Sviluppare un'applicazione Kubernetes per database SQL di Azure
Si applica a:![]() Database SQL di Azure
Database SQL di Azure
In questa esercitazione, ci sono informazioni su come sviluppare un'applicazione moderna usando Python, contenitori Docker, Kubernetes e database SQL di Azure.
Lo sviluppo di applicazioni moderne presenta diverse sfide. Dalla selezione di uno stack di front-end attraverso l'archiviazione e l'elaborazione dei dati da diversi standard concorrenti, attraverso la garanzia dei livelli più elevati di sicurezza e prestazioni, gli sviluppatori sono tenuti a garantire il dimensionamento delle applicazioni e prestazioni ottimali ed è supportabile su più piattaforme. Per questo ultimo requisito, la creazione di bundle dell'applicazione in tecnologie contenitore, ad esempio Docker e la distribuzione di più contenitori nella piattaforma Kubernetes, è ora necessaria nello sviluppo di applicazioni.
In questo esempio viene illustrato l'uso di Python, contenitori Docker e Kubernetes, tutti in esecuzione nella piattaforma Microsoft Azure. L'uso di Kubernetes significa anche avere la flessibilità di usare ambienti locali o anche altri cloud per una distribuzione uniforme e coerente dell'applicazione e consente distribuzioni multi-cloud per una resilienza ancora più elevata. Verranno usati anche database SQL di Microsoft Azure per un ambiente basato su servizi, scalabile, altamente resiliente e sicuro per l'archiviazione e l'elaborazione dei dati. In molti casi, infatti, altre applicazioni usano già spesso database SQL di Microsoft Azure e questa applicazione di esempio può essere utilizzata per usare e arricchire ulteriormente i dati.
Questo esempio è abbastanza completo nell'ambito, ma usa l'applicazione, il database e la distribuzione più semplici per illustrare il processo. È possibile adattare questo campione in modo che sia molto più solido, anche usando le tecnologie più recenti per i dati restituiti. È uno strumento di apprendimento utile per creare un modello per altre applicazioni.
Usare Python, contenitori Docker, Kubernetes e il database di esempio AdventureWorksLT in un esempio pratico
La società AdventureWorks (fittizia) usa un database che archivia i dati relativi a vendite e marketing, prodotti, clienti e produzione. Contiene inoltre visualizzazioni e stored procedure che aggiungono informazioni sui prodotti, ad esempio il nome del prodotto, la categoria, il prezzo e una breve descrizione.
Il team di sviluppo AdventureWorks vuole creare un modello di verifica (PoC) che restituisca dati da una vista nel database AdventureWorksLT e renderli disponibili come API REST. Usando questo PoC, il team di sviluppo creerà un'applicazione più scalabile e multi-cloud pronta per il team di vendita. Hanno selezionato la piattaforma Microsoft Azure per tutti gli aspetti della distribuzione. Il PoC usa gli elementi seguenti:
- Un'applicazione Python che usa il pacchetto Flask per la distribuzione Web headless.
- Contenitori Docker per l'isolamento del codice e dell'ambiente, archiviati in un registro privato in modo che l'intera azienda possa riutilizzare i contenitori dell'applicazione nei progetti futuri, risparmiando tempo e denaro.
- Kubernetes per semplificare la distribuzione e il dimensionamento ed evitare il blocco della piattaforma.
- Database SQL di Microsoft Azure per la selezione di dimensioni, prestazioni, dimensionamento, gestione automatica e backup, oltre all'archiviazione e all'elaborazione dei dati relazionali al livello di sicurezza più elevato.
