Introduzione a Change Data Capture nell'archivio analitico per Azure Cosmos DB
SI APPLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Usare Change Data Capture (CDC) nell'archivio analitico di Azure Cosmos DB come origine per Azure Data Factory o Azure Synapse Analytics per acquisire modifiche specifiche ai dati.
Nota
Si noti che l'interfaccia del servizio collegato per l'API Azure Cosmos DB for MongoDB non è ancora disponibile nel flusso di dati. Tuttavia, è possibile usare l'endpoint documento dell'account con l'interfaccia del servizio collegato "Azure Cosmos DB for NoSQL" come soluzione alternativa fino a quando non sarà supportato il servizio collegato Mongo. In un servizio collegato NoSQL scegliere "Immetti manualmente" per fornire le informazioni sull'account Cosmos DB e usare l'endpoint documento dell'account (ad esempio, https://[your-database-account-uri].documents.azure.com:443/) anziché l'endpoint MongoDB (ad esempio, mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/)
Prerequisiti
- Un account Azure Cosmos DB esistente.
- Se si dispone di una sottoscrizione di Azure, creare un nuovo account.
- Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- In alternativa, è possibile provare azure Cosmos DB gratuitamente prima di eseguire il commit.
Abilitare l'archivio analitico
Prima di tutto, abilitare Collegamento ad Azure Synapse a livello dell'account e quindi abilitare l'archivio analitico per i contenitori appropriato per il carico di lavoro.
Abilitare Collegamento ad Azure Synapse: Abilitare Collegamento ad Azure Synapse per un account Azure Cosmos DB
Abilitare l'archivio analitico per i contenitori:
