Disponibilità elevata con Istanza gestita di SQL abilitata da Azure Arc
Istanza gestita di SQL abilitata da Azure Arc viene distribuita in Kubernetes come un'applicazione in contenitori. Usa costrutti Kubernetes, ad esempio set con stato e archiviazione permanente per fornire in modalità predefinita:
- Monitoraggio dell’integrità
- rilevamento degli errori
- Failover automatico per mantenere l'integrità dei servizi.
Per una maggiore affidabilità, è anche possibile configurare Istanza gestita di SQL abilitata da Azure Arc per la distribuzione con repliche aggiuntive in una configurazione a disponibilità elevata. Il controller dei dati di Arc gestisce:
- Monitoraggio
- rilevamento degli errori
- Failover automatico
Il servizio dati abilitato per Arc fornisce questo servizio senza l'intervento dell'utente. Il servizio:
- Configura il gruppo di disponibilità
- Configura gli endpoint di mirroring del database
- Aggiunge database al gruppo di disponibilità
- Coordina il failover e l'aggiornamento.
Questo documento illustra entrambe le tipologie di disponibilità elevata.
Istanza gestita di SQL abilitata da Azure Arc offre diversi livelli di disponibilità elevata a seconda che l'Istanza gestita di SQL sia stata distribuita come livello di servizio con utilizzo generico o livello di servizio business critical.
Disponibilità elevata nel livello di servizio con utilizzo generico
Nel livello di servizio con utilizzo generico, è disponibile una sola replica e la disponibilità elevata viene ottenuta tramite l'orchestrazione di Kubernetes. Ad esempio, se un pod o un nodo contenente l'immagine del contenitore dell'istanza gestita si arresta in modo anomalo, Kubernetes tenta di gestire un altro pod o nodo e di collegarsi alla stessa risorsa di archiviazione permanente. Durante questo periodo, Istanza gestita di SQL non è disponibile per le applicazioni. Le applicazioni devono riconnettersi e ripetere la transazione quando il nuovo pod è in esecuzione. Se il tipo di servizio usato è load balancer, le applicazioni possono riconnettersi allo stesso endpoint primario e Kubernetes reindirizzerà la connessione al nuovo database primario. Se il tipo di servizio è nodeport, le applicazioni dovranno riconnettersi al nuovo indirizzo IP.
Verificare la disponibilità elevata predefinita
Per verificare la disponibilità elevata predefinita fornita da Kubernetes, è possibile:
- Eliminare il pod di un'istanza gestita esistente
- Verificare che Kubernetes si ripristini da questa azione
Durante il ripristino, Kubernetes esegue il bootstrap di un altro pod e collega l'archiviazione permanente.
Prerequisiti
- Il cluster Kubernetes richiede l'archiviazione remota condivisa
- Un'Istanza gestita di SQL abilitata da Azure Arc distribuita con una replica (impostazione predefinita)
Visualizzare i pod.
kubectl get pods -n <namespace of data controller>Eliminare il pod dell'istanza gestita.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Ad esempio:
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedVisualizzare i pod per verificare che l'istanza gestita stia eseguendo il ripristino.
kubectl get pods -n <namespace of data controller>Ad esempio:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Dopo il ripristino di tutti i contenitori all'interno del pod, è possibile connettersi all'istanza gestita.
Disponibilità elevata nel livello di servizio business critical
Nel livello di servizio business critical, oltre a quello fornito in modo nativo dall'orchestrazione Kubernetes, Istanza gestita di SQL per Azure Arc fornisce un gruppo di disponibilità indipendente. Il gruppo di disponibilità indipendente è basato sulla tecnologia SQL Server Always On. Offre livelli di disponibilità più elevati. Istanza gestita di SQL abilitata da Azure Arc distribuita con il livello di servizio business critical può essere distribuita con 2 o 3 repliche. Queste repliche vengono sempre sincronizzate tra loro.
Con i gruppi di disponibilità indipendenti, eventuali arresti anomali dei pod o errori dei nodi sono trasparenti per l'applicazione. Il gruppo di disponibilità indipendente fornisce almeno un altro pod che contiene tutti i dati del database primario ed è pronto per acquisire connessioni.
