Informazioni sui linguaggi dei volumi in Azure NetApp Files
Il linguaggio del volume (simile alle impostazioni locali di sistema nei sistemi operativi client) in un volume di Azure NetApp Files controlla le lingue e i set di caratteri supportati quando si usano protocolli NFS e SMB. Azure NetApp Files usa un linguaggio di volume predefinito C.UTF-8, che fornisce la codifica UTF-8 conforme a POSIX per i set di caratteri. La lingua C.UTF-8 supporta in modo nativo i caratteri con una dimensione di 0-3 byte, che include la maggior parte delle lingue del mondo sul piano multilingue di base (BMP) (incluso giapponese, tedesco e la maggior parte dell'ebraico e cirillico). Per altre informazioni su BMP, vedere Unicode.
I caratteri al di fuori del BMP talvolta superano le dimensioni a 3 byte supportate da Azure NetApp Files. È quindi necessario usare la logica della coppia di surrogati, in cui più set di byte di caratteri vengono combinati per formare nuovi caratteri. I simboli emoji, ad esempio, rientrano in questa categoria e sono supportati in Azure NetApp Files negli scenari in cui UTF-8 non viene applicato: ad esempio i client Windows che usano la codifica UTF-16 o NFSv3 che non applica UTF-8. NFSv4.x applica UTF-8, ovvero i caratteri della coppia di surrogati non vengono visualizzati correttamente quando si usa NFSv4.x.
La codifica non standard, ad esempio MAIUSC-JIS e caratteri CJK meno comuni, non viene visualizzata correttamente quando viene applicato UTF-8 in Azure NetApp Files.
Suggerimento
È consigliabile inviare e ricevere testo con UTF-8 per evitare situazioni in cui i caratteri non possono essere tradotti correttamente, causando scenari di creazione/ridenominazione o copia di file.
Le impostazioni della lingua del volume attualmente non possono essere modificate in Azure NetApp Files. Per altre informazioni, vedere Comportamenti dei protocolli con set di caratteri speciali.
Per le procedure consigliate, vedere Procedure consigliate per i set di caratteri.
Codifica dei caratteri nei volumi NFS e SMB di Azure NetApp Files
In un ambiente di condivisione file di Azure NetApp Files i nomi di file e cartelle sono rappresentati da una serie di caratteri che gli utenti finali leggono e interpretano. Il modo in cui questi caratteri vengono visualizzati dipende dal modo in cui il client invia e riceve la codifica di tali caratteri. Ad esempio, se un client invia la codifica ASCII (American Standard Code for Information Interchange) legacy al volume di Azure NetApp Files durante l'accesso, è limitato alla visualizzazione solo di caratteri supportati nel formato ASCII.
Ad esempio, il carattere giapponese per i dati è 資. Poiché questo carattere non può essere rappresentato in ASCII, un client che usa la codifica ASCII mostra "?" invece di 資.
ASCII supporta solo 95 caratteri stampabili, principalmente quelli presenti nella lingua inglese. Ognuno di questi caratteri usa 1 byte, che viene inserito nella lunghezza totale del percorso del file in un volume di Azure NetApp Files. Ciò limita l'internazionalizzazione dei set di dati, poiché i nomi di file possono avere un'ampia gamma di caratteri non riconosciuti da ASCII, dal giapponese al cirillico all'emoji. Uno standard internazionale (ISO/IEC 8859) ha tentato di supportare più caratteri internazionali, ma ha anche avuto le sue limitazioni. La maggior parte dei client moderni invia e riceve caratteri usando una forma di Unicode.
Unicode
In seguito alle limitazioni delle codifiche ASCII e ISO/IEC 8859, lo standard Unicode è stato stabilito in modo che chiunque possa visualizzare la lingua dell'area principale dai propri dispositivi.
- Unicode supporta più di un milione di set di caratteri aumentando sia il numero di byte per carattere consentito (fino a 4 byte) sia il numero totale di byte consentiti in un percorso di file anziché le codifiche meno recenti, ad esempio ASCII.
- Unicode supporta la compatibilità con le versioni precedenti riservando i primi 128 caratteri per ASCII, assicurando allo stesso tempo che i primi 256 punti di codice siano identici agli standard ISO/IEC 8859.
- Nello standard Unicode, i set di caratteri vengono suddivisi in piani. Un piano è un gruppo continuo di 65.536 punti di codice. In totale, ci sono 17 piani (0-16) nello standard Unicode. Il limite è 17 a causa delle limitazioni di UTF-16.
- Il piano 0 è il piano multilingue di base (BMP). Questo piano contiene i caratteri più usati in più lingue.
- Dei 17 piani, solo cinque hanno attualmente assegnato set di caratteri a partire dalla versione Unicode 15.1.
- I piani 1-17 sono noti come piani multilingue supplementari (SMP) e contengono set di caratteri meno usati, ad esempio sistemi di scrittura antichi come cuneiformi e glifi di gerarchia, nonché speciali caratteri cinesi/giapponesi/coreani (CJK).
