Slurm
Slurm è un gestore di carichi di lavoro altamente configurabile open source. Per una panoramica, vedere il sito del progetto Slurm .
Nota
A partire da CycleCloud 8.4.0, l'integrazione Slurm è stata riscritta per supportare nuove funzionalità e funzionalità. Per altre informazioni, vedere la documentazione di Slurm 3.0 .
Slurm può essere facilmente abilitato in un cluster CycleCloud modificando "run_list" nella sezione di configurazione della definizione del cluster. I due componenti di base di un cluster Slurm sono il nodo 'master' (o 'scheduler') che fornisce un file system condiviso in cui viene eseguito il software Slurm e i nodi 'execute' che sono gli host che montano il file system condiviso ed eseguono i processi inviati. Ad esempio, un semplice frammento di modello di cluster può essere simile al seguente:
[cluster custom-slurm]
[[node master]]
ImageName = cycle.image.centos7
MachineType = Standard_A4 # 8 cores
[[[cluster-init cyclecloud/slurm:default]]]
[[[cluster-init cyclecloud/slurm:master]]]
[[[configuration]]]
run_list = role[slurm_master_role]
[[nodearray execute]]
ImageName = cycle.image.centos7
MachineType = Standard_A1 # 1 core
[[[cluster-init cyclecloud/slurm:default]]]
[[[cluster-init cyclecloud/slurm:execute]]]
[[[configuration]]]
run_list = role[slurm_master_role]
slurm.autoscale = true
# Set to true if nodes are used for tightly-coupled multi-node jobs
slurm.hpc = true
slurm.default_partition = true
Slurm può essere facilmente abilitato in un cluster CycleCloud modificando "run_list" nella sezione di configurazione della definizione del cluster. I due componenti di base di un cluster Slurm sono il nodo 'scheduler' che fornisce un file system condiviso in cui viene eseguito il software Slurm e i nodi "execute" che sono gli host che montano il file system condiviso ed eseguono i processi inviati. Ad esempio, un semplice frammento di modello di cluster può essere simile al seguente:
[cluster custom-slurm]
[[node scheduler]]
ImageName = cycle.image.centos7
MachineType = Standard_A4 # 8 cores
[[[cluster-init cyclecloud/slurm:default]]]
[[[cluster-init cyclecloud/slurm:scheduler]]]
[[[configuration]]]
run_list = role[slurm_scheduler_role]
[[nodearray execute]]
ImageName = cycle.image.centos7
MachineType = Standard_A1 # 1 core
[[[cluster-init cyclecloud/slurm:default]]]
[[[cluster-init cyclecloud/slurm:execute]]]
[[[configuration]]]
run_list = role[slurm_scheduler_role]
slurm.autoscale = true
# Set to true if nodes are used for tightly-coupled multi-node jobs
slurm.hpc = true
slurm.default_partition = true
Modifica di cluster Slurm esistenti
I cluster Slurm in esecuzione in CycleCloud versione 7.8 e successive implementano una versione aggiornata delle API di scalabilità automatica che consente ai cluster di usare più nodearray e partizioni. Per facilitare questa funzionalità in Slurm, CycleCloud precompila i nodi di esecuzione nel cluster. Per questo motivo, è necessario eseguire un comando nel nodo dell'utilità di pianificazione Slurm dopo aver apportato modifiche al cluster, ad esempio limiti di scalabilità automatica o tipi di vm.
Apportare modifiche al cluster
Il cluster Slurm distribuito in CycleCloud contiene uno script che facilita questa operazione. Dopo aver apportato modifiche al cluster, eseguire quanto segue come radice (ad esempio eseguendo sudo -i) nel nodo dell'utilità di pianificazione Slurm per ricompilare e slurm.conf aggiornare i nodi nel cluster:
/opt/cycle/slurm/cyclecloud_slurm.sh remove_nodes
/opt/cycle/slurm/cyclecloud_slurm.sh scale
Nota
Per CycleCloud versioni < 7.9.10, lo cyclecloud_slurm.sh script si trova in /opt/cycle/jetpack/system/bootstrap/slurm.
Importante
Se si apportano modifiche che influiscono sulle macchine virtuali per i nodi in una partizione MPI ,ad esempio dimensioni della macchina virtuale, immagine o cloud-init, i nodi devono essere terminati per primi.
Il remove_nodes comando stampa un avviso in questo caso, ma non viene chiuso con un errore.
Se sono presenti nodi in esecuzione, verrà visualizzato un errore relativo all'avvio di This node does not match existing scaleset attribute nuovi nodi.
/opt/cycle/slurm/cyclecloud_slurm.sh apply_changes
Nota
Per CycleCloud versione < 8.2, lo cyclecloud_slurm.sh script si trova in /opt/cycle/jetpack/system/bootstrap/slurm.