Gruppi di disponibilità indipendenti
Un gruppo di disponibilità associa uno o più database utente a un gruppo logico in modo che, quando si verifica un failover, l'intero gruppo di database esegue il failover nella replica secondaria come singola unità. Un gruppo di disponibilità replica solo i dati nei database dell'utente, ma non i dati nei database di sistema, come account di accesso, autorizzazioni o processi dell'agente. Un gruppo di disponibilità indipendente include metadati dei database di sistema, come i database msdb e master. Quando gli account di accesso vengono creati o modificati nella replica primaria, vengono creati automaticamente anche nelle repliche secondarie. Analogamente, quando un processo dell'agente viene creato o modificato nella replica primaria, le repliche secondarie ricevono anche tali modifiche.
Istanza gestita di SQL abilitata da Azure Arc accetta questo concetto di gruppo di disponibilità indipendente e aggiunge l'operatore Kubernetes per supportare la distribuzione su larga scala.
Le funzionalità che contengono gruppi di disponibilità abilitano:
Con l distribuzione con più repliche, viene creato un singolo gruppo di disponibilità con lo stesso nome dell'Istanza gestita di SQL abilitata per Arc. Per impostazione predefinita, il gruppo di disponibilità indipendente include tre repliche, tra cui la replica primaria. Tutte le operazioni CRUD per il gruppo di disponibilità vengono gestite internamente, inclusa la creazione del gruppo di disponibilità o l'aggiunta di repliche al gruppo di disponibilità creato. Non è possibile creare più gruppi di disponibilità in un'istanza.
Tutti i database vengono aggiunti automaticamente al gruppo di disponibilità, inclusi tutti i database utente e di sistema come
masteremsdb. Questa funzionalità offre una vista a singolo sistema di tutte le repliche del gruppo di disponibilità. Si notino entrambi i databasecontainedag_masterecontainedag_msdbse ci si connette direttamente all'istanza. I databasecontainedag_*rappresentano i databasemasteremsdball'interno del gruppo di disponibilità.Viene effettuato il provisioning automatico di un endpoint esterno per la connessione ai database all'interno del gruppo di disponibilità. Questo endpoint
<managed_instance_name>-external-svcha il ruolo di listener del gruppo di disponibilità.
Distribuire Istanza gestita di SQL abilitata da Azure Arc con più repliche tramite il portale di Azure
Dal portale di Azure, nella pagina di creazione dell'Istanza gestita di SQL abilitata da Azure Arc:
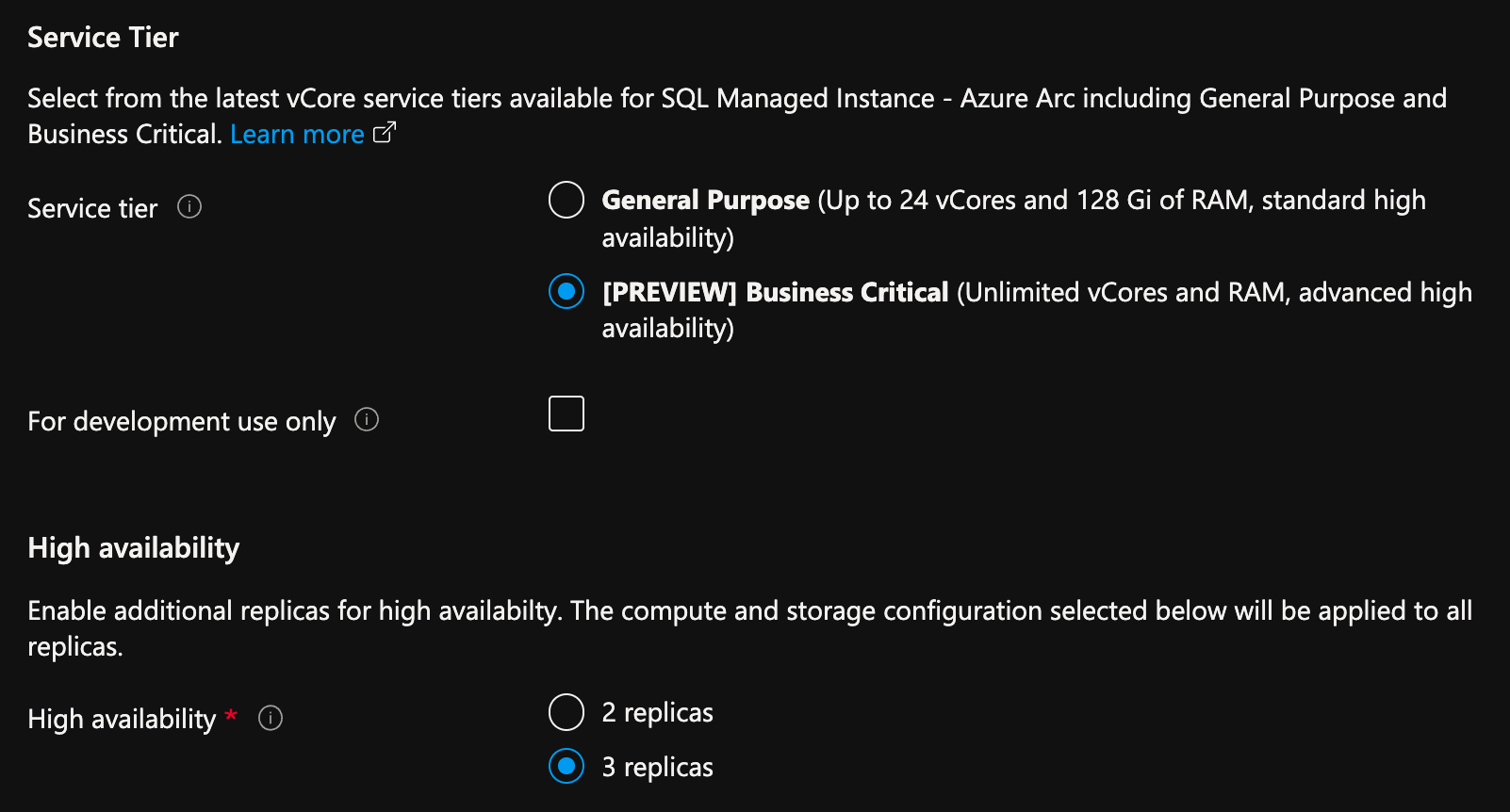
- Selezionare Configura calcolo e archiviazione in Calcolo e archiviazione. Il portale mostra le impostazioni avanzate.
- In Livello di servizio, selezionare Business critical.
- Selezionare l'opzione "Solo per lo sviluppo", per l'utilizzo unicamente a scopo di sviluppo.
- In Disponibilità elevata, selezionare 2 repliche o 3 repliche.
Eseguire la distribuzione con più repliche usando l'interfaccia della riga di comando di Azure
Quando un'Istanza gestita di SQL abilitata da Azure Arc viene distribuita nel livello di servizio business critical, la distribuzione crea più repliche. L'installazione e la configurazione dei gruppi di disponibilità indipendenti tra tali istanze vengono eseguite automaticamente durante il provisioning.
Ad esempio, il comando seguente crea un'istanza gestita con 3 repliche.
Modalità con connessione indiretta:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Esempio:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Modalità con connessione diretta:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Esempio:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Per impostazione predefinita, tutte le repliche vengono configurate in modalità sincrona. Ciò significa che tutti gli aggiornamenti nell'istanza primaria vengono replicati in modo sincrono in ciascuna delle istanze secondarie.
Visualizzare e monitorare lo stato di disponibilità elevata
Al termine della distribuzione, connettersi all'endpoint primario da SQL Server Management Studio.
Verificare e recuperare l'endpoint della replica primaria e connettersi a esso da SQL Server Management Studio.
Ad esempio, se l'istanza di SQL è stata distribuita usando service-type=loadbalancer, eseguire il comando sotto riportato per recuperare l'endpoint a cui connettersi:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
or
kubectl get sqlmi -A
Ottenere gli endpoint primario e secondario e lo stato del gruppo di disponibilità
Usare i comandi kubectl describe sqlmi o az sql mi-arc show per visualizzare gli endpoint primario e secondario e lo stato di disponibilità elevata.
