'endpoint del cluster di Esplora dati di Azure con il formato https://<clusterName>.<regionName>.kusto.windows.net. |
Sì |
| database | Nome del database. | Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio: uso dell'autenticazione con identità gestita assegnata dal sistema
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Autenticazione dell'identità gestita assegnata dall'utente
Per altre informazioni sulle identità gestite per le risorse di Azure, vedere Identità gestite per le risorse di Azure
Per usare l'autenticazione tramite identità gestita assegnata dall’utente, eseguire questa procedura:
Creare una o più identità gestite assegnate dall'utente e concedere l'autorizzazione in Esplora dati di Azure. Vedere Gestire le autorizzazioni del database di Esplora dati di Azure per informazioni dettagliate su ruoli e autorizzazioni e sulla gestione delle autorizzazioni. In generale, è necessario:
- Come origine, concedere almeno il ruolo Visualizzatore di database al database
- Come sink, concedere almeno il ruolo Inseritore database al database
Assegnare una o più identità gestite assegnate dall'utente alla data factory o a workspace Synapse e creare le credenziali per ogni identità gestita assegnata dall'utente.
Per il servizio collegato Esplora dati di Azure sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureDataExplorer. | Sì |
| endpoint | URL dell'endpoint del cluster di Esplora dati di Azure con il formato https://<clusterName>.<regionName>.kusto.windows.net. |
Sì |
| database | Nome del database. | Sì |
| credentials | Specificare l'identità gestita assegnata dall'utente come oggetto credenziale. | Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio: uso dell'autenticazione con identità gestita assegnata dall'utente
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati. Questa sezione elenca le proprietà supportate dal set di dati di Esplora dati di Azure.
Per copiare dati in Esplora dati di Azure, impostare la proprietà type del set di dati su AzureDataExplorerTable.
Sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureDataExplorerTable. | Sì |
| table | Nome della tabella a cui fa riferimento il servizio collegato. | Sì per il sink, no per l'origine |
Esempio di proprietà del set di dati:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere Pipeline e attività. Questa sezione presenta un elenco delle proprietà supportate dalle origini e dai sink di Esplora dati di Azure.
Esplora dati di Azure come origine
Per copiare dati da Esplora dati di Azure, impostare la proprietà type nell'origine dell'attività di copia su AzureDataExplorerSource. Nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività Copy deve essere impostata su: AzureDataExplorerSource | Sì |
| query | Richiesta di sola lettura in formato KQL. Usare la query KQL personalizzata come riferimento. | Sì |
| queryTimeout | Il tempo di attesa prima del timeout della richiesta di query. Il valore predefinito è 10 minuti (00:10:00); il valore massimo consentito è 1 ora (01:00:00). | No |
| noTruncation | Indica se troncare il set di risultati restituito. Per impostazione predefinita, il risultato viene troncato dopo 500.000 record o 64 megabyte (MB). Il troncamento è fortemente consigliato per garantire il comportamento corretto dell'attività. | No |
Nota
Per impostazione predefinita, l'origine di Esplora dati di Azure ha un limite di dimensioni pari a 500.000 record o 64 MB. Per recuperare tutti i record senza troncamento, è possibile specificare set notruncation; all'inizio della query. Per altre informazioni, vedere Limiti delle query.
Esempio:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Esplora dati di Azure come sink
Per copiare dati in Esplora dati di Azure, impostare la proprietà type nel sink dell'attività di copia su AzureDataExplorerSink. Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività Copy deve essere impostata su: AzureDataExplorerSink. | Sì |
| ingestionMappingName | Nome di un mapping creato in precedenza in una tabella Kusto. Per eseguire il mapping delle colonne dall'origine a Esplora dati di Azure (che si applica a tutti gli archivi e i formati di origine supportati, inclusi i formati CSV/JSON/Avro), è possibile usare l'attività Copy Mapping delle colonne (in modo implicito in base al nome o in modo esplicito come configurato) e/o i mapping di Esplora dati di Azure. | No |
| additionalProperties | Contenitore delle proprietà che può essere usato per specificare le proprietà di inserimento che non sono già impostate dal sink di Esplora dati di Azure. In particolare, può essere utile per specificare i tag di inserimento. Per altre informazioni, vedere la documentazione sull'inserimento dati di Esplora dati di Azure. | No |
Esempio:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Proprietà del flusso di dati per mapping
Durante la trasformazione dei dati in un flusso di dati per mapping è possibile leggere da e scrivere in tabelle di Esplora dati di Azure. Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati per mapping. È possibile scegliere di usare un set di dati di Esplora dati di Azure o un set di dati inline come tipo di origine e sink.
Trasformazione origine
La tabella seguente elenca le proprietà supportate dall'origine di Esplora dati di Azure. È possibile modificare queste proprietà nella scheda Opzioni origine.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Tabella | Se si seleziona Tabella come input, il flusso di dati recupera tutti i dati dalla tabella specificata nel set di dati di Esplora dati di Azure o nelle opzioni di origine quando si usa il set di dati inline. | No | String | (solo per set di dati inline) tableName |
| Query | Richiesta di sola lettura in formato KQL. Usare la query KQL personalizzata come riferimento. | No | String | query |
| Timeout | Il tempo di attesa prima del timeout della richiesta di query. Il valore predefinito è "172000" (2 giorni) | No | Intero | timeout |
Esempi di script di origine di Esplora dati di Azure
Quando si usa il set di dati di Esplora dati di Azure come tipo di origine, lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Se si usa un set di dati inline, lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Trasformazione sink
La tabella seguente elenca le proprietà supportate dal sink di Esplora dati di Azure. È possibile modificare queste proprietà nella scheda Impostazioni. Quando si usa il set di dati inline, verranno visualizzate impostazioni aggiuntive, che corrispondono alle proprietà descritte nella sezione Proprietà del set di dati.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| azione Tabella | determina se ricreare o rimuovere tutte le righe dalla tabella di destinazione prima della scrittura. - Nessuno: non verrà eseguita alcuna azione sulla tabella. - Ricrea: la tabella verrà eliminata e ricreata. Questa opzione è obbligatoria se si crea una nuova tabella in modo dinamico. - Tronca: verranno rimosse tutte le righe della tabella di destinazione. |
No | true oppure false |
recreate truncate |
| Pre e post-script SQL | Specificare più script dei comandi di controllo Kusto che verranno eseguiti prima (pre-elaborazione) e dopo (post-elaborazione) la scrittura dei dati nel database sink. | No | String | preSQLs; postSQLs |
| Timeout | Il tempo di attesa prima del timeout della richiesta di query. Il valore predefinito è "172000" (2 giorni) | No | Intero | timeout |
Esempi di script del sink di Esplora dati di Azure
Quando si usa il set di dati di Esplora dati di Azure come tipo di sink, lo script del flusso di dati associato è:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Se si usa un set di dati inline, lo script del flusso di dati associato è:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività di Ricerca.
Contenuto correlato
Per un elenco degli archivi dati supportati dall'attività Copy come origini e sink, vedere Archivi dati supportati.
Altre informazioni su come copiare dati da Azure Data Factory e Synapse Analytics in Esplora dati di Azure.