Opzione Guida Abilitare per un nuovo contenitore specifico Abilitare Collegamento ad Azure Synapse per i nuovi contenitori Abilitare per un contenitore specifico esistente Abilitare Collegamento ad Azure Synapse per i contenitori esistenti
Creare una risorsa di Azure di destinazione usando i flussi di dati
La funzionalità Change Data Capture dell'archivio analitico è disponibile tramite la funzionalità flusso di dati di Azure Data Factory o Azure Synapse Analytics. Per questa guida, usare Azure Data Factory.
Importante
In alternativa, è possibile usare Azure Synapse Analytics. Prima di tutto, creare un'area di lavoro di Azure Synapse, se non ne è già disponibile una. Nell'area di lavoro appena creata selezionare la scheda Sviluppo, quindi Aggiungi nuova risorsa e infine Flusso di dati.
Creare un'istanza di Azure Data Factory, se non ne è già disponibile una.
Suggerimento
Se possibile, creare la data factory nella stessa area in cui risiede l'account Azure Cosmos DB.
Avviare la data factory appena creata.
Nella data factory selezionare la scheda Flussi di dati e quindi selezionare Nuovo flusso di dati.
Assegnare al flusso di dati appena creato un nome univoco. In questo esempio il flusso di dati è denominato
cosmoscdc.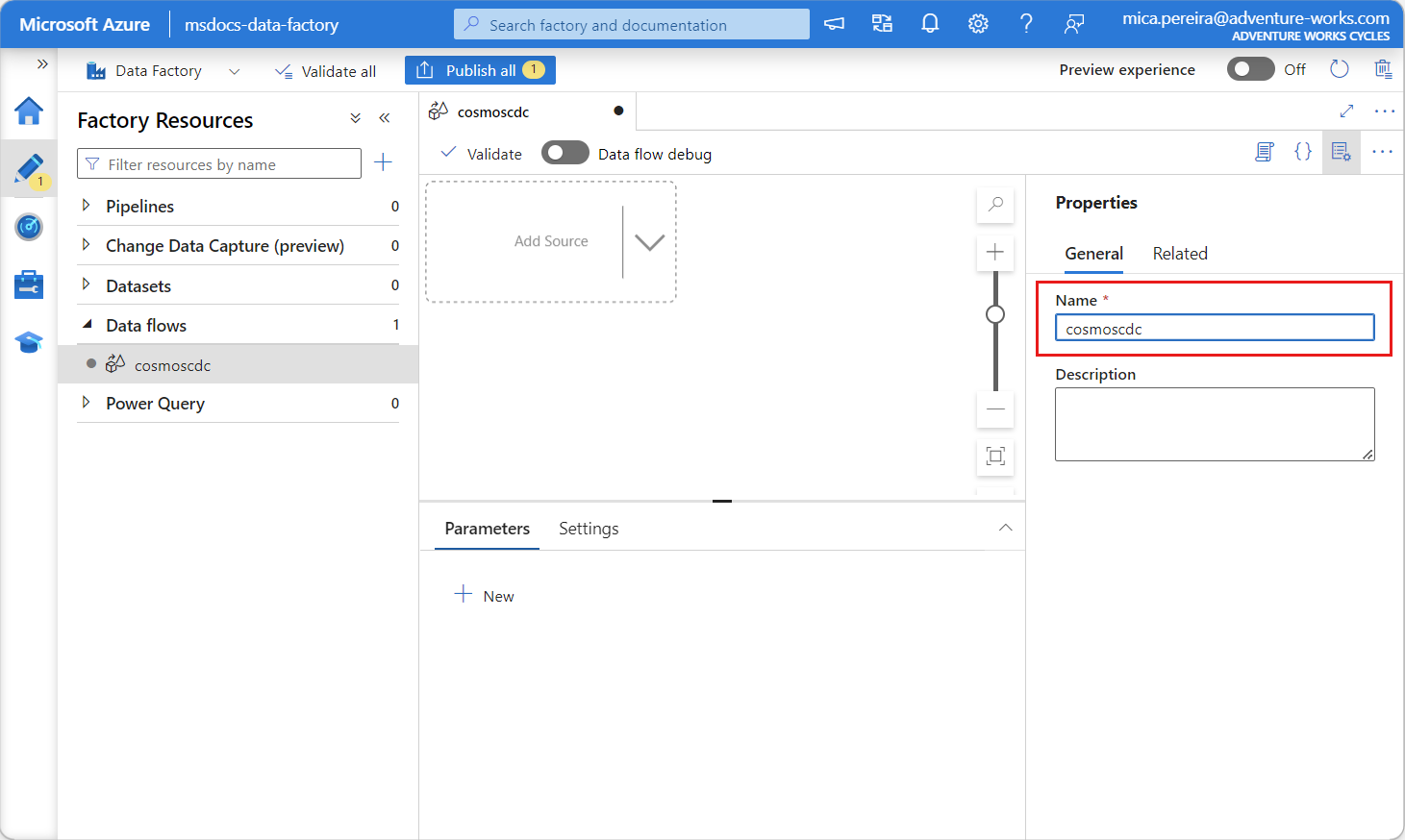

Configurare le impostazioni di origine per il contenitore dell'archivio analitico
Creare e configurare un'origine per il flusso dei dati dall'archivio analitico dell'account Azure Cosmos DB.
Seleziona Aggiungi origine.
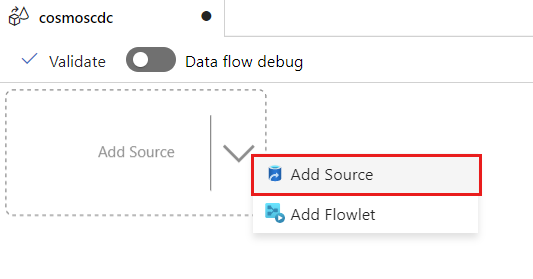
Nel campo Nome flusso di output immettere cosmos.
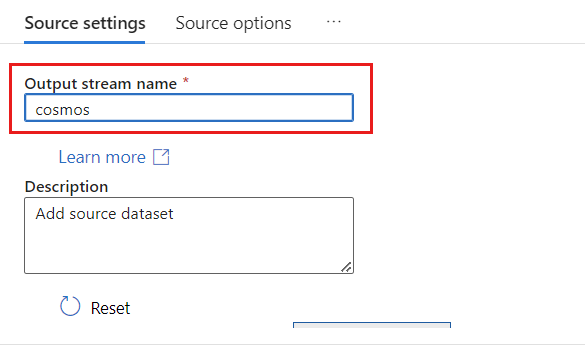
Nella sezione Tipo di origine selezionare Inline.
