Copiare e trasformare i dati in Azure Cosmos DB for NoSQL usando Azure Data Factory
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
In questo articolo viene illustrato come usare l'attività Copy in Azure Data Factory per copiare dati da e verso Azure Cosmos DB for NoSQL e usare Flusso di dati per trasformare i dati in Azure Cosmos DB for NoSQL. Per altre informazioni, vedere gli articoli introduttivi per Azure Data Factory e Azure Synapse Analytics.
Nota
Questo connettore supporta solo Azure Cosmos DB for NoSQL. Per Azure Cosmos DB for MongoDB, fare riferimento al connettore per Azure Cosmos DB for MongoDB. Al momento non sono supportati altri tipi di API.
Funzionalità supportate
Questo connettore Azure Cosmos DB for NoSQL è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR | Endpoint privato gestito |
|---|---|---|
| Attività di copia (origine/sink) | 7.3 | ✓ |
| Flusso di dati di mapping (origine/sink) | 1 | ✓ |
| Attività Lookup | 7.3 | ✓ |
① Runtime di integrazione di Azure ② Runtime di integrazione self-hosted
Per l'attività Copy, il connettore Azure Cosmos DB for NoSQL supporta:
- Copiare dati da e verso Azure Cosmos DB for NoSQL tramite chiave, entità servizio o identità gestite per l'autenticazione delle risorse di Azure.
- Scrivere in Azure Cosmos DB tramite insert o upsert.
- Importare ed esportare documenti JSON come sono o copiare dati da o in un set di dati tabulari, ad esempio un database SQL e un file CSV. Per copiare documenti come sono da o in file JSON oppure da o in un'altra raccolta di Azure Cosmos DB, vedere Importare ed esportare documenti JSON.
Le pipeline di Data Factory e Synapse si integrano con la libreria di esecuzione bulk di Azure Cosmos DB per offrire le migliori prestazioni durante la scrittura in Azure Cosmos DB.
Suggerimento
Il video sulla migrazione dei dati illustra la procedura di copia dei dati da Archiviazione BLOB di Azure ad Azure Cosmos DB. Il video presenta inoltre alcune considerazioni generali sull'ottimizzazione delle prestazioni per l'inserimento di dati in Azure Cosmos DB.
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato ad Azure Cosmos DB usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato ad Azure Cosmos DB nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Azure Cosmos DB for NoSQL e selezionare il connettore Azure Cosmos DB for NoSQL.
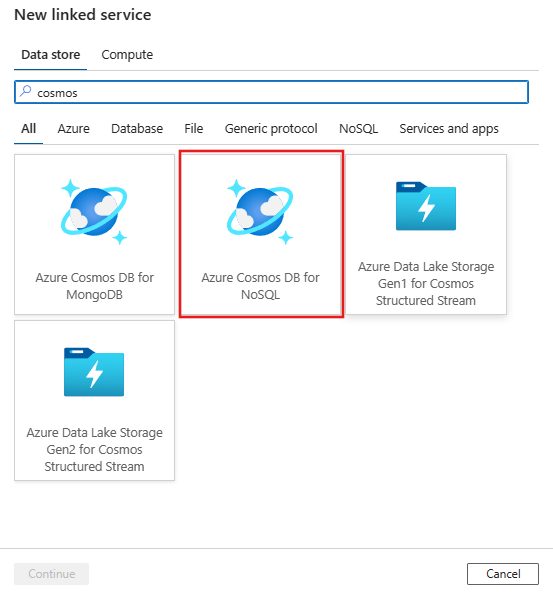
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
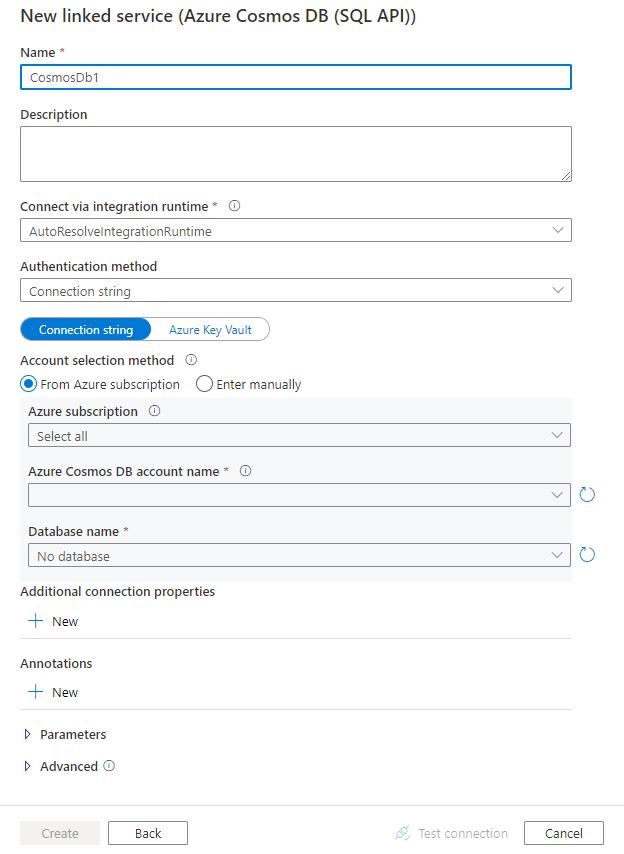
