L'elaborazione del linguaggio naturale (NLP) include molte applicazioni, ad esempio l'analisi del sentiment, il rilevamento degli argomenti, il rilevamento della lingua, l'estrazione di frasi chiave e la categorizzazione dei documenti.
In particolare, è possibile utilizzare NPL per:
- Classificare i documenti, ad esempio, etichettandoli come sensibili o spam.
- Eseguire operazioni di elaborazione o ricerche successive con output NLP.
- Riepilogare il testo identificando le entità nel documento.
- Contrassegnare i documenti con parole chiave, usando le entità identificate.
- Eseguire ricerche e recupero basati sul contenuto tramite l'assegnazione di tag.
- Riepilogare gli argomenti chiave di un documento usando le entità identificate.
- Classificare i documenti per lo spostamento utilizzando gli argomenti rilevati.
- Enumerare i documenti correlati in base a un argomento selezionato.
- Valutare il sentiment del testo per comprenderne il tono positivo o negativo.
Grazie ai progressi nella tecnologia, la prevenzione della perdita di rete non solo può essere usata per classificare e analizzare i dati di testo, ma anche per migliorare le funzioni di intelligenza artificiale interpretabili in diversi domini. L'integrazione di LLM (Large Language Models) migliora significativamente le funzionalità di NLP. LE MACCHINE VIRTUALI come GPT e BERT possono generare testo simile a quello umano, con riconoscimento contestuale, rendendoli estremamente efficaci per attività complesse di elaborazione del linguaggio. Completano le tecniche NLP esistenti gestendo attività cognitive più ampie, che migliorano i sistemi di conversazione e l'engagement dei clienti, soprattutto con modelli come Dolly 2.0 di Databricks.
Relazione e differenze tra modelli di linguaggio e NLP
NLP è un campo completo che comprende varie tecniche per l'elaborazione del linguaggio umano. Al contrario, i modelli linguistici sono un subset specifico all'interno di NLP, concentrandosi sull'apprendimento avanzato per eseguire attività del linguaggio di alto livello. Anche se i modelli linguistici migliorano la prevenzione della perdita dei dati fornendo funzionalità avanzate di generazione e comprensione del testo, non sono sinonimi di NLP. Servono invece come strumenti potenti all'interno del dominio NLP più ampio, consentendo l'elaborazione del linguaggio più sofisticata.
Nota
Questo articolo è incentrato su NLP. La relazione tra modelli di linguaggio e NLP dimostra che i modelli linguistici migliorano i processi NLP tramite funzionalità superiori di comprensione e generazione del linguaggio.
Apache®, Apache Spark e il logo con la fiamma sono marchi o marchi registrati di Apache Software Foundation negli Stati Uniti e/o in altri Paesi. L'uso di questi marchi non implica alcuna approvazione da parte di Apache Software Foundation.
Potenziali casi d'uso
Gli scenari aziendali che possono trarre vantaggio dalla prevenzione della perdita di rete personalizzata includono:
- Intelligence sui documenti per documenti scritti a mano o creati da computer in finanza, sanità, vendita al dettaglio, governo e altri settori.
- Attività NLP indipendenti dal settore per l'elaborazione del testo, ad esempio il riconoscimento delle entità dei nomi (NER), la classificazione, il riepilogo e l'estrazione delle relazioni. Queste attività automatizzano il processo di recupero, identificazione e analisi delle informazioni sui documenti, ad esempio testo e dati non strutturati. Esempi di queste attività includono modelli di stratificazione dei rischi, classificazione dell'ontologia e riepiloghi delle vendite al dettaglio.
- Recupero delle informazioni e creazione del grafico delle informazioni per la ricerca semantica. Questa funzionalità consente di creare grafici di conoscenze mediche che supportano la scoperta di farmaci e studi clinici.
- Traduzione testuale per sistemi di intelligenza artificiale conversazionale nelle applicazioni rivolte ai clienti in settori retail, finance, travel e altri settori.
- Sentiment e intelligenza emotiva avanzata nell'analisi, in particolare per il monitoraggio della percezione del marchio e dell'analisi dei feedback dei clienti.
