Velocizzare l'analisi di Big Data in tempo reale con il connettore Spark
Si applica a:![]() Database SQL di Azure
Database SQL di Azure![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Nota
A partire da settembre 2020, questo connettore non è più mantenuto attivamente. Tuttavia, Apache Spark Connector per SQL Server e Azure SQL è ora disponibile, con il supporto per i binding Python e R, un'interfaccia più semplice da usare per l'inserimento di dati in blocco e molti altri miglioramenti. È consigliabile valutare e usare il nuovo connettore anziché questo. Le informazioni sul connettore precedente (questa pagina) vengono conservate solo a scopo di archiviazione.
Il connettore Spark consente ai database in Azure SQL Database, Istanza gestita di Azure SQL e SQL Server di fungere da origine dati di input o destinazione dati di output per i compiti Spark. È possibile utilizzare dati transazionali in tempo reale nel processo di big data analytics e mantenere i risultati per query ad hoc o per la generazione di report. Rispetto al connettore JDBC incorporato, questo connettore offre la possibilità di inserire dati in grandi quantità nel proprio database. Può superare l'inserimento riga per riga con prestazioni 10x a 20x più veloci. Il connettore Spark supporta l'autenticazione con Microsoft Entra ID (in precedenza Azure Active Directory) per connettersi a database SQL di Azure e Istanza gestita di SQL di Azure, consentendo di connettere il database da Azure Databricks usando l'account Microsoft Entra. Fornisce interfacce simili al connettore JDBC incorporato. È facile eseguire la migrazione dei processi Spark esistenti per l'utilizzo di questo nuovo connettore.
Nota
Microsoft Entra ID era precedentemente conosciuto come Azure Active Directory (Azure AD).
Scaricare e compilare un connettore Spark
Il repository GitHub per il vecchio connettore precedentemente collegato da questa pagina non viene gestito attivamente. È invece consigliabile valutare e usare il nuovo connettore.
Versioni supportate ufficialmente
| Componente | Versione |
|---|---|
| Apache Spark | 2.0.2 o versione successiva |
| Scala | 2.10 o versione successiva |
| Driver Microsoft JDBC per SQL Server | 6.2 o versione successiva |
| Microsoft SQL Server | SQL Server 2008 o versione successiva |
| Database SQL di Azure | Supportato |
| Istanza gestita di SQL di Azure | Supportata |
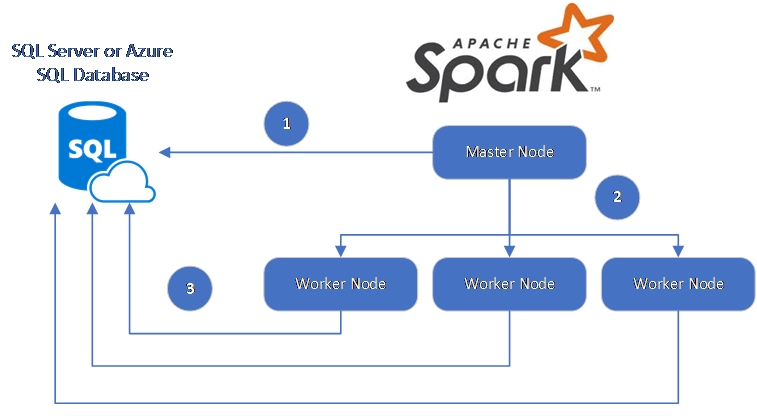
Il connettore Spark utilizza Microsoft JDBC Driver per SQL Server per trasferire dati tra i nodi di lavoro Spark e i database SQL:
Il flusso di dati è il seguente:
- Il nodo principale Spark si connette al database SQL o a SQL Server e carica i dati da una tabella specifica o utilizzando una query SQL specifica.
- Il nodo principale Spark distribuisce i dati ai nodi di lavoro per la trasformazione.
- Il nodo di lavoro si connette a database che a loro volta si collegano al database SQL e a SQL Server e scrive i dati nel database. L'utente può scegliere se utilizzare l'inserimento riga per riga o l'inserimento in blocco.
Il diagramma seguente illustra il flusso di dati.
Creare il connettore Spark
Attualmente il progetto del connettore usa Maven. Per creare il connettore senza le dipendenze, è possibile eseguire:
- mvn clean package (esegue una compilazione pulita e crea il pacchetto del progetto)
- Scaricare le versioni più recenti del file JAR dalla cartella release
- Includere il JAR del database SQL Spark
Effettuare la connessione e leggere i dati usando il connettore Spark
È possibile connettersi al database SQL e SQL Server dai processi di Spark per leggere o scrivere dati. È anche possibile eseguire una query DML o DDL nei database all'interno di SQL Database e di SQL Server.
Leggere dati da Azure SQL o SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Leggere i dati da Azure SQL e SQL Server con una query SQL specificata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Scrivere i dati in Azure SQL e SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Acquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Eseguire una query DML o DDL in Azure SQL o SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Connettersi da Spark utilizzando l'autenticazione di Microsoft Entra
È possibile connettersi a Database SQL e Istanza SQL gestita usando l'autenticazione di Microsoft Entra. Usare l'autenticazione di Microsoft Entra per gestire centralmente le identità degli utenti del database e come alternativa all'autenticazione di SQL.
Connessione tramite la modalità di autenticazione ActiveDirectoryPassword
Requisiti di installazione
Se si utilizza la modalità di autenticazione ActiveDirectoryPassword, è necessario scaricare microsoft-authentication-library-for-java e le relative dipendenze e includerli nel percorso di compilazione Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Connessione tramite token di accesso
Requisiti di installazione
Se si utilizza la modalità di autenticazione basata su token di accesso, è necessario scaricare microsoft-authentication-library-for-java e le relative dipendenze e includerli nel percorso di compilazione Java.
Consulta l'uso dell'autenticazione Microsoft Entra per sapere come ottenere un token di accesso per il database nel database SQL di Azure o nell'Istanza gestita di Azure SQL.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Scrivere dati con BULK INSERT
Il connettore JDBC tradizionale scrive i dati nel tuo database tramite l'inserimento riga per riga. È possibile utilizzare il connettore da Spark per scrivere dati in Azure SQL e SQL Server tramite l’inserimento in blocco. Migliora significativamente le prestazioni di scrittura durante il caricamento di grandi set di dati o quando si caricano dati in tabelle in cui viene utilizzato un indice columnstore.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Passaggi successivi
Se ancora non lo si è fatto, scaricare il connettore Spark dal repository GitHub azure-sqldb-spark ed esplorare le risorse aggiuntive nel repository:
Potresti anche voler consultare la guida ad Apache Spark SQL, DataFrames e set di dati e la documentazione di Azure Databricks.