In questo articolo, viene illustrato il processo di creazione dell'intero progetto del modello di verifica. I passaggi generali per la creazione dell'applicazione sono:
- Configurare i prerequisiti
- Creare l'applicazione
- Creare un contenitore Docker per distribuire l'applicazione e testare
- Creare un Registro del servizio Azure Container (ACS) e caricare il contenitore nel Registro ACS
- Creare l'ambiente del servizio Azure Kubernetes (AKS)
- Distribuire il contenitore dell'applicazione dal Registro ACS ad AKS
- Testare l'applicazione
- Eseguire la pulizia
Prerequisiti
In questo articolo sono disponibili diversi valori da sostituire. Assicurarsi di sostituire in modo coerente questi valori per ogni passaggio. È possibile aprire un editor di testo ed escludere questi valori per impostare i valori corretti mentre si usa il progetto del modello di verifica:
-
ReplaceWith_AzureSubscriptionName: sostituire questo valore con il nome della sottoscrizione di Azure. -
ReplaceWith_PoCResourceGroupName: sostituire questo valore con il nome del gruppo di risorse che si desidera creare. -
ReplaceWith_AzureSQLDBServerName: sostituire questo valore con il nome del server logico database SQL di Azure creato usando il portale di Azure. -
ReplaceWith_AzureSQLDBSQLServerLoginName: sostituire questo valore con il valore del nome utente di SQL Server creato nel portale di Azure. -
ReplaceWith_AzureSQLDBSQLServerLoginPassword: sostituire questo valore con il valore della password utente di SQL Server creata nel portale di Azure. -
ReplaceWith_AzureSQLDBDatabaseName: sostituire questo valore con il nome del database SQL di Azure creato usando il portale di Azure. -
ReplaceWith_AzureContainerRegistryName: sostituire questo valore con il nome del Registro Azure Container che si desidera creare. -
ReplaceWith_AzureKubernetesServiceName: sostituire questo valore con il nome del servizio Azure Kubernetes che si desidera creare.
Gli sviluppatori di AdventureWorks usano una combinazione di sistemi Windows, Linux e Apple per lo sviluppo, quindi usano Visual Studio Code come ambiente e Git per il controllo del codice sorgente, che eseguono entrambe multipiattaforma.
Per il PoC, il team richiede i prerequisiti seguenti:
Python, pip e pacchetti: il team di sviluppo sceglie il linguaggio di programmazione Python come standard per questa applicazione basata sul Web. Attualmente usano la versione 3.9, ma qualsiasi versione che supporta i pacchetti necessari per il PoC è accettabile.
- È possibile scaricare Python versione 3.9 da python.org.
Il team usa il pacchetto
pyodbcper l'accesso al database.- È possibile installare il pacchetto pyodbc con i comandi pip.
- Potrebbe essere necessario anche il software Microsoft ODBC Driver se non è già installato.
Il team usa il pacchetto
ConfigParserper controllare e impostare le variabili di configurazione.Il team usa il pacchetto Flask per un'interfaccia Web per l'applicazione.
Successivamente, il team ha installato lo strumento dell'interfaccia della riga di comando di Azure, facilmente identificato con la sintassi
az. Questo strumento multipiattaforma consente un approccio da riga di comando e con script al PoC, in modo da poter ripetere i passaggi man mano che apportano modifiche e miglioramenti.Con l'interfaccia della riga di comando di Azure configurata, il team accede alla sottoscrizione di Azure e imposta il nome della sottoscrizione usato per il PoC. Hanno quindi verificato che il server di database SQL di Azure siano accessibili alla sottoscrizione:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameUn gruppo di risorse Microsoft Azure è un contenitore logico in cui risiedono le risorse correlate per una soluzione di Azure. È in genere consigliabile aggiungere risorse che condividono lo stesso ciclo di vita allo stesso gruppo di risorse per poterle distribuire, aggiornare ed eliminare facilmente come gruppo. Viene specificato un percorso per il gruppo di risorse perché nel gruppo di risorse vengono archiviati i metadati delle risorse.
Puoi creare e gestire gruppi di risorse usando il portale di Azure o l'interfaccia della riga di comando di Azure. Possono anche essere usati per raggruppare le risorse correlate per un'applicazione e dividerle in gruppi per la produzione e la non produzione o qualsiasi altra struttura organizzativa preferita.

Nel frammento di codice seguente è possibile visualizzare il comando
azusato per creare un gruppo di risorse. Nel campione viene usata l'area di Azureeastus.az group create --name ReplaceWith_PoCResourceGroupName --location eastusIl team di sviluppo crea un database SQL di Azure con il database
AdventureWorksLTdi esempio installato usando un account di accesso autenticato SQL.AdventureWorks ha standardizzato la piattaforma del sistema di gestione di database relazionali Microsoft SQL Server e il team di sviluppo vuole usare un servizio gestito per il database anziché installarlo localmente. L'uso di database SQL di Azure consente a questo servizio gestito di essere completamente compatibile con il codice ovunque eseguano il motore di SQL Server: in locale, in un contenitore, in Linux o Windows o anche in un ambiente Internet delle cose (IoT).
