Modellare app di analisi in tempo reale in Azure Cosmos DB for PostgreSQL
SI APPLICA A: ![]() Azure Cosmos DB for PostgreSQL (con tecnologia basata su estensione di database Citus per PostgreSQL)
Azure Cosmos DB for PostgreSQL (con tecnologia basata su estensione di database Citus per PostgreSQL)
Condividere tabelle di grandi dimensioni con chiave di partizione
Per selezionare la chiave di partizione per un'applicazione di analisi operativa in tempo reale, seguire queste linee guida:
- Scegliere una colonna comune nelle tabelle di grandi dimensioni
- Scegliere una colonna che rappresenta una dimensione naturale nei dati o una parte centrale dell'applicazione. Di seguito alcuni esempi:
- Nel mondo finanziario, un'applicazione che analizza le tendenze di sicurezza probabilmente userà
security_id. - In un carico di lavoro di analisi degli utenti in cui si vogliono analizzare le metriche di utilizzo del sito Web,
user_idsarebbe una colonna di distribuzione valida
- Nel mondo finanziario, un'applicazione che analizza le tendenze di sicurezza probabilmente userà
La condivisione di tabelle di grandi dimensioni consente di eseguire il push di query SQL nei nodi di lavoro in parallelo. Il push delle query evita la spostamento casuale dei dati tra i nodi nella rete. Le operazioni come JOIN, aggregazioni, rollup, filtri, LIMIT possono essere eseguite in modo efficiente.
Per visualizzare query distribuite parallele in tabelle con percorso condiviso, considerare questo diagramma:
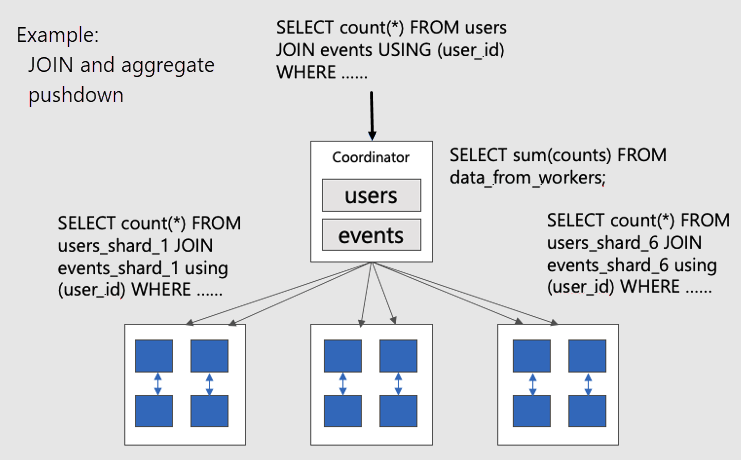
Le tabelle users e events sono entrambe partizionate da user_id, quindi le righe correlate per lo stesso ID utente vengono inserite nello stesso nodo di lavoro. I JOIN SQL possono verificarsi senza eseguire il pull delle informazioni tra i ruoli di lavoro.
Modello di dati ottimale per le app in tempo reale
Continuare con l'esempio di un'applicazione che analizza le visite e le metriche dei siti Web degli utenti. Esistono due tabelle "fatti", ovvero utenti ed eventi, e altre tabelle "dimensioni" più piccole.
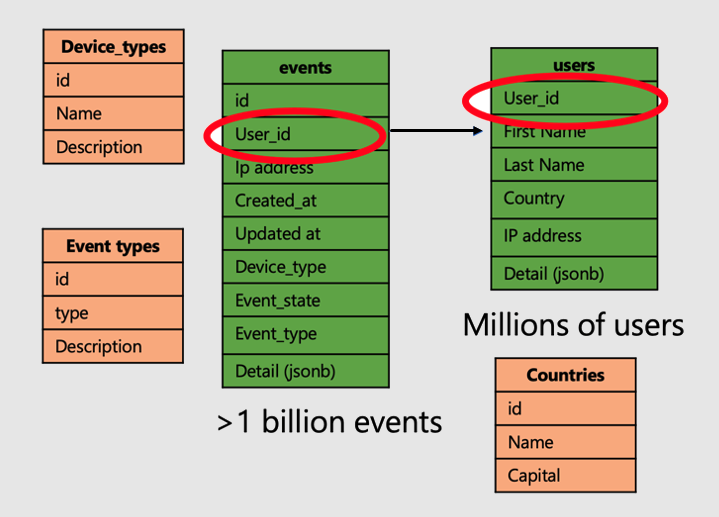
Per applicare la super potenza delle tabelle distribuite in Azure Cosmos DB for PostgreSQL, seguire questa procedura:
- Distribuire tabelle dei fatti di grandi dimensioni in una colonna comune. In questo caso, gli utenti e gli eventi vengono distribuiti su
user_id. - Contrassegnare le tabelle piccole/delle dimensioni (
device_types,countriese 'event_types) come tabelle di riferimento. - Assicurarsi di includere la colonna di distribuzione nei vincoli di chiave primaria, univoca ed esterna nelle tabelle distribuite. L'inclusione della colonna può richiedere la composizione delle chiavi. È necessario aggiornare le chiavi per le tabelle di riferimento.
- Quando si uniscono tabelle distribuite di grandi dimensioni, assicurarsi di eseguire il join usando la chiave di partizione.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Passaggi successivi
È stata completata l'esplorazione della modellazione dei dati per le app scalabili. Il passaggio successivo consiste nel connettere ed eseguire query sul database con il linguaggio di programmazione preferito.