Inserire dati da Apache Kafka in Azure Esplora dati
Apache Kafka è una piattaforma di streaming distribuito per la creazione di pipeline di dati in streaming in tempo reale che consente di spostare in modo affidabile i dati tra applicazioni o sistemi. Kafka Connect è uno strumento per lo streaming scalabile e affidabile di dati tra Apache Kafka e altri sistemi. Il sink Kafka Kusto funge da connettore a Kafka e non richiede l'uso del codice. Scaricare il file jar del connettore sink dal Repository Git o dall'Hub del connettore Confluent.
Questo articolo illustra come inserire dati con Kafka usando un installatore di Docker autonomo per semplificare la configurazione del cluster Kafka e del cluster del connettore Kafka.
Per altre informazioni, vedere il Repository Git del connettore e le specifiche della versione.
Prerequisiti
- Una sottoscrizione di Azure. Creare un account Azure gratuito.
- Un cluster e un database di Azure Esplora dati con i criteri di conservazione e cache predefiniti.
- Interfaccia della riga di comando di Azure.
- Docker e Docker Compose.
Creare un'entità servizio Microsoft Entra
L'entità servizio Microsoft Entra può essere creata tramite il portale di Azure o a livello di programmazione, come nell'esempio seguente.
Questa entità servizio è l'identità usata dal connettore per scrivere dati nella tabella in Kusto. Si possono concedere le autorizzazioni a questa entità servizio per accedere alle risorse Kusto.
Accedere alla sottoscrizione di Azure usando l'interfaccia della riga di comando di Azure. Eseguire quindi l'autenticazione nel browser.
az loginScegliere la sottoscrizione per ospitare l'entità di sicurezza. Questo passaggio è necessario quando si hanno più sottoscrizioni.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCreare l'entità servizio. In questo esempio l'entità servizio viene chiamata
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Dai dati JSON restituiti copiare
appId,passwordetenantper un uso futuro.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
L'applicazione Microsoft Entra e l'entità servizio sono state create.
Creare una tabella di destinazione
Nell'ambiente query creare una tabella denominata
Stormsusando il comando seguente:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Creare il mapping della tabella corrispondente
Storms_CSV_Mappingper i dati inseriti usando il comando seguente:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Creare un criterio di inserimento in batch nella tabella per la latenza di inserimento in coda configurabile.
Suggerimento
I criteri di inserimento in batch sono un’ottimizzazione per le prestazioni e comprendono tre parametri. La prima condizione soddisfatta attiva l'inserimento nella tabella.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Usare l'entità servizio da Creare un'entità servizio Microsoft Entra per concedere l'autorizzazione a lavorare con il database.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Eseguire il lab
Il lab seguente è progettato per offrire l'esperienza di iniziare a creare dati, configurare il connettore Kafka e trasmettere questi dati. È quindi possibile esaminare i dati inseriti.
Clonare il repository Git
Clonare il repository Git del lab.
Creare una directory locale sul proprio computer.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holclonare il repository.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Contenuto del repository clonato
Eseguire il comando seguente per elencare il contenuto del repository clonato:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Il risultato della ricerca è:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Esaminare i file nel repository clonato
Le sezioni seguenti illustrano le parti importanti dei file nell'albero dei file.
adx-sink-config.json
Questo file contiene il file delle proprietà del sink Kusto in cui si aggiornano dettagli di configurazione specifici:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Sostituire i valori per gli attributi seguenti in base all'installazione: aad.auth.authority, aad.auth.appid, aad.auth.appkey, kusto.tables.topics.mapping (nome del database), kusto.ingestion.url e kusto.query.url.
Connettore - Dockerfile
Questo file comprende i comandi per generare l'immagine Docker per l'istanza del connettore. Comprende il download del connettore dalla release directory del git repository.
Directory Storm-events-producer
Questa directory comprende un programma Go che legge un file "StormEvents.csv" locale e pubblica i dati in un argomento Kafka.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Avviare i contenitori
Avviare i contenitori sul proprio computer:
docker-compose upL'applicazione producer inizierà a inviare eventi all'argomento
storm-events. I log visibili dovrebbero essere simili ai seguenti:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Per verificare i log eseguire il seguente comando in un altro computer:
docker-compose logs -f | grep kusto-connect
Avviare il connettore
Usare una chiamata REST Kafka Connect per avviare il connettore.
In un altro computer avviare l'attività sink con il comando seguente:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsEseguire il seguente comando in un altro computer per verificare lo stato:
curl http://localhost:8083/connectors/storm/status
Il connettore avvia i processi di inserimento in coda.
Nota
In caso di problemi del connettore di log, creare un problema.
Identità gestita
Per impostazione predefinita, il connettore Kafka usa il metodo dell'applicazione per l'autenticazione durante l'inserimento. Per eseguire l'autenticazione con l'identità gestita:
Assegnare al cluster un'identità gestita e concedere all'account di archiviazione le autorizzazioni di lettura. Per altre informazioni, vedere Inserire dati usando l'autenticazione dell'identità gestita.
Nel file adx-sink-config.json impostare
aad.auth.strategymanaged_identitysu e assicurarsi cheaad.auth.appidsia impostato sull'ID client di identità gestita (applicazione).Usare un token del servizio metadati dell'istanza privata anziché l'entità servizio Microsoft Entra.
Nota
Quando si usa un'identità appId gestita e tenant viene dedotto dal contesto del sito di chiamata e password non è necessario.