Durante la creazione, ha usato il portale di gestione di Azure per impostare il firewall per l'applicazione nel computer di sviluppo locale e ha modificato l'impostazione predefinita visualizzata qui per abilitare Consenti tutti i servizi di Azure e ha recuperato anche le credenziali di connessione.
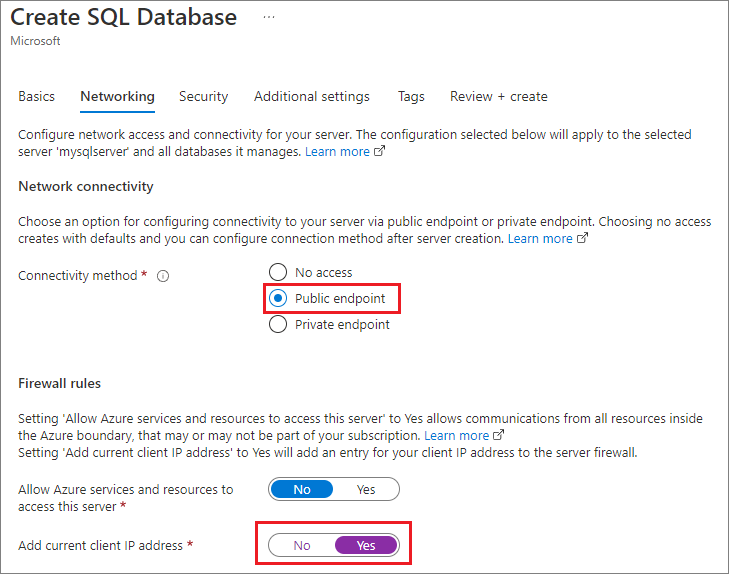
Con questo approccio, il database potrebbe essere accessibile in un'altra area o anche in una sottoscrizione diversa.
Il team ha configurato un account di accesso autenticato SQL per il test, ma revisionerà questa decisione in una verifica della sicurezza.
Il team ha usato il database di esempio
AdventureWorksLTper il PoC usando lo stesso gruppo di risorse PoC. Al termine di questa esercitazione verranno pulite tutte le risorse in questo nuovo gruppo di risorse PoC.È possibile distribuire il database SQL di Azure usando il portale di Azure. Quando si crea il database SQL di Azure, nella scheda Impostazioni aggiuntive selezionare Esempio per l'opzione Usa dati esistenti.
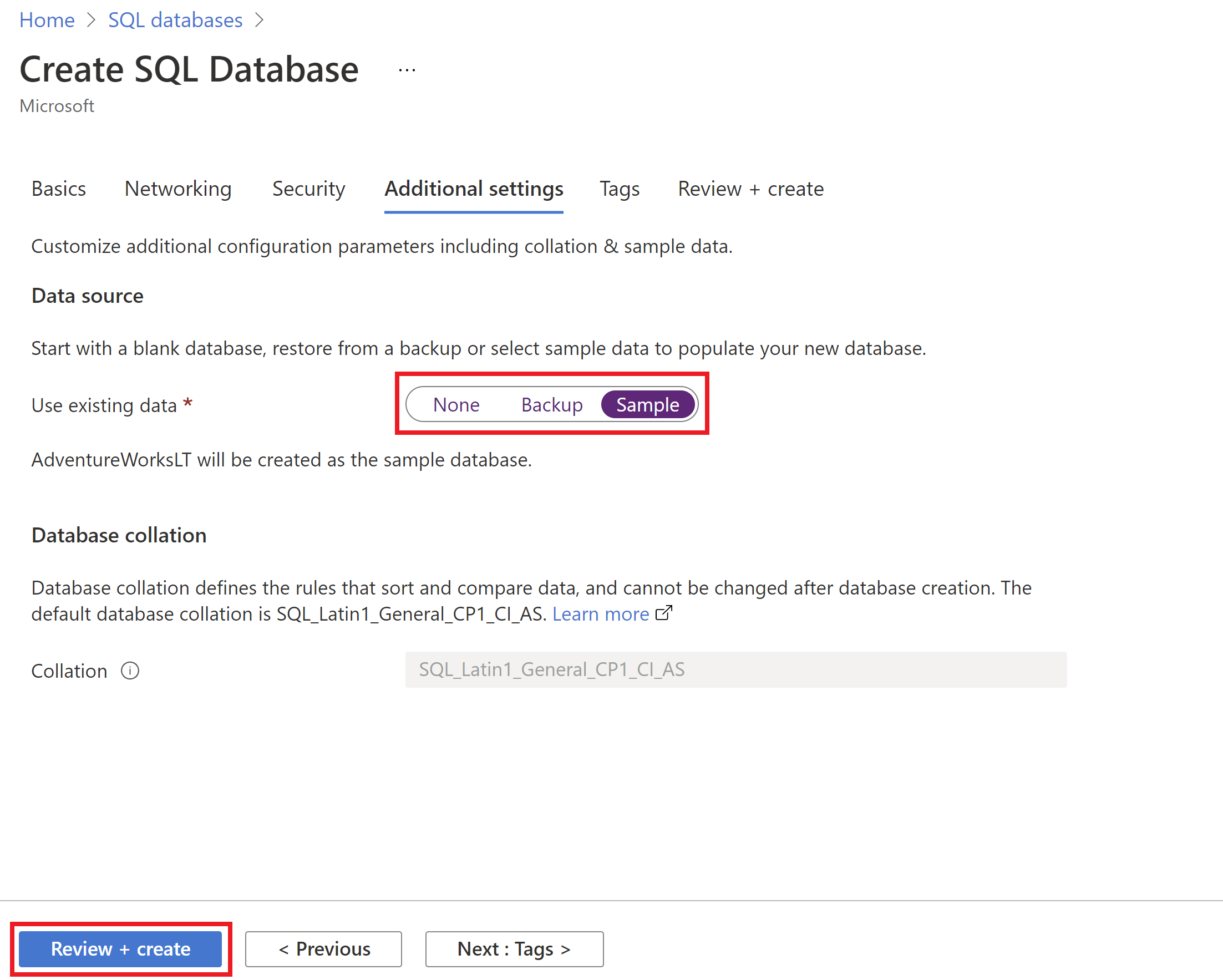
Infine, nella scheda Tag del nuovo database SQL di Azure il team di sviluppo ha fornito i metadati dei tag per questa risorsa di Azure, ad esempio Proprietario o ServiceClass o WorkloadName.

Creare l'applicazione
Successivamente, il team di sviluppo ha creato una semplice applicazione Python che apre una connessione a database SQL di Azure e restituisce un elenco di prodotti. Questo codice verrà sostituito con funzioni più complesse e potrebbe includere anche più di un'applicazione distribuita nei pod Kubernetes di produzione per un approccio solido, basato su manifesto, alle soluzioni applicative.
Il team ha creato un semplice file di testo denominato
