Risolvere i problemi comuni in Azure Cosmos DB for Apache Cassandra
SI APPLICA A: ![]() Cassandra
Cassandra
L'API for Cassandra in Azure Cosmos DB è un livello di compatibilità che fornisce supporto del protocollo di collegamento per il database Apache Cassandra open source.
Questo articolo descrive gli errori e le soluzioni comuni per le applicazioni che usano Azure Cosmos DB for Apache Cassandra. Se l'errore non compare nell'elenco e si verifica un problema quando si esegue un'operazione supportata in Cassandra, ma l'errore non è presente quando si usa il servizio Apache Cassandra nativo, creare una richiesta di supporto tecnico di Azure.
Nota
In qualità di servizio nativo del cloud completamente gestito, Azure Cosmos DB offre garanzie di disponibilità, velocità effettiva e coerenza per l'API for Cassandra. L'API for Cassandra facilita anche le operazioni della piattaforma senza manutenzione e l'applicazione di patch senza tempi di inattività.
Queste garanzie non sono possibili nelle implementazioni precedenti di Apache Cassandra, quindi molte delle operazioni back-end dell'API for Cassandra sono diverse da quelle di Apache Cassandra. È consigliabile adottare impostazioni e approcci specifici per evitare errori comuni.
NoNodeAvailableException
Questo errore è un'eccezione wrapper di primo livello con molte possibili cause ed eccezioni interne, molte delle quali possono essere correlate al client.
Cause comuni e soluzioni:
Timeout di inattività dei servizi di bilanciamento del carico di Azure: questo problema potrebbe anche manifestarsi come
ClosedConnectionException. Per risolvere il problema, configurare l'impostazione keep-alive nel driver (vedere Abilitare l'impostazione keep-alive per il driver Java) e aumentare il valore delle impostazioni keep-alive nel sistema operativo oppure regolare il timeout di inattività in Azure Load Balancer.Esaurimento delle risorse dell'applicazione client: assicurarsi che i computer client dispongano di risorse sufficienti per completare la richiesta.
Non è possibile connettersi a un host
Potrebbe essere visualizzato un errore simile a: "Non è possibile connettersi a un host. È previsto un nuovo tentativo tra 600.000 millisecondi".
Questo errore potrebbe essere causato da un esaurimento SNAT (Source Network Address Translation) sul lato client. Seguire la procedura descritta in SNAT per le connessioni in uscita per escludere questo problema.
L'errore potrebbe anche essere causato da un timeout di inattività in quanto il servizio di bilanciamento del carico di Azure ha quattro minuti di timeout di inattività per impostazione predefinita. Vedere timeout di inattività del servizio di bilanciamento del carico. Abilitare l'impostazione keep-alive per il driver Java e impostare l'intervallo di keepAlive nel sistema operativo su un valore minore di quattro minuti.
Per altre modalità di gestione dell'eccezione, vedere risolvere i problemi relativi a NoHostAvailableException.
OverloadedException (Java)
Le richieste vengono limitate perché il numero totale di unità richiesta utilizzate è superiore al numero di unità richiesta di cui è stato effettuato il provisioning nel keyspace o nella tabella.
Valutare la possibilità di aumentare il numero di unità richiesta assegnate a un keyspace o a una tabella dal portale di Azure (vedere Scalabilità elastica di un account Azure Cosmos DB for Apache Cassandra) o implementare un criterio di ripetizione dei tentativi.
Per Java, vedere esempi di ripetizione dei tentativi per il driver v3.x e il driver v4.x. Vedere anche Estensioni Cassandra di Azure Cosmos DB per Java.
Eccezione OverloadedException nonostante una velocità effettiva sufficiente
Il sistema sembra limitare le richieste anche se è stato effettuato il provisioning di una velocità effettiva sufficiente per il volume delle richieste o il costo di unità richiesta utilizzato. Le cause possono essere due:
Operazioni a livello di schema: l'API for Cassandra implementa un budget di velocità effettiva del sistema per le operazioni a livello di schema (CREATE TABLE, ALTER TABLE, DROP TABLE). Questo budget deve essere sufficiente per le operazioni dello schema in un sistema di produzione. Tuttavia, se il numero di operazioni a livello di schema è elevato, è possibile che questo limite venga superato.
Poiché il budget non è controllato dall'utente, è consigliabile provare a ridurre il numero di operazioni dello schema eseguite. Se l'azione non risolve il problema o non è fattibile per il carico di lavoro, creare una richiesta di supporto tecnico di Azure.
