Generazione aumentata di recupero (RAG) con Azure Cosmos DB basato su vCore per MongoDB
Nel regno dell’IA generativa in rapida evoluzione i modelli linguistici di grandi dimensioni (LLM) come GPT-3.5 hanno trasformato l'elaborazione del linguaggio naturale. Tuttavia, una tendenza emergente nell’intelligenza artificiale è l'uso di archivi vettoriali, che svolgono un ruolo fondamentale nel miglioramento delle applicazioni di intelligenza artificiale.
Questa esercitazione mostra come usare Azure Cosmos DB for MongoDB (vCore), LangChain e OpenAI per implementare la generazione aumentata del recupero (RAG) per migliorare le prestazioni dell'intelligenza artificiale, e illustra modelli linguistici di grandi dimensioni (LLM) e le relative limitazioni. Viene esplorato il paradigma della "generazione aumentata del recupero" (RAG) adottato rapidamente e si illustrano brevemente il framework LangChain e i modelli di Azure OpenAI. Infine, questi concetti vengono integrati in un'applicazione reale. Alla fine, i lettori avranno una solida comprensione di questi concetti.
Informazioni sui modelli linguistici di grandi dimensioni (LLM) e sulle relative limitazioni
I modelli linguistici di grandi dimensioni (LLM) sono modelli avanzati di rete neurale profonda sottoposti a training su set di dati di testo estesi, che consentono loro di comprendere e generare testo simile a quello umano. Anche se i modelli linguistici di grandi dimensioni (LLM) sono rivoluzionari nell'elaborazione del linguaggio naturale, hanno limitazioni intrinseche:
- Allucinazioni: a volte i modelli linguistici di grandi dimensioni generano informazioni realmente errate o infondate, dette "allucinazioni".
- Dati non aggiornati: i modelli linguistici di grandi dimensioni (LLM) vengono sottoposti a training su set di dati statici che potrebbero non includere le informazioni più recenti, limitando la loro pertinenza corrente.
- Nessun accesso ai dati locali dell'utente: i modelli linguistici di grandi dimensioni (LLM) non hanno accesso diretto a dati personali o localizzati e ciò limita la loro capacità di fornire risposte personalizzate.
- Limiti dei token: i modelli linguistici di grandi dimensioni (LLM) hanno un limite massimo di token per interazione, che vincola la quantità di testo che possono elaborare contemporaneamente. Ad esempio, gpt-3.5-turbo di OpenAI ha un limite di 4096 token.
Sfruttare la generazione aumentata del recupero (RAG)
La generazione aumentata del recupero (RAG) è un'architettura progettata per superare le limitazioni dei modelli linguistici di grandi dimensioni (LLM). La generazione aumentata del recupero (RAG) usa la ricerca vettoriale per recuperare i documenti pertinenti in base a una query di input e fornisce questi documenti come contesto ai modelli linguistici di grandi dimensioni (LLM) per generare risposte più accurate. Invece di basarsi esclusivamente su modelli con training preliminare, la generazione aumentata del recupero (RAG) migliora le risposte incorporando informazioni aggiornate e pertinenti. Questo approccio consente di:
- Ridurre al minimo le allucinazioni: basando le risposte su informazioni reali.
- Accertarsi che le informazioni siano aggiornate: recuperando i dati più recenti per garantire risposte aggiornate.
- Utilizzare database esterni: anche se non viene concesso l'accesso diretto ai dati personali, la generazione aumentata del recupero (RAG) consente l'integrazione con knowledge base esterne specifiche dell'utente.
- Ottimizzare l'utilizzo dei token: concentrandosi sui documenti più pertinenti, la generazione aumentata del recupero (RAG) rende più efficiente l'utilizzo dei token.
Questa esercitazione mostra come implementare la generazione aumentata del recupero (RAG) usando Azure Cosmos DB for MongoDB (vCore) per creare un'applicazione di risposta alle domande ottimizzata per i dati.
