Usare la scalabilità automatica predittiva per aumentare la capacità prima delle richieste di carico nei set di scalabilità di macchine virtuali
La scalabilità automatica predittiva usa Machine Learning per gestire e ridimensionare i set di scalabilità di macchine virtuali di Azure con modelli di carichi di lavoro ciclici. Prevede il carico complessivo della CPU nel set di scalabilità di macchine virtuali, in base ai modelli di utilizzo cronologici della CPU. Consente di stimare il carico complessivo della CPU osservando e imparando dall'utilizzo cronologico. Questo processo garantisce che lo scale-out avvenga in tempo per soddisfare la domanda.
Per fornire le stime, la scalabilità automatica predittiva richiede almeno sette giorni di cronologia. Il periodo di campionamento massimo è una finestra mobile di 15 giorni, che offre i migliori risultati predittivi. Per i modelli di carico di lavoro mensili o annuali, usare le configurazioni di scalabilità automatica basata su pianificazione o scalabilità automatica basata su metriche.
La scalabilità automatica predittiva rispetta i limiti di ridimensionamento impostati per il set di scalabilità di macchine virtuali. Quando il sistema prevede che il carico CPU percentuale del set di scalabilità di macchine virtuali supera il limite di scale-out, le nuove istanze vengono aggiunte in base alle specifiche. È anche possibile configurare il tempo prima di effettuare il provisioning delle nuove istanze, fino a 1 ora prima che si verifichi il picco previsto del carico di lavoro.