- Generazione automatica di report. Sintetizzare e generare report testuali completi da input di dati strutturati, supportando settori come finanza e conformità, dove è necessaria una documentazione completa.
- Interfacce attivate dalla voce per migliorare le interazioni utente nelle applicazioni IoT e smart device integrando NLP per il riconoscimento vocale e le funzionalità di conversazione naturale.
- Modelli linguistici adattivi per regolare dinamicamente l'output della lingua in base ai vari livelli di comprensione del pubblico, che è fondamentale per i miglioramenti del contenuto didattico e dell'accessibilità.
- Analisi del testo della cybersecurity per analizzare i modelli di comunicazione e l'utilizzo della lingua in tempo reale per identificare potenziali minacce alla sicurezza nella comunicazione digitale, migliorando il rilevamento dei tentativi di phishing o delle disinformazioni.
Apache Spark come framework NLP personalizzato
Apache Spark è un potente framework di elaborazione parallela che migliora le prestazioni delle applicazioni analitiche di Big Data tramite l'elaborazione in memoria. Azure Synapse Analytics, Azure HDInsighte Azure Databricks continuare a fornire un accesso affidabile alle funzionalità di elaborazione di Spark, garantendo un'esecuzione senza problemi di operazioni sui dati su larga scala.
Per i carichi di lavoro NLP personalizzati, Spark NLP rimane un framework efficiente in grado di elaborare grandi volumi di testo. Questa libreria open source offre funzionalità complete tramite le librerie Python, Java e Scala, che offrono la sofisticatezza trovata nelle principali librerie NLP, ad esempio spaCy e NLTK. Spark NLP include funzionalità avanzate come il controllo ortografico, l'analisi del sentiment e la classificazione dei documenti, garantendo in modo coerente l'accuratezza e la scalabilità all'avanguardia.
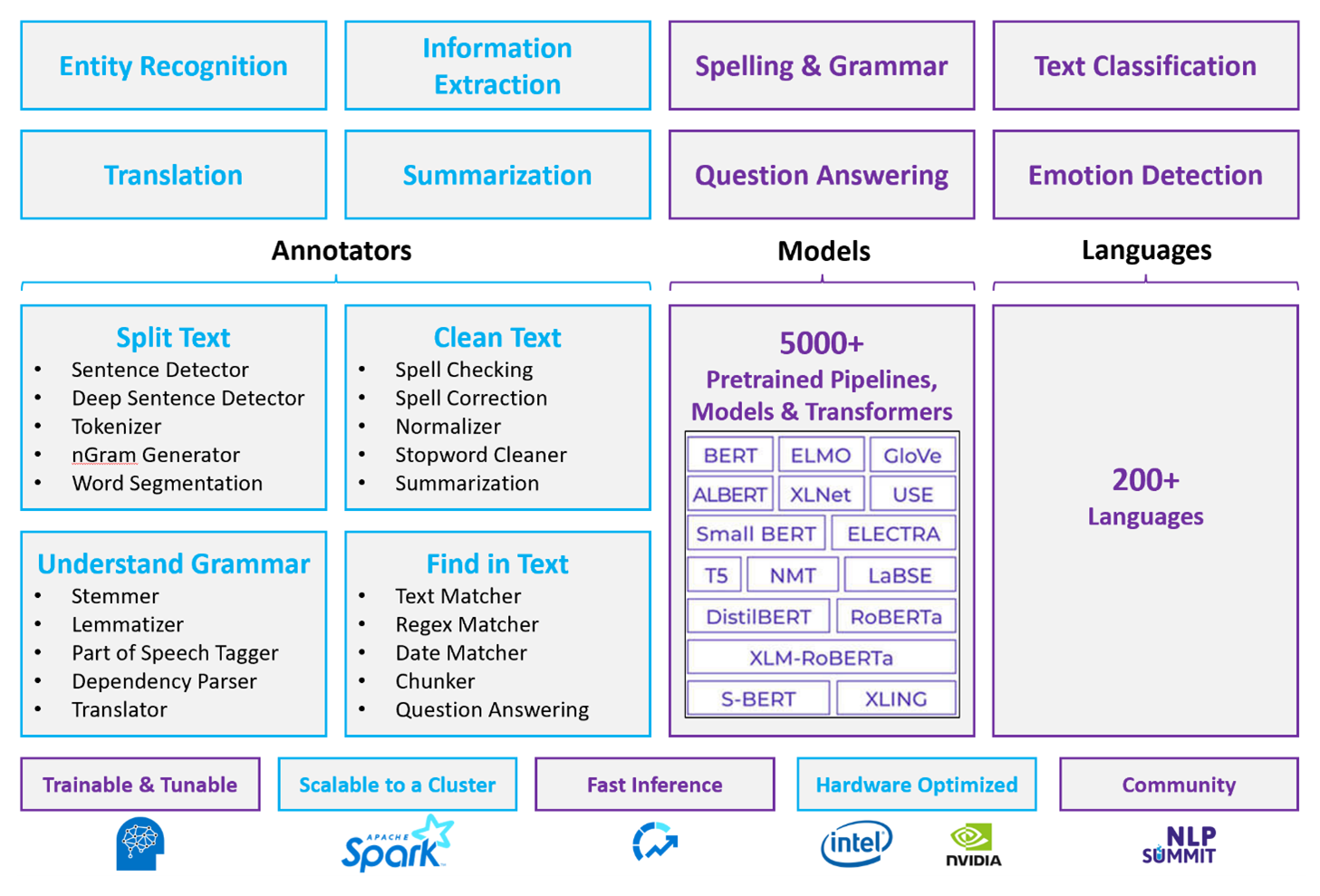
I benchmark pubblici recenti evidenziano le prestazioni di Spark NLP, mostrando miglioramenti significativi della velocità rispetto ad altre librerie mantenendo al contempo un'accuratezza paragonabile per il training di modelli personalizzati. In particolare, l'integrazione dei modelli Llama-2 e OpenAI Whisper migliora le interfacce conversazionali e il riconoscimento vocale multilingue, segnando passi significativi nelle funzionalità di elaborazione ottimizzate.
