Ottenere dati da Amazon S3
L'inserimento dati è il processo usato per caricare dati da una o più origini in una tabella in Azure Esplora dati. Una volta inseriti, i dati diventano disponibili per le query. Questo articolo illustra come ottenere dati da Amazon S3 in una tabella nuova o esistente.
Per maggiori informazioni su Amazon S3, vedi Che cos'è Amazon S3?.
Per informazioni generali sull'inserimento dati, vedere Panoramica dell'inserimento di dati in Azure Esplora dati.
Prerequisiti
- Un account Microsoft o un'identità utente di Microsoft Entra. Non è necessaria una sottoscrizione di Azure.
- Accedere all'interfaccia utente Web di Azure Esplora dati.
- Un cluster e un database di Esplora dati di Azure. Creare un cluster e un database.
Ottenere dati
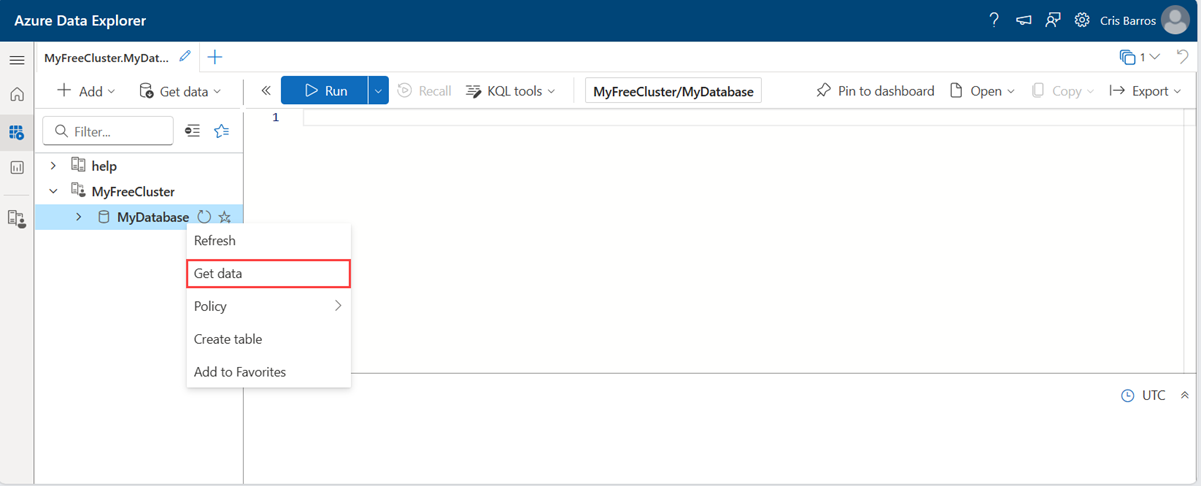
Scegliere Query dal menu a sinistra.
Fare clic con il pulsante destro del mouse sul database in cui si desidera inserire i dati e quindi scegliere Recupera dati.

Origine
Nella finestra Ottieni dati è selezionata la scheda Origine.
Selezionare l'origine dati dall'elenco disponibile. In questo esempio si inseriscono dati da Amazon S3.

Configurare
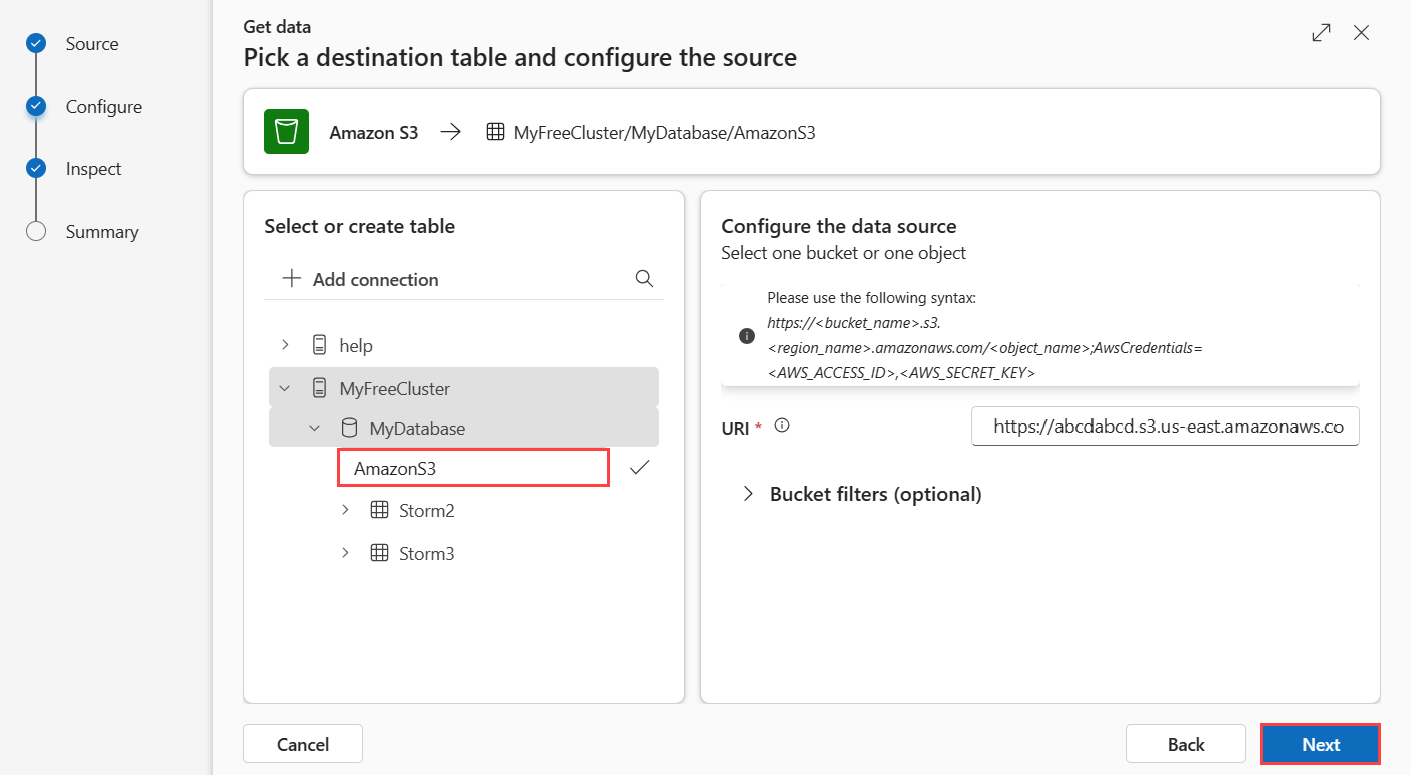
Selezionare un database e una tabella di destinazione. Se si desidera inserire dati in una nuova tabella, selezionare +Nuova tabella e immettere un nome tabella.
Nota
I nomi delle tabelle possono avere un massimo di 1.024 caratteri, inclusi spazi, caratteri alfanumerici, trattini e trattini bassi. I caratteri speciali non sono supportati.
Nel campo URI incollare la stringa di connessione di un singolo bucket o un singolo oggetto nel formato seguente.
Bucket:
https://BucketName.s3.RegionName.amazonaws.comOggetto: ObjectName
;AwsCredentials=AwsAccessID,AwsSecretKeyÈ facoltativo applicare filtri bucket per filtrare i dati in base a un'estensione di file specifica.
Nota
L'inserimento supporta file di dimensione massima di 6 GB. È consigliabile inserire file di dimensione compresa tra 100 MB e 1 GB.
Selezionare Avanti.