Dettagli di configurazione del connettore
Le sezioni seguenti presentano informazioni dettagliate sulle proprietà che è possibile usare per definire entità specifiche per Azure Cosmos DB for NoSQL.
Proprietà del servizio collegato
Il connettore Azure Cosmos DB for NoSQL supporta i tipi di autenticazione seguenti. Per informazioni dettagliate, vedere le sezioni corrispondenti:
- Autenticazione della chiave
- Autenticazione di un'entità servizio
- Autenticazione dell'identità gestita assegnata dal sistema
- Autenticazione dell'identità gestita assegnata dall'utente
Autenticazione della chiave
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su CosmosDb. | Sì |
| connectionString | Specificare le informazioni richieste per connettersi al database di Azure Cosmos DB. Nota: è necessario specificare le informazioni sul database nella stringa di connessione come illustrato negli esempi seguenti. È anche possibile inserire la chiave dell'account in Azure Key Vault e rimuovere la configurazione di accountKey dalla stringa di connessione. Vedere gli esempi seguenti e l'articolo Archiviare le credenziali in Azure Key Vault per altri dettagli. |
Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se questa proprietà non è specificata, come valore predefinito viene usato Azure Integration Runtime. | No |
Esempio
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;AccountKey=<AccessKey>;Database=<Database>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: archiviare la chiave dell'account in Azure Key Vault
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;Database=<Database>",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'entità servizio
Nota
Attualmente, l'autenticazione tramite entità servizio non è supportata nel flusso di dati.
Per usare l'autenticazione basata sull'entità servizio, eseguire queste operazioni.
Registrare un'applicazione con Microsoft Identity Platform. Per informazioni sulla procedura, vedere Avvio rapido: Registrare un'applicazione in Microsoft Identity Platform. Prendere nota di questi valori che si usano per definire il servizio collegato:
- ID applicazione
- Chiave applicazione
- ID tenant
Concedere all'entità servizio l'autorizzazione appropriata. Per gli esempi di funzionamento dell'autorizzazione in Azure Cosmos DB, vedere Elenchi di controllo di accesso per file e directory. Nello specifico, creare una definizione di ruolo e assegnare il ruolo all'entità servizio tramite l'ID oggetto entità servizio.