In modo univoco, Spark NLP usa in modo efficace un cluster Spark distribuito, che funziona come estensione nativa di Spark ML che opera direttamente nei frame di dati. Questa integrazione supporta miglioramenti delle prestazioni nei cluster, semplificando la creazione di pipeline di NLP e Machine Learning unificate per attività quali la classificazione dei documenti e la stima dei rischi. L'introduzione di incorporamenti MPNet e un ampio supporto ONNX arricchiscono ulteriormente queste funzionalità, consentendo un'elaborazione precisa e compatibile con il contesto.
Oltre ai vantaggi delle prestazioni, Spark NLP offre una precisione all'avanguardia in un'ampia gamma di attività NLP. La raccolta include modelli di Deep Learning predefiniti per il riconoscimento di entità denominate, la classificazione dei documenti, il rilevamento del sentiment e altro ancora. La progettazione avanzata delle funzionalità include modelli linguistici con training preliminare che supportano incorporamenti di parole, blocchi, frasi e documenti.
Con build ottimizzate per CPU, GPU e chip Intel Xeon più recenti, l'infrastruttura di Spark NLP è progettata per la scalabilità, consentendo ai processi di training e inferenza di usare completamente i cluster Spark. In questo modo si garantisce una gestione efficiente delle attività NLP in diversi ambienti e applicazioni, mantenendo la propria posizione all'avanguardia dell'innovazione NLP.
Problematiche
Risorse di elaborazione: l'elaborazione di una raccolta di documenti di testo in formato libero richiede una quantità significativa di risorse di calcolo e l'elaborazione richiede tempi elevati. Questo tipo di elaborazione comporta spesso la distribuzione di calcolo GPU. Miglioramenti recenti, ad esempio ottimizzazioni nelle architetture spark NLP come Llama-2 che supportano la quantizzazione, consentono di semplificare queste attività intensive, rendendo più efficiente l'allocazione delle risorse.
problemi di standardizzazione: Senza un formato documento standardizzato, può essere difficile ottenere risultati coerenti quando si utilizza l'elaborazione di testo in formato libero per estrarre fatti specifici da un documento. Ad esempio, l'estrazione del numero e della data della fattura da varie fatture comporta problemi. L'integrazione di modelli NLP adattabili come M2M100 migliora l'accuratezza dell'elaborazione in più linguaggi e formati, semplificando una maggiore coerenza nei risultati.