- Per i metodi per visualizzare le lunghezze dei caratteri e le dimensioni del percorso e per controllare la codifica inviata a un sistema, vedere Conversione di file in codifiche diverse.
Unicode usa Il formato trasformazione Unicode come standard, con UTF-8 e UTF-16 come due formati principali.
Piani Unicode
Unicode sfrutta 17 piani di 65.536 caratteri (256 punti di codice moltiplicati per 256 caselle nel piano), con Piano 0 come piano multilingue di base (BMP). Questo piano contiene i caratteri più usati in più lingue. Poiché le lingue e i set di caratteri del mondo superano i 65536 caratteri, sono necessari più piani per supportare set di caratteri meno usati.
Ad esempio, il Piano 1 (I Piani Multilingue Supplementari (SMP) include script storici come cuneiform e gerarchici egiziani, nonché alcuni Osage, Warang Citi, Adlam, Wancho e Toto. Il piano 1 include anche alcuni simboli e caratteri emoticon .
Piano 2– il piano Ideografico supplementare (SIP), contiene Ideogrammi unificati cinesi/giapponesi/coreani (CJK). I caratteri nei piani 1 e 2 in genere sono di 4 byte.
Ad esempio:
- L'emoticon 😃"grinning face with big eyes" in plane 1 è di 4 byte.
- La gerarchia egiziana "𓀀" nel piano 1 è di 4 byte.
- Il carattere osage "𐒸" nel piano 1 è di 4 byte.
- Il carattere CJK "𫝁" nel piano 2 è di 4 byte.
Poiché questi caratteri sono tutti di >3 byte di dimensione, richiedono il corretto funzionamento delle coppie di surrogati. Azure NetApp Files supporta in modo nativo coppie di surrogati, ma la visualizzazione dei caratteri varia a seconda del protocollo in uso, delle impostazioni locali del client e delle impostazioni dell'applicazione di accesso client remoto.
UTF-8
UTF-8 usa la codifica a 8 bit e può avere fino a 1.112.064 punti di codice (o caratteri). UTF-8 è la codifica standard in tutti i linguaggi nei sistemi operativi basati su Linux. Poiché UTF-8 usa la codifica a 8 bit, il numero massimo di interi senza segno possibile è 255 (2^8 - 1), che è anche la lunghezza massima del nome file per tale codifica. UTF-8 viene usato su oltre il 98% delle pagine su Internet, rendendolo di gran lunga lo standard di codifica più adottato. Il Web Hypertext Application Technology Working Group (WHATWG) considera UTF-8 "la codifica obbligatoria per tutti i [testo]" e che per motivi di sicurezza le applicazioni browser non devono usare UTF-16.
I caratteri in formato UTF-8 usano ognuno da 1 a 4 byte, ma quasi tutti i caratteri in tutte le lingue usano tra 1 e 3 byte. Ad esempio:
- La lettera dell'alfabeto latino "A" usa 1 byte. (Uno dei 128 caratteri ASCII riservati)
- Un simbolo di copyright "©" utilizza 2 byte.
- Il carattere "ä" usa 2 byte. (1 byte per "a" + 1 byte per l'umlaut)
- Il simbolo Kanji giapponese per i dati (資) usa 3 byte.
- Un'emoji del viso scaltro (😃) usa 4 byte.
Le impostazioni locali del linguaggio possono usare uno standard UTF-8 (C.UTF-8) o un formato più specifico dell'area, ad esempio en_US. UTF-8, ja. UTF-8 e così via. È consigliabile usare la codifica UTF-8 per i client Linux quando si accede ad Azure NetApp Files quando possibile. A partire da OS X, i client macOS usano anche UTF-8 per la codifica predefinita e non devono essere modificati.
I client Windows usano UTF-16. Nella maggior parte dei casi, questa impostazione deve essere lasciata come predefinita per le impostazioni locali del sistema operativo, ma i client più recenti offrono il supporto beta per i caratteri UTF-8 tramite una casella di controllo. I client terminal in Windows possono anche essere modificati per usare UTF-8 in PowerShell o CMD in base alle esigenze. Per altre informazioni, vedere Comportamenti dei protocolli duali con set di caratteri speciali.
UTF-16
UTF-16 usa la codifica a 16 bit ed è in grado di codificare tutti i 1.112.064 punti di codice di Unicode. La codifica per UTF-16 può usare una o due unità di codice a 16 bit, ognuna di 2 byte. Tutti i caratteri in UTF-16 usano dimensioni di 2 o 4 byte. I caratteri in UTF-16 che usano 4 byte sfruttano coppie surrogate, che combinano due caratteri separati a 2 byte per creare un nuovo carattere. Questi caratteri supplementari non rientrano nel piano BMP standard e in uno degli altri piani multilingue.