Panoramica dell'architettura dell'applicazione
Il diagramma dell'architettura seguente mostra i componenti chiave dell'implementazione della generazione aumentata del recupero (RAG):
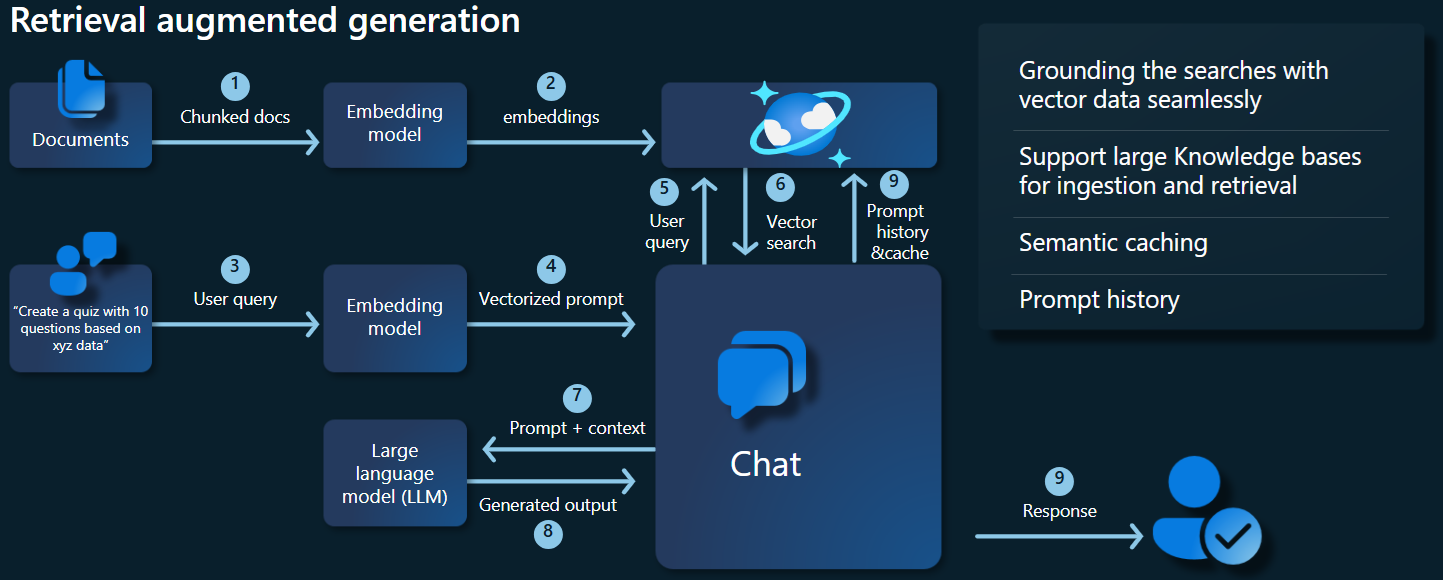
Componenti e framework principali
Ora verranno illustrati i vari framework, modelli e componenti usati in questa esercitazione, evidenziandone i ruoli e le sfumature.
Azure Cosmos DB for MongoDB (vCore)
Azure Cosmos DB for MongoDB (vCore) supporta ricerche di similarità semantica, essenziali per le applicazioni basate sull'intelligenza artificiale. Consente la rappresentazione dei dati in vari formati come incorporamenti vettoriali, che possono essere archiviati insieme a dati e metadati di origine. Usando un algoritmo approssimativo del vicino più prossimo, ad esempio HNSW (Hierarchical Navigable Small World), è possibile eseguire query su tali incorporamenti per ricerche rapide di similarità semantica.
Framework LangChain
LangChain semplifica la creazione di applicazioni LLM fornendo un'interfaccia standard per catene, più integrazioni di strumenti e catene end-to-end per attività comuni. Consente agli sviluppatori IA di generare applicazioni LLM che sfruttano origini dati esterne.
Aspetti principali di LangChain:
- Catene: sequenze di componenti che risolvono attività specifiche.
- Componenti: moduli come wrapper LLM, wrapper dell'archivio vettoriale, modelli di prompt, caricatori di dati, separatori di testo e funzioni di recupero.
- Modularità: semplifica lo sviluppo, il debug e la manutenzione.
- Popolarità: un progetto open source rapidamente adottato che si evolve per soddisfare le esigenze degli utenti.
Interfaccia dei servizi app di Azure
I servizi app offrono una solida piattaforma per la creazione di interfacce Web semplici da usare per applicazioni di IA generativa. Questa esercitazione usa i servizi app di Azure per creare un'interfaccia Web interattiva per l'applicazione.
Modelli OpenAI
OpenAI è leader nella ricerca sull’intelligenza artificiale e fornisce vari modelli per la generazione di linguaggio, la vettorizzazione di testo, la creazione di immagini e la conversione da audio a testo. In questa esercitazione vengono usati modelli di incorporamento e linguaggi di OpenAI, fondamentali per comprendere e generare applicazioni basate sul linguaggio.
