Esercitazione: progettare un dashboard di analisi in tempo reale usando Azure Cosmos DB for PostgreSQL
SI APPLICA A: ![]() Azure Cosmos DB for PostgreSQL (con tecnologia basata su estensione di database Citus per PostgreSQL)
Azure Cosmos DB for PostgreSQL (con tecnologia basata su estensione di database Citus per PostgreSQL)
In questa esercitazione si usa Azure Cosmos DB for PostgreSQL per imparare a:
- Creare un cluster
- Usare l'utilità psql per creare uno schema
- Ripartire le tabelle tra i nodi
- Generare dati di esempio
- Eseguire i rollup
- Eseguire query sui dati non elaborati e aggregati
- Impostare la scadenza dei dati
Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Creare un cluster
Per creare un cluster di Azure Cosmos DB for PostgreSQL accedere al portale di Azure e seguire questa procedura:
Passare a Creare un cluster di Azure Cosmos DB for PostgreSQL nel portale di Azure.
Nel modulo Creare un cluster Azure Cosmos DB for PostgreSQL:
Immettere le informazioni richieste nella scheda Nozioni di base.
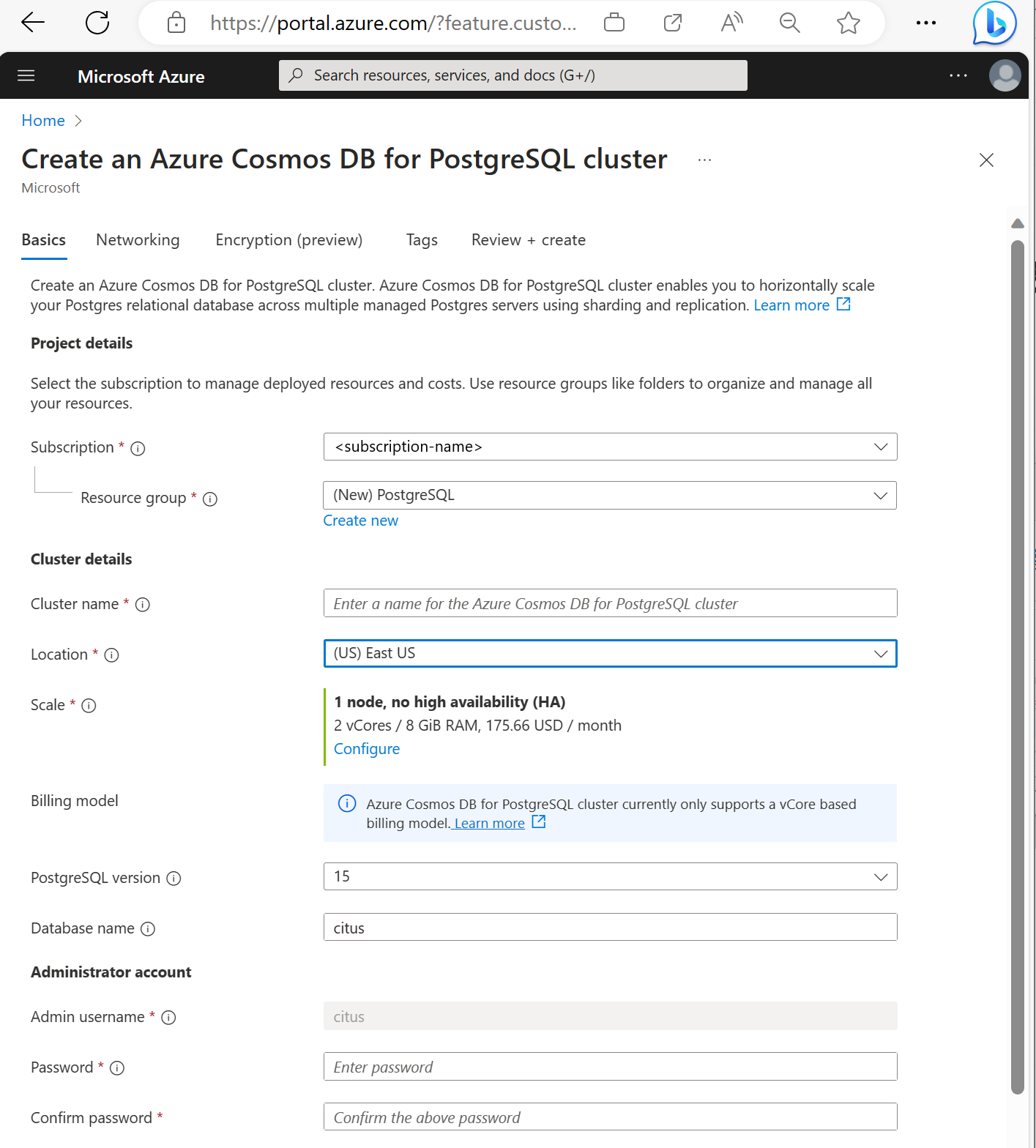
Anche se la maggior parte delle opzioni è autoesplicativa, tenere presente quanto segue:
- Il nome del cluster determina il nome DNS usato dalle applicazioni per la connessione, nel formato
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - È possibile scegliere una versione principale di PostgreSQL, ad esempio 15. Azure Cosmos DB for PostgreSQL supporta sempre la versione Citus più recente per la versione principale selezionata di Postgres.
