Eseguire la migrazione del database SQL di Azure dal modello basato su DTU al modello basato su vCore
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
Questo articolo descrive come eseguire la migrazione del database nel database SQL di Azure dal modello di acquisto basato su DTU al modello di acquisto basato su vCore.
Eseguire la migrazione di un database
La migrazione di un database dal modello di acquisto basato su DTU al modello di acquisto basato su vCore è simile al ridimensionamento tra gli obiettivi di servizio nei livelli di servizio Basic, standard e Premium, con una durata e un tempo di inattività minimo simili alla fine del processo di migrazione. Un database migrato al modello di acquisto basato su vCore può essere migrato di nuovo al modello di acquisto basato su DTU in qualsiasi momento con l’uso degli stessi passaggi, ad eccezione dei database migrati al livello di servizio Hyperscale.
È possibile eseguire la migrazione del database a un modello di acquisto diverso usando il portale di Azure, PowerShell, l'interfaccia della riga di comando di Azure e Transact-SQL.
Per eseguire la migrazione del database a un modello di acquisto diverso usando il portale di Azure, seguire queste procedure:
Passare al database SQL nel portale di Azure.
In Impostazioni selezionare Calcolo e archiviazione.
Usare l'elenco a discesa in Livello di servizio per selezionare un nuovo modello di acquisto e un nuovo livello di servizio:
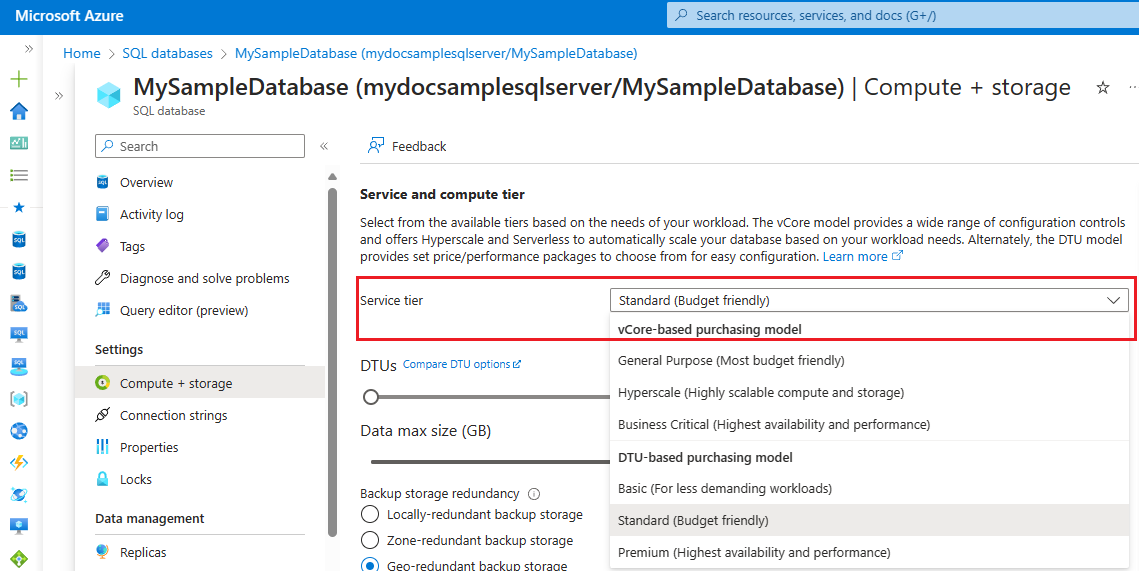

Scegliere il livello di servizio vCore e l'obiettivo di servizio
Per la maggior parte degli scenari di migrazione da DTU a vCore, i database e i pool elastici nei livelli di servizio Basic e standard verranno mappati al livello di servizio Utilizzo generico. I database e i pool elastici nel livello di servizio Premium verranno mappati al livello di servizio Business Critical. A seconda dello scenario e dei requisiti dell'applicazione, il livello di servizio Hyperscale può spesso essere usato come destinazione di migrazione per database e pool elastici in tutti i livelli di servizio DTU.
Per scegliere l'obiettivo di servizio o le dimensioni di calcolo per il database migrato nel modello vCore, puoi usare una regola semplice ma approssimativa: ogni 100 DTU nei livelli Basic o Standard viene richiesto almeno 1 vCore e ogni 125 DTU nel livello Premium viene richiesto almeno 1 vCore.
Suggerimento
Questa regola è approssimativa perché non considera il tipo specifico di hardware usato per il database DTU o il pool elastico.
Nel modello DTU il sistema può selezionare qualsiasi configurazione hardware disponibile per il database o il pool elastico. Inoltre, nel modello DTU hai solo il controllo indiretto sul numero di vCore (CPU logiche) scegliendo valori DTU o eDTU superiori o inferiori.
Nel modello vCore i clienti devono scegliere esplicitamente sia la configurazione hardware che il numero di vCore (CPU logiche). Anche se il modello DTU non offre queste opzioni, il tipo di hardware e il numero di CPU logiche usate per ogni database e pool elastico vengono esposti tramite DMV. In questo modo è possibile determinare più precisamente l'obiettivo del servizio vCore corrispondente.
L'approccio seguente usa queste informazioni per determinare un obiettivo di servizio vCore con un'allocazione simile di risorse, per ottenere un livello di prestazioni simile dopo la migrazione al modello vCore.
Mapping da DTU a vCore
La query Transact-SQL riportata di seguito, se eseguita nel contesto di un database DTU di cui eseguire la migrazione, restituisce un numero corrispondente (eventualmente frazionario) di vCore in ciascuna configurazione hardware del modello vCore. È possibile arrotondare questo numero al numero più vicino di vCore disponibili per i database e i pool elastici in ogni configurazione hardware nel modello vCore. I clienti possono scegliere l'obiettivo di servizio vCore più vicino per il database DTU o il pool elastico.
Gli scenari di migrazione di esempio che usano questo approccio sono descritti nella sezione Esempi.
Esegui questa query nel contesto del database di cui eseguire la migrazione, anziché nel database master. Quando esegui la migrazione di un pool elastico, esegui la query nel contesto di qualsiasi database nel pool.
;WITH dtu_vcore_map
AS (
SELECT rg.slo_name,
CAST(DATABASEPROPERTYEX(DB_NAME(), 'Edition') AS NVARCHAR(40)) COLLATE DATABASE_DEFAULT AS dtu_service_tier,
CASE
WHEN slo.slo_name LIKE '%SQLG4%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLGZ%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLG5%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG6%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG7%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%GPGEN8%' THEN 'standard_series'
END COLLATE DATABASE_DEFAULT AS dtu_hardware_gen,
s.scheduler_count * CAST(rg.instance_cap_cpu / 100. AS DECIMAL(3, 2)) AS dtu_logical_cpus,
CAST((jo.process_memory_limit_mb / s.scheduler_count) / 1024. AS DECIMAL(4, 2)) AS dtu_memory_per_core_gb
FROM sys.dm_user_db_resource_governance AS rg
CROSS JOIN (
SELECT COUNT(1) AS scheduler_count
FROM sys.dm_os_schedulers
WHERE status COLLATE DATABASE_DEFAULT = 'VISIBLE ONLINE'
) AS s
CROSS JOIN sys.dm_os_job_object AS jo
CROSS APPLY (SELECT UPPER(rg.slo_name) COLLATE DATABASE_DEFAULT AS slo_name) slo
WHERE rg.dtu_limit > 0
AND DB_NAME() COLLATE DATABASE_DEFAULT <> 'master'
AND rg.database_id = DB_ID()
)
SELECT dtu_logical_cpus,
dtu_memory_per_core_gb,
dtu_service_tier,
CASE
WHEN dtu_service_tier = 'Basic' THEN 'General Purpose'
WHEN dtu_service_tier = 'Standard' THEN 'General Purpose or Hyperscale'
WHEN dtu_service_tier = 'Premium' THEN 'Business Critical or Hyperscale'
END AS vcore_service_tier,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus
END AS standard_series_vcores,
5.05 AS standard_series_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.8
END AS Fsv2_vcores,
1.89 AS Fsv2_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.9
END AS M_vcores,
29.4 AS M_memory_per_core_gb
FROM dtu_vcore_map;
Fattori aggiuntivi
Oltre al numero di vCore (CPU logiche) e al tipo di hardware, diversi altri fattori possono influenzare la scelta dell'obiettivo del servizio vCore:
La query Transact-SQL di mapping corrisponde agli obiettivi del servizio DTU e vCore in termini di capacità della CPU, pertanto i risultati saranno più accurati per i carichi di lavoro associati alla CPU.
Per lo stesso tipo di hardware e lo stesso numero di vCore, i limiti delle risorse di produttività delle operazioni di I/O al secondo e dei log delle transazioni per i database vCore sono spesso superiori rispetto ai database DTU. Per i carichi di lavoro associati a I/O, può essere possibile ridurre il numero di vCore nel modello vCore per ottenere lo stesso livello di prestazioni. I limiti effettivi delle risorse per i database DTU e vCore vengono esposti nella vista sys.dm_user_db_resource_governance. Il confronto di questi valori tra il database o il pool DTU di cui eseguire la migrazione e un database o un pool vCore con un obiettivo di servizio approssimativamente corrispondente consente di selezionare più precisamente l'obiettivo del servizio vCore.
La query di mapping restituisce anche la quantità di memoria per core per il database DTU o il pool elastico di cui eseguire la migrazione e per ogni configurazione hardware nel modello vCore. Garantire memoria totale simile o superiore dopo la migrazione a vCore è importante per i carichi di lavoro che richiedono una cache di dati di memoria di grandi dimensioni per ottenere prestazioni sufficienti o carichi di lavoro che richiedono concessioni di memoria di grandi dimensioni per l'elaborazione delle query. Per tali carichi di lavoro, a seconda delle prestazioni effettive, potrebbe essere necessario aumentare il numero di vCore in modo da ottenere una memoria totale sufficiente.
L'utilizzo cronologico delle risorse del database DTU deve essere considerato quando si sceglie l'obiettivo del servizio vCore. I database DTU con risorse CPU sottoutilizzate in modo coerente potrebbero richiedere meno vCore rispetto al numero restituito dalla query di mapping. Viceversa, i database DTU in cui un utilizzo costante elevato della CPU causa prestazioni del carico di lavoro inadeguate possono richiedere più vCore rispetto a quelli restituiti dalla query.
Se esegui la migrazione di database con modelli di utilizzo intermittenti o imprevedibili, prendi in considerazione l'uso del livello di calcolo Serverless per il database SQL di Azure. Il numero massimo di ruoli di lavoro simultanei in serverless è pari al 75% del limite nel calcolo con provisioning per lo stesso numero di vCore massimi configurati. Inoltre, la memoria massima disponibile in serverless è pari a 3 GB per il numero massimo di vCore configurati, che è minore della memoria per core per un calcolo in provisioning. Ad esempio, su Gen5 la memoria massima è di 120 GB quando 40 vCore massimi sono configurati in modalità serverless, contro i 204 GB di un calcolo con 40 vCore in provisioning.
Nel modello vCore le dimensioni massime supportate del database possono variare a seconda dell'hardware. Per i database di grandi dimensioni, controlla le dimensioni massime supportate nel modello vCore per database singoli e pool elastici.
Per i pool elastici, i limiti delle risorse per i pool elastiche che utilizzano il modello di acquisto DTU e vCore presentano differenze nel numero massimo di database supportati per pool. Questo fattore deve essere considerato quando si esegue la migrazione di pool elastici con molti database.
Alcune configurazioni hardware potrebbero non essere disponibili in ogni area. Controlla la disponibilità in Configurazione hardware per database SQL.
Le linee guida per il dimensionamento da DTU a vCore sopra sono fornite per facilitare la stima iniziale dell'obiettivo di servizio del database di destinazione.
La configurazione ottimale del database di destinazione dipende dal carico di lavoro. Pertanto, per ottenere il rapporto prezzo/prestazioni ottimale dopo la migrazione, potrebbe essere necessario sfruttare la flessibilità del modello vCore per regolare il numero di vCore, la configurazione hardware e i livelli di calcolo e servizio. Potrebbe anche essere necessario modificare i parametri di configurazione del database, ad esempio il grado massimo di parallelismo e/o modificare il livello di compatibilità del database per consentire miglioramenti recenti nel motore di database.
Esempi di migrazione da DTU a vCore
Nota
I valori negli esempi seguenti sono solo a scopo illustrativo. I valori effettivi restituiti negli scenari descritti possono essere diversi.
Migrazione di un database S9 Standard
La query di mapping restituisce il risultato seguente (alcune colonne non sono visualizzate per brevità):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 24.00 | 5.40 | 24.000 | 5,05 |
Vediamo che il database standard DTU ha 24 CPU logiche (vCore), con 5,4 GB di memoria per vCore. La corrispondenza diretta è un database Per utilizzo generico 2 vCore su hardware di serie standard (Gen5), l'obiettivo di servizio vCore GP_Gen5_24.
Migrazione di un database S0 standard
La query di mapping restituisce il risultato seguente (alcune colonne non sono visualizzate per brevità):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 0,25 | 1.3 | 0,500 | 5,05 |
Vediamo che il database standard DTU presenta l’equivalente di 0,25 CPU logiche (vCore), con 1,3 GB di memoria per vCore. Gli obiettivi di servizio vCore più piccoli nella configurazione hardware della serie standard (Gen5), GP_Gen5_2, forniscono più risorse di calcolo rispetto al database standard S0, quindi non è possibile trovare una corrispondenza diretta. L'opzione GP_Gen5_2 è preferibile. Inoltre, se il carico di lavoro è adatto per il livello di calcolo serverless, GP_S_Gen5_1 sarebbe una corrispondenza più vicina.
Migrazione di un database Premium P15
La query di mapping restituisce il risultato seguente (alcune colonne non sono visualizzate per brevità):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 42.00 | 4,86 | 42.000 | 5,05 |
Vediamo che il database DTU ha 42 CPU logiche (vCore), con 4,86 GB di memoria per vCore. Anche se non esiste un obiettivo di servizio vCore con 42 core, l'obiettivo di servizio BC_Gen5_40 è quasi equivalente in termini di capacità di CPU e memoria ed è una buona corrispondenza.
Migrazione di un pool elastico Basic 200 eDTU
La query di mapping restituisce il risultato seguente (alcune colonne non sono visualizzate per brevità):
| dtu_logical_cpus | dtu_memory_per_core_gb | standard_series_vcores | standard_series_memory_per_core_gb |
|---|---|---|---|
| 4.00 | 5.40 | 4,000 | 5,05 |
Vediamo che il pool elastico DTU ha 4 CPU logiche (vCore), con 5,4 GB di memoria per vCore. L'hardware della serie standard richiede 4 vCore, tuttavia questo obiettivo di servizio supporta un massimo di 200 database per pool, mentre il pool elastico Basic 200 eDTU supporta fino a 500 database. Se il pool elastico da migrare presenta più di 200 database, l'obiettivo del servizio vCore corrispondente dovrà essere GP_Gen5_6, che supporta fino a 500 database.
Eseguire la migrazione dei database con replica geografica
La migrazione dal modello basato su DTU al modello di acquisto basato su vCore è simile all'aggiornamento o al downgrade delle relazioni di replica geografica tra i livelli di servizio standard e Premium. Durante la migrazione non è necessario arrestare la replica geografica per i livelli di servizio Utilizzo generico e Business Critical, ma è necessario seguire queste regole di sequenza:
- Quando si esegue l'aggiornamento, è necessario aggiornare prima il database secondario e dopo il database primario.
- Quando si esegue il downgrade, è necessario seguire l'ordine inverso, ovvero eseguire prima il downgrade del database primario e dopo quello del database secondario.
Per eseguire la migrazione al livello di servizio Hyperscale, la replica geografica deve essere rimossa temporaneamente. Per altre informazioni, vedere Eseguire la migrazione di un database esistente a Hyperscale.
Quando usi la replica geografica tra due pool elastici, è consigliabile che designi un pool come primario e l'altro come secondario. In questo caso, quando esegui la migrazione dei pool elastici devi rispettare le stesse linee guida per la sequenza. Tuttavia, se disponi di pool elastici che contengono database primari e secondari, considera il pool con l’utilizzo maggiore come primario e segui pertanto le regole di sequenza.
La tabella seguente contiene linee guida per scenari di migrazione specifici:
| Livello di servizio corrente | Livello di servizio di destinazione | Tipo di migrazione | Azioni utente |
|---|---|---|---|
| Standard | Utilizzo generico | Laterale | La migrazione può avvenire in qualsiasi ordine, ma è necessario garantire un dimensionamento adeguato dei vCore come descritto in precedenza |
| Premium | Business Critical | Laterale | La migrazione può avvenire in qualsiasi ordine, ma è necessario garantire un dimensionamento adeguato dei vCore come descritto in precedenza |
| Standard | Business Critical | Aggiornamento | È necessario eseguire prima la migrazione del database secondario |
| Business Critical | Standard | Downgrade | È necessario eseguire prima la migrazione del database primario |
| Premium | Utilizzo generico | Downgrade | È necessario eseguire prima la migrazione del database primario |
| Utilizzo generico | Premium | Aggiornamento | È necessario eseguire prima la migrazione del database secondario |
| Business Critical | Utilizzo generico | Downgrade | È necessario eseguire prima la migrazione del database primario |
| Utilizzo generico | Business Critical | Aggiornamento | È necessario eseguire prima la migrazione del database secondario |
| Standard | Hyperscale | Laterale | Replica geografica da disattivare prima della migrazione a Hyperscale |
| Premium | Hyperscale | Laterale | Replica geografica da disattivare prima della migrazione a Hyperscale |
Eseguire la migrazione dei gruppi di failover
Per i gruppi di failover con più database è necessario eseguire separatamente la migrazione dei database primari e secondari. Durante questo processo sono valide le stesse considerazioni e regole di sequenziazione. Dopo la conversione dei database nel modello di acquisto basato su vCore, il gruppo di failover rimane attivo con le stesse impostazioni di criteri.
Creare database secondari di replica geografica
Puoi creare un database secondario di replica geografica (un database geografico secondario) solo usando lo stesso livello di servizio usato per il database primario. Per i database con frequenza di generazione dei log elevata, è consigliabile creare il database geografico secondario con le stesse dimensioni di calcolo del database primario.
Se nel pool elastico viene creato un database secondario di replica geografica per un singolo database primario, verifica che l’impostazione maxVCore per il pool corrisponda alle dimensioni di calcolo del database primario. Se crei un database geografico secondario per un database primario in un altro pool elastico, è consigliabile che i pool abbiano le stesse impostazioni di maxVCore.
Usare la copia del database per eseguire la migrazione da DTU a vCore
La copia del database crea uno snapshot coerente in modo transazionale dei dati a partire da un punto nel tempo dopo l'avvio dell'operazione di copia. Non sincronizza i dati tra l'origine e la destinazione dopo quel punto nel tempo.
È possibile copiare un database con dimensioni di calcolo basate su DTU in un database con dimensioni di calcolo basate su vCore usando PowerShell, l'interfaccia della riga di comando di Azure, o Transact-SQL senza restrizioni o particolari regole di sequenza a condizione che le dimensioni di calcolo del database di destinazione supportino le dimensioni massime del database di origine. La copia di un database in un livello di servizio diverso non è supportata nel portale di Azure.