Queste sono le proprietà supportate dal servizio collegato:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo deve essere impostata su CosmosDb. | Sì |
| accountEndpoint | Specificare l'URL dell'endpoint dell'account per l'istanza di Azure Cosmos DB. | Sì |
| database | Specificare il nome del database. | Sì |
| servicePrincipalId | Specificare l'ID client dell'applicazione. | Sì |
| servicePrincipalCredentialType | Tipo di credenziale da usare per l'autenticazione dell'entità servizio. I valori consentiti sono ServicePrincipalKey e ServicePrincipalCert. | Sì |
| servicePrincipalCredential | Credenziali dell'entità servizio. Quando si usa ServicePrincipalKey come tipo di credenziale, specificare la chiave dell'applicazione. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro, oppure fare riferimento a un segreto archiviato in Azure Key Vault. Quando si usa ServicePrincipalCert come credenziale, fare riferimento a un certificato in Azure Key Vault e assicurarsi che il tipo di contenuto del certificato sia PKCS #12. |
Sì |
| tenant | Specificare le informazioni sul tenant (nome di dominio o ID tenant) in cui si trova l'applicazione. Recuperarlo passando il cursore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
| azureCloudType | Per l'autenticazione dell'entità servizio, specificare il tipo di ambiente cloud di Azure in cui è registrata l'applicazione Microsoft Entra. I valori consentiti sono AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Per impostazione predefinita, viene usato l'ambiente cloud del servizio. |
No |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio: usare l'autenticazione con chiave dell'entità servizio
È anche possibile archiviare la chiave dell'entità servizio in Azure Key Vault.
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: usare l'autenticazione con certificato dell'entità servizio
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'identità gestita assegnata dal sistema
Nota
L'autenticazione dell'identità gestita assegnata dal sistema è attualmente supportata nei flussi di dati tramite l'uso di proprietà avanzate in formato JSON.
Una pipeline di data factory o di Synapse può essere associata a un'identità gestita assegnata dal sistema per risorse di Azure che rappresenta quella istanza del servizio specifica. È possibile usare direttamente questa identità gestita per l'autenticazione di Azure Cosmos DB, analogamente all'uso dell'entità servizio. Consente alla risorsa designata di accedere e copiare i dati da e verso l'istanza di Azure Cosmos DB.
Per usare le identità gestite assegnate dal sistema per l'autenticazione delle risorse di Azure, eseguire queste operazioni.
Recuperare le informazioni relative all'identità gestita assegnata dal sistema copiando il valore di ID oggetto dell'identità gestita generato con il servizio.
Concedere l'autorizzazione appropriata per l'identità gestita assegnata dal sistema. Per gli esempi di funzionamento dell'autorizzazione in Azure Cosmos DB, vedere Elenchi di controllo di accesso per file e directory. Nello specifico, creare una definizione di ruolo e assegnare il ruolo all'identità gestita assegnata dal sistema.
Queste sono le proprietà supportate dal servizio collegato:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo deve essere impostata su CosmosDb. | Sì |
| accountEndpoint | Specificare l'URL dell'endpoint dell'account per l'istanza di Azure Cosmos DB. | Sì |
| database | Specificare il nome del database. | Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
| subscriptionId | Specificare l’ID sottoscrizione per l'istanza di Azure Cosmos DB | No per l'attività di copia, Sì per il flusso di dati per mapping |
| tenantId | Specificare l’ID tenant per l'istanza di Azure Cosmos DB | No per l'attività di copia, Sì per il flusso di dati per mapping |
| resourceGroup | Specificare il nome del gruppo di risorse per l'istanza di Azure Cosmos DB | No per l'attività di copia, Sì per il flusso di dati per mapping |
Esempio:
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'identità gestita assegnata dall'utente
Nota
L'autenticazione dell'identità gestita assegnata dall’utente è attualmente supportata nei flussi di dati tramite l'uso di proprietà avanzate in formato JSON.
Una pipeline di data factory o di Synapse può essere associata a un'identità gestita assegnata dall'utente che rappresenta quella istanza del servizio specifica. È possibile usare direttamente questa identità gestita per l'autenticazione di Azure Cosmos DB, analogamente all'uso dell'entità servizio. Consente alla risorsa designata di accedere e copiare i dati da e verso l'istanza di Azure Cosmos DB.
Per usare le identità gestite assegnate dall'utente per l'autenticazione delle risorse di Azure, eseguire queste operazioni.