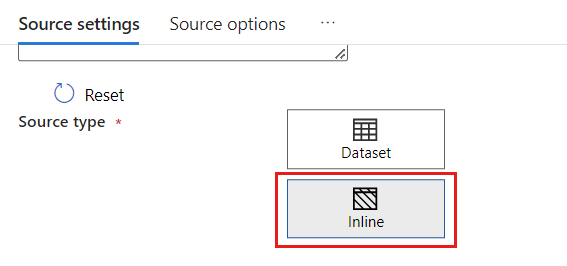
Nel campo Set di dati selezionare Azure - Azure Cosmos DB for NoSQL.
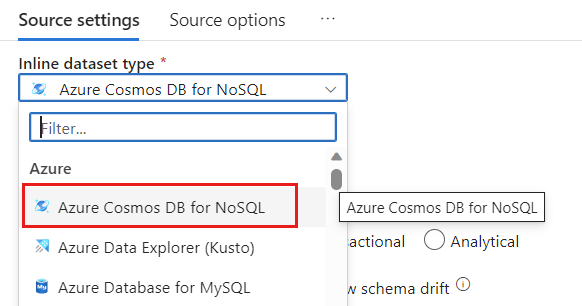
Creare un nuovo servizio collegato per l'account denominato cosmoslinkedservice. Selezionare l'account Azure Cosmos DB for NoSQL esistente nella finestra di dialogo popup Nuovo servizio collegato e quindi scegliere OK. In questo esempio viene selezionato un account Azure Cosmos DB for NoSQL preesistente denominato
msdocs-cosmos-sourcee un database denominatocosmicworks.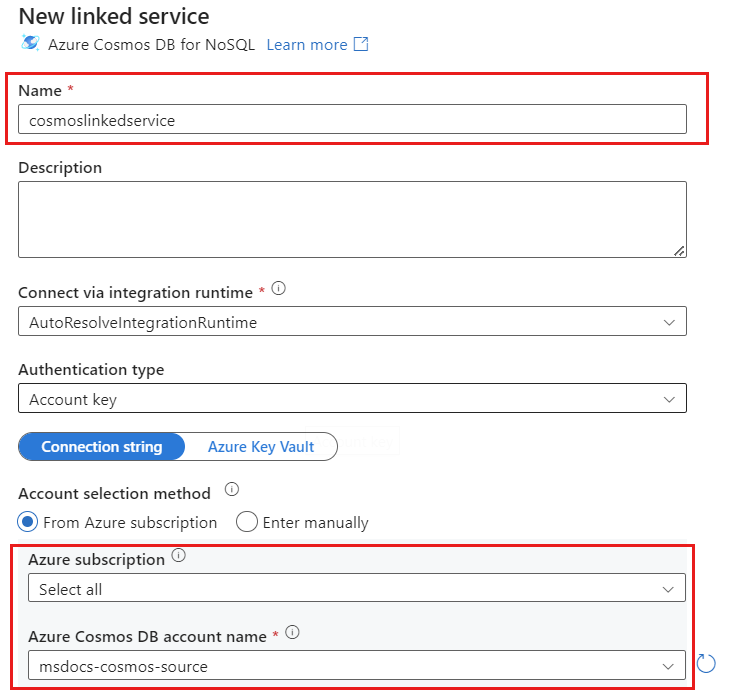
Selezionare Analitico per il tipo di archivio.
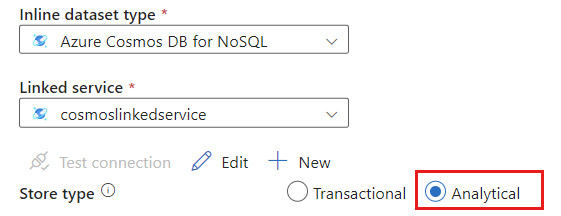
Selezionare la scheda Opzioni origine.
In Opzioni origine selezionare il contenitore di destinazione e abilitare Debug del flusso di dati. In questo esempio il contenitore è denominato
products.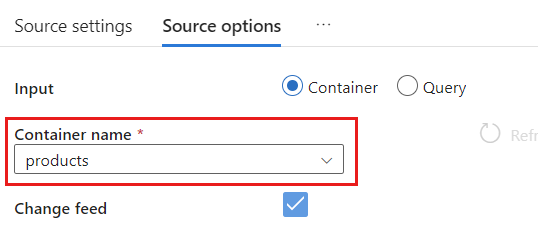
Selezionare Debug flusso di dati. Nella finestra di dialogo popup Attiva il debug del flusso di dati mantenere le opzioni predefinite e quindi scegliere OK.