Asimmetria dei dati: quando viene effettuato il provisioning della velocità effettiva nell'API for Cassandra, i dati vengono divisi equamente tra le partizioni fisiche e ogni partizione fisica prevede un limite massimo. In caso di inserimento o query su un volume di dati elevato da una partizione specifica, le richieste potrebbero essere limitate anche se si effettua il provisioning di una grande quantità di velocità effettiva complessiva (unità richiesta) per tale tabella.
Esaminare il modello di dati e assicurarsi che non sia presente un'asimmetria eccessiva con partizioni ad accesso molto frequente.
Errori di connettività intermittente (Java)
La connessione si interrompe o si verifica un timeout imprevisto.
I driver Apache Cassandra per Java forniscono due criteri di riconnessione nativi: ExponentialReconnectionPolicy e ConstantReconnectionPolicy. Il valore predefinito è ExponentialReconnectionPolicy. Tuttavia, per Azure Cosmos DB for Apache Cassandra, è consigliabile ConstantReconnectionPolicy con un ritardo di due secondi.
Vedere la documentazione per il driver Java 4.x, la documentazione per il driver Java 3.x o gli esempi in Configurazione dei criteri di riconnessione per il driver Java.
Errore dei criteri di bilanciamento del carico
È possibile che sia stato implementato un criterio di bilanciamento del carico nella versione 3.x del driver DataStax Java, con un codice simile al seguente:
cluster = Cluster.builder()
.addContactPoint(cassandraHost)
.withPort(cassandraPort)
.withCredentials(cassandraUsername, cassandraPassword)
.withPoolingOptions(new PoolingOptions() .setConnectionsPerHost(HostDistance.LOCAL, 1, 2)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32000).setMaxQueueSize(Integer.MAX_VALUE))
.withSSL(sslOptions)
.withLoadBalancingPolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("West US").build())
.withQueryOptions(new QueryOptions().setConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM))
.withSocketOptions(getSocketOptions())
.build();
Se il valore per withLocalDc() non corrisponde al data center del punto di contatto, è possibile che si verifichi un errore intermittente: com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (no host was tried).
Implementare il criterio CosmosLoadBalancingPolicy. Per farlo funzionare, potrebbe essere necessario aggiornare DataStax usando il codice seguente:
LoadBalancingPolicy loadBalancingPolicy = new CosmosLoadBalancingPolicy.Builder().withWriteDC("West US").withReadDC("West US").build();
L'operazione count ha esito negativo in una tabella di grandi dimensioni