- Il nome utente amministratore deve essere il valore
citus. - È possibile lasciare il nome del database al valore predefinito 'citus' o definire un proprio nome. Non è possibile rinominare il database dopo il provisioning del cluster.
- Il nome del cluster determina il nome DNS usato dalle applicazioni per la connessione, nel formato
Selezionare Avanti: Rete nella parte inferiore della schermata.
Nella schermata Rete selezionare Consentire l'accesso pubblico dai servizi e dalle risorse di Azure all'interno di Azure a questo cluster.
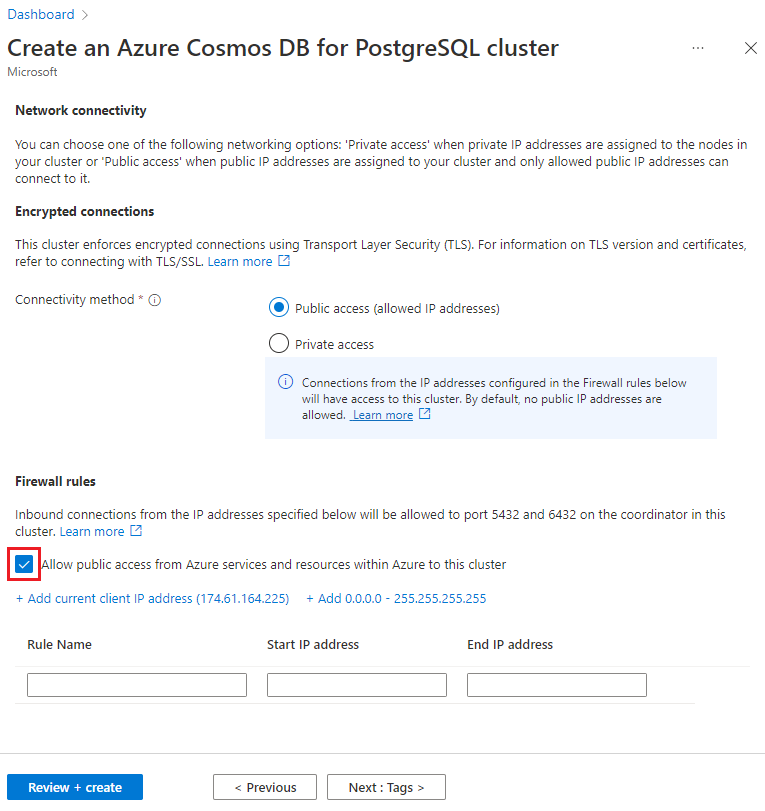
Selezionare Rivedi e crea e, al termine della convalida, selezionare Crea per creare il cluster.
Il provisioning richiede alcuni minuti. La pagina viene reindirizzata per monitorare la distribuzione. Quando lo stato cambia da Distribuzione in corso a Distribuzione completata, selezionare Vai alla risorsa.
Usare l'utilità psql per creare uno schema
Dopo la connessione ad Azure Cosmos DB for PostgreSQL tramite psql, è possibile completare alcune attività di base. Questa esercitazione illustra come inserire dati sul traffico dall'analisi Web e come eseguire il rollup dei dati per fornire dashboard in tempo reale basati su tali dati.