Creare una o più identità gestite assegnate dall'utente e concedere l'autorizzazione appropriata per l'identità gestita assegnata dall'utente. Per gli esempi di funzionamento dell'autorizzazione in Azure Cosmos DB, vedere Elenchi di controllo di accesso per file e directory. Nello specifico, creare una definizione di ruolo e assegnare il ruolo all'identità gestita assegnata dall'utente.
Assegnare una o più identità gestite assegnate dall'utente alla data factory e creare le credenziali per ogni identità gestita assegnata dall'utente.
Queste sono le proprietà supportate dal servizio collegato:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo deve essere impostata su CosmosDb. | Sì |
| accountEndpoint | Specificare l'URL dell'endpoint dell'account per l'istanza di Azure Cosmos DB. | Sì |
| database | Specificare il nome del database. | Sì |
| credentials | Specificare l'identità gestita assegnata dall'utente come oggetto credenziale. | Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
| subscriptionId | Specificare l’ID sottoscrizione per l'istanza di Azure Cosmos DB | No per l'attività di copia, Sì per il flusso di dati per mapping |
| tenantId | Specificare l’ID tenant per l'istanza di Azure Cosmos DB | No per l'attività di copia, Sì per il flusso di dati per mapping |
| resourceGroup | Specificare il nome del gruppo di risorse per l'istanza di Azure Cosmos DB | No per l'attività di copia, Sì per il flusso di dati per mapping |
Esempio:
{
"name": "CosmosDbSQLAPILinkedService",
"properties": {
"type": "CosmosDb",
"typeProperties": {
"accountEndpoint": "<account endpoint>",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"subscriptionId": "<subscription id>",
"tenantId": "<tenant id>",
"resourceGroup": "<resource group>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati e servizi collegati.
Per il set di dati di Azure Cosmos DB for NoSQL sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su CosmosDbSqlApiCollection. | Sì |
| collectionName | Nome della raccolta documenti di Azure Cosmos DB. | Sì |
Se si usa il set di dati di tipo "DocumentDbCollection", è ancora supportato così come è per la compatibilità con le versioni precedenti per l'attività Copy e Lookup, ma non è supportato per il flusso di dati. Si consiglia di usare il nuovo modello in futuro.
Esempio
{
"name": "CosmosDbSQLAPIDataset",
"properties": {
"type": "CosmosDbSqlApiCollection",
"linkedServiceName":{
"referenceName": "<Azure Cosmos DB linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"collectionName": "<collection name>"
}
}
}
Proprietà dell'attività di copia
Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink di Azure Cosmos DB for NoSQL. Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere Pipeline.
Azure Cosmos DB for NoSQL come origine
Per copiare dati da Azure Cosmos DB for NoSQL, impostare il tipo source nell'attività Copy su DocumentDbCollectionSource.
Nella sezione source dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività Copy deve essere impostata su CosmosDbSqlApiSource. | Sì |
| query | Specificare la query Azure Cosmos DB per leggere i dati. Esempio: SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\" |
No Se non specificato, viene eseguita questa istruzione SQL: select <columns defined in structure> from mycollection |
| preferredRegions | Elenco preferito di aree a cui connettersi durante il recupero dei dati da Azure Cosmos DB. | No |
| pageSize | Numero di documenti per pagina del risultato della query. Il valore predefinito è "-1" che indica l'uso delle dimensioni di pagina dinamiche sul lato servizio fino a 1000. | No |
| detectDatetime | Indica se rilevare datetime dai valori stringa nei documenti. I valori consentiti sono: true (predefinito), false. | No |
Se si usa l'origine di tipo "DocumentDbCollectionSource", è ancora supportata così come è per la compatibilità con le versioni precedenti. Si consiglia di usare il nuovo modello in futuro che offre funzionalità più avanzate per copiare dati da Azure Cosmos DB.