Modelli di incorporamento e modelli di generazione di linguaggio
| Categoria | Modello di incorporamento di testo | Modello linguistico |
|---|---|---|
| Scopo | Conversione del testo in incorporamenti vettoriali. | Comprensione e generazione del linguaggio naturale. |
| Funzione | Trasforma i dati testuali in matrici altamente dimensionali di numeri, acquisendo il significato semantico del testo. | Comprende e produce testo simile a quello umano in base all'input specificato. |
| Output | Matrice di numeri (incorporamenti vettoriali). | Testo, risposte, traduzioni, codice e così via. |
| Output esempio | Ogni incorporamento rappresenta il significato semantico del testo in forma numerica, con una dimensionalità determinata dal modello. Ad esempio text-embedding-ada-002 genera vettori con 1536 dimensioni. |
Testo contestualmente pertinente e coerente generato in base all'input fornito. Ad esempio, gpt-3.5-turbo può generare risposte a domande, tradurre testo, scrivere codice e altro. |
| Casi d'uso tipici | - Ricerca semantica | - Chatbot |
| - Sistemi di consigli | - Creazione automatica del contenuto | |
| - Clustering e classificazione di dati di testo | - Traduzione linguistica | |
| - Recupero di informazioni | - Riepilogo | |
| Rappresentazione dei dati | Rappresentazione numerica (incorporamenti) | Testo del linguaggio naturale |
| Dimensionalità | La lunghezza della matrice corrisponde al numero di dimensioni nello spazio di incorporamento, ad esempio 1536 dimensioni. | Generalmente viene rappresentata come sequenza di token, con il contesto che determina la lunghezza. |
Componenti principali dell'applicazione
- Azure Cosmos DB for MongoDB vCore: archiviazione ed esecuzione di query su incorporamenti vettoriali.
- LangChain: creazione del flusso di lavoro LLM dell'applicazione. Usa strumenti come:
- Caricatore documenti: per il caricamento e l'elaborazione di documenti da una directory.
- Integrazione dell'archivio vettoriale: per l'archiviazione e l'esecuzione di query su incorporamenti vettoriali in Azure Cosmos DB.
- AzureCosmosDBVectorSearch: wrapper per la ricerca vettoriale di Cosmos DB
- Servizi app di Azure: creazione dell'interfaccia utente per l'app Cosmic Food.
- Azure OpenAI: per fornire modelli LLM e di incorporamento, tra cui:
- text-embedding-ada-002: modello di incorporamento di testo che converte il testo in incorporamenti vettoriali con 1536 dimensioni.
- gpt-3.5-turbo: modello linguistico per la comprensione e la generazione di linguaggio naturale.
Configurare l'ambiente
Per iniziare a ottimizzare la generazione aumentata del recupero (RAG) con Azure Cosmos DB for MongoDB (vCore), seguire questi passaggi:
- Creare le risorse seguenti in Microsoft Azure:
- Cluster di Azure Cosmos DB for MongoDB vCore: vedere la Guida introduttiva qui.
- Risorsa di Azure OpenAI con:
- Distribuzione del modello di incorporamento (ad esempio
text-embedding-ada-002). - Distribuzione del modello di chat (ad esempio
gpt-35-turbo).
- Distribuzione del modello di incorporamento (ad esempio
Documenti di esempio
In questa esercitazione viene caricato un singolo file di testo usando Documento. Questi file devono essere salvati in una directory denominata dati nella cartella src. Il contenuto è il seguente:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Caricare i documenti
Impostare la stringa di connessione di Cosmos DB for MongoDB (vCore), il nome del database, il nome della raccolta e l'indice:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Inizializzare il client di incorporamento.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Creare incorporamenti dai dati, salvarli nel database e restituire una connessione all'archivio vettoriale Cosmos DB for MongoDB (vCore).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Creare il seguente indice vettoriale HNSW nella raccolta (si noti che il nome dell'indice è uguale a quello precedente).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Eseguire la ricerca vettoriale con Cosmos DB for MongoDB (vCore)
Connettersi all'archivio vettoriale.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Definire una funzione che esegue una ricerca di similarità semantica usando la ricerca vettoriale di Cosmos DB su una query (si noti che questo frammento di codice è solo una funzione di test).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Inizializzare il client chat per implementare una funzione RAG.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Creare una funzione RAG.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Converte l'archivio vettoriale in una funzione di recupero, che può cercare documenti pertinenti in base ai parametri specificati.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Creare una catena di recupero in grado di riconoscere la cronologia delle conversazioni, che garantisce il recupero di documenti contestualmente pertinenti usando il modello azure_openai_chat e vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Creare una catena che combina i documenti recuperati in una risposta coerente usando il modello linguistico (azure_openai_chat) e un prompt specificato (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Creare una catena che gestisce l'intero processo di recupero, integrando la catena di recupero con riconoscimento della cronologia e la catena di combinazioni di documenti. Questa catena RAG può essere eseguita per recuperare e generare risposte contestualmente accurate.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
Output di esempio
Lo screenshot seguente mostra gli output per varie domande. Una ricerca di similarità puramente semantica restituisce il testo non elaborato dai documenti di origine, mentre l'app di risposta alle domande che usa l'architettura RAG genera risposte precise e personalizzate combinando il contenuto del documento recuperato con il modello linguistico.