UTF-16 viene usato nei sistemi operativi Windows e nelle API, Java e JavaScript. Poiché non supporta la compatibilità con le versioni precedenti con i formati ASCII, non ha mai guadagnato popolarità sul Web. UTF-16 costituisce solo circa lo 0,002% di tutte le pagine su Internet. Il Web Hypertext Application Technology Working Group (WHATWG) considera UTF-8 "la codifica obbligatoria per tutto il testo" e consiglia alle applicazioni di non usare UTF-16 per la sicurezza del browser.
Azure NetApp Files supporta la maggior parte dei caratteri UTF-16, incluse le coppie di surrogati. Nei casi in cui il carattere non è supportato, i client Windows segnalano un errore "nome file specificato non è valido o troppo lungo".
Gestione dei set di caratteri su client remoti
Le connessioni remote ai client che montano volumi di Azure NetApp Files (ad esempio le connessioni SSH ai client Linux per accedere ai montaggi NFS) possono essere configurate per inviare e ricevere codifiche specifiche del linguaggio del volume. La codifica della lingua inviata al client tramite l'utilità di connessione remota controlla come vengono creati e visualizzati i set di caratteri. Di conseguenza, una connessione remota che usa una codifica della lingua diversa rispetto a un'altra connessione remota (ad esempio due diverse finestre PuTTY) può visualizzare risultati diversi per i caratteri quando si elencano i nomi di file e cartelle nel volume di Azure NetApp Files. Nella maggior parte dei casi, questo non creerà discrepanze (ad esempio per i caratteri latini/inglesi), ma nei casi di caratteri speciali, ad esempio emoji, i risultati possono variare.
Ad esempio, l'uso di una codifica UTF-8 per la connessione remota mostra risultati prevedibili per i caratteri nei volumi di Azure NetApp Files poiché C.UTF-8 è il linguaggio del volume. Il carattere giapponese per "data" (資) viene visualizzato in modo diverso a seconda della codifica inviata dal terminale.
Codifica dei caratteri in PuTTY
Quando una finestra PuTTY usa UTF-8 (disponibile nelle impostazioni di conversione di Windows), il carattere viene rappresentato correttamente per un volume montato NFSv3 in Azure NetApp Files:

Se la finestra PuTTY usa una codifica diversa, ad esempio ISO-8859-1:1998 (Latin-1, West Europe), lo stesso carattere viene visualizzato in modo diverso anche se il nome file è lo stesso.

PuTTY, per impostazione predefinita, non contiene codifiche CJK. Sono disponibili patch per aggiungere tali set di linguaggio a PuTTY.
Codifiche di caratteri in Bastion
Microsoft Azure consiglia di usare Bastion per la connettività remota alle macchine virtuali in Azure. Quando si usa Bastion, la codifica del linguaggio inviata e ricevuta non viene esposta nella configurazione, ma sfrutta la codifica UTF-8 standard. Di conseguenza, la maggior parte dei set di caratteri visualizzati in PuTTY con UTF-8 dovrebbe essere visibile anche in Bastion, a condizione che i set di caratteri siano supportati nel protocollo in uso.

Suggerimento
È possibile usare altri terminali SSH, ad esempio TeraTerm. TeraTerm offre una gamma più ampia di set di caratteri supportati per impostazione predefinita, incluse le codifiche CJK e le codifiche non standard, ad esempio SHIFT-JIS.
Comportamenti del protocollo con set di caratteri speciali
I volumi di Azure NetApp Files usano la codifica UTF-8 e supportano in modo nativo i caratteri che non superano 3 byte. Tutti i caratteri nel set ASCII e UTF-8 vengono visualizzati correttamente perché rientrano nell'intervallo da 1 a 3 byte. Ad esempio:
- Il carattere alfabeto latino "A" usa 1 byte (uno dei 128 caratteri ASCII riservati).
- Un simbolo © di copyright utilizza 2 byte.
- Il carattere "ä" usa 2 byte (1 byte per "a" e 1 byte per l'umlaut).
- Il simbolo Kanji giapponese per i dati (資) usa 3 byte.
Azure NetApp Files supporta anche alcuni caratteri che superano i 3 byte tramite la logica della coppia di surrogati (ad esempio emoji), purché la codifica client e la versione del protocollo li supporti. Per altre informazioni sui comportamenti dei protocolli, vedere:
Comportamenti SMB
Nei volumi SMB, Azure NetApp Files crea e mantiene due nomi per i file o le directory in qualsiasi directory che abbia accesso da un client SMB: il nome lungo originale e un nome in formato 8.3.
Nomi di file in SMB con Azure NetApp Files
Quando i nomi di file o directory superano i byte di caratteri consentiti o usano caratteri non supportati, Azure NetApp Files genera un nome di formato 8.3 come indicato di seguito:
- Tronca il nome originale del file o della directory.
- Aggiunge una tilde (~) e un numero (1-5) ai nomi di file o directory che non sono più univoci dopo il troncamento. Se sono presenti più di cinque file con nomi non univoci, Azure NetApp Files crea un nome univoco senza alcuna relazione con il nome originale. Per i file, Azure NetApp Files tronca l'estensione del nome file a tre caratteri.
Ad esempio, se un client NFS crea un file denominato specifications.html, Azure NetApp Files crea il nome specif~1.htm del file seguendo il formato 8.3. Se questo nome esiste già, Azure NetApp Files usa un numero diverso alla fine del nome del file. Ad esempio, se un client NFS crea un altro file denominato specifications\_new.html, il formato 8.3 di specifications\_new.html è specif~2.htm.
Carattere speciale in SMB con Azure NetApp Files
Quando si usa SMB con volumi di Azure NetApp Files, i caratteri che superano i 3 byte usati nei nomi di file e cartelle (incluse le emoticon) sono consentiti a causa del supporto di coppie di surrogati. Di seguito è riportato ciò che Esplora risorse visualizza per i caratteri all'esterno del BMP in una cartella creata da un client Windows quando si usa l'inglese con la codifica UTF-16 predefinita.
Nota
Il tipo di carattere predefinito in Esplora risorse è Segoe UI. Le modifiche apportate ai tipi di carattere possono influire sul modo in cui alcuni caratteri vengono visualizzati nei client.

La modalità di visualizzazione dei caratteri nel client dipende dal tipo di carattere di sistema e dalle impostazioni locali e della lingua. In generale, i caratteri che rientrano nel BMP sono supportati in tutti i protocolli, indipendentemente dal fatto che la codifica sia UTF-8 o UTF-16.
Quando si usa CMD o PowerShell, la visualizzazione del set di caratteri dipende dalle impostazioni del tipo di carattere. Queste utilità hanno scelte limitate per i tipi di carattere per impostazione predefinita. CMD usa Consolas come tipo di carattere predefinito.
I nomi di file potrebbero non essere visualizzati come previsto a seconda del tipo di carattere usato perché alcune console non supportano in modo nativo l'interfaccia utente di Segoe o altri tipi di carattere che eseguono correttamente il rendering di caratteri speciali.
Questo problema può essere risolto nei client Windows usando PowerShell ISE, che offre un supporto più affidabile per i tipi di carattere. Ad esempio, impostando PowerShell ISE su Segoe UI vengono visualizzati correttamente i nomi di file con caratteri supportati.

PowerShell ISE, tuttavia, è progettato per la creazione di script, anziché per la gestione delle condivisioni. Le versioni più recenti di Windows offrono Terminale Windows, che consente di controllare i tipi di carattere e i valori di codifica.
Nota
Usare il chcp comando per visualizzare la codifica per il terminale. Per un elenco completo delle tabelle codici, vedere Identificatori della tabella codici.

Se il volume è abilitato per il protocollo duale (sia NFS che SMB), è possibile osservare comportamenti diversi. Per altre informazioni, vedere Comportamenti a doppio protocollo con set di caratteri speciali.
Comportamenti NFS
Il modo in cui NFS visualizza caratteri speciali dipende dalla versione di NFS usata, dalle impostazioni locali del client, dai tipi di carattere installati e dalle impostazioni del client di connessione remota in uso. Ad esempio, l'uso di Bastion per accedere a un client Ubuntu gestisce i caratteri viene visualizzato in modo diverso rispetto a un client PuTTY impostato su impostazioni locali diverse nella stessa macchina virtuale. Gli esempi NFS seguenti si basano su queste impostazioni locali per la macchina virtuale Ubuntu:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
Comportamento di NFSv3
NFSv3 non applica la codifica UTF ai file e alle cartelle. Nella maggior parte dei casi, i set di caratteri speciali non devono avere problemi. Tuttavia, il client di connessione usato può influire sulla modalità di invio e ricezione dei caratteri. Ad esempio, l'uso di caratteri Unicode all'esterno di BMP per un nome di cartella nel client di connessione di Azure Bastion può comportare un comportamento imprevisto a causa del funzionamento della codifica client.
Nello screenshot seguente Bastion non è in grado di copiare e incollare i valori al prompt dell'interfaccia della riga di comando dall'esterno del browser quando si assegna un nome a una directory su NFSv3. Quando si tenta di copiare e incollare il valore di NFSv3Bastion𓀀𫝁😃𐒸, i caratteri speciali vengono visualizzati tra virgolette nell'input.

Il comando copy-paste è consentito su NFSv3, ma i caratteri vengono creati come valori numerici, che influiscono sulla visualizzazione:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Questa visualizzazione è dovuta alla codifica usata da Bastion per l'invio di valori di testo durante la copia e incolla.
Quando si usa PuTTY per creare una cartella con gli stessi caratteri su NFSv3, il nome della cartella è diverso da quello in Bastion rispetto a quando Bastion è stato usato per crearlo. L'emoticon viene visualizzato come previsto (a causa dei tipi di carattere e delle impostazioni locali installati), ma gli altri caratteri (ad esempio osage "𐒸") non lo fanno.

Da una finestra PuTTY i caratteri vengono visualizzati correttamente:

Comportamento di NFSv4.x
NFSv4.x applica la codifica UTF-8 nei nomi di file e cartelle in base alle specifiche di internazionalizzazione RFC-8881.