Solo previsione consente di visualizzare la stima della CPU senza attivare l'azione di ridimensionamento in base alla previsione. Quindi è possibile confrontare la previsione con i modelli di carico di lavoro effettivi per incrementare l'attendibilità dei modelli di stima, prima di abilitare la funzionalità di scalabilità automatica predittiva.
Offerte di scalabilità automatica predittiva
- La scalabilità automatica predittiva si riferisce ai carichi di lavoro che evidenziano modelli di utilizzo ciclico della CPU.
- Il supporto è disponibile solo per i set di scalabilità di macchine virtuali.
- La metrica Percentuale CPU con il tipo di aggregazione Media è l'unica metrica attualmente supportata.
- La scalabilità automatica predittiva supporta solo la strategia di scale-out. Configurare la scalabilità automatica standard per gestire la riduzione delle azioni.
- La scalabilità automatica predittiva è disponibile solo per il cloud commerciale di Azure. I cloud di Azure per enti pubblici non sono attualmente supportati.
Abilitare la scalabilità automatica predittiva o solo la previsione con il portale di Azure
Passare alla schermata Set di scalabilità di macchine virtuali e selezionare Ridimensionamento.
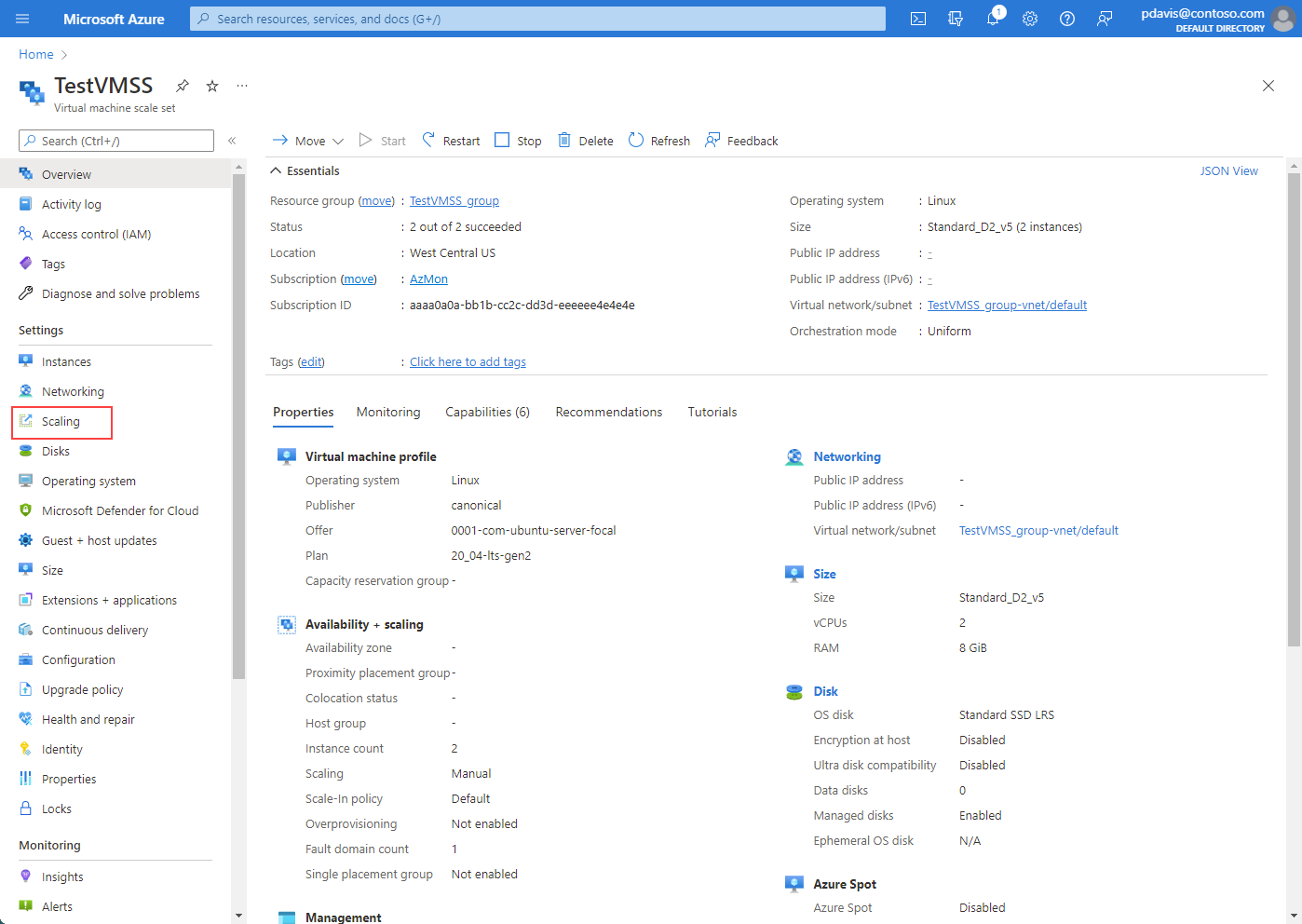
Nella sezione Scalabilità automatica personalizzata viene visualizzato Scalabilità automatica predittiva.
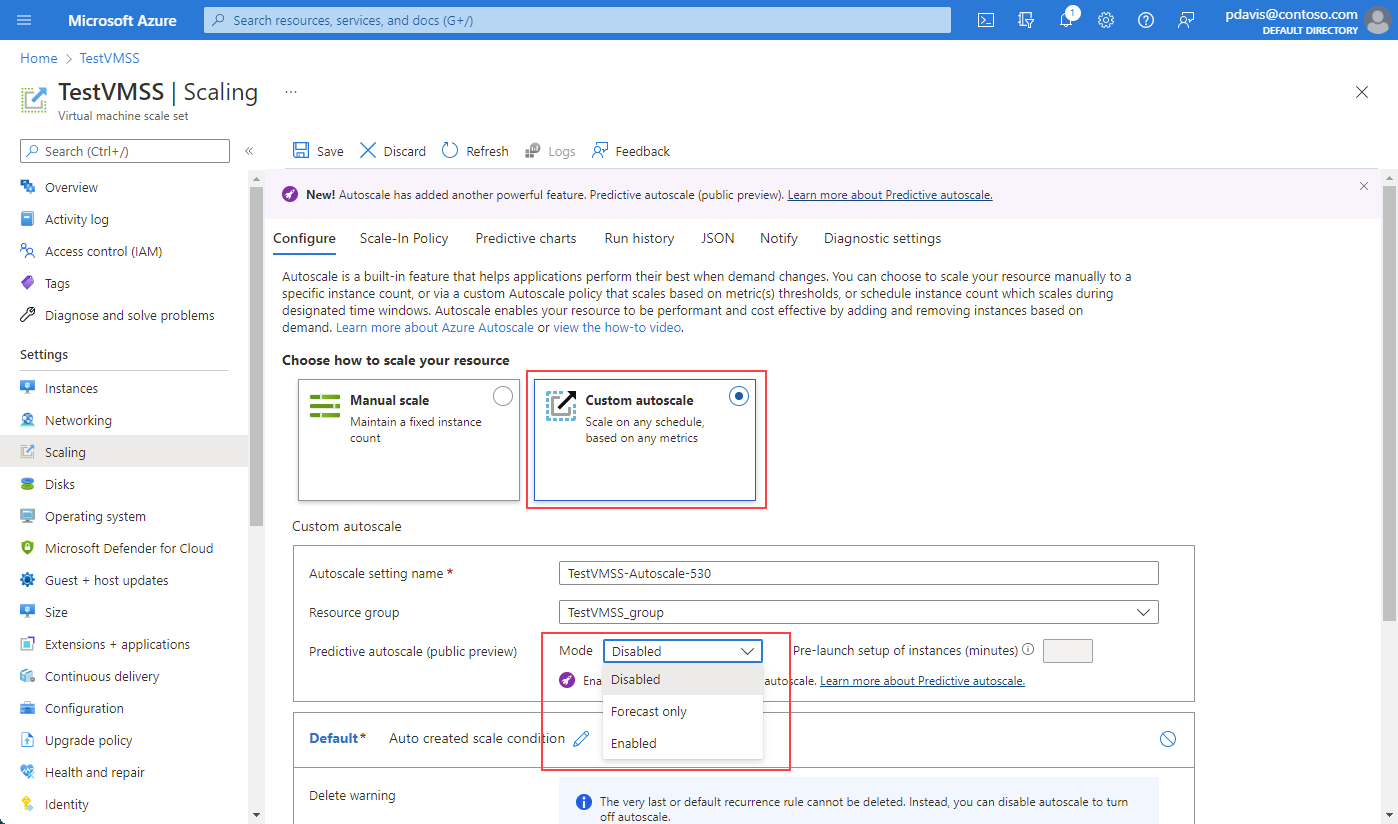
Usando la selezione dell'elenco a discesa, è possibile:
- Disabilitare la scalabilità automatica predittiva. Disable è la selezione predefinita quando si entra per la prima volta nella pagina per la scalabilità automatica predittiva.
- Abilitare la modalità di sola previsione.
- Abilitare la scalabilità automatica predittiva.
Nota
Prima di abilitare la scalabilità automatica predittiva o la modalità Solo previsione, è necessario configurare le condizioni di scalabilità automatica reattive standard.
Per abilitare la modalità Solo previsione, selezionarla dall'elenco a discesa. Definire un trigger di scale-out in base alla Percentuale di CPU. Quindi selezionare Salva. Lo stesso processo si applica per abilitare la scalabilità automatica predittiva. Per disabilitare la scalabilità automatica predittiva o la modalità Solo previsione, selezionare Disabilita dall'elenco a discesa.
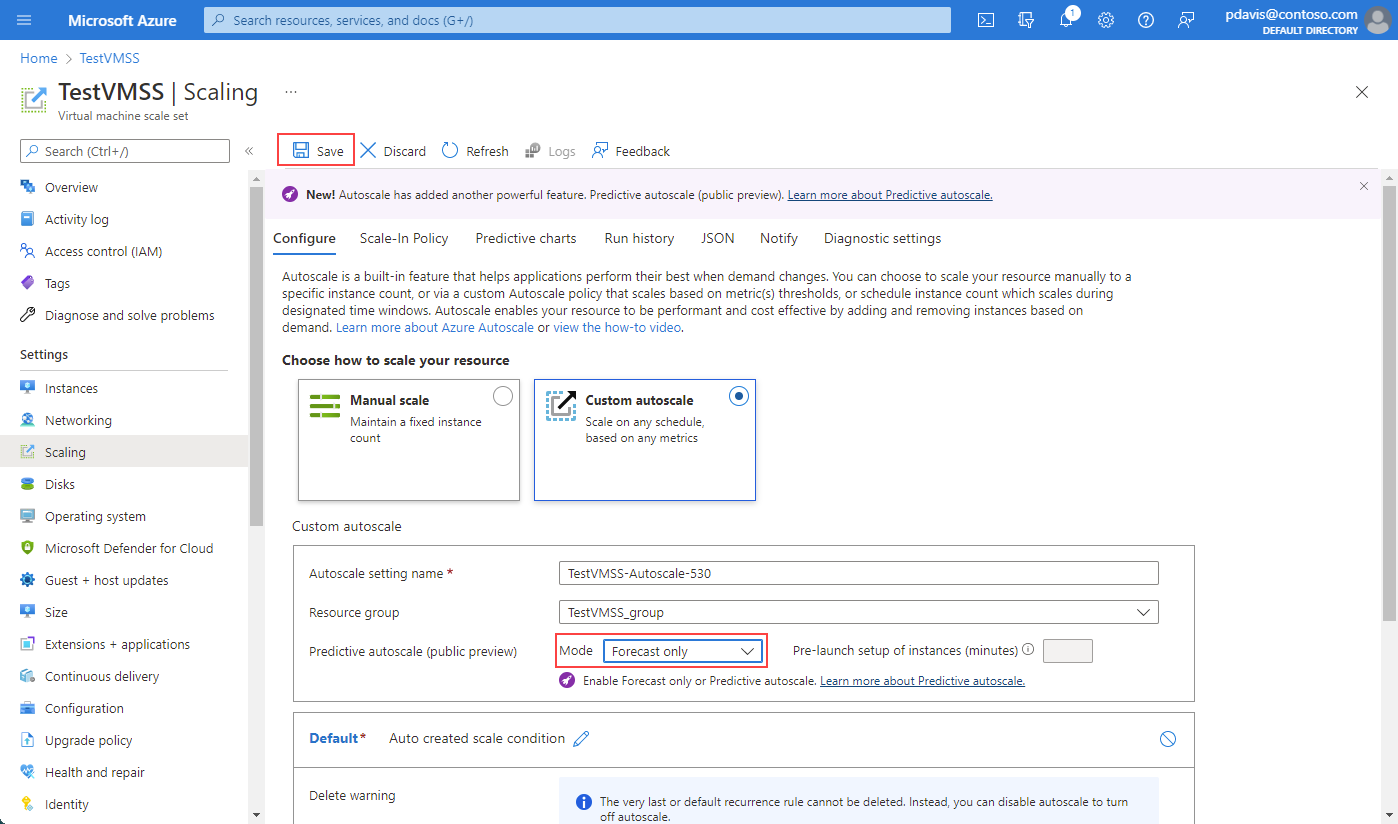
Se necessario, indicare un orario di preavvio in modo che le istanze siano completamente in esecuzione prima che diventino necessarie. È possibile preavviare le istanze con un tempo compreso tra 5 e 60 minuti prima dell'orario di previsione necessario.
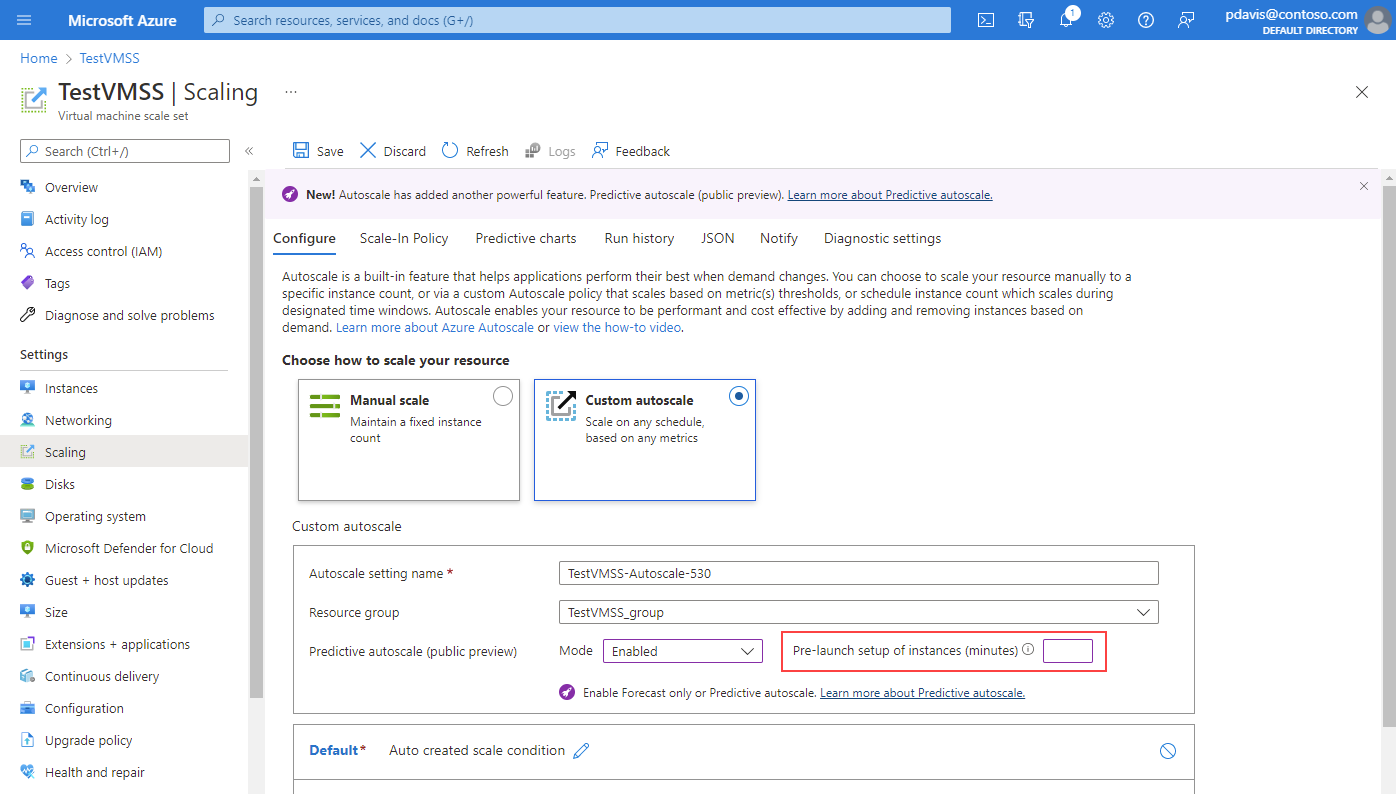
Dopo aver abilitato la scalabilità automatica predittiva o la modalità Solo previsione e salvarla, selezionare Grafici predittivi.
Vengono visualizzati tre grafici:
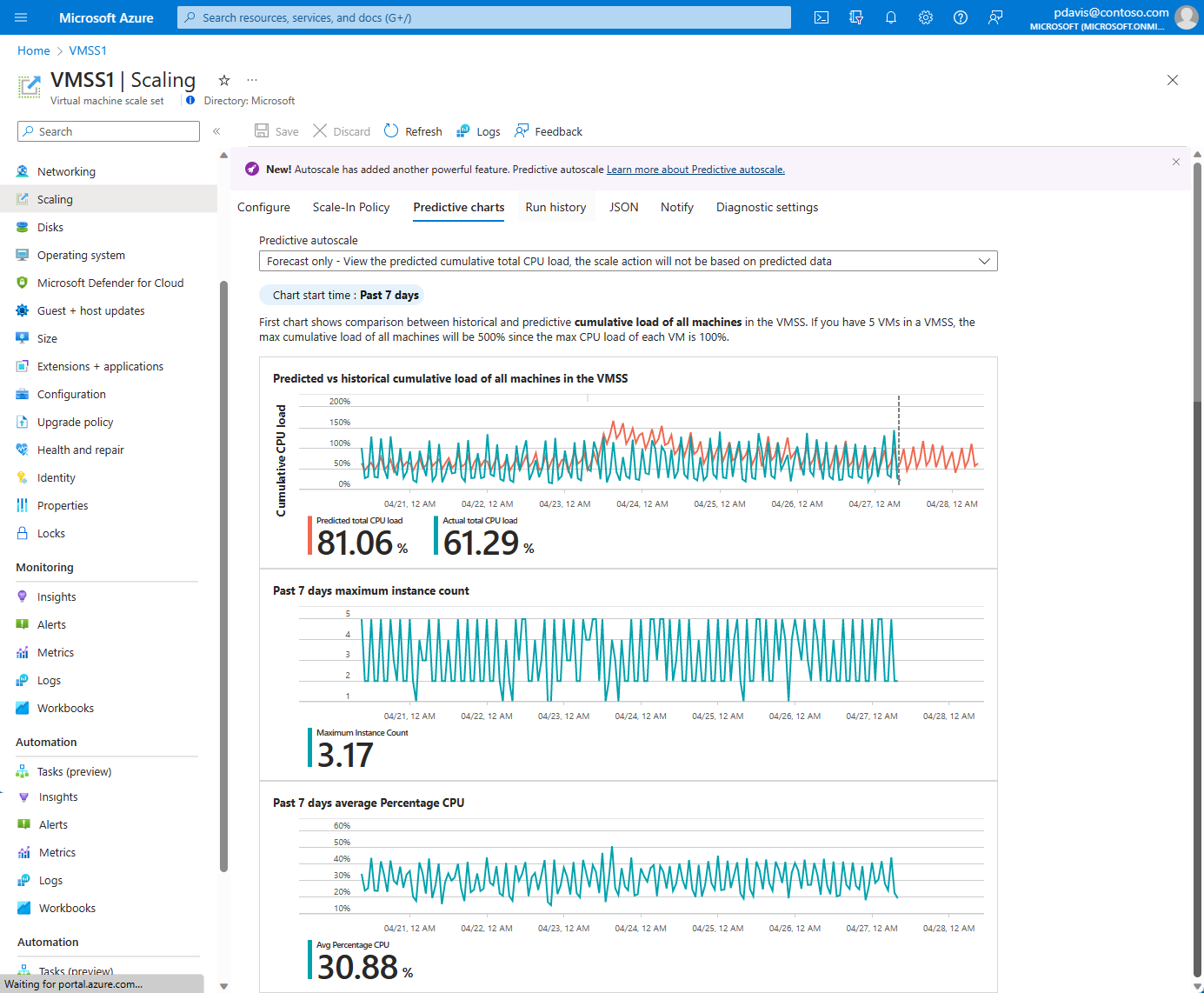
- Il grafico superiore mostra il confronto sovrapposto tra la percentuale totale di CPU effettiva e quella stimata. Nell'intervallo di tempo mostrato nel grafico mostrato sono compresi gli ultimi sette giorni e le 24 ore successive.
- Il grafico intermedio mostra il numero massimo di istanze in esecuzione negli ultimi sette giorni.
- Il grafico inferiore mostra l'utilizzo medio della CPU corrente negli ultimi sette giorni.



Abilitare usando un modello di Azure Resource Manager.
Recuperare l'ID della risorsa per il set di scalabilità di macchine virtuali e il gruppo di risorse del set di scalabilità di macchine virtuali. Ad esempio: /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
Aggiornare il file autoscale_only_parameters con l'ID risorsa del set di scalabilità di macchine virtuali e i parametri dell'impostazione di scalabilità automatica.
Usare un comando di PowerShell per distribuire il modello contenente le impostazioni di scalabilità automatica. Ad esempio:
PS G:\works\kusto_onboard\test_arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy -resourcegroupname cpatest2 -templatefile autoscale_only.json -templateparameterfile autoscale_only_parameters.json
PS C:\works\autoscale\predictive_autoscale\arm_template> new-azurermresourcegroupdeployment -name binzAutoScaleDeploy - resourcegroupname patest2 -templatefile autoscale_only_binz.json -templateparameterfile autoscale_only_parameters_binz.json
DeploymentName : binzAutoScaleDeploy
ResourceGroupName : patest2
ProvisioningState : Succeeded
Timestamp : 3/30/2021 10:11:02 PM
Mode : Incremental
TemplateLink
Parameters :
Name Type Value
================ ============================= ====================
targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
location String East US
minimumCapacity Int 1
maximumCapacity Int 4
defaultCapacity Int 4
metricThresholdToScaleOut Int 50
metricTimeWindowForScaleOut String PT5M
metricThresholdToScaleln Int 30
metricTimeWindowForScaleln String PT5M
changeCountScaleOut Int 1
changeCountScaleln Int 1
predictiveAutoscaleMode String Enabled
Outputs :
Name Type Value
================ ============================== ====================
targetVmssResourceld String /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2
settingLocation String East US
predictiveAutoscaleMode String Enabled
DeloymentDebugLoglevel :
PS C:\works\autoscale\predictive_autoscale\arm_template>
autoscale_only.json
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"targetVmssResourceId": {
"type": "string"
},
"location": {
"type": "string"
},
"minimumCapacity": {
"type": "Int",
"defaultValue": 2,
"metadata": {
"description": "The minimum capacity. Autoscale engine will ensure the instance count is at least this value."
}
},
"maximumCapacity": {
"type": "Int",
"defaultValue": 5,
"metadata": {
"description": "The maximum capacity. Autoscale engine will ensure the instance count is not greater than this value."
}
},
"defaultCapacity": {
"type": "Int",
"defaultValue": 3,
"metadata": {
"description": "The default capacity. Autoscale engine will preventively set the instance count to be this value if it can not find any metric data."
}
},
"metricThresholdToScaleOut": {
"type": "Int",
"defaultValue": 30,
"metadata": {
"description": "The metric upper threshold. If the metric value is above this threshold then autoscale engine will initiate scale out action."
}
},
"metricTimeWindowForScaleOut": {
"type": "string",
"defaultValue": "PT5M",
"metadata": {
"description": "The metric look up time window."
}
},
"metricThresholdToScaleIn": {
"type": "Int",
"defaultValue": 20,
"metadata": {
"description": "The metric lower threshold. If the metric value is below this threshold then autoscale engine will initiate scale in action."
}
},
"metricTimeWindowForScaleIn": {
"type": "string",
"defaultValue": "PT5M",
"metadata": {
"description": "The metric look up time window."
}
},
"changeCountScaleOut": {
"type": "Int",
"defaultValue": 1,
"metadata": {
"description": "The instance count to increase when autoscale engine is initiating scale out action."
}
},
"changeCountScaleIn": {
"type": "Int",
"defaultValue": 1,
"metadata": {
"description": "The instance count to decrease the instance count when autoscale engine is initiating scale in action."
}
},
"predictiveAutoscaleMode": {
"type": "String",
"defaultValue": "ForecastOnly",
"metadata": {
"description": "The predictive Autoscale mode."
}
}
},
"variables": {
},
"resources": [{
"type": "Microsoft.Insights/autoscalesettings",
"name": "cpuPredictiveAutoscale",
"apiVersion": "2022-10-01",
"location": "[parameters('location')]",
"properties": {
"profiles": [{
"name": "DefaultAutoscaleProfile",
"capacity": {
"minimum": "[parameters('minimumCapacity')]",
"maximum": "[parameters('maximumCapacity')]",
"default": "[parameters('defaultCapacity')]"
},
"rules": [{
"metricTrigger": {
"metricName": "Percentage CPU",
"metricNamespace": "",
"metricResourceUri": "[parameters('targetVmssResourceId')]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "[parameters('metricTimeWindowForScaleOut')]",
"timeAggregation": "Average",
"operator": "GreaterThan",
"threshold": "[parameters('metricThresholdToScaleOut')]"
},
"scaleAction": {
"direction": "Increase",
"type": "ChangeCount",
"value": "[parameters('changeCountScaleOut')]",
"cooldown": "PT5M"
}
}, {
"metricTrigger": {
"metricName": "Percentage CPU",
"metricNamespace": "",
"metricResourceUri": "[parameters('targetVmssResourceId')]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "[parameters('metricTimeWindowForScaleIn')]",
"timeAggregation": "Average",
"operator": "LessThan",
"threshold": "[parameters('metricThresholdToScaleIn')]"
},
"scaleAction": {
"direction": "Decrease",
"type": "ChangeCount",
"value": "[parameters('changeCountScaleOut')]",
"cooldown": "PT5M"
}
}
]
}
],
"enabled": true,
"targetResourceUri": "[parameters('targetVmssResourceId')]",
"predictiveAutoscalePolicy": {
"scaleMode": "[parameters('predictiveAutoscaleMode')]"
}
}
}
],
"outputs": {
"targetVmssResourceId" : {
"type" : "string",
"value" : "[parameters('targetVmssResourceId')]"
},
"settingLocation" : {
"type" : "string",
"value" : "[parameters('location')]"
},
"predictiveAutoscaleMode" : {
"type" : "string",
"value" : "[parameters('predictiveAutoscaleMode')]"
}
}
}
autoscale_only_parameters.json
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"targetVmssResourceId": {
"value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/patest2/providers/Microsoft.Compute/virtualMachineScaleSets/patest2"
},
"location": {
"value": "East US"
},
"minimumCapacity": {
"value": 1
},
"maximumCapacity": {
"value": 4
},
"defaultCapacity": {
"value": 4
},
"metricThresholdToScaleOut": {
"value": 50
},
"metricTimeWindowForScaleOut": {
"value": "PT5M"
},
"metricThresholdToScaleIn": {
"value": 30
},
"metricTimeWindowForScaleIn": {
"value": "PT5M"
},
"changeCountScaleOut": {
"value": 1
},
"changeCountScaleIn": {
"value": 1
},
"predictiveAutoscaleMode": {
"value": "Enabled"
}
}
}
Per altre informazioni sui modelli di Azure Resource Manager, vedere Informazioni generali sul modello di Resource Manager.
Domande frequenti
Questa sezione presenta le risposte alle domande frequenti.
Perché la percentuale della CPU è superiore al 100% nei grafici predittivi?
Il grafico predittivo mostra il carico cumulativo per tutti i computer nel set di scalabilità. Se in un set di scalabilità sono presenti 5 macchine virtuali, il carico cumulativo massimo per tutte le VM sarà pari al 500%, ovvero cinque volte il carico massimo della CPU del 100% per ogni VM.
Cosa accade nel tempo quando si attiva la scalabilità automatica predittiva per un set di scalabilità di macchine virtuali?
La scalabilità automatica della stima usa la cronologia di un set di scalabilità di macchine virtuali in esecuzione. Se il set di scalabilità è in esecuzione da meno di sette giorni, si riceverà un messaggio indicante che il modello è in fase di training. Per altre informazioni, vedere messaggio nessun dato predittivo. Le stime migliorano con il passare del tempo e ottengono un livello di accuratezza massima 15 giorni dopo la creazione del set di scalabilità di macchine virtuali.
Se si verificano modifiche al modello di carico di lavoro che tuttavia rimangono periodiche, il modello riconosce la modifica e inizia a regolare la previsione. La previsione migliora con il passare del tempo. Il livello di accuratezza massima viene raggiunto 15 giorni dopo la modifica nel modello di traffico. Tenere presente che le regole di scalabilità automatica standard rimangono valide. Se si verifica un nuovo aumento imprevisto del traffico, il set di scalabilità di macchine virtuali verrà comunque aumentato per soddisfare la domanda.
Cosa succede se il modello non funziona bene per me?
La modellazione funziona al meglio con i carichi di lavoro che presentano periodicità. È consigliabile valutare prima di tutto le stime abilitando "Solo previsione", che sovrapporrà l'utilizzo stimato della CPU del set di scalabilità con l'utilizzo effettivo osservato. Dopo aver confrontato e valutato i risultati, se le stime del modello sono sufficienti per lo scenario, è possibile quindi scegliere di abilitare il ridimensionamento in base alle metriche stimate.
Perché è necessario abilitare la scalabilità automatica standard prima di abilitare la scalabilità automatica predittiva?
La scalabilità automatica standard è un fallback necessario se il modello predittivo non funziona correttamente per lo scenario. La scalabilità automatica standard coprirà picchi di carico imprevisti, che non fanno parte del modello di carico tipico della CPU. Fornisce anche un fallback se si verifica un errore nel recupero dei dati predittivi.
Se vengono impostate le regole di scalabilità automatica sia predittive che standard, quale regola avrà effetto?
Le regole di scalabilità automatica standard vengono usate se si verifica un picco imprevisto nel carico della CPU o in caso di errore durante il recupero dei dati predittivi.
Viene usato il valore soglia impostato nelle regole di scalabilità automatica standard per comprendere quando aumentare le istanze e il numero di istanze. Se si vuole aumentare il numero di istanze del set di scalabilità di macchine virtuali quando l'utilizzo della CPU supera il 70% e i dati effettivi o stimati indicano che l'utilizzo della CPU è o sarà superiore al 70%, si verificherà un aumento del numero di istanze.
Errori e avvisi
Questa sezione presenta gli errori e gli avvisi comuni.
Non è stata abilitata la scalabilità automatica standard
Viene visualizzato il messaggio di errore seguente:
Per abilitare la scalabilità automatica predittiva, creare una regola di scalabilità orizzontale in base alla metrica 'CPU percentuale'. Fare clic qui per passare alla scheda 'Configura' per impostare una regola di scalabilità automatica.