Varietà e complessità dei dati: Affrontare la varietà di strutture di documenti e sfumature linguistiche rimane complessa. Le innovazioni come gli incorporamenti MPNet offrono una migliore comprensione contestuale, offrendo una gestione più intuitiva di formati testuali diversi e migliorando l'affidabilità complessiva dell'elaborazione dei dati.
Criteri di scelta principali
In Azure, i servizi Spark come Azure Databricks, Microsoft Fabric e Azure HDInsight offrono funzionalità NLP quando vengono usate con Spark NLP. I servizi di intelligenza artificiale di Azure sono un'altra opzione per la funzionalità NLP. Per decidere quale servizio utilizzare, considerare le seguenti domande:
Si desidera usare modelli predefiniti? In caso affermativo, è consigliabile usare le API offerte dai servizi di intelligenza artificiale di Azure o scaricare il modello preferito tramite Spark NLP, che ora include modelli avanzati come Llama-2 e MPNet per funzionalità avanzate.
È necessario eseguire il training di modelli personalizzati con una raccolta di grandi dimensioni di dati di testo? In caso affermativo, prendere in considerazione l'uso di Azure Databricks, Microsoft Fabric o Azure HDInsight con Spark NLP. Queste piattaforme offrono la potenza di calcolo e la flessibilità necessarie per il training completo del modello.
Sono necessarie funzionalità di elaborazione del linguaggio naturale di base, quali tokenizzazione, stemming, lemmatizzazione e frequenza del termine/frequenza inversa del documento (TF/IDF)? In caso affermativo, prendere in considerazione l'uso di Azure Databricks, Microsoft Fabric o Azure HDInsight con Spark NLP. In alternativa, usare una libreria software open source nello strumento di elaborazione preferito.
Sono necessarie funzionalità di elaborazione del linguaggio naturale avanzate, quali identificazione di entità e finalità, rilevamento dell'argomento, controllo ortografico o analisi del sentiment? In caso affermativo, prendere in considerazione l'uso delle API offerte dai servizi di intelligenza artificiale di Azure. In alternativa, scaricare il modello preferito tramite Spark NLP per sfruttare le funzioni predefinite per queste attività.
Matrice delle funzionalità
Le tabelle seguenti riassumono le principali differenze nelle capacità dei servizi di PNL.
Funzionalità generali
| Funzionalità | Servizio Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) con Spark NLP | Servizi di Azure AI |
|---|---|---|
| Fornisce modelli sottoposti a training come servizio | Sì | Sì |
| REST API | Sì | Sì |
| Programmabilità | Python Scala | Per sapere quali lingue sono supportate, vedere Ulteriori risorse. |
| Supporta l'elaborazione di set di Big Data e documenti di grandi dimensioni | Sì | No |
Funzionalità NLP di basso livello
Funzionalità di annotatori
| Funzionalità | Servizio Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) con Spark NLP | Servizi di Azure AI |
|---|---|---|
| Rilevamento frasi | Sì | No |
| Rilevamento frasi profonde | Sì | Sì |
| Tokenizer | Sì | Sì |
| Generatore N-gram | Sì | No |
| Segmentazione delle parole | Sì | Sì |
| Stemmer | Sì | No |
| Lemmatizer | Sì | No |
| Tag delle parti del discorso | Sì | No |
| Parser delle dipendenze | Sì | No |
| Traduzione | Sì | No |
| Pulitura parola non significative | Sì | No |
| Correzione dell'ortografia | Sì | No |
| Normalizer | Sì | Sì |
| Matcher di testo | Sì | No |
| TF/IDF | Sì | No |
| Corrisponde all'espressione regolare | Sì | Incorporato in Conversational Language Understanding (CLU) |
| Matcher data | Sì | Possibile in CLU tramite riconoscitori DateTime |
| Chunker | Sì | No |
Nota
Microsoft Language Understanding (LUIS) verrà ritirato il 1° ottobre 2025. Le applicazioni LUIS esistenti sono incoraggiate a eseguire la migrazione a Conversational Language Understanding (CLU), una funzionalità di Servizi di intelligenza artificiale di Azure per il linguaggio, che migliora le funzionalità di comprensione del linguaggio e offre nuove funzionalità.
