Disponibilità (affidabilità) e ripristino di emergenza in Azure Cosmos DB per MongoDB vCore: dietro le quinte
SI APPLICA A: ![]() MongoDB vCore
MongoDB vCore
Questo articolo illustra gli elementi interni di disponibilità elevata e ripristino di emergenza tra aree per Azure Cosmos DB per MongoDB vCore, delineando la progettazione e le funzionalità di queste funzionalità. Fornisce informazioni dettagliate per una pianificazione efficace della strategia in area geografica e tra aree per garantire affidabilità e continuità aziendale.
Anatomia del cluster vCore di Azure Cosmos DB per MongoDB
Un cluster vCore di Azure Cosmos DB per MongoDB è costituito da una o più partizioni fisiche (nodi). Ogni partizione fisica include un nodo di calcolo dedicato e un'archiviazione SSD Premium remota. Le risorse di calcolo e archiviazione di una partizione fisica sono esclusive di un singolo database e non condivise tra cluster o database.
Nei cluster con più partizioni, ogni partizione ha una configurazione di calcolo e archiviazione identica. Indipendentemente dal numero di partizioni, tutte le risorse del cluster sono ospitate nella stessa area di Azure.
Azure Cosmos DB per MongoDB vCore usa l'archiviazione con ridondanza locale, assicurando che tutti i dati vengano replicati in modo sincrono tre volte all'interno della posizione fisica del cluster. Archiviazione di Azure gestisce in modo trasparente queste repliche, verifica l'integrità dei dati usando controlli di ridondanza ciclici e ripristina eventuali danneggiamenti rilevati usando dati ridondanti. Inoltre, i checksum vengono applicati al traffico di rete per evitare il danneggiamento dei dati durante l'archiviazione e il recupero.
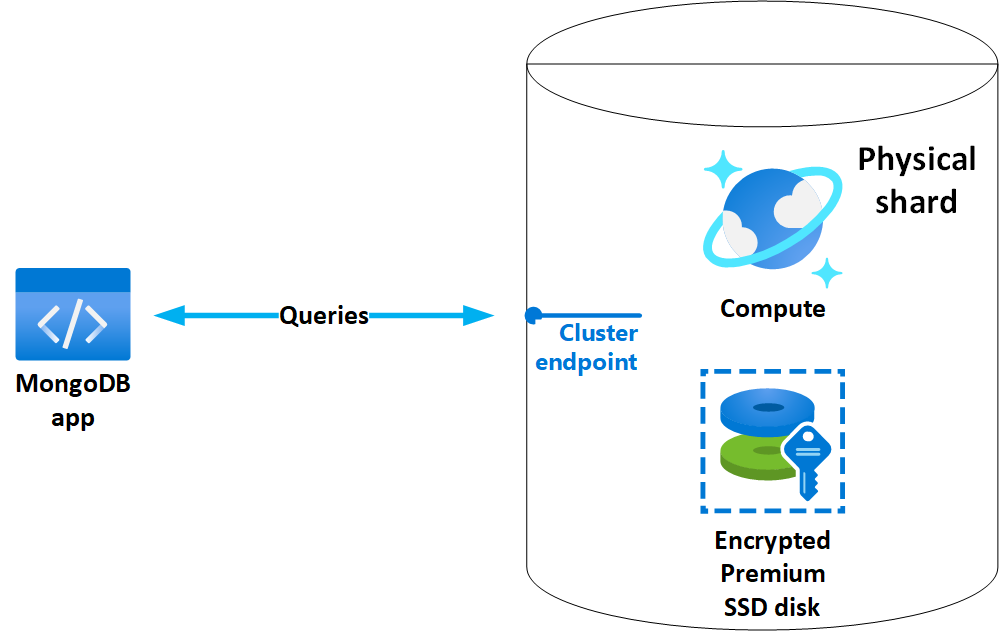 Figura 1. Componenti del cluster vCore di Azure Cosmos DB per MongoDB.
Figura 1. Componenti del cluster vCore di Azure Cosmos DB per MongoDB.
Indipendentemente dal fatto che l'applicazione si connetta a una singola partizione o a un cluster con più partizioni, usa un singolo stringa di connessione ed endpoint. Questa astrazione semplifica le operazioni di database distribuite, semplificando la connessione a un'installazione su più partizioni come a un database MongoDB autonomo.