Eseguire una query ed esaminare i dati
Confermare l'inserimento dei dati
Dopo che i dati sono arrivati nella tabella
Storms, confermare il trasferimento dei dati controllando il conteggio delle righe:Storms | countVerificare che non siano presenti errori nel processo di inserimento:
.show ingestion failuresDopo aver visualizzato i dati, provare alcune query.
Eseguire una query sui dati
Per visualizzare tutti i record eseguire la query seguente:
Storms | take 10Usare
whereeprojectper filtrare dati specifici:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdUsare l'operatore
summarize:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart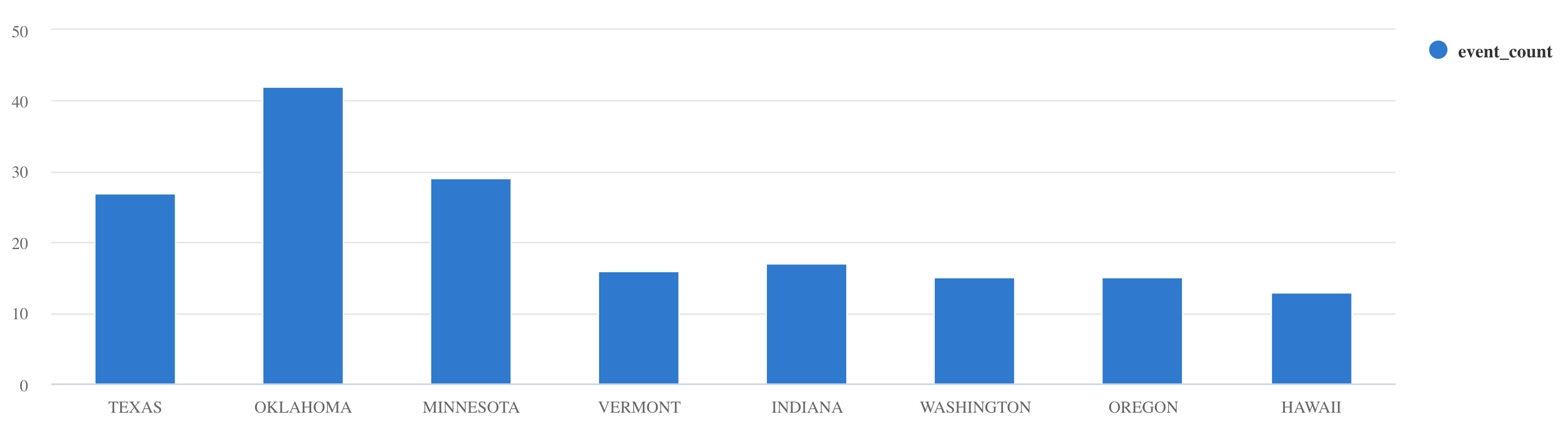
Per altri esempi di query e indicazioni, vedere Scrivere query in KQL e Documentazione sul Linguaggio di query Kusto.
Reset (Ripristina)
Per ripristinare, seguire questa procedura:
- Arrestare i contenitori (
docker-compose down -v) - Elimina (
drop table Storms) - Creare la tabella
Storms - Creare nuovamente i mapping della tabella
- Riavviare i contenitori (
docker-compose up)
Pulire le risorse
Per eliminare le risorse di Azure Esplora dati, usare az kusto cluster delete (estensione kusto) o az kusto database delete (estensione kusto):To delete the Azure Esplora dati resources, use az kusto cluster delete (kusto extension) or az kusto database delete (kusto extension):
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
È anche possibile eliminare il cluster e il database tramite il portale di Azure. Per altre informazioni, vedere Eliminare un cluster di Azure Esplora dati ed Eliminare un database in Azure Esplora dati.
Ottimizzazione del connettore Sink Kafka
Ottimizzare il connettore Sink Kafka per lavorare con i criteri di inserimento in batch:
- Ottimizzare il limite di dimensioni del sink Kafka
flush.size.bytesa partire da 1 MB, aumentando con degli incrementi di 10 MB o 100 MB. - Quando si usa il sink Kafka, i dati vengono aggregati due volte. I dati sul lato connettore vengono aggregati in base alle impostazioni di scaricamento e sul lato servizio in base ai criteri di invio in batch. Se il tempo di invio in batch è troppo breve e i dati non possono essere inseriti sia dal connettore che dal servizio, è necessario aumentare il tempo di invio in batch. Impostare le dimensioni di invio in batch a 1 GB e aumentare o diminuire con degli incrementi di 100 MB in base alle esigenze. Ad esempio, se le dimensioni dello scaricamento sono pari a 1 MB e le dimensioni dei criteri di invio in batch sono pari a 100 MB, il connettore Sink Kafka aggrega i dati in un batch di 100 MB. Tale batch viene quindi inserito dal servizio. Se il tempo dei criteri di invio in batch è di 20 secondi e il connettore Sink Kafka scarica 50 MB in un periodo di 20 secondi, il servizio inserisce un batch di 50 MB.
- È possibile ridimensionare aggiungendo istanze e partizioni Kafka. Aumentare
tasks.maxal numero di partizioni. Creare una partizione se i dati sono sufficienti a produrre un BLOB delle dimensioni dell'impostazioneflush.size.bytes. Se il BLOB è più piccolo, il batch viene elaborato quando raggiunge il limite di tempo, quindi la partizione non riceve una produttività sufficiente. Un numero elevato di partizioni comporta un sovraccarico di elaborazione maggiore.
Contenuto correlato
- Altre informazioni sull'architettura di Big Data.
- Informazioni su come inserire dati di esempio in formato JSON in Azure Esplora dati.
- Altre informazioni con i lab Kafka: