Configurare probe di attività
Le applicazioni nei contenitori possono essere eseguite per periodi prolungati di tempo e ciò può causare stati interrotti che potrebbe risultare necessario ripristinare riavviando il contenitore. Istanze di Azure Container supporta probe di attività in modo che sia possibile configurare i contenitori all'interno del gruppo di contenitori per il riavvio se la funzionalità critica non funziona. Il probe di idoneità si comporta come un probe di attività Kubernetes.
Questo articolo illustra come distribuire un gruppo di contenitori che include un probe di attività, per dimostrare il riavvio automatico di un contenitore non integro simulato.
Istanze di Azure Container supporta anche i probe di idoneità, che è possibile configurare per garantire che il traffico raggiunga un contenitore solo quando è pronto.
Distribuzione con file YAML
Creare un file liveness-probe.yaml con il frammento seguente. Questo file definisce un gruppo di contenitori costituito da un contenitore NGINX che diventa non integro.
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
Eseguire il comando seguente per distribuire questo gruppo di contenitori con la configurazione YAML riportata in precedenza:
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
Comando di avvio
La distribuzione include una proprietà command che definisce un comando iniziale che viene eseguito al primo avvio dell'esecuzione del contenitore. Questa proprietà accetta una matrice di stringhe. Questo comando simula l'immissione di uno stato non integro del contenitore.
Prima di tutto, avvia una sessione bash e crea un file denominato healthy all'interno della directory /tmp. L'operazione viene quindi sospesa per 30 secondi prima di eliminare il file, poi viene attivata una sospensione di 10 minuti:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
Comando di verifica dell'attività (liveness)
Questa distribuzione definisce un livenessProbe che supporta un comando di verifica dell'attività exec usato come controllo di attività. Se questo comando termina con un valore diverso da zero, il contenitore viene terminato e riavviato, a indicare che non è stato trovato il file healthy. Se questo comando termina correttamente con il codice di uscita 0, non viene eseguita alcuna azione.
La proprietà periodSeconds stabilisce che il comando di verifica dell'attività deve essere eseguito ogni 5 secondi.
Verificare l'output di attività
Entro i primi 30 secondi deve essere confermata l'esistenza del file healthy creato dal comando di avvio. Quando il comando di verifica dell'attività controlla l'esistenza del file healthy, il codice di stato restituisce 0, a indicare l'esito positivo, quindi non si verifica alcun riavvio.
Dopo 30 secondi, il comando cat /tmp/healthy inizia ad avere esito negativo, con conseguente generazione degli eventi per lo stato non integro e la terminazione.
Questi eventi possono essere visualizzati dal portale di Azure o dall'interfaccia della riga di comando di Azure.
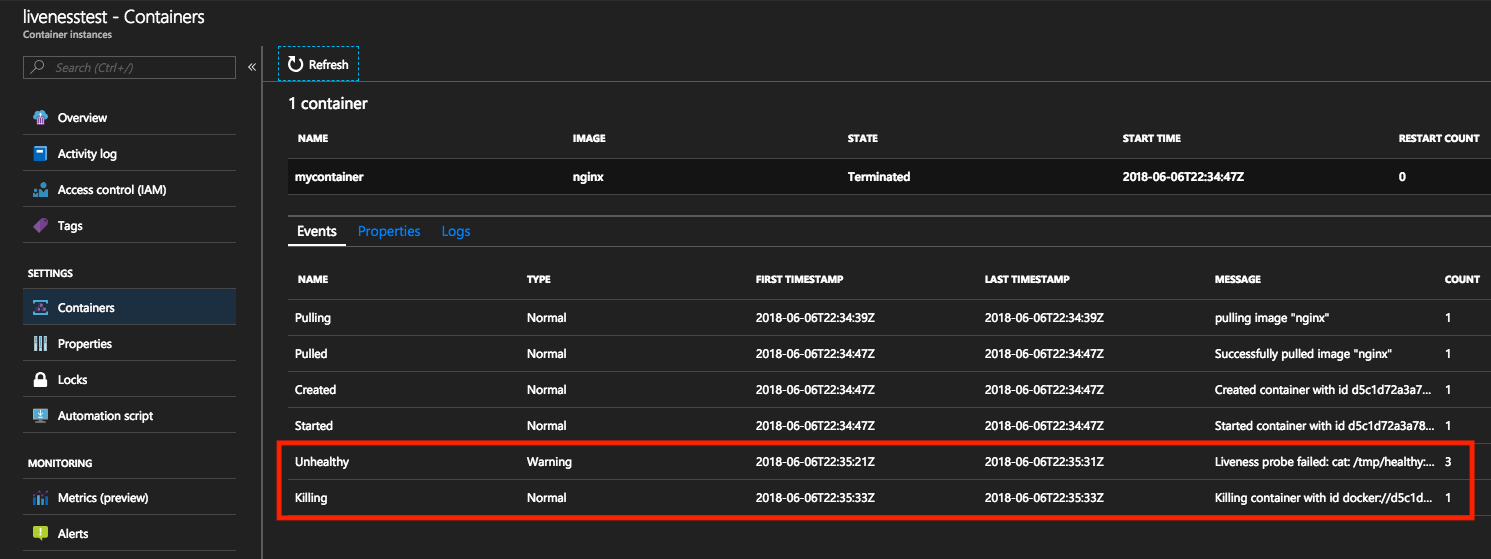
Quando si visualizzano gli eventi nel portale di Azure, gli eventi di tipo Unhealthy vengono attivati in caso di errore del comando di attività. L'evento successivo è di tipo Killing, che significa l'eliminazione di un contenitore, quindi può iniziare un riavvio. Il conteggio di riavvio per il contenitore incrementa ogni volta che si verifica questo evento.
I riavvi vengono completati sul posto, in modo da mantenere risorse come gli indirizzi IP pubblici e il contenuto specifico del nodo.

Se il probe di attività ha continuamente esito negativo e genera troppi riavvii, per il contenitore subentra un ritardo di backoff esponenziale.
Probe di attività e criteri di riavvio
I criteri di riavvio sostituiscono il comportamento di riavvio attivato dai probe di attività. Ad esempio, se si impostano i criteri restartPolicy = Never e un probe di attività, il gruppo di contenitori non verrà riavviato a causa di un controllo di attività non riuscito. Il gruppo di contenitori deve invece rispettare i criteri di riavvio Never del gruppo di contenitori.
Passaggi successivi
Per gli scenari basati su attività potrebbe essere necessario che un probe di attività abiliti i riavvii automatici se una funzione prerequisito non funziona correttamente. Per altre informazioni sull'esecuzione di contenitori basati su attività, vedere Eseguire attività in contenitori in Istanze di Azure Container.