Disponibilità elevata nell'area
Per i carichi di lavoro di produzione, è consigliabile abilitare la disponibilità elevata in un'area per soddisfare gli standard di affidabilità moderni. Anche se la disponibilità elevata può essere disabilitata per lo sviluppo o i cluster sperimentali per ridurre i costi, è fondamentale per mantenere la disponibilità del database nell'ambiente di produzione.
La disponibilità elevata può essere attivata/disattivata durante il provisioning del cluster o in qualsiasi momento dopo la creazione del cluster. È disponibile in tutte le aree di Azure che supportano Azure Cosmos DB per mongoDB vCore, indipendentemente dalle funzionalità specifiche a livello di area.
Quando la disponibilità elevata è abilitata, ogni partizione fisica primaria nel cluster viene associata a una partizione di standby. La partizione di standby esegue il mirroring della configurazione di calcolo e archiviazione della controparte primaria. Ciò comporta sei repliche di dati per partizione, tre nella partizione primaria e tre in standby. Nelle aree con zone di disponibilità (AZs) le partizioni primarie e di standby vengono distribuite in zone separate.
I dati vengono replicati in modo sincrono tra ogni partizione primaria e di standby. Le scritture vengono riconosciute solo dopo il commit corretto in entrambe le partizioni, garantendo una coerenza assoluta all'interno del cluster a disponibilità elevata. In altre parole, una partizione fisica di standby è una replica completa sempre aggiornata della partizione fisica primaria che offre coerenza assoluta all'interno del cluster a disponibilità elevata.
 Figura 2. Cluster vCore di Azure Cosmos DB per MongoDB con e senza disponibilità elevata nell'area abilitata.
Figura 2. Cluster vCore di Azure Cosmos DB per MongoDB con e senza disponibilità elevata nell'area abilitata.
In caso di errore di partizione primaria, il servizio esegue automaticamente un failover nella partizione di standby. Durante il failover, tutte le richieste di lettura e scrittura vengono reindirizzate alla partizione di standby, che diventa la nuova replica primaria. Le operazioni di scrittura in corso durante il failover vengono ritentate all'interno del servizio per garantire la continuità. Viene quindi creata una partizione sostitutiva per ristabilire la replica sincrona, diventando il nuovo standby.
Replica tra aree: ripristino di emergenza a livello di area
Anche se rara, le interruzioni a livello di area possono compromettere l'accesso al database. La replica tra aree offre una strategia di ripristino di emergenza affidabile, garantendo l'accesso ai dati anche durante interruzioni su larga scala.
Con la replica tra aree, è possibile creare un cluster di replica in un'area di Azure diversa. Ogni partizione nel cluster di replica replica replica in modo asincrono i dati dalla controparte nel cluster primario. Questo modello di replica garantisce la coerenza finale riducendo al minimo l'impatto sulle prestazioni nel cluster primario.
La replica asincrona evita che ogni operazione di scrittura venga recapitata immediatamente e confermata dalle repliche prima che all'applicazione venga inviato un riconoscimento "write complete". Ciò significa tuttavia che alcune scritture completate nel cluster primario potrebbero non essere ancora replicate nel cluster di replica, causando un ritardo di replica. L'estensione del ritardo di replica dipende dall'intensità delle operazioni di scrittura nel cluster primario e dal carico complessivo nei cluster di replica e primari.
In questa configurazione:
- Il cluster primario nell'area A gestisce tutte le letture e le scritture.
- Il cluster di replica nell'area B supporta l'accesso in sola lettura, consentendo operazioni di lettura ad alte prestazioni più vicine alle applicazioni o agli utenti di tale area.
Le applicazioni possono eseguire query OLTP nel cluster primario nell'area A e operazioni di lettura intense, ad esempio query OLAP/reporting, possono essere puntate al cluster di replica nell'area B.
Le applicazioni possono usare un stringa di connessione di lettura/scrittura globale dinamico, che punta sempre al cluster aperto per le scritture. Durante un'interruzione a livello di area, il cluster di replica nell'area B può essere alzato di livello per accettare le scritture. Il stringa di connessione globale viene aggiornato automaticamente in modo da puntare al cluster alzato di livello, garantendo operazioni di scrittura ininterrotte.