Esempio
"activities":[
{
"name": "CopyFromCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cosmos DB for NoSQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CosmosDbSqlApiSource",
"query": "SELECT c.BusinessEntityID, c.Name.First AS FirstName, c.Name.Middle AS MiddleName, c.Name.Last AS LastName, c.Suffix, c.EmailPromotion FROM c WHERE c.ModifiedDate > \"2009-01-01T00:00:00\"",
"preferredRegions": [
"East US"
]
},
"sink": {
"type": "<sink type>"
}
}
}
]
Quando si copiano dati da Azure Cosmos DB, a meno che non si vogliano esportare documenti JSON così come sono, è consigliabile specificare il mapping nell'attività Copy. Il servizio rispetta il mapping specificato nell'attività. Se una riga non contiene un valore per una colonna, viene fornito un valore null per il valore della colonna. Se non si specifica un mapping, il servizio deduce lo schema usando la prima riga dei dati. Se la prima riga non contiene lo schema completo, alcune colonne non saranno presenti nel risultato dell'operazione dell'attività.
Azure Cosmos DB for NoSQL come sink
Per copiare dati in Azure Cosmos DB for NoSQL, impostare il tipo sink nell'attività Copy su DocumentDbCollectionSink.
Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività Copy deve essere impostata su CosmosDbSqlApiSink. | Sì |
| writeBehavior | Descrive come scrivere i dati in Azure Cosmos DB. Valori consentiti: insert e upsert. Il comportamento di upsert consiste nella sostituzione del documento se esiste già un documento con lo stesso ID. In caso contrario, il documento viene inserito. Nota: il servizio genera automaticamente un ID per un documento se non è specificato un ID nel documento originale o tramite il mapping di colonna. È quindi necessario assicurarsi che il documento contenga un ID in modo che upsert funzioni come previsto. |
No (il valore predefinito è insert) |
| writeBatchSize | Il servizio usa la libreria dell'esecuzione bulk di Azure Cosmos DB per scrivere dati in Azure Cosmos DB. La proprietà writeBatchSize controlla le dimensioni dei documenti forniti dal servizio alla libreria. È possibile provare ad aumentare il valore per writeBatchSize per migliorare le prestazioni e a ridurre il valore se le dimensioni dei documenti diventano grandi. Vedere i suggerimenti di seguito. | No (il valore predefinito è 10.000) |
| disableMetricsCollection | Il servizio raccoglie metriche come le UR di Azure Cosmos DB per l'ottimizzazione delle prestazioni di copia e per fornire consigli. Se questo comportamento non è desiderato, specificare true per disattivarlo. |
No (il valore predefinito è false) |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
Suggerimento
Per importare documenti JSON come sono, fare riferimento alla sezione Importare o esportare documenti JSON. Per copiare da dati in forma tabulare, fare riferimento a Eseguire la migrazione dal database relazionale ad Azure Cosmos DB.
Suggerimento
Azure Cosmos DB limita le dimensioni per una singola richiesta a 2 MB. La formula è Dimensioni richiesta = Dimensioni singolo documento * Dimensioni batch di scrittura. Se viene generato l'errore "Dimensioni della richiesta troppo grandi.", ridurre il valore writeBatchSize nella configurazione del sink di copia.
Se si usa l'origine di tipo "DocumentDbCollectionSink", è ancora supportata così come è per la compatibilità con le versioni precedenti. Si consiglia di usare il nuovo modello in futuro che offre funzionalità più avanzate per copiare dati da Azure Cosmos DB.
Esempio
"activities":[
{
"name": "CopyToCosmosDBSQLAPI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "CosmosDbSqlApiSink",
"writeBehavior": "upsert"
}
}
}
]
Mapping dello schema
Per copiare dati da Azure Cosmos DB in un sink tabulare o viceversa, fare riferimento al mapping dello schema.
Proprietà del flusso di dati per mapping
Quando si trasformano i dati nel flusso di dati per mapping, è possibile leggere e scrivere nelle raccolte in Azure Cosmos DB. Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati per mapping.
Nota
Azure Cosmos DB serverless non è supportato nel flusso di dati per mapping.
Trasformazione origine
Le impostazioni specifiche di Azure Cosmos DB sono disponibili nella scheda Opzioni origine della trasformazione origine.