Esempio:
kubectl describe sqlmi sqldemo -n my-namespace
or
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Output di esempio:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
È possibile connettersi all'endpoint primario con SQL Server Management Studio e verificare le DMV come:
SELECT * FROM sys.dm_hadr_availability_replica_states
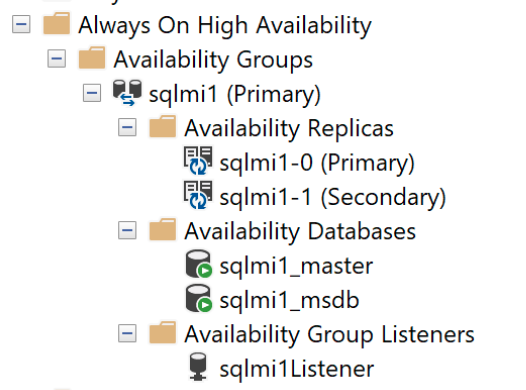
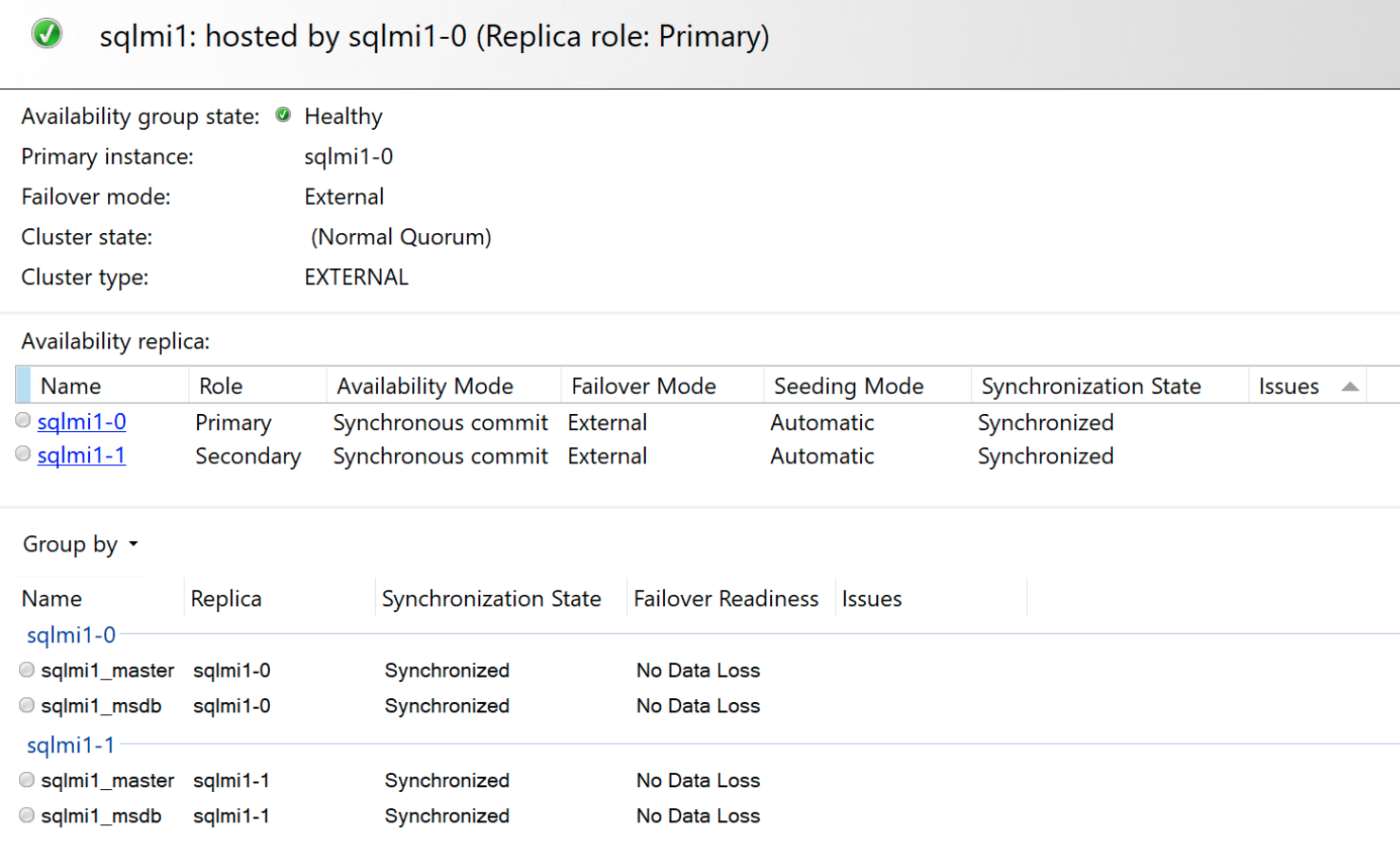
E il dashboard di disponibilità indipendente:
Scenari di failover
A differenza dei gruppi di disponibilità Always On di SQL Server, il gruppo di disponibilità indipendente è una soluzione a disponibilità elevata gestita. Di conseguenza, le modalità di failover sono limitate rispetto alle modalità tipiche disponibili con i gruppi di disponibilità Always On di SQL Server.
Distribuire istanze gestite di SQL del livello di servizio business critical nella configurazione a due o tre repliche. Gli effetti degli errori e la successiva capacità di ripristino variano per ogni configurazione. Un'istanza con tre repliche offre un livello di disponibilità e ripristino superiore rispetto a un'istanza con due repliche.