La scheda Opzioni origine contiene anche altre opzioni che è possibile abilitare. Questa tabella descrive tali opzioni:
| Opzione | Descrizione |
|---|---|
| Acquisisci aggiornamenti intermedi | Abilitare questa opzione se si vuole acquisire la cronologia delle modifiche apportate agli elementi, incluse le modifiche intermedie tra le letture di Change Data Capture. |
| Acquisisci eliminazioni | Abilitare questa opzione per acquisire i record eliminati dall'utente e applicarli nel sink. Le eliminazioni non possono essere applicate in Esplora dati di Azure e nei sink di Azure Cosmos DB. |
| Acquisisci record TTL dell'archivio transazionale | Abilitare questa opzione per acquisire i record TTL (Time-To-Live) eliminati dell'archivio transazionale di Azure Cosmos DB e applicarli al sink. Le eliminazioni dei record TTL non possono essere applicate a Esplora dati di Azure e ai sink di Azure Cosmos DB. |
| Dimensioni batch in byte | Questa impostazione è infatti espressa in gigabyte. Specificare le dimensioni in gigabyte se si vuole raggruppare in batch i feed di Change Data Capture |
| Configurazioni aggiuntive | Configurazioni aggiuntive dell'archivio analitico di Azure Cosmos DB e i relativi valori. (Ad esempio: spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
Utilizzo delle opzioni origine
Quando si seleziona una delle opzioni Capture intermediate updates, Capture Deltes e Capture Transactional store TTLs, il processo CDC creerà e popola il campo __usr_opType nel sink con i valori seguenti:
| Valore | Descrizione | Opzione |
|---|---|---|
| 1 | UPDATE | Acquisisci aggiornamenti intermedi |
| 2 | INSERT | Non esiste un'opzione per gli inserimenti, è attivata per impostazione predefinita |
| 3 | USER_DELETE | Acquisisci eliminazioni |
| 4 | TTL_DELETE | Acquisisci record TTL dell'archivio transazionale |
Se è necessario distinguere i record TTL eliminati dai documenti eliminati da utenti o applicazioni, è necessario selezionare entrambe le opzioni Capture intermediate updates e Capture Transactional store TTLs. È quindi necessario adattare i processi, le applicazioni o le query CDC per usare __usr_opType in base alle esigenze aziendali.
Suggerimento
Se è necessario che i consumer downstream ripristinino l'ordine degli aggiornamenti con l'opzione "Acquisisci aggiornamenti intermedi" selezionata, il campo _ts del timestamp di sistema può essere usato come campo di ordinamento.
Creare e configurare le impostazioni del sink per le operazioni di aggiornamento ed eliminazione
Prima di tutto, creare un sink di Archiviazione BLOB di Azure e quindi configurare il sink per filtrare i dati solo per operazioni specifiche.
Se non se ne ha già uno, creare un account di Archiviazione BLOB di Azure e un contenitore. Per gli esempi successivi si userà un account denominato
msdocsblobstoragee un contenitore denominatooutput.Suggerimento
Se possibile, creare l'account di archiviazione nella stessa area in cui risiede l'account Azure Cosmos DB.
Tornare ad Azure Data Factory e creare un nuovo sink per i dati delle modifiche acquisiti dall'origine
cosmos.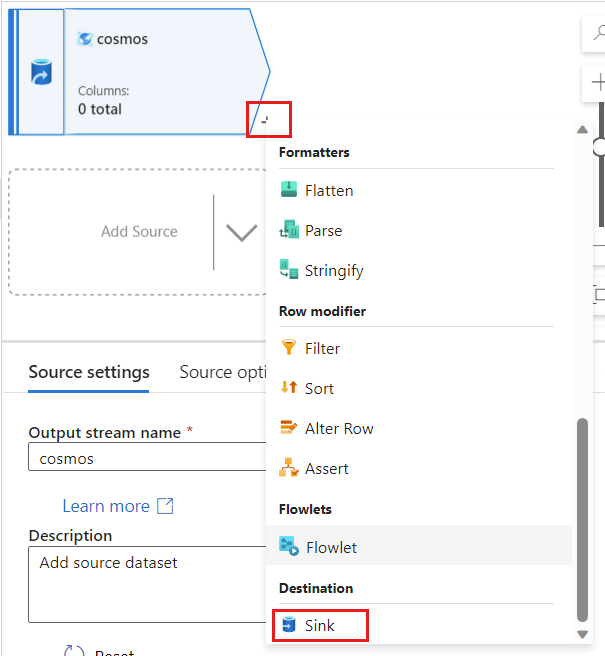
Assegnare al sink un nome univoco. In questo esempio il sink è denominato
storage.