Includi colonne di sistema: se true, id, _ts, e altre colonne di sistema verranno incluse nei metadati del flusso di dati da Azure Cosmos DB. Quando si aggiornano le raccolte, è importante includerle per poter recuperare l'ID di riga esistente.
Dimensioni pagina: numero di documenti per pagina del risultato della query. Il valore predefinito è "-1" che usa la pagina dinamica del servizio fino a 1000.
Velocità effettiva: impostare un valore facoltativo per il numero di UR da applicare alla raccolta di Azure Cosmos DB per ogni esecuzione di questo flusso di dati durante l'operazione di lettura. Il valore minimo è 400.
Aree preferite: scegliere le aree di lettura preferite per questo processo.
Feed di modifiche: se true, si otterranno i dati dal feed di modifiche di Azure Cosmos DB, ovvero un record permanente delle modifiche apportate a un contenitore nell'ordine in cui si verificano dall'ultima esecuzione automaticamente. Quando si imposta true, non impostare entrambe le opzioni Deduci tipi di colonna con deriva e Consenti spostamento schema su true contemporaneamente. Per altri dettagli, vedere Feed di modifiche di Azure Cosmos DB.
Avvia dall'inizio: se true, si otterrà il caricamento iniziale dei dati completi dello snapshot nella prima esecuzione, seguito dall'acquisizione dei dati modificati nelle esecuzioni successive. Se false, il caricamento iniziale verrà ignorato nella prima esecuzione, seguito dall'acquisizione dei dati modificati nelle esecuzioni successive. L'impostazione è allineata allo stesso nome di impostazione nelle informazioni di riferimento su Azure Cosmos DB. Per altri dettagli, vedere Feed di modifiche di Azure Cosmos DB.
Trasformazione sink
Le impostazioni specifiche di Azure Cosmos DB sono disponibili nella scheda Impostazioni della trasformazione sink.
Metodo update: determina le operazioni consentite nella destinazione del database. Per impostazione predefinita, sono consentiti solo gli inserimenti. Per eseguire operazioni di aggiornamento, upsert o eliminazione di righe, è necessaria una trasformazione alter-row che applichi alle righe i tag corrispondenti alle azioni. Per le operazioni di aggiornamento, upsert ed eliminazione è necessario impostare una o più colonne chiave per determinare quale riga modificare.
Azione di raccolta: determina se ricreare la raccolta di destinazione prima della scrittura.
- Nessuna: non verrà eseguita alcuna azione sulla raccolta.
- Ricrea: la raccolta verrà eliminata e ricreata
Dimensioni batch: numero intero che rappresenta il numero di oggetti scritti nella raccolta di Azure Cosmos DB in ogni batch. In genere, è sufficiente partire dalle dimensioni batch predefinite. Per mettere a punto questo valore, notare quanto segue:
- Azure Cosmos DB limita le dimensioni per una singola richiesta a 2 MB. La formula è "Dimensioni richiesta = Dimensioni singolo documento * Dimensioni batch". Se si verifica un errore che indica che la dimensione della richiesta è troppo grande, ridurre il valore delle dimensioni del batch.
- Più grande è il batch, maggiore è la velocità effettiva che il servizio può ottenere, assicurandosi di allocare sufficienti UR per supportare il carico di lavoro.
Chiave di partizione: immettere una stringa che rappresenta la chiave di partizione per la raccolta. Esempio: /movies/title
Velocità effettiva: impostare un valore facoltativo per il numero di UR da applicare alla raccolta di Azure Cosmos DB per ogni esecuzione di questo flusso di dati. Il valore minimo è 400.
Budget della velocità effettiva di scrittura: numero intero che rappresenta le UR da allocare per questa operazione di scrittura del flusso di dati, dalla velocità effettiva totale allocata alla raccolta.
Nota
Per limitare l'utilizzo delle UR, impostare Velocità effettiva (scalabilità automatica) per Cosmos DB su Manuale.
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Importare ed esportare documenti JSON
È possibile usare questo connettore Azure Cosmos DB for NoSQL per eseguire facilmente le operazioni seguenti:
- Copiare documenti come sono da una raccolta di Azure Cosmos DB a un'altra.