Funzionalità NLP di alto livello
| Funzionalità | Servizio Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) con Spark NLP | Servizi di Azure AI |
|---|---|---|
| Controllo ortografia | Sì | No |
| Riepilogo | Sì | Sì |
| Risposta alle domande | Sì | Sì |
| Rilevamento del sentiment | Sì | Sì |
| Rilevamento delle emozioni | Sì | Supporta il opinion mining |
| Classificazione dei token | Sì | Sì, tramite modelli personalizzati |
| Classificazione testo | Sì | Sì, tramite modelli personalizzati |
| Rappresentazione di testo | Sì | No |
| NERE | Sì | Sì: l'analisi del testo fornisce un set di modelli NER e i modelli personalizzati sono nel riconoscimento delle entità |
| Riconoscimento delle entità | Sì | Sì, tramite modelli personalizzati |
| Rilevamento lingua | Sì | Sì |
| Supporto altre lingue oltre all'inglese | Sì, supporta più di 200 lingue | Sì, supporta più di 97 lingue |
Configurare Spark NLP in Azure
Per installare Spark NLP, usare il codice seguente, ma sostituire <version> con il numero di versione più recente. Per altre informazioni, vedere la documentazione Spark NPL.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Sviluppa pipeline NLP
Per l'ordine di esecuzione di una pipeline NLP, Spark NLP segue lo stesso concetto di sviluppo dei modelli di Machine Learning Spark ML tradizionali, applicando tecniche di NLP specializzate.
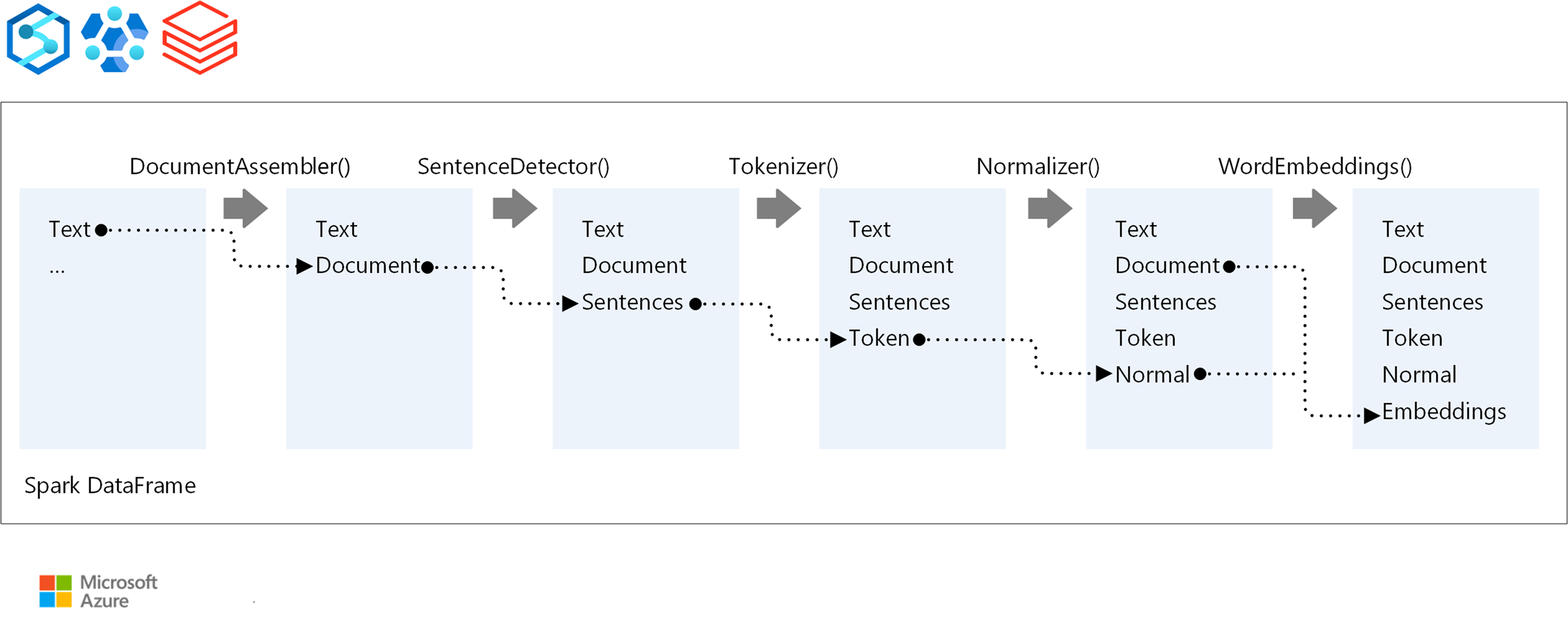
I componenti principali di una pipeline spark NLP sono:
DocumentAssembler: trasformatore che prepara i dati convertendoli in un formato che spark NLP può elaborare. Questa fase è il punto di ingresso per ogni pipeline spark NLP. DocumentAssembler legge una colonna
Stringo unArray[String], con opzioni per pre-elaborare il testo usandosetCleanupMode, che è disattivato per impostazione predefinita.SentenceDetector: annotazione che identifica i limiti delle frasi usando approcci predefiniti. Può restituire ogni frase rilevata in un
Arrayo in righe separate quandoexplodeSentencesè impostato su true.Tokenizer: un annotatore che divide il testo non elaborato in token discreti, ovvero parole, numeri e simboli, che reputa come
TokenizedSentence. Il tokenizer non è adattato e usa la configurazione di input all'interno delRuleFactoryper creare regole di tokenizzazione. È possibile aggiungere regole personalizzate quando le impostazioni predefinite non sono sufficienti.Normalizer: un annotatore con attività di affinamento dei token. Normalizer applica espressioni regolari e trasformazioni del dizionario per pulire il testo e rimuovere caratteri estranei.