Quando si esegue select count(*) from table o una funzione simile per un numero elevato di righe, si verifica un timeout del server.
Se si usa un client CQLSH locale, modificare le impostazioni di --connect-timeout o --request-timeout. Vedere cqlsh: the CQL shell.
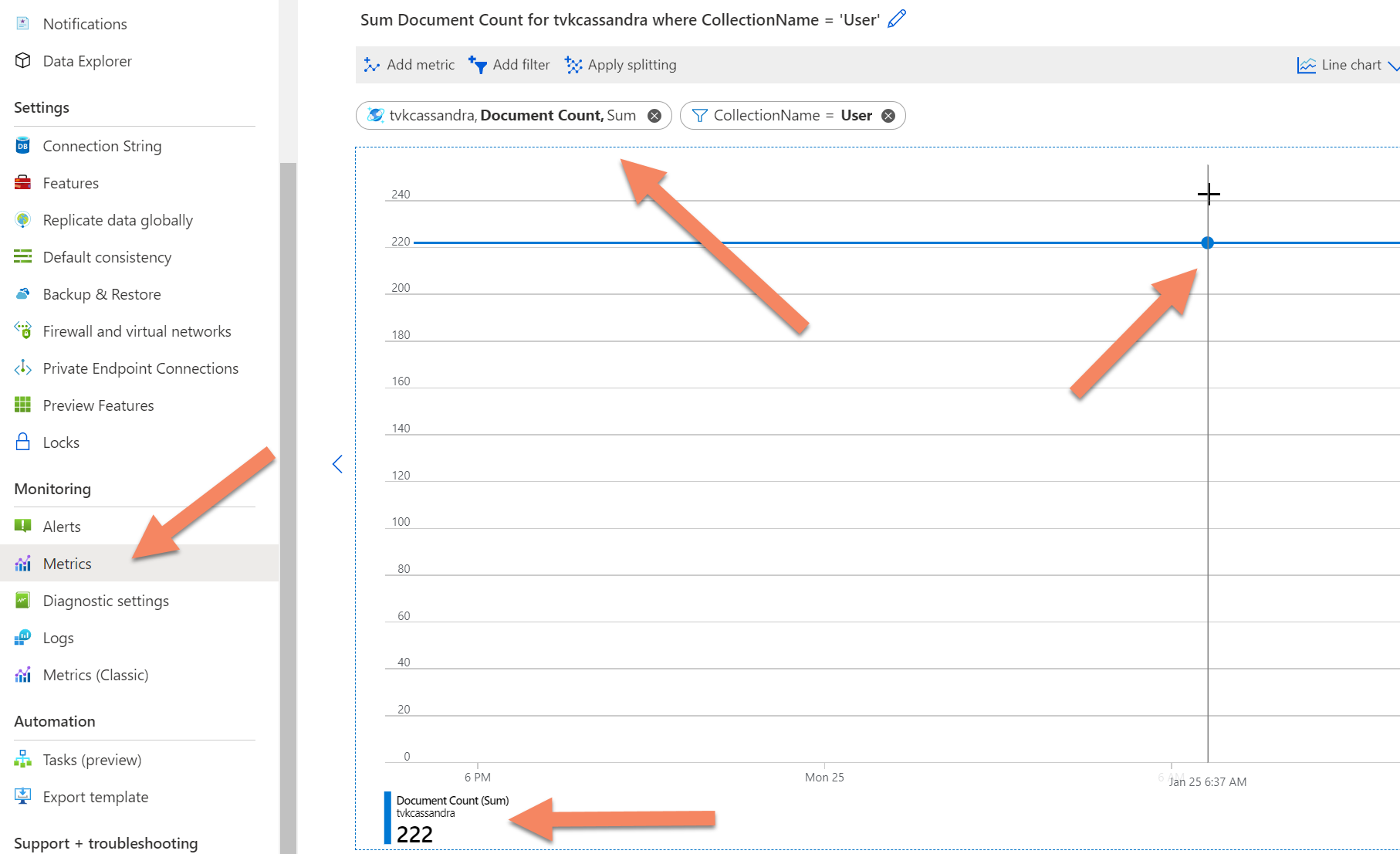
Se il timeout per l'operazione count persiste, è possibile ottenere un conteggio dei record dai dati di telemetria del back-end di Azure Cosmos DB passando alla scheda Metriche nel portale di Azure, selezionando la metrica document count e quindi aggiungendo un filtro per il database o la raccolta (che corrisponde alla tabella in Azure Cosmos DB). È quindi possibile passare il puntatore del mouse sul grafico risultante per il momento nel tempo per cui si desidera un conteggio del numero di record.
Configurare i criteri di riconnessione per il driver Java
Versione 3.x
Per la versione 3.x del driver Java, configurare i criteri di riconnessione quando si crea un oggetto cluster:
import com.datastax.driver.core.policies.ConstantReconnectionPolicy;
Cluster.builder()
.withReconnectionPolicy(new ConstantReconnectionPolicy(2000))
.build();
Versione 4.x
Per la versione 4.x del driver Java, configurare i criteri di riconnessione eseguendo l'override delle impostazioni nel file reference.conf:
datastax-java-driver {
advanced {
reconnection-policy{
# The driver provides two implementations out of the box: ExponentialReconnectionPolicy and
# ConstantReconnectionPolicy. We recommend ConstantReconnectionPolicy for API for Cassandra, with
# base-delay of 2 seconds.
class = ConstantReconnectionPolicy
base-delay = 2 second
}
}
Abilitare l'impostazione keep-alive per il driver Java
Versione 3.x
Per la versione 3.x del driver Java, configurare l'impostazione keep-alive quando si crea un oggetto cluster e quindi assicurarsi che l'impostazione keep-alive sia abilitata nel sistema operativo:
import java.net.SocketOptions;
SocketOptions options = new SocketOptions();
options.setKeepAlive(true);
cluster = Cluster.builder().addContactPoints(contactPoints).withPort(port)
.withCredentials(cassandraUsername, cassandraPassword)
.withSocketOptions(options)
.build();
Versione 4.x
Per la versione 3.x del driver Java, configurare l'impostazione keep-alive eseguendo l'override delle impostazioni in reference.conf e quindi assicurarsi che l'impostazione keep-alive sia abilitata nel sistema operativo:
datastax-java-driver {
advanced {
socket{
keep-alive = true
}
}
Passaggi successivi
- Informazioni sulle funzionalità supportate in Azure Cosmos DB for Apache Cassandra.
- Informazioni su come eseguire la migrazione da Apache Cassandra nativo ad Azure Cosmos DB for Apache Cassandra.