.envper contenere le variabili per le connessioni server e altre informazioni. Usando la libreriapython-dotenvè quindi possibile separare le variabili dal codice Python. Si tratta di un approccio comune per mantenere i segreti e altre informazioni dal codice stesso.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseNameAttenzione
Per maggiore chiarezza e semplicità, questa applicazione usa un file di configurazione letto da Python. Poiché il codice verrà distribuito con il contenitore, le informazioni di connessione potrebbero essere in grado di derivare dal contenuto. È consigliabile considerare attentamente i vari metodi di utilizzo di sicurezza, connessioni e segreti e determinare il livello e il meccanismo migliori da usare per l'applicazione. Scegliere sempre il livello di sicurezza più elevato e anche più livelli per garantire la sicurezza dell'applicazione. Sono disponibili più opzioni per l'uso di informazioni segrete, ad esempio stringhe di connessione e simili, e l'elenco seguente mostra alcune di queste opzioni.
Per altre informazioni, vedere sicurezza di Database SQL di Azure.
- Un altro metodo per usare i segreti in Python consiste nell'usare la libreria python-secrets.
- Revisionare la sicurezza e i segreti di Docker.
- Revisionare i segreti Kubernetes.
- È anche possibile ottenere altre informazioni sull'autenticazione di Microsoft Entra (in precedenza Azure Active Directory).
Il team ha quindi scritto l'applicazione PoC e l'ha chiamata
app.py.Lo script seguente esegue questi passaggi:
- Configurare le librerie per le interfacce Web di base e di configurazione.
- Caricare le variabili dal file
.env. - Creare l'applicazione Flask-RESTful.
- Ottenere informazioni di connessione per database SQL di Azure usando i valori del file
config.ini. - Creare una connessione per database SQL di Azure usando i valori del file
config.ini. - Connettere al database SQL di Azure tramite il pacchetto
pyodbc. - Creare query SQL da eseguire sul database.
- Creare la classe che verrà usata per restituire i dati dall'API.
- Impostare l'endpoint API sulla classe
Products. - Infine, avviare l'app sulla porta Flask 5000 predefinita.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://learn.microsoft.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)Hanno verificato che l'applicazione venga eseguita localmente e restituisca una pagina a
http://localhost:5000/products.
Importante
Quando si compilano applicazioni di produzione, non usare l'account amministratore per accedere al database. Per altre informazioni, vedere altre informazioni su come configurare un account per l'applicazione. Il codice in questo articolo è semplificato in modo da poter iniziare rapidamente a usare le applicazioni con Python e Kubernetes in Azure.
In modo più realistico, è possibile usare un utente del database indipendente con autorizzazioni di sola lettura oppure un utente di database di accesso o di database indipendente connesso a un'identità gestita assegnata dall'utente con autorizzazioni di sola lettura.
Per altre informazioni, vedere un esempio completo su come creare UN'API con Python e database SQL di Azure.

Distribuire l'applicazione in un contenitore Docker
Un contenitore è uno spazio riservato e protetto in un sistema di elaborazione che fornisce isolamento e incapsulamento. Per creare un contenitore, usare un file manifesto, che è semplicemente un file di testo che descrive i file binari e il codice che si desidera contenere. Usando un runtime di contenitori, ad esempio Docker, è quindi possibile creare un'immagine binaria con tutti i file da eseguire e fare riferimento. Da qui è possibile eseguire l'immagine binaria, denominata contenitore, a cui è possibile fare riferimento come se fosse un sistema di elaborazione completo. È un modo più ridotto e semplice per astrarre i runtime e l'ambiente dell'applicazione rispetto all'uso di una macchina virtuale completa. Per altre informazioni, vedere Contenitori e Docker.
Il team ha iniziato con un DockerFile (manifesto) che esegue i layer degli elementi di ciò che il team vuole usare. Iniziano con un'immagine Python di base che include già le librerie pyodbc installate e quindi eseguono tutti i comandi necessari per contenere il programma e il file di configurazione nel passaggio precedente.
Il Dockerfile seguente prevede i passaggi seguenti:
- Iniziare con un file binario contenitore che ha già Python e
pyodbcinstallato. - Creare una directory di lavoro per l'applicazione.
- Copiare tutto il codice dalla directory corrente in
WORKDIR. - Installare le librerie necessarie.
- Dopo l'avvio del contenitore, eseguire l'applicazione e aprire tutte le porte TCP/IP.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
Con tale file sul posto, il team è stato eliminato in un prompt dei comandi nella directory di codifica ed è stato eseguito il codice seguente per creare l'immagine binaria dal manifesto e quindi un altro comando per avviare il contenitore:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
Ancora una volta, il team testa il collegamento http://localhost:5000/products per assicurarsi che il contenitore possa accedere al database e che visualizzi la restituzione seguente:

Distribuire l'immagine in un registro Docker
Il contenitore funziona ora, ma è disponibile solo nel computer dello sviluppatore. Il team di sviluppo vuole rendere disponibile l'immagine dell'applicazione al resto dell'azienda e quindi a Kubernetes per la distribuzione di produzione.
L'area di archiviazione per le immagini del contenitore è denominata repository e può essere disponibile sia repository pubblici che privati per immagini contenitore. AdventureWorks usa infatti un'immagine pubblica per l'ambiente Python nel dockerfile.
Il team vuole controllare l'accesso all'immagine e, invece di inserirlo sul Web, decide di ospitarlo autonomamente, ma in Microsoft Azure in cui ha il controllo completo sulla sicurezza e l'accesso. Altre informazioni su Microsoft Registro Azure Container sono disponibili qui.
Tornando alla riga di comando, il team di sviluppo usa az CLI per aggiungere un servizio registro contenitori, abilitare un account di amministrazione, impostarlo su pull anonimo durante la fase di test e impostare un contesto di accesso sul registro:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
Questo contesto verrà usato nei passaggi successivi.
Contrassegnare l'immagine Docker locale per prepararla per il caricamento
Il passaggio successivo consiste nell'inviare l'immagine del contenitore dell'applicazione locale al servizio Registro Azure Container (ACR) in modo che sia disponibile nel cloud.
- Nello script di esempio seguente, il team usa i comandi Docker per elencare le immagini nel computer.