Se si apportano modifiche che influiscono sulle macchine virtuali per i nodi in una partizione MPI ,ad esempio dimensioni della macchina virtuale, immagine o cloud-init, e i nodi sono in esecuzione, verrà visualizzato un errore relativo all'avvio di This node does not match existing scaleset attribute nuovi nodi. Per questo motivo, il apply_changes comando verifica che i nodi vengano terminati e abbia esito negativo con il seguente messaggio di errore, in caso contrario: i nodi seguenti devono essere terminati completamente prima di applicare le modifiche.
Se si apporta una modifica che non influisce sulle proprietà della macchina virtuale per i nodi MPI, non è prima necessario terminare i nodi in esecuzione. In questo caso, è possibile apportare le modifiche usando i due comandi seguenti:
/opt/cycle/slurm/cyclecloud_slurm.sh remove_nodes
/opt/cycle/slurm/cyclecloud_slurm.sh scale
Nota
Il apply_changes comando esiste solo in CycleCloud 8.3+, quindi l'unico modo per apportare una modifica nelle versioni precedenti è con i comandi precedenti + remove_nodesscale.
Assicurarsi che il remove_nodes comando non stampa un avviso sui nodi che devono essere terminati.
Creazione di partizioni aggiuntive
Il modello predefinito fornito con Azure CycleCloud include due partizioni (hpc e htc) ed è possibile definire oggetti nodearray personalizzati che eseguono il mapping direttamente alle partizioni Slurm. Ad esempio, per creare una partizione GPU, aggiungere la sezione seguente al modello di cluster:
[[nodearray gpu]]
MachineType = $GPUMachineType
ImageName = $GPUImageName
MaxCoreCount = $MaxGPUExecuteCoreCount
Interruptible = $GPUUseLowPrio
AdditionalClusterInitSpecs = $ExecuteClusterInitSpecs
[[[configuration]]]
slurm.autoscale = true
# Set to true if nodes are used for tightly-coupled multi-node jobs
slurm.hpc = false
[[[cluster-init cyclecloud/slurm:execute:2.0.1]]]
[[[network-interface eth0]]]
AssociatePublicIpAddress = $ExecuteNodesPublic
Impostazioni di memoria
CycleCloud imposta automaticamente la quantità di memoria disponibile per Slurm da usare a scopo di pianificazione. Poiché la quantità di memoria disponibile può cambiare leggermente a causa di diverse opzioni del kernel Linux e il sistema operativo e la macchina virtuale possono usare una piccola quantità di memoria che altrimenti sarebbe disponibile per i processi, CycleCloud riduce automaticamente la quantità di memoria nella configurazione Slurm. Per impostazione predefinita, CycleCloud mantiene il 5% della memoria disponibile segnalata in una macchina virtuale, ma questo valore può essere sottoposto a override nel modello di cluster impostando slurm.dampen_memory la percentuale di memoria da conservare. Ad esempio, per conservare il 20% della memoria di una macchina virtuale:
slurm.dampen_memory=20
Disabilitazione della scalabilità automatica per nodi o partizioni specifici
Anche se la funzionalità predefinita CycleCloud "KeepAlive" non funziona attualmente per i cluster Slurm, è possibile disabilitare la scalabilità automatica per un cluster Slurm in esecuzione modificando direttamente il file slurm.conf. È possibile escludere singoli nodi o intere partizioni dalla scalabilità automatica.
Esclusione di un nodo
Per escludere un nodo o più nodi dalla scalabilità automatica, aggiungere SuspendExcNodes=<listofnodes> al file di configurazione Slurm. Ad esempio, per escludere i nodi 1 e 2 dalla partizione hpc, aggiungere quanto segue a /sched/slurm.conf:
SuspendExcNodes=hpc-pg0-[1-2]
Riavviare quindi il slurmctld servizio per rendere effettiva la nuova configurazione.
Esclusione di una partizione
L'esclusione di intere partizioni dalla scalabilità automatica è simile all'esclusione dei nodi. Per escludere l'intera hpc partizione, aggiungere quanto segue a /sched/slurm.conf
SuspendExcParts=hpc
Riavviare quindi il slurmctld servizio.
Risoluzione dei problemi
Conflitti UID per gli utenti Slurm e Munge
Per impostazione predefinita, questo progetto usa un UID e un GID di 11100 per l'utente Slurm e 11101 per l'utente Munge. Se ciò causa un conflitto con un altro utente o gruppo, è possibile eseguire l'override di queste impostazioni predefinite.
