Disponibilità elevata e ripristino di emergenza con Managed Redis di Azure (anteprima)
Come per tutti i sistemi cloud, possono verificarsi interruzioni non pianificate che comportano la disattivazione di un'istanza di macchine virtuali (VM), una zona di disponibilità o un'intera area di Azure. È consigliabile che i clienti dispongano di un piano per gestire interruzioni della zona o dell'area.
Questo articolo presenta le informazioni per i clienti per creare un piano di continuità aziendale e ripristino di emergenza per l'implementazione di Redis gestita di Azure (anteprima).
Opzioni di disponibilità elevata:
| Opzione | Descrizione | Disponibilità |
|---|---|---|
| Replica standard | Configurazione replicata a doppio nodo in un singolo data center con failover automatico | 99,9% (vedi i dettagli) |
| Ridondanza della zona | Configurazione replicata a più nodi tra zone di disponibilità, con failover automatico | 99,99% (vedere i dettagli) |
| Replica geografica | Istanze della cache collegate in due aree, con failover controllato dall'utente | Attivo (vedere i dettagli) |
| Importazione/Esportazione | Snapshot temporizzato dei dati nella cache. | 99,9% (vedi i dettagli) |
| Persistenza | Salvataggio periodico dei dati nell'account di archiviazione. | 99,9% (vedi i dettagli) |
Replica standard per disponibilità elevata
Consigliato per: disponibilità elevata
Managed Redis di Azure dispone di un'architettura a disponibilità elevata che garantisce il funzionamento dell'istanza gestita, anche quando interruzioni interessano le macchine virtuali sottostanti. Se l'interruzione è pianificata o non pianificata, Azure Managed Redis offre percentuali di disponibilità maggiori rispetto a quelle raggiungibili ospitando Redis in una singola macchina virtuale. Un'installazione di Redis gestita di Azure viene eseguita in una coppia di server Redis per impostazione predefinita. I due server sono ospitati in macchine virtuali dedicate.
Con Azure Managed Redis, un server è il nodo primario , mentre l'altro è la replica. Dopo il provisioning dei nodi del server, Azure Managed Redis assegna i ruoli primari e di replica. Il nodo primario è in genere responsabile della manutenzione delle richieste di scrittura e lettura dai client. In un'operazione di scrittura, esegue il commit di una nuova chiave e di un aggiornamento della chiave alla memoria interna e risponde immediatamente al client. Inoltra l'operazione alla replica in modo asincrono.
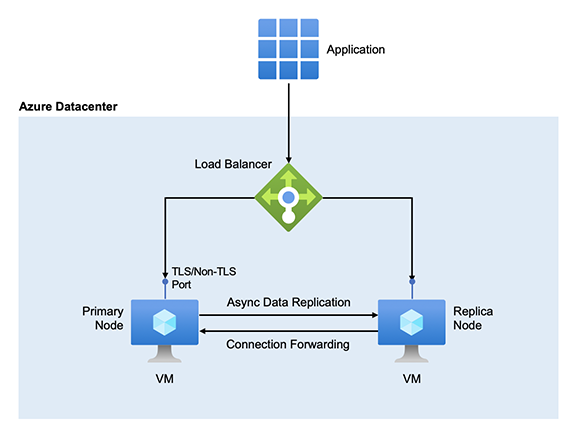
Se il nodo primario in una cache non è disponibile, la replica si promuove automaticamente per diventare il nuovo nodo primario. Questo processo viene chiamato failover. Un failover è costituito solo da due nodi, primario/replica, scambio di ruoli, replica/primario, con uno dei nodi che potrebbero andare offline per alcuni minuti. Nella maggior parte dei failover, i nodi primario e di replica coordinano l'handover così che non vi sia praticamente nessun istante senza un nodo primario.
L'ex nodo primario va brevemente offline per ricevere gli aggiornamenti dal nuovo nodo primario. Quindi, quello che è ora il nodo replica torna online e rielabora la cache completamente sincronizzata. La cosa importante è che quando un nodo non è disponibile, si tratta di una condizione temporanea, perché torna online.
Una sequenza di failover tipica è simile a quella seguente, quando un nodo primario deve arrestarsi per manutenzione:
- I nodi primario e di replica negoziano un failover coordinato e si scambiano i ruoli.
- Il nodo replica (in precedenza primario) va offline per un riavvio.
- Pochi secondi o minuti dopo, la replica torna online.
- Il nodo replica sincronizza i dati con il nodo primario.
Un nodo primario può andare offline come parte di un'attività di manutenzione pianificata, ad esempio nel caso di un aggiornamento del software Redis o del sistema operativo. Può anche smettere di funzionare a causa di eventi non pianificati, ad esempio errori nell'hardware, nel software o nella rete sottostanti. Il failover e l'applicazione di patch per Redis gestito di Azure fornisce una spiegazione dettagliata sui tipi di failover. Un'istanza di Redis gestita di Azure passa attraverso molti failover durante la sua durata. La progettazione dell'architettura a disponibilità elevata rende queste modifiche all'interno di una cache il più trasparente possibile per i client.
Ridondanza della zona
Consigliato per: disponibilità elevata, ripristino di emergenza - all'interno dell'area
Managed Redis di Azure supporta la configurazione della ridondanza della zona per impostazione predefinita. Una cache con ridondanza della zona inserisce automaticamente i nodi in diversi zone di disponibilità di Azure nella stessa area. Quando una zona diventa inattiva, i nodi della cache in altre zone sono disponibili per mantenere la cache funzionante come di consueto. Elimina l'interruzione del data center o della zona di disponibilità come singolo punto di errore e aumenta la disponibilità complessiva della cache.
Esperienza di zona non disponibile
Quando un nodo dati diventa non disponibile o si verifica una suddivisione di rete, viene eseguito un failover simile a quello descritto in Replica standard. Il cluster usa un modello basato sul quorum per determinare quali nodi sopravvissuti partecipano a un nuovo quorum. Promuove anche le partizioni replica all'interno di tali nodi a partizioni primarie in base alle esigenze.
Disponibilità a livello di area
Le cache con ridondanza della zona sono disponibili nelle aree seguenti:
| Americhe | Europa | Medio Oriente | Africa | Asia/Pacifico |
|---|---|---|---|---|
| Canada centrale* | Europa settentrionale | Australia orientale | ||
| Stati Uniti centrali* | Regno Unito meridionale | India centrale | ||
| Stati Uniti orientali | Europa occidentale | Asia sud-orientale | ||
| Stati Uniti orientali 2 | Giappone orientale* | |||
| Stati Uniti centro-meridionali | Asia orientale* | |||
| West US 2 | ||||
| Stati Uniti occidentali 3 | ||||
| Brasile meridionale |
Persistenza
Consigliato per: Durabilità dei dati
Poiché i dati della cache vengono archiviati in memoria, un errore raro e non pianificato di più nodi può causare l'eliminazione di tutti i dati. Per evitare di perdere completamente i dati, la persistenza di Redis consente di creare snapshot periodici dei dati in memoria e di archiviarli in un disco gestito collegato direttamente all'istanza della cache. In caso di perdita di dati, i dati della cache vengono ripristinati automaticamente usando lo snapshot nel disco gestito. Per altre informazioni, vedere Configurare la persistenza dei dati per un'istanza di Redis gestita di Azure.
Importazione/Esportazione
Consigliato per: Ripristino di emergenza
Redis gestito di Azure supporta l'opzione per importare ed esportare file di database Redis (RDB) per garantire la portabilità dei dati. Consente di importare dati in Redis gestito di Azure o di esportare dati da Redis gestito di Azure usando uno snapshot RDB. Lo snapshot RDB da una cache viene esportato in un BLOB in un account Archiviazione di Azure. È possibile creare uno script per attivare periodicamente l'esportazione nell'account di archiviazione. Per altre informazioni, vedere Importare ed esportare dati in Managed Redis di Azure.
Account di archiviazione per l'esportazione
Valutare la possibilità di scegliere un account di archiviazione con ridondanza geografica per garantire la disponibilità elevata dei dati esportati. Per altre informazioni, vedere Ridondanza di Archiviazione di Azure.
Replica geografica attiva
Consigliato per: disponibilità elevata, ripristino di emergenza - regioni multiple
La replica geografica è un meccanismo per collegare le istanze di Redis gestite di Azure in più aree di Azure. Redis gestito di Azure supporta una forma avanzata di replica geografica denominata replica geografica attiva che offre disponibilità più elevata e ripristino di emergenza tra più aree. Il software Redis gestito di Azure usa tipi di dati replicati senza conflitti per supportare le scritture in più istanze della cache, unisce le modifiche e risolve i conflitti. È possibile aggiungere fino a cinque istanze della cache in aree di Azure diverse per formare un gruppo di replica geografica.
Un'applicazione che utilizza una cache di questo tipo è in grado di leggere e scrivere in una qualsiasi delle istanze della cache con distribuzione geografica tramite gli endpoint corrispondenti. L'applicazione deve usare quella che è più vicina a ciascuna istanza dell'applicazione, offrendo la latenza più bassa. Per altre informazioni, vedere Configurare la replica geografica attiva per le istanze di Redis gestite di Azure.
Se un'area di una delle cache nel gruppo di replica diventa inattiva, l'applicazione deve passare a un'altra area disponibile.
Quando una cache nel gruppo di replica non è disponibile, è consigliabile monitorare l'utilizzo della memoria per le altre cache nello stesso gruppo di replica. Mentre una delle cache è inattiva, tutte le altre cache del gruppo di replica iniziano a salvare i metadati che non possono condividere con la cache inattiva. Se l'utilizzo della memoria per le cache disponibili inizia a crescere a una frequenza elevata dopo che una delle cache è diventata inattiva, è consigliabile scollegare la cache non disponibile dal gruppo di replica.
Per altre informazioni sullo scollegamento forzato, vedere Forzare lo scollegamento in caso di interruzione dell'area.
Eliminare e ricreare la cache
Se si verifica un'interruzione a livello di area, provare a ricreare la cache in un'area diversa e aggiornare l'applicazione per connettersi alla nuova cache. È importante comprendere che i dati vengono persi durante un'interruzione a livello di area, a meno che non si usi la replica geografica attiva. Il codice dell'applicazione deve essere resiliente alla perdita di dati.
Dopo aver ripristinato l'area interessata, il redis gestito di Azure non disponibile viene ripristinato automaticamente e disponibile nuovamente per l'uso. Per altre strategie per spostare la cache in un'area diversa, vedere Spostare le istanze di Redis gestite di Azure in aree diverse.