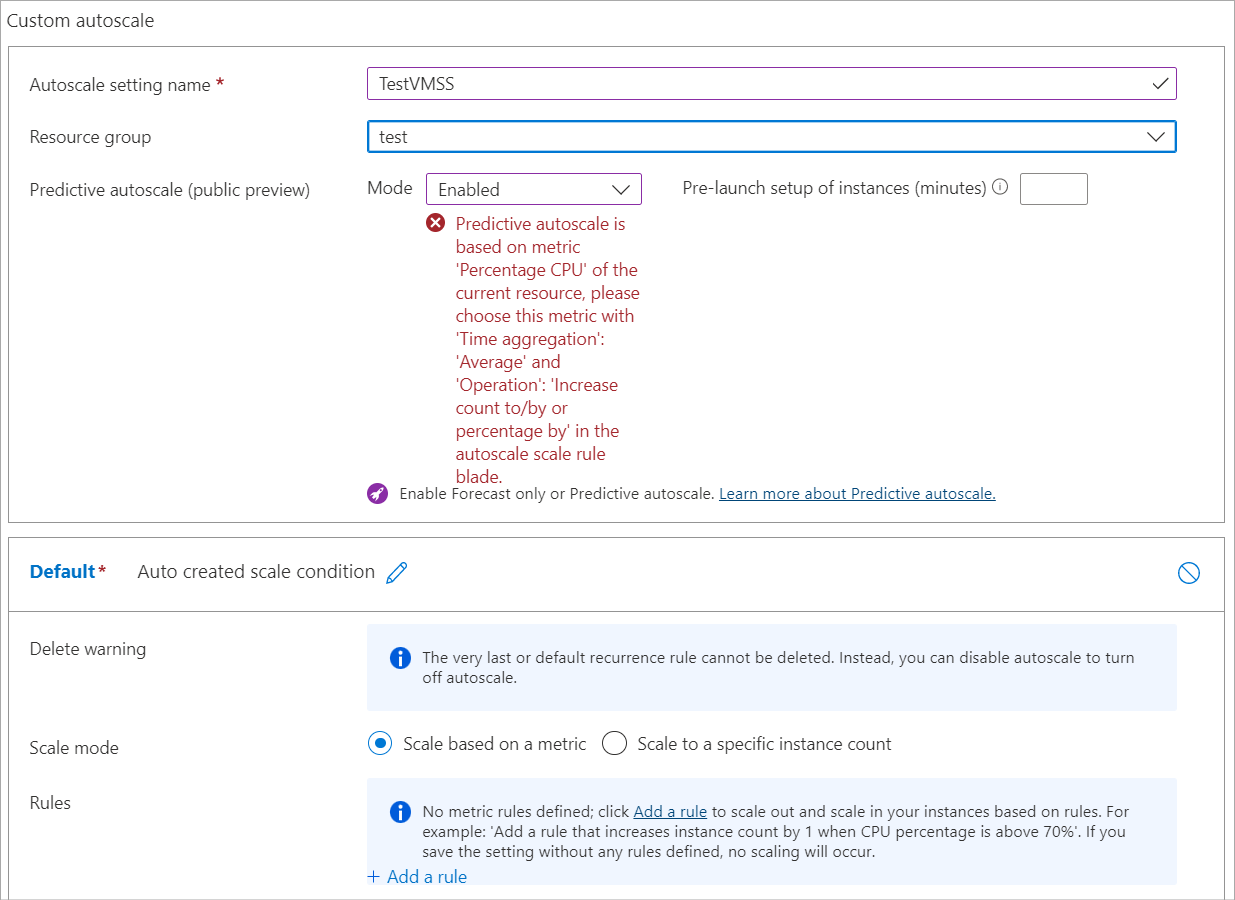
Questo messaggio indica che si è tentato di abilitare la scalabilità automatica predittiva prima di abilitare la scalabilità automatica standard e di impostarla per l'uso della metrica Percentuale CPU con tipo di aggregazione Media.
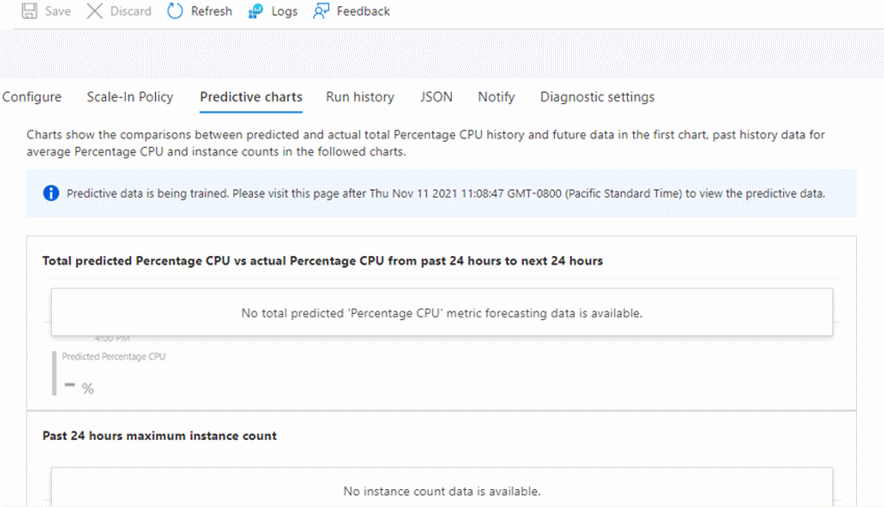
Nessun dato predittivo
I dati nei grafici predittivi non verranno visualizzati in determinate condizioni. Questo comportamento è previsto e non è un errore.
Quando la scalabilità automatica predittiva è disabilitata, si riceve invece un messaggio che inizia con "Nessun dato da visualizzare..." Vengono quindi visualizzate le istruzioni relative a cosa abilitare per visualizzare un grafico predittivo.

Quando si crea per la prima volta un set di scalabilità di macchine virtuali e si abilita la modalità Solo previsione, viene visualizzato il messaggio "I dati predittivi sono in fase di training..." e un'indicazione di quando tornare a vedere il grafico.
Passaggi successivi
Altre informazioni sulla scalabilità automatica sono disponibili negli articoli seguenti:
- Panoramica della scalabilità automatica
- Metriche comuni per la scalabilità automatica di Monitoraggio di Azure
- Procedure consigliate per la scalabilità automatica in Monitoraggio di Azure
- Usare le azioni di ridimensionamento automatico per inviare notifiche di avviso di webhook e posta elettronica in Azure Insights
- API REST per il ridimensionamento automatico