Nella sezione Tipo di sink selezionare Inline. Nel campo Set di dati selezionare Delta.
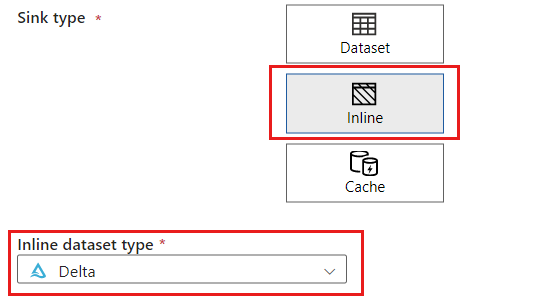
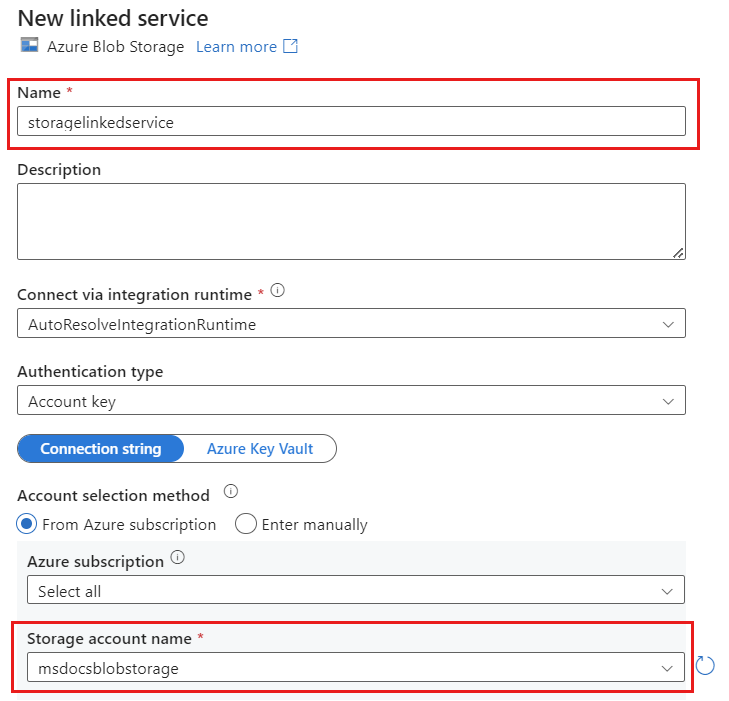
Creare un nuovo servizio collegato per l'account denominato storagelinkedservice usando Archiviazione BLOB di Azure. Selezionare l'account di archiviazione BLOB di Azure esistente nella finestra di dialogo popup Nuovo servizio collegato e quindi scegliere OK. In questo esempio viene selezionato un account di archiviazione BLOB di Azure preesistente denominato
msdocsblobstorage.
Seleziona la scheda Impostazioni.