In una configurazione con due repliche, quando entrambi gli stati del nodo sono SYNCHRONIZED, se la replica primaria non è più disponibile, la replica secondaria viene automaticamente alzata di livello a primaria. Quando la replica non riuscita diventa disponibile, viene aggiornata con tutte le modifiche in sospeso. Se si verificano problemi di connettività tra le repliche, la replica primaria potrebbe non eseguire il commit di alcuna transazione, perché ogni transazione deve essere sottoposta a commit in entrambe le repliche prima che venga restituito un esito positivo nel database primario.
In una configurazione con tre repliche, una transazione deve eseguire il commit in almeno 2 delle 3 repliche prima di restituire un messaggio di esito positivo all'applicazione. In caso di errore, una delle repliche secondarie viene automaticamente promossa a replica primaria mentre Kubernetes tenta di recuperare la replica non riuscita. Quando la replica diventa disponibile, viene automaticamente unita al gruppo di disponibilità indipendente e le modifiche in sospeso vengono sincronizzate. Se si verificano problemi di connettività tra le repliche e più di 2 repliche non sono sincronizzate, la replica primaria non eseguirà il commit di alcuna transazione.
Nota
È consigliabile distribuire un'Istanza gestita di SQL business critical in una configurazione con tre repliche rispetto a una configurazione con due repliche per ottenere una perdita di dati pressoché nulla.
Per eseguire il failover dalla replica primaria a una secondaria per un evento pianificato, eseguire il comando seguente:
Se ci si connette all'elemento primario, è possibile usare il T-SQL seguente per eseguire il failover dell'istanza di SQL in uno degli elementi secondari:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Se ci si connette all'elemento secondario, è possibile usare il T-SQL seguente per alzare di livello l'elemento secondario desiderato a replica primaria.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Replica primaria preferita
È anche possibile impostare una replica specifica come replica primaria usando l'interfaccia della riga di comando di Azure come indicato di seguito:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Esempio:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Nota
Kubernetes tenterà di impostare la replica preferita, ma l'esito dell'operazione non è garantito.
Ripristino di un database in un'istanza con più repliche
Sono necessari passaggi aggiuntivi per ripristinare un database in un gruppo di disponibilità. La procedura seguente illustra come ripristinare un database in un'istanza gestita e aggiungerlo a un gruppo di disponibilità.
Esporre l'endpoint esterno dell'istanza primaria creando un nuovo servizio Kubernetes.
Determinare il pod che ospita la replica primaria. Connettersi all'istanza gestita e procedere all'esecuzione:
SELECT @@SERVERNAMELa query restituisce il pod che ospita la replica primaria.
Creare il servizio Kubernetes nell'istanza primaria eseguendo il comando seguente se il cluster Kubernetes usa servizi
NodePort. Sostituire<podName>con il nome del server restituito nel passaggio precedente,<serviceName>con il nome preferito per il servizio Kubernetes creato.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortPer un servizio LoadBalancer, eseguire lo stesso comando, ad eccezione del fatto che il tipo del servizio creato è
LoadBalancer. Ad esempio:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerDi seguito è riportato un esempio di questo comando eseguito nel servizio Azure Kubernetes, in cui il pod che ospita l'elemento primario è
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerOttenere l'indirizzo IP del servizio Kubernetes creato:
kubectl get services -n <namespaceName>Ripristinare il database all'endpoint dell'istanza primaria.
Aggiungere il file di backup del database nel contenitore dell'istanza primaria.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Esempio
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcRipristinare il file di backup del database eseguendo il comando seguente.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOEsempio
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOAggiungere il database al gruppo di disponibilità.
Per aggiungere il database al gruppo di disponibilità, il database deve essere eseguito in modalità di recupero con registrazione completa ed è necessario acquisire un backup del log. Eseguire le istruzioni TSQL seguenti per aggiungere il database ripristinato al gruppo di disponibilità.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>L'esempio seguente aggiunge un database denominato
WideWorldImportersche è stato ripristinato nell'istanza:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Importante
Come procedura consigliata, eliminare il servizio Kubernetes creato in precedenza tramite questo comando:
kubectl delete svc sql2-0-p -n arc
Limiti
I gruppi di disponibilità di Istanza gestita di SQL abilitata da Azure Arc presentano le stesse limitazioni dei gruppi di disponibilità del cluster Big Data. Per altre informazioni, vedere Distribuire un cluster Big Data di SQL Server con disponibilità elevata.
Contenuto correlato
Altre informazioni su Caratteristiche e funzionalità di Istanza gestita di SQL abilitata da Azure Arc