Di conseguenza, se viene inviato un carattere speciale con codifica non UTF-8, NFSv4.x potrebbe non consentire il valore.
In alcuni casi, un comando può essere consentito usando un carattere esterno al piano BMP (Basic Multilingual Plane), ma potrebbe non visualizzare il valore dopo la creazione.
Ad esempio, l'emissione mkdir con un nome di cartella, inclusi i caratteri "𓀀𫝁😃𐒸" (caratteri nei piani multilingue supplementari (SMP) e il piano Ideografico supplementare (SIP) sembra avere esito positivo in NFSv4.x. La cartella non sarà visibile quando si esegue il ls comando .
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
La cartella esiste nel volume. Il passaggio a tale nome di directory nascosta funziona dal client PuTTY e un file può essere creato all'interno di tale directory.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Un comando stat da PuTTY conferma anche che la cartella esiste:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Anche se la cartella è confermata, i comandi con caratteri jolly non funzionano, perché il client non può ufficialmente "vedere" la cartella nella visualizzazione.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 invia un errore al client quando rileva un carattere che non si basa sulla codifica UTF-8.
Ad esempio, quando si usa Bastion per tentare di accedere alla stessa directory creata usando PuTTY su NFSv4.1, questo è il risultato:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL è trattato in RFC-8881.
Poiché è possibile accedere alla cartella da PuTTY (a causa della codifica inviata e ricevuta), può essere copiata se il nome è specificato. Dopo aver copiato tale cartella dal volume NFSv4.1 di Azure NetApp Files al volume NFSv3 di Azure NetApp Files, il nome della cartella viene visualizzato:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Lo stesso NFS4ERR\_INVAL errore può essere visualizzato se viene tentata una conversione di file (usando 'iconv'') in un formato non UTF-8, ad esempio Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Per altre informazioni, vedere Conversione di file in codifiche diverse.
Comportamenti dei protocolli duali
Azure NetApp Files consente l'accesso ai volumi sia da NFS che da SMB tramite accesso a doppio protocollo. A causa delle vaste differenze nella codifica del linguaggio usata da NFS (UTF-8) e SMB (UTF-16), set di caratteri, nomi di file e cartelle e lunghezze di percorso possono avere comportamenti molto diversi tra i protocolli.
Visualizzazione di file e cartelle creati da NFS da SMB
Quando Azure NetApp Files viene usato per l'accesso a doppio protocollo (SMB e NFS), è possibile usare un set di caratteri non supportato da UTF-16 in un nome file creato con UTF-8 tramite NFS. In questi scenari, quando SMB accede a un file con caratteri non supportati, il nome viene troncato in SMB usando la convenzione di nome file breve 8.3.
File creati da NFSv3 e comportamenti SMB con set di caratteri
NFSv3 non applica la codifica UTF-8. I caratteri che usano codifiche del linguaggio non standard (ad esempio Shift-JIS) funzionano con Azure NetApp Files quando si usa NFSv3.
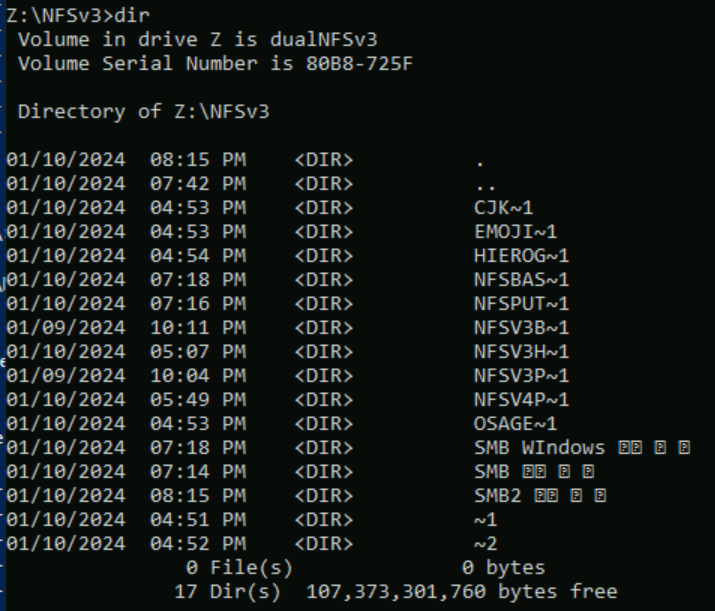
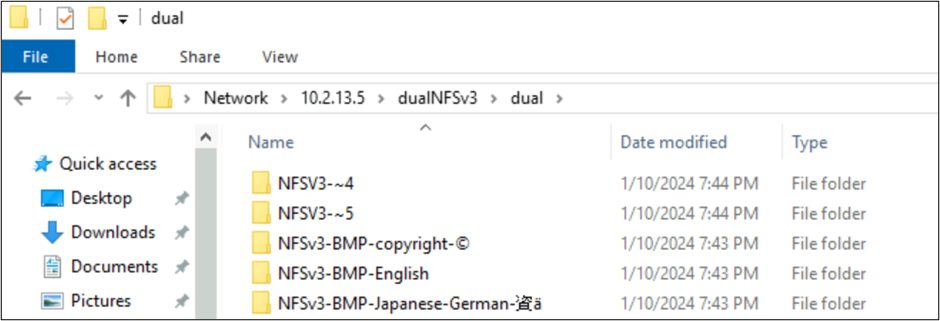
Nell'esempio seguente è stata creata una serie di nomi di cartelle che usano set di caratteri diversi da vari piani in Unicode in un volume di Azure NetApp Files usando NFSv3. Quando vengono visualizzati da NFSv3, questi vengono visualizzati correttamente.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Da Windows SMB, le cartelle con caratteri trovati nel BMP vengono visualizzate correttamente, ma i caratteri al di fuori del piano vengono visualizzati con il formato del nome 8.3 a causa della conversione UTF-8/UTF-16 non compatibile per tali caratteri.