- Usano l'utilità
az CLIper elencare le immagini nel servizio ACR. - Usano il comando Docker per contrassegnare l'immagine con il nome di destinazione di ACR creato nel passaggio precedente e per impostare un numero di versione per DevOps appropriato.
- Infine, elencano nuovamente le informazioni sull'immagine locale per assicurarsi che il tag venga applicato correttamente.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
Con il codice scritto e testato, il Dockerfile, l'immagine e il contenitore vengono eseguiti e testati, il servizio ACR configurato e tutti i tag applicati, il team può caricare l'immagine nel servizio ACR.
Usano il comando Docker push per inviare il file e quindi l'utilità az CLI per assicurarsi che l'immagine sia stata caricata:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Eseguire la distribuzione in Kubernetes
Il team potrebbe semplicemente eseguire contenitori e distribuire l'applicazione in ambienti locali e nel cloud. Tuttavia, vogliono aggiungere più copie dell'applicazione per il dimensionamento e la disponibilità, aggiungere altri contenitori che eseguono attività diverse e aggiungere monitoraggio e strumentazione all'intera soluzione.
Per raggruppare i contenitori in una soluzione completa, il team ha deciso di usare Kubernetes. Kubernetes viene eseguito in locale e in tutte le principali piattaforme cloud. Microsoft Azure ha un ambiente gestito completo per Kubernetes, denominato servizio Azure Kubernetes (AKS). Ulteriori informazioni sul AKS con l'Introduzione a Kubernetes nel percorso di training di Azure.
Usando l'utilità az CLI, il team aggiunge AKS allo stesso gruppo di risorse creato in precedenza. Con un singolo comando az, il team di sviluppo esegue i passaggi seguenti:
- Aggiungere due nodi o ambienti di calcolo per la resilienza nella fase di test
- Generare automaticamente chiavi SSH per l'accesso all'ambiente
- Collegare il servizio ACR creato nei passaggi precedenti in modo che il cluster di AKS possa individuare le immagini da usare per la distribuzione
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
Kubernetes usa una utilità da riga di comando per accedere e controllare un cluster denominato kubectl. Il team usa l'utilità az CLI per scaricare lo strumento kubectl e installarlo:
az aks install-cli
Poiché al momento hanno una connessione ad AKS, possono chiedere di inviare le chiavi SSH per la connessione da usare quando eseguono l'utilità kubectl:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
Queste chiavi vengono archiviate in un file denominato .config nella directory dell'utente. Con il contesto di sicurezza impostato, il team usa kubectl get nodes per visualizzare i nodi nel cluster:
kubectl get nodes
Il team usa ora lo strumento az CLI per elencare le immagini nel servizio ACR:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
Ora possono compilare il manifesto usato da Kubernetes per controllare la distribuzione. Si tratta di un file di testo archiviato in un formato yaml. Ecco il testo con annotazioni nel file flask2sql.yaml:
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
Con il file flask2sql.yaml definito, il team può distribuire l'applicazione nel cluster di AKS in esecuzione. Questa operazione viene eseguita con il comando kubectl apply, che come si ricorda ha ancora un contesto di protezione per il cluster. Il comando kubectl get service viene quindi inviato per controllare il cluster durante la compilazione.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
Dopo alcuni istanti, il comando “watch” restituirà un indirizzo IP esterno. A questo punto, il team preme CTRL-C per interrompere il comando watch e registra l'indirizzo IP esterno del servizio di bilanciamento del carico.
Testare l'applicazione
Usando l'indirizzo IP (endpoint) ottenuto nell'ultimo passaggio, il team verifica per garantire lo stesso output dell'applicazione locale e del contenitore Docker:
Eseguire la pulizia
Con l'applicazione creata, modificata, documentata e testata, il team può ora rimuovere l'applicazione. Mantenendo tutti gli elementi in un singolo gruppo di risorse in Microsoft Azure, è una semplice questione di eliminare il gruppo di risorse PoC usando l'utilità az CLI:
az group delete -n ReplaceWith_PoCResourceGroupName -y
Nota
Se è stato creato il database SQL di Azure in un altro gruppo di risorse e non è più necessario, è possibile usare il portale di Azure per eliminarlo.
Il membro del team che guida il progetto PoC usa Microsoft Windows come workstation e vuole conservare il file dei segreti da Kubernetes, ma anche rimuoverlo dal sistema come posizione attiva. È possibile semplicemente copiare il file in un file di testo config.old, quindi eliminarlo:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config