In Impostazioni impostare Percorso cartella sul nome del contenitore BLOB. In questo esempio il nome del contenitore è
output.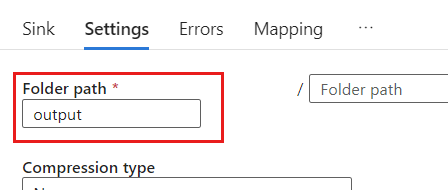
Individuare la sezione Metodo aggiornamento e modificare le selezioni in modo da consentire solo le operazioni di eliminazione e aggiornamento. Specificare anche le Colonne chiave come Elenco di colonne utilizzando il campo
{_rid}come identificatore univoco.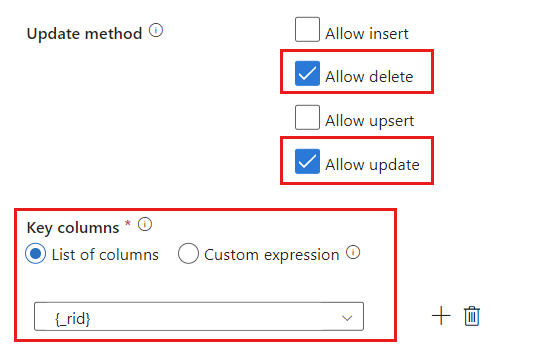
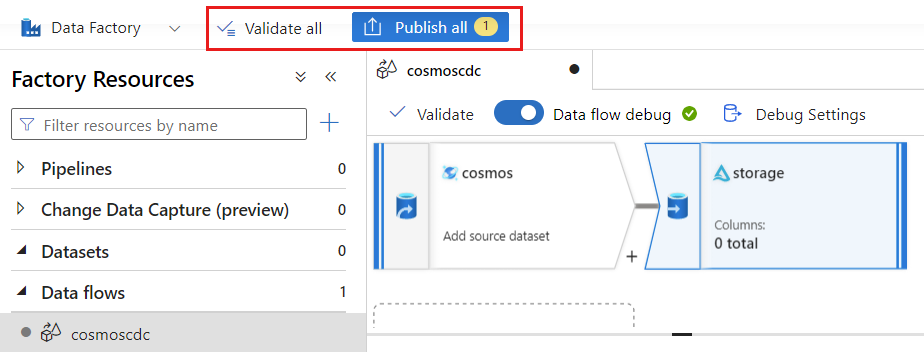
Selezionare Convalida per assicurarsi che non siano presenti errori o omissioni. Selezionare quindi Pubblica per pubblicare il flusso di dati.
Pianificare l'esecuzione di Change Data Capture
Dopo la pubblicazione di un flusso di dati, è possibile aggiungere una nuova pipeline per spostare e trasformare i dati.
Crea una nuova pipeline. Assegnare alla pipeline un nome univoco. In questo esempio la pipeline è denominata
cosmoscdcpipeline.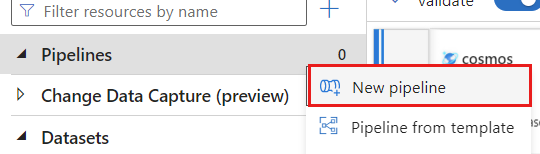
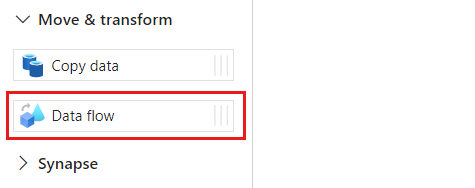
Nella sezione Attività espandere l'opzione Sposta e trasforma e quindi selezionare Flusso di dati.
Assegnare un nome univoco all'attività del flusso di dati. In questo esempio l'attività è denominata
cosmoscdcactivity.Nella scheda Impostazioni selezionare il flusso di dati denominato
cosmoscdccreato in precedenza in questa guida. Selezionare quindi una dimensione di calcolo in base al volume dei dati e alla latenza necessaria per il carico di lavoro.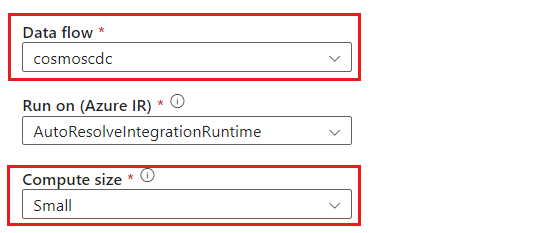
Suggerimento
Per dimensioni incrementali dei dati maggiori di 100 GB, è consigliabile usare le dimensioni Personalizzate con un numero di core pari a 32 (+16 core driver).