Per eseguire l'override dell'UID e del GID, fare clic sul pulsante modifica per entrambi i scheduler nodi:


E nodearray execute : 
e aggiungere gli attributi seguenti alla Configuration sezione :
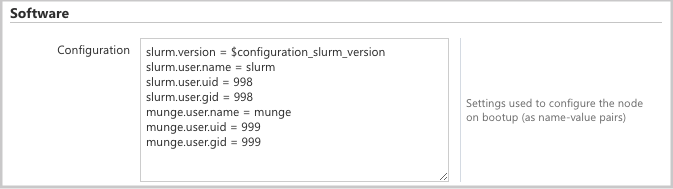
slurm.user.name = slurm
slurm.user.uid = 11100
slurm.user.gid = 11100
munge.user.name = munge
munge.user.uid = 11101
munge.user.gid = 11101
Autoscale
CycleCloud usa la funzionalità elastic computing di Slurm. Per eseguire il debug dei problemi di scalabilità automatica, è possibile controllare alcuni log nel nodo dell'utilità di pianificazione. Il primo consiste nel verificare che le chiamate di ripresa risparmio energia vengano effettuate controllando /var/log/slurmctld/slurmctld.log. Verranno visualizzate righe simili alle seguenti:
[2019-12-09T21:19:03.400] power_save: pid 8629 waking nodes htc-1
L'altro log da controllare è /var/log/slurmctld/resume.log. Se il passaggio di ripresa ha esito negativo, sarà presente anche un oggetto /var/log/slurmctld/resume_fail.log. Se sono presenti messaggi relativi a nomi di nodi sconosciuti o non validi, assicurarsi di non aver aggiunto nodi al cluster senza seguire la procedura descritta nella sezione "Apportare modifiche al cluster" precedente.
Informazioni di riferimento sulla configurazione di Slurm
Di seguito sono riportate le opzioni di configurazione specifiche di Slurm che è possibile attivare o disattivare per personalizzare le funzionalità:
| Opzioni di configurazione specifiche di Slurm | Descrizione |
|---|---|
| slurm.version | Impostazione predefinita: '18.08.7-1'. Questa è la versione Slurm da installare ed eseguire. Questa è attualmente l'opzione predefinita e solo . In futuro potrebbero essere supportate altre versioni del software Slurm. |
| slurm.autoscale | Impostazione predefinita: 'false'. Si tratta di un'impostazione per nodearray che controlla se Slurm deve arrestare e avviare automaticamente i nodi in questo nodearray. |
| slurm.hpc | Impostazione predefinita: 'true'. Si tratta di un'impostazione per nodearray che controlla se i nodi nell'oggetto nodearray verranno posizionati nello stesso gruppo di posizionamento. Usato principalmente per nodearray che usano famiglie di macchine virtuali con InfiniBand. Si applica solo quando slurm.autoscale è impostato su "true". |
| slurm.default_partition | Impostazione predefinita: 'false'. Si tratta di un'impostazione per nodearray che controlla se nodearray deve essere la partizione predefinita per i processi che non richiedono una partizione in modo esplicito. |
| slurm.dampen_memory | Impostazione predefinita: '5'. Percentuale di memoria da conservare per il sovraccarico del sistema operativo/macchina virtuale. |
| slurm.suspend_timeout | Impostazione predefinita: '600'. Intervallo di tempo , espresso in secondi, tra una chiamata di sospensione e il momento in cui tale nodo può essere usato di nuovo. |
| slurm.resume_timeout | Impostazione predefinita: '1800'. Quantità di tempo (in secondi) per attendere l'avvio di un nodo. |
| slurm.install | Impostazione predefinita: 'true'. Determina se Slurm è installato all'avvio del nodo ('true'). Se Slurm è installato in un'immagine personalizzata, questa opzione deve essere impostata su 'false'. (proj versione 2.5.0+) |
| slurm.use_pcpu | Impostazione predefinita: 'true'. Si tratta di un'impostazione per nodearray per controllare la pianificazione con vcpu iperthreaded. Impostare su 'false' per impostare CPU=vcpus in cyclecloud.conf. |
| slurm.user.name | Impostazione predefinita: 'slurm'. Si tratta del nome utente per il servizio Slurm da usare. |
| slurm.user.uid | Impostazione predefinita: '11100'. ID utente da usare per l'utente Slurm. |
| slurm.user.gid | Impostazione predefinita: '11100'. ID gruppo da usare per l'utente Slurm. |
| munge.user.name | Impostazione predefinita: 'munge'. Si tratta del nome utente per il servizio di autenticazione MUNGE da usare. |
| munge.user.uid | Impostazione predefinita: '11101'. ID utente da usare per l'utente MUNGE. |
| munge.user.gid | Impostazione predefinita: '11101'. ID gruppo da usare per l'utente MUNGE. |
CycleCloud supporta un set standard di attributi autostop tra gli utilità di pianificazione:
| Attributo | Descrizione |
|---|---|
| cyclecloud.cluster.autoscale.stop_enabled | Il supporto automatico è abilitato in questo nodo? [true/false] |
| cyclecloud.cluster.autoscale.idle_time_after_jobs | Quantità di tempo (in secondi) per un nodo inattivo dopo il completamento dei processi prima che venga ridimensionato. |
| cyclecloud.cluster.autoscale.idle_time_before_jobs | Quantità di tempo (in secondi) per un nodo inattivo prima di completare i processi prima che venga ridimensionato. |