Controllare
Viene visualizzata la scheda inspect con un'anteprima dei dati.
Selezionare Fine per completare il processo di inserimento.

Facoltativo:
- Selezionare Command viewer per visualizzare e copiare i comandi automatici generati dagli input.
- Usare il menù a discesa File di definizione dello schema per modificare il file da cui viene dedotto lo schema.
- Modificare il formato dei dati dedotti automaticamente selezionando il formato desiderato dal menu a tendina. Per l'inserimento, vedere Formati di dati supportati da Azure Esplora dati.
- Modifica colonne.
- Esplorare le Opzioni avanzate in base al tipo di dati.
Modifica colonne
Nota
- Per i formati tabulari (CSV, TSV, PSV), non è possibile eseguire il mapping di una colonna due volte. Per eseguire il mapping a una colonna esistente, eliminare prima quella nuova.
- Non è possibile modificare un tipo di colonna esistente. Se si tenta di eseguire il mapping su una colonna con un formato diverso, è possibile che appaiano colonne vuote.
Le modifiche che è possibile apportare in una tabella dipendono dai parametri seguenti:
- Il tipo di tabella è nuovo o esistente
- Il tipo di mapping è nuovo o esistente
| Tipo di tabella | Tipo di mapping | Modifiche disponibili |
|---|---|---|
| Nuova tabella | Nuovo mapping | Rinominare la colonna, modificare il tipo di dati, modificare l'origine dati, eseguire la Trasformazione del mapping, aggiungere una colonna, eliminare una colonna |
| Tabella esistente | Nuovo mapping | Aggiungi colonna (per cui è poi possibile cambiare il tipo di dati, rinominare e aggiornare) |
| Tabella esistente | Mapping esistente | Nessuno |

Trasformazioni del mapping
Alcuni mapping del formato dati (Parquet, JSON e Avro) supportano semplici trasformazioni in fase di inserimento. Per applicare le trasformazioni del mapping, creare o aggiornare una colonna nella finestra Modifica colonne.
Le trasformazioni del mapping possono essere eseguite su una colonna di tipo string o date/time, con l'origine che ha un tipo di dati int o long. Le trasformazioni del mapping supportate sono:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opzioni avanzate in base al tipo di dati
Tabulare (CSV, TSV, PSV):
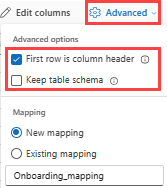
Se si inseriscono formati tabulari in una tabella esistente, è possibile selezionare Avanzate>Mantieni lo schema della tabella corrente. I dati tabulari non comprendono necessariamente i nomi di colonna usati per eseguire il mapping dei dati di origine sulle colonne esistenti. Quando questa opzione è selezionata, il mapping viene eseguito in base all'ordine e lo schema della tabella rimane invariato. Se questa opzione è deselezionata, vengono create nuove colonne per i dati in ingresso, indipendentemente dalla struttura dei dati.
Per usare la prima riga come nomi di colonna, selezionare Avanzate>Prima riga è intestazione di colonna.
JSON:
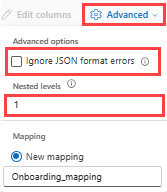
Per determinare la divisione delle colonne dei dati JSON, selezionare Avanzate>Livelli annidati, da 1 a 100.
Se si seleziona Ignora errori di formato dati avanzati>, i dati vengono inseriti in formato JSON. Se si lascia deselezionata questa casella di controllo, i dati vengono inseriti in formato multijson.
Riepilogo
Nella finestra Preparazione dei dati, tutti e tre i passaggi sono contrassegnati con segni di spunta verdi quando l'inserimento dati si conclude con successo. È possibile visualizzare i comandi usati per ogni passaggio oppure selezionare una scheda per eseguire query, visualizzare o eliminare i dati inseriti.