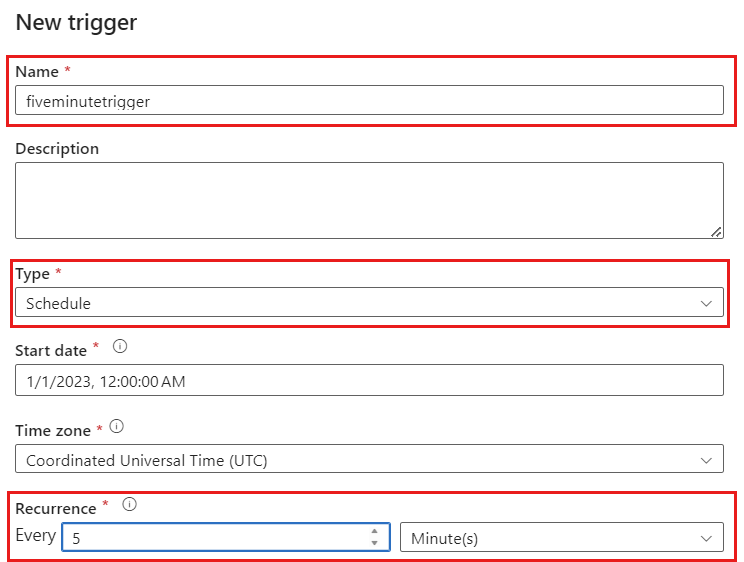
Selezionare + Aggiungi trigger. Pianificare l'esecuzione di questa pipeline alla cadenza appropriata per il carico di lavoro. In questo esempio la pipeline è configurata per l'esecuzione ogni cinque minuti.
Nota
La finestra di ricorrenza minima per le esecuzioni di Change Data Capture è di un minuto.
Selezionare Convalida per assicurarsi che non siano presenti errori o omissioni. Selezionare quindi Pubblica per pubblicare la pipeline.
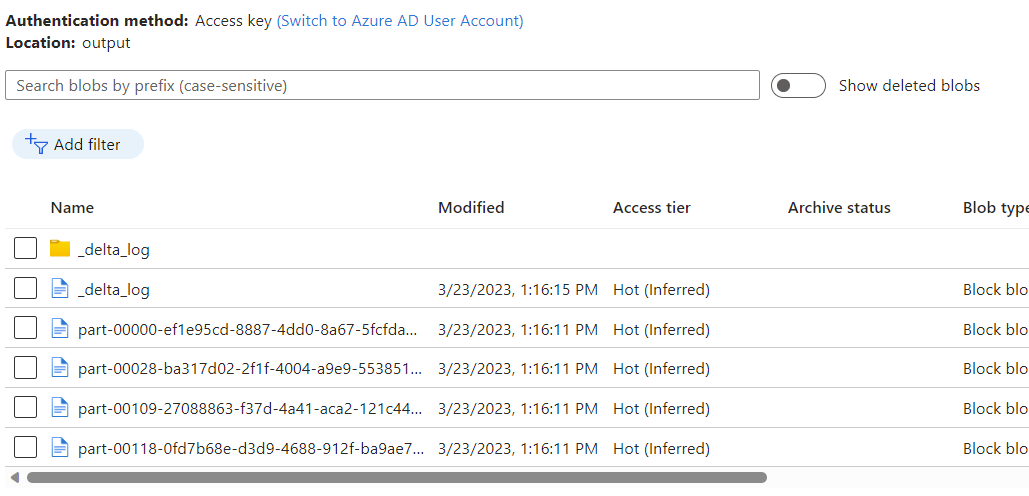
Osservare i dati inseriti nel contenitore di Archiviazione BLOB di Azure come output del flusso di dati usando Change Data Capture nell'archivio analitico di Azure Cosmos DB.
Nota
Il tempo di avvio iniziale del cluster può richiedere fino a tre minuti. Per evitare il tempo di avvio del cluster nelle esecuzioni successive di Change Data Capture, configurare il valore Durata (TTL) del cluster del flusso di dati. Per altre informazioni sul runtime di integrazione e la durata TTL, vedere Runtime di integrazione in Azure Data Factory.
Processi simultanei
Le dimensioni del batch nelle opzioni per l'origine o i casi in cui il sink è lento nell'inserimento del flusso delle modifiche, possono causare l'esecuzione di più processi contemporaneamente. Per evitare questa situazione, impostare l'opzione Concorrenza su 1 nelle impostazioni della pipeline per assicurarsi che non vengano attivate nuove esecuzioni fino al completamento dell'esecuzione corrente.