- Importare in Azure Cosmos DB documenti JSON da varie origini, tra cui Archiviazione BLOB di Azure, Azure Data Lake Storage e altri archivi basati su file supportati dal servizio.
- Esportare documenti JSON da una raccolta di Azure Cosmos DB in diversi archivi basati su file.
Per ottenere la copia senza schema:
- Quando si usa lo strumento Copia dati, selezionare l'opzione Esporta così com'è in file JSON o in una raccolta di Azure Cosmos DB.
- Quando si usa la creazione di attività, scegliere il formato JSON con l'archivio file corrispondente per l'origine o il sink.
Eseguire la migrazione dal database relazionale ad Azure Cosmos DB
Quando si esegue la migrazione da un database relazionale come SQL Server ad Azure Cosmos DB, l'attività Copy può eseguire facilmente il mapping dei dati tabulari dall'origine a documenti JSON resi flat in Azure Cosmos DB. In alcuni casi, è possibile riprogettare il modello di dati per ottimizzarlo per i casi d'uso NoSQL in base alla modellazione dei dati in Azure Cosmos DB, ad esempio, per annullare la normalizzazione dei dati incorporando tutti gli elementi secondari correlati all'interno di un documento JSON. Per questo caso, fare riferimento a questo articolo con una procedura dettagliata su come ottenere questo risultato usando l'attività Copy.
Feed di modifiche di Azure Cosmos DB
Azure Data Factory può recuperare dati dal feed di modifiche di Azure Cosmos DB abilitandolo nella trasformazione origine del flusso di dati per mapping. Con questa opzione del connettore è possibile leggere i feed di modifiche e applicare trasformazioni prima di caricare i dati trasformati nei set di dati di destinazione desiderati. Non è necessario usare funzioni di Azure per leggere il feed di modifiche e quindi scrivere trasformazioni personalizzate. È possibile usare questa opzione per spostare i dati da un contenitore a un altro, preparare le visualizzazioni materiali basate sul feed di modifiche per scopi di adattamento o automatizzare il backup o il ripristino dei contenitori in base al feed di modifiche e abilitare molti altri casi d'uso usando la funzionalità di trascinamento e rilascio visiva di Azure Data Factory.
Accertarsi di mantenere invariato il nome della pipeline e dell'attività, in modo che il checkpoint possa essere registrato da ADF per ottenere automaticamente i dati modificati dall'ultima esecuzione. Se si modifica il nome della pipeline o il nome dell'attività, il checkpoint verrà reimpostato, il che porta a ricominciare dall'inizio o a ottenere le modifiche da subito nella successiva esecuzione.
Quando si esegue il debug della pipeline, questa funzionalità funziona allo stesso modo. Tenere presente che il checkpoint verrà reimpostato quando si aggiorna il browser durante l'esecuzione del debug. Quando il risultato della pipeline dall'esecuzione del debug è soddisfacente, è possibile procedere alla pubblicazione e all'attivazione della pipeline. Al momento della prima attivazione della pipeline pubblicata, la pipeline viene riavviata automaticamente dall'inizio o ottiene le modifiche da tale momento in avanti.
Nella sezione di monitoraggio, è sempre possibile eseguire nuovamente una pipeline. Quando si esegue questa operazione, i dati modificati vengono sempre acquisiti dal checkpoint precedente dell'esecuzione della pipeline selezionata.
Inoltre, l'archivio analitico di Azure Cosmos DB supporta ora Change Data Capture (CDC) per l'API Azure Cosmos DB for NoSQL e l'API Azure Cosmos DB per Mongo DB (anteprima pubblica). L'archivio analitico di Azure Cosmos DB consente di usare in modo efficiente un feed continuo e incrementale di dati modificati (inseriti, aggiornati ed eliminati) dall'archivio analitico.
Contenuto correlato
Per un elenco degli archivi dati supportati dall'attività Copy come origini e sink, vedere Archivi dati supportati.