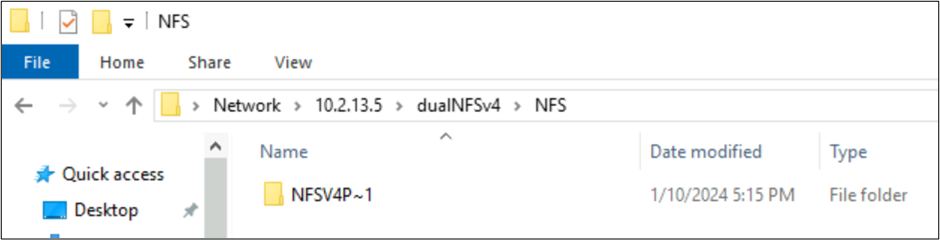
File creati da NFSv4.1 e comportamenti SMB con set di caratteri
Negli esempi precedenti è stata creata una cartella denominata NFSv4 Putty 𓀀𫝁😃𐒸 in un volume di Azure NetApp Files su NFSv4.1, ma non è possibile visualizzare usando NFSv4.1. Tuttavia, può essere visto usando SMB. Il nome viene troncato in SMB in un formato 8.3 supportato a causa dei set di caratteri non supportati creati dal client NFS e della conversione UTF-8/UTF-16 non compatibile per i caratteri in piani Unicode diversi.
Quando un nome di cartella usa caratteri UTF-8 standard trovati in BMP (inglese o in altro modo), SMB converte correttamente i nomi.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
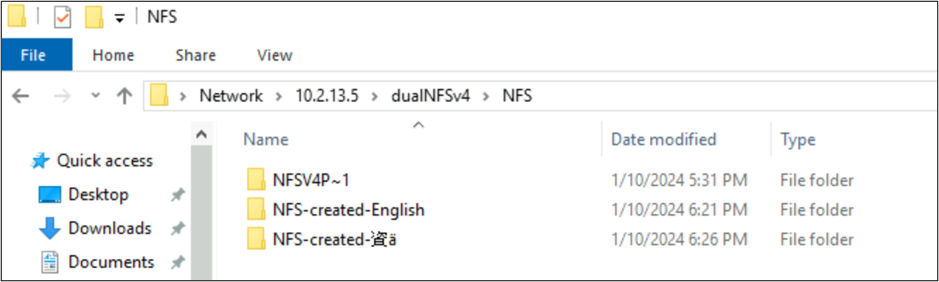
File e cartelle creati da SMB su NFS
I client Windows sono il tipo principale di client usati per accedere alle condivisioni SMB. Per impostazione predefinita, questi client hanno la codifica UTF-16. È possibile supportare alcuni caratteri con codifica UTF-8 in Windows abilitandolo nelle impostazioni dell'area:
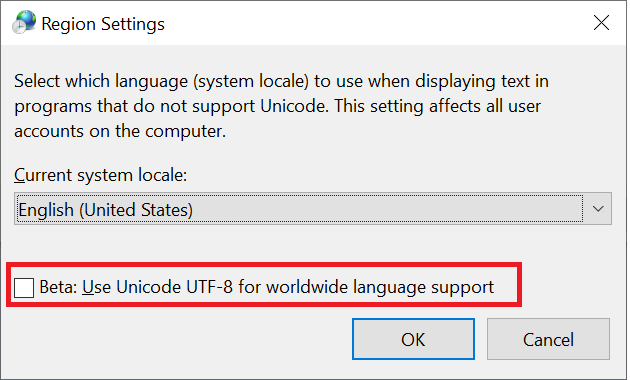
Quando un file o una cartella viene creata tramite una condivisione SMB in Azure NetApp Files, il set di caratteri codifica come UTF-16. Di conseguenza, i client che usano la codifica UTF-8 (ad esempio i client NFS basati su Linux) potrebbero non essere in grado di tradurre correttamente alcuni set di caratteri, in particolare i caratteri che non rientrano nel piano multilingue di base (BMP).
Comportamento dei caratteri non supportato
In questi scenari, quando un client NFS accede a un file creato usando SMB con caratteri non supportati, il nome viene visualizzato come una serie di valori numerici che rappresentano i valori Unicode per il carattere.
Ad esempio, questa cartella è stata creata in Esplora risorse usando caratteri esterni al modello BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
In NFSv3 viene visualizzata la cartella creata da SMB:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Su NFSv4.1, la cartella creata da SMB viene visualizzata come segue:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Comportamento dei caratteri supportato
Quando i caratteri si trovano nel BMP, non sono presenti problemi tra i protocolli SMB e NFS e le relative versioni.
Ad esempio, un nome di cartella creato usando SMB in un volume di Azure NetApp Files con caratteri presenti in BMP in più lingue (inglese, tedesco, cirillico, Runic) viene visualizzato correttamente in tutti i protocolli e le versioni.
- Latino di base "SMB"
- Greco "ͶΘΓ"
- Cirillico "ЁЄЊ"
- Runic "ᚠᚱᛯ"
- Ideogrammi di compatibilità CJK "豈滑虜"
Questo è il modo in cui il nome viene visualizzato in SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Ecco come viene visualizzato il nome da NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Ecco come viene visualizzato il nome da NFSv4.1:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Conversione di file in codifiche diverse
I nomi di file e cartelle non sono le uniche parti degli oggetti del file system che utilizzano le codifiche del linguaggio. Anche il contenuto del file (ad esempio caratteri speciali all'interno di un file di testo) può svolgere un ruolo. Ad esempio, se si tenta di salvare un file con caratteri speciali in un formato incompatibile, potrebbe essere visualizzato un messaggio di errore. In questo caso, non è possibile salvare un file con caratteri Katagana in ANSI, perché tali caratteri non esistono in tale codifica.
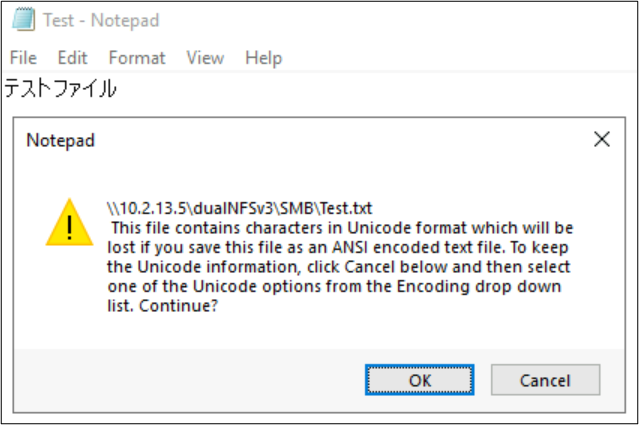
Una volta salvato il file in tale formato, i caratteri vengono convertiti in punti interrogativi:
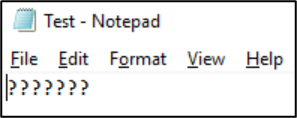
Le codifiche dei file possono essere visualizzate dai client NAS. Nei client Windows è possibile usare un'applicazione come Blocco note o Blocco note++ per visualizzare una codifica di un file. Se sottosistema Windows per Linux (WSL) o Git sono installati nel client, è possibile usare il file comando .
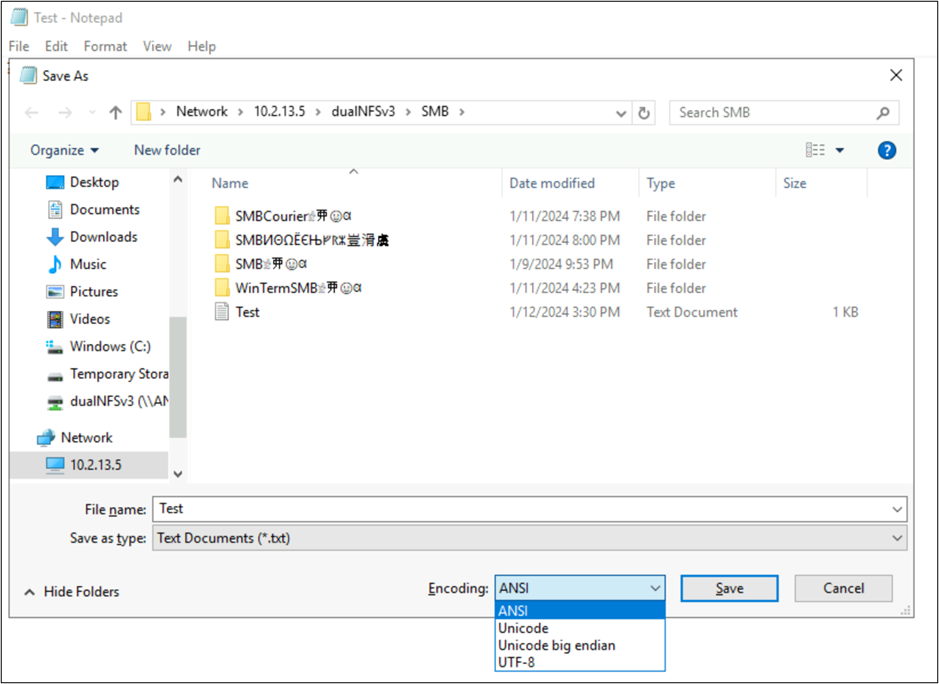
Queste applicazioni consentono anche di modificare la codifica del file salvando come tipi di codifica diversi. Inoltre, PowerShell può essere usato per convertire la codifica nei file con i Get-Content cmdlet e Set-Content .