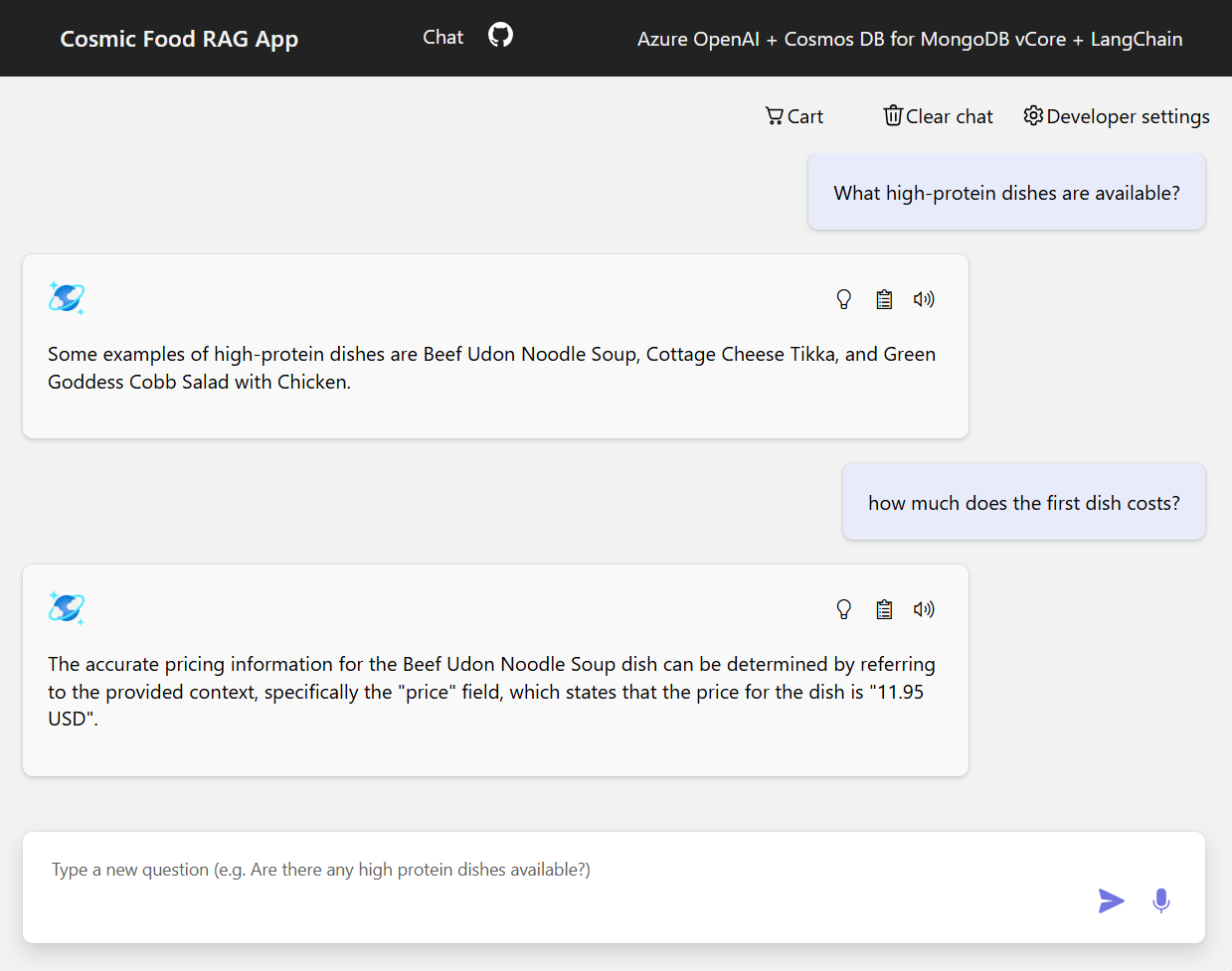
Conclusione
In questa esercitazione è stato descritto come creare un'app di risposta alle domande che interagisce con i dati privati usando Cosmos DB come archivio vettoriale. Sfruttando l'architettura della generazione aumentata del recupero (RAG) con LangChain e Azure OpenAI, è stato dimostrato come gli archivi vettoriali siano essenziali per le applicazioni LLM.
RAG rappresenta un progresso significativo nell'IA, in particolare nell'elaborazione del linguaggio naturale, e la combinazione di queste tecnologie consente la creazione di potenti applicazioni basate sull'intelligenza artificiale per diversi casi d'uso.