WordEmbeddings: annotatori di ricerca che eseguono il mapping dei token a vettori, semplificando l'elaborazione semantica. È possibile specificare un dizionario di incorporamento personalizzato usando
setStoragePath, dove ogni riga contiene un token e il relativo vettore, separati da spazi. I token non risolti per impostazione predefinita sono zero vettori.
Spark NLP sfrutta le pipeline Spark MLlib, con il supporto nativo di MLflow, una piattaforma open source che gestisce il ciclo di vita di Machine Learning. I componenti chiave di MLflow includono:
MLflow Tracking: registra le esecuzioni sperimentali e offre solide funzionalità di query per l'analisi dei risultati.
progetti MLflow: consente l'esecuzione di codice di data science su piattaforme diverse, migliorando la portabilità e la riproducibilità.
modelli MLflow: supporta la distribuzione di modelli versatili in ambienti diversi tramite un framework coerente.
modello registro: offre una gestione completa dei modelli, l'archiviazione centralizzata delle versioni per semplificare l'accesso e la distribuzione, semplificando l'idoneità alla produzione.
MLflow è integrato con piattaforme come Azure Databricks, ma può anche essere installato in altri ambienti basati su Spark per gestire e tenere traccia degli esperimenti. Questa integrazione consente l'uso del Registro modelli MLflow per rendere disponibili i modelli a scopo di produzione, semplificando così il processo di distribuzione e mantenendo la governance del modello.
Usando MLflow insieme a Spark NLP, è possibile garantire una gestione efficiente e la distribuzione delle pipeline NLP, risolvendo i requisiti moderni per la scalabilità e l'integrazione, supportando tecniche avanzate come incorporamenti di parole e adattamenti di modelli linguistici di grandi dimensioni.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Freddy Ayala | Cloud Solution Architect
- Merge Steller | Senior Cloud Solution Architect
Passaggi successivi
Documentazione di Spark NPL:
Componenti di Azure:
Informazioni sulle risorse:
Risorse correlate
- Scegliere una tecnologia per i servizi di Microsoft Azure AI
- Confrontare i prodotti e le tecnologie di apprendimento automatico di Microsoft
- MLflow e Azure Machine Learning
- Arricchimento tramite intelligenza artificiale con elaborazione di immagini e linguaggio naturale in Ricerca cognitiva di Azure