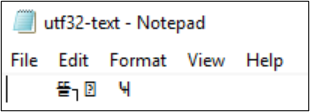
Ad esempio, il file utf8-text.txt viene codificato come UTF-8 e contiene caratteri esterni al modello BMP. Poiché viene usato UTF-8, i caratteri vengono visualizzati correttamente.

Se la codifica viene convertita in UTF-32, i caratteri non vengono visualizzati correttamente.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
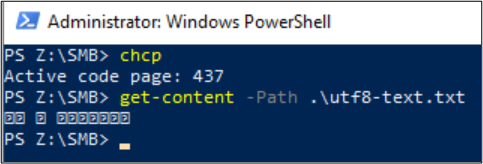
Get-Content può essere usato anche per visualizzare il contenuto del file. Per impostazione predefinita, PowerShell usa la codifica UTF-16 (tabella codici 437) e le selezioni dei tipi di carattere per la console sono limitate, quindi il file formattato UTF-8 con caratteri speciali non può essere visualizzato correttamente:
I client Linux possono usare il file comando per visualizzare la codifica del file. Negli ambienti a doppio protocollo, se un file viene creato con SMB, il client Linux che usa NFS può controllare la codifica dei file.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
La conversione della codifica dei file può essere eseguita nei client Linux usando il iconv comando . Per visualizzare l'elenco dei formati di codifica supportati, usare iconv -l.
Ad esempio, il file con codifica UTF-8 può essere convertito in UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Se il set di caratteri sul nome del file o nel contenuto del file non è supportato dalla codifica di destinazione, la conversione non è consentita. Ad esempio, Shift-JIS non può supportare i caratteri nel contenuto del file.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Se un file contiene caratteri supportati dalla codifica, la conversione avrà esito positivo. Ad esempio, se il file contiene i caratteri Katagana テストファイト, la conversione SHIFT-JIS avrà esito positivo su NFS. Poiché il client NFS usato qui non riconosce Shift-JIS a causa delle impostazioni locali, la codifica mostra "unknown-8bit".
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Poiché i volumi di Azure NetApp Files supportano solo la formattazione compatibile con UTF-8, i caratteri Katagana vengono convertiti in un formato illeggibile.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Quando si usa NFSv4.x, la conversione è consentita quando i caratteri non conformi sono presenti all'interno del contenuto del file, anche se NFSv4.x applica la codifica UTF-8. In questo esempio un file con codifica UTF-8 con caratteri Katagana che si trova in un volume di Azure NetApp Files mostra correttamente il contenuto di un file.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Ma una volta convertito, i caratteri nel file vengono visualizzati in modo non corretto a causa della codifica incompatibile.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Se il nome del file contiene caratteri non supportati per UTF-8, la conversione ha esito positivo su NFSv3, ma esegue il failover su NFSv4.x a causa dell'imposizione UTF-8 della versione del protocollo.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Procedure consigliate per i set di caratteri
Quando si usano caratteri speciali o caratteri esterni al piano BMP (Basic Multilingual Plane) standard nei volumi di Azure NetApp Files, è consigliabile tenere in considerazione alcune procedure consigliate.
- Poiché i volumi di Azure NetApp Files usano il linguaggio del volume UTF-8, la codifica dei file per i client NFS deve usare anche la codifica UTF-8 per ottenere risultati coerenti.
- I set di caratteri nei nomi di file o contenuti nel contenuto del file devono essere compatibili con UTF-8 per la corretta visualizzazione e funzionalità.
- Poiché SMB usa la codifica dei caratteri UTF-16, i caratteri esterni a BMP potrebbero non essere visualizzati correttamente su NFS nei volumi a doppio protocollo. Il più possibile, ridurre al minimo l'uso di caratteri speciali nel contenuto del file.
- Evitare di usare caratteri speciali all'esterno del BMP nei nomi di file, soprattutto quando si usano volumi NFSv4.1 o dual-protocol.
- Per i set di caratteri non nel BMP, la codifica UTF-8 deve consentire la visualizzazione dei caratteri in Azure NetApp Files quando si usa un singolo protocollo di file (solo SMB o NFS). Tuttavia, nella maggior parte dei casi, i volumi a doppio protocollo non sono in grado di supportare questi set di caratteri.
- La codifica non standard (ad esempio SHIFT-JIS) non è supportata nei volumi di Azure NetApp Files.
- I caratteri di coppia surrogati (ad esempio emoji) sono supportati nei volumi di Azure NetApp Files.