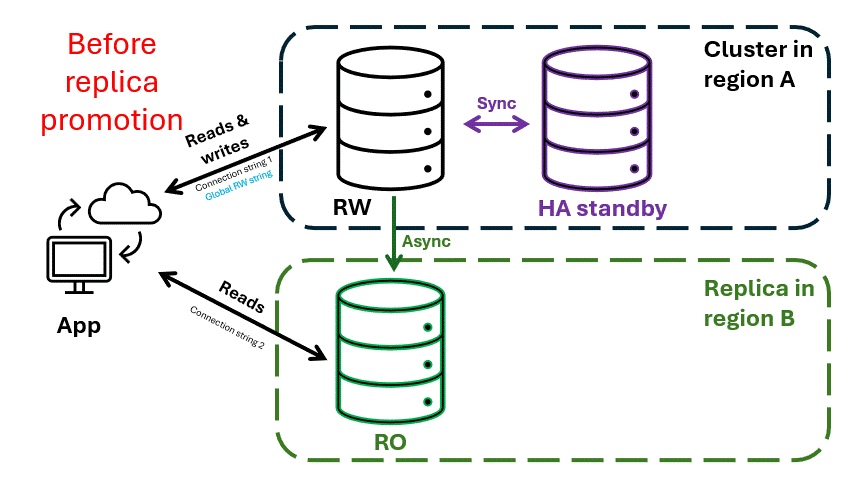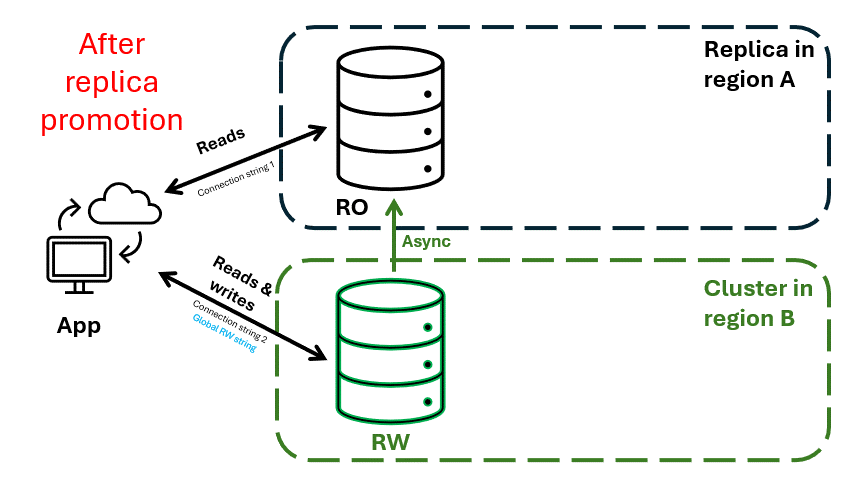 Figura 3. Ripristino di emergenza a livello di area con un cluster vCore di Azure Cosmos DB per MongoDB con la replica tra aree abilitate. Il cluster nell'area B viene alzato di livello per diventare il nuovo cluster di lettura/scrittura. Il cluster nell'area A diventa un cluster di replica.
Figura 3. Ripristino di emergenza a livello di area con un cluster vCore di Azure Cosmos DB per MongoDB con la replica tra aree abilitate. Il cluster nell'area B viene alzato di livello per diventare il nuovo cluster di lettura/scrittura. Il cluster nell'area A diventa un cluster di replica.
Riepilogo delle funzionalità di disponibilità nell'area e ripristino di emergenza tra aree
La tabella seguente riepiloga le considerazioni principali per abilitare e gestire la disponibilità elevata in un'area e una strategia di ripristino di emergenza tra aree.
| Scenario | Funzionalità vCore di Azure Cosmos DB per MongoDB | Senza perdita di dati | Protezione da interruzioni a livello di area | Failover automatico | Nessuna modifica stringa di connessione |
|---|---|---|---|---|---|
| Errore di partizione fisica | Disponibilità elevata nell'area | ✔️ | ❌ | ✔️ | ✔️ |
| Interruzione a livello di area | Cluster di replica tra aree | ❌ | ✔️ | ❌ | ✔️† |
† Quando si usa l'stringa di connessione di lettura/scrittura globale.