Verrà ora creata una tabella che utilizzerà tutti i dati sul traffico Web non elaborati. Eseguire i comandi seguenti nel terminale psql:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
Verrà anche creata una tabella che conterrà le aggregazioni al minuto e una tabella che gestisce la posizione dell'ultimo rollup. Eseguire i comandi seguenti anche in psql:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
È ora possibile visualizzare le tabelle appena create nell'elenco delle tabelle con questo comando psql:
\dt
Ripartire le tabelle tra i nodi
Una distribuzione Azure Cosmos DB for PostgreSQL archivia le righe di tabella in nodi diversi in base al valore di una colonna designata dall'utente. Questa "colonna di distribuzione" determina come i dati vengono condivisi tra i nodi.
La colonna di distribuzione verrà impostata come site_id, ovvero la chiave di partizione. In psql eseguire queste funzioni:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
Importante
La distribuzione delle tabelle o l'uso del partizionamento orizzontale basato su schema sono necessari per sfruttare le funzionalità delle prestazioni di Azure Cosmos DB for PostgreSQL. Se non si distribuiscono le tabelle o gli schemi, i nodi di lavoro non possono eseguire query che coinvolgono i rispettivi dati.
Generare dati di esempio
A questo punto il cluster sarà pronto per l'inserimento di alcuni dati. È possibile eseguire il codice seguente in locale dalla connessione psql per inserire in modo continuativo i dati.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
La query inserisce circa otto righe al secondo. Le righe vengono archiviate in nodi di lavoro diversi determinati dalla colonna di distribuzione site_id.
Nota
Lasciare la query di generazione dei dati in esecuzione e aprire una seconda connessione psql per i comandi rimanenti in questa esercitazione.
Query
Azure Cosmos DB for PostgreSQL consente a più nodi di elaborare le query in parallelo per aumentare la velocità. Il database consente, ad esempio, di calcolare aggregazioni come SUM e COUNT nei nodi di lavoro e combina i risultati in una risposta finale.
Ecco una query per il conteggio delle richieste Web al minuto insieme ad alcune statistiche. Provare a eseguirla in psql e osservare i risultati.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
Rollup dei dati
La query precedente funziona bene nelle fasi iniziali, ma le prestazioni diminuiranno con l'aumentare dei dati. Anche con l'elaborazione distribuita, è più veloce precalcolare i dati che ricalcolarli ripetutamente.
Per fare in modo che il dashboard non subisca rallentamenti, eseguire regolarmente il rollup dei dati non elaborati in una tabella aggregata. È possibile effettuare esperimenti con la durata dell'aggregazione. È stata usata una tabella di aggregazione al minuto, ma è possibile dividere i dati in 5, 15 e 60 minuti.
Per eseguire più facilmente questo rollup, sarà necessario inserirlo in una funzione plpgsql. Eseguire questi comandi in psql per creare la funzione rollup_http_request.
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
Dopo aver creato la funzione, usarla per eseguire il rollup dei dati:
SELECT rollup_http_request();
Con i dati in formato preaggregato è possibile eseguire una query sulla tabella di rollup per ottenere lo stesso report di prima. Eseguire la query riportata di seguito:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
Impostare come scaduti i dati meno recenti
I rollup velocizzano le query, ma è comunque necessario impostare come scaduti i dati meno recenti per evitare costi di archiviazione eccessivi. È sufficiente decidere per quanto tempo conservare i dati per ogni granularità e usare le query standard per eliminare i dati scaduti. Nell'esempio seguente è stato deciso di conservare i dati non elaborati per un giorno e le aggregazioni al minuto per un mese:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
In fase di produzione, è possibile eseguire il wrapping di queste query in una funzione e chiamarla ogni minuto in un processo cron.
Pulire le risorse
Nei passaggi precedenti sono state create risorse di Azure in un cluster. Se non si prevede di avere bisogno di queste risorse in futuro, eliminare il cluster. Fare clic sul pulsante Elimina nella pagina Panoramica per il cluster. Quando viene visualizzata la richiesta in una pagina popup, verificare il nome del cluster e fare clic sul pulsante Elimina in basso.
Passaggi successivi
In questa esercitazione si è appreso come effettuare il provisioning di un cluster. È stata stabilita la connessione al gruppo con psql, è stato creato uno schema e sono stati distribuiti i dati. È stato illustrato come eseguire query sui dati in formato non elaborato, aggregare regolarmente i dati, eseguire query sulle tabelle aggregate e impostare come scaduti i dati meno recenti.
- Informazioni sui tipi di nodi dei cluster
- Determinare le dimensioni iniziali ottimali per il cluster