Distribuzione e test per carichi di lavoro cruciali in Azure
La distribuzione e il test dell'ambiente mission critical sono un elemento fondamentale dell'architettura di riferimento complessiva. I singoli stampi dell'applicazione vengono distribuiti usando l'infrastruttura come codice da un repository di codice sorgente. Gli aggiornamenti all'infrastruttura e l'applicazione in primo piano devono essere distribuiti senza tempi di inattività per l'applicazione. È consigliabile usare una pipeline di integrazione continua DevOps per recuperare il codice sorgente dal repository e distribuire i singoli timbri in Azure.
La distribuzione e gli aggiornamenti sono il processo centrale nell'architettura. Gli aggiornamenti correlati all'infrastruttura e alle applicazioni devono essere distribuiti su unità completamente indipendenti. Solo i componenti dell'infrastruttura globale nell'architettura vengono condivisi tra i francobolli. I francobolli esistenti nell'infrastruttura non vengono toccati. Gli aggiornamenti dell'infrastruttura vengono distribuiti in questi nuovi francobolli. Analogamente, le nuove versioni dell'applicazione vengono distribuite in questi nuovi francobolli.
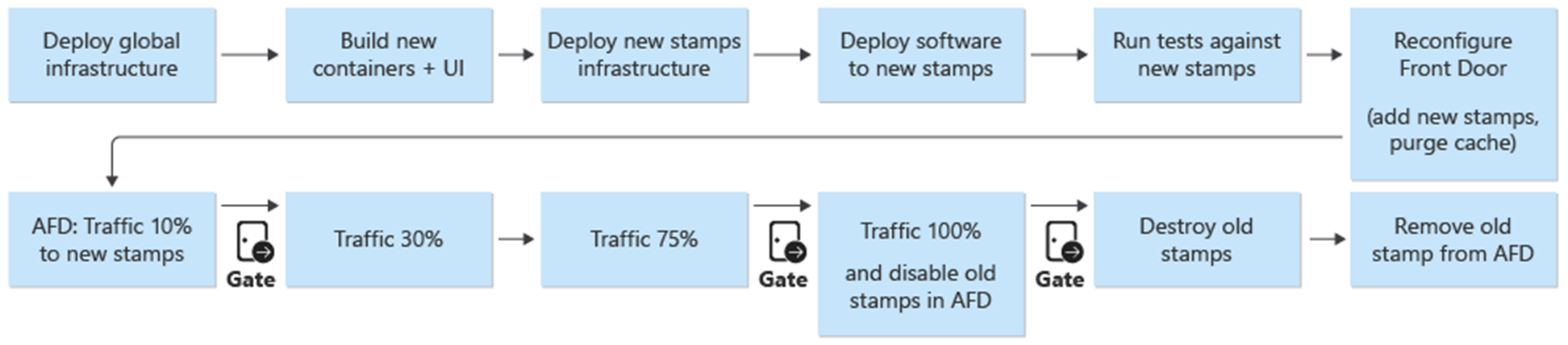
I nuovi francobolli vengono aggiunti a Frontdoor di Azure. Il traffico viene gradualmente spostato verso i nuovi francobolli. Quando il traffico viene servito dai nuovi francobolli senza problemi, i francobolli precedenti vengono eliminati.
I test di penetrazione, caos e stress sono consigliati per l'ambiente distribuito. Il test proattivo dell'infrastruttura rileva i punti deboli e il comportamento dell'applicazione distribuita in caso di errore.
Distribuzione
La distribuzione dell'infrastruttura nell'architettura di riferimento dipende dai processi e dai componenti seguenti:
DevOps: il codice sorgente di GitHub e le pipeline per l'infrastruttura.
Aggiornamenti senza interruzione: gli aggiornamenti e upgrade vengono distribuiti nell'ambiente senza interruzioni per l'applicazione distribuita.
Ambienti: ambienti di breve durata e permanenti utilizzati per l'architettura.
Risorse condivise e dedicate: risorse di Azure dedicate e condivise ai francobolli e all'infrastruttura complessiva.
Per altre informazioni, vedere Distribuzione e test per carichi di lavoro cruciali in Azure: Considerazioni sulla progettazione
Distribuzione: DevOps
I componenti DevOps forniscono il repository del codice sorgente e le pipeline CI/CD per la distribuzione dell'infrastruttura e degli aggiornamenti. GitHub e Azure Pipelines sono stati scelti come componenti.
GitHub: contiene i repository di codice sorgente per l'applicazione e l'infrastruttura.
di Azure Pipelines: le pipeline usate dall'architettura per tutte le attività di compilazione, test e rilascio.
Un componente aggiuntivo nella progettazione usata per la distribuzione è costituito dagli agenti di compilazione. Gli agenti di compilazione ospitati da Microsoft vengono usati come parte di Azure Pipelines per distribuire l'infrastruttura e gli aggiornamenti. L'uso degli agenti di compilazione ospitati da Microsoft elimina il carico di gestione per gli sviluppatori per gestire e aggiornare l'agente di compilazione.
Per altre informazioni su Azure Pipelines, vedere Che cos'è Azure Pipelines?.

Per altre informazioni, vedere Distribuzione e test di per carichi di lavoro cruciali in Azure: Distribuzioni di infrastruttura come codice
Distribuzione: aggiornamenti senza tempi di inattività
La strategia di aggiornamento senza tempi di inattività nell'architettura di riferimento è fondamentale per l'applicazione mission critical complessiva. La metodologia di sostituzione anziché l'aggiornamento dei francobolli garantisce una nuova installazione dell'applicazione in un timbro dell'infrastruttura. L'architettura di riferimento usa un approccio blu/verde e consente ambienti di test e sviluppo separati.
Esistono due componenti principali dell'architettura di riferimento:
Infrastruttura - servizi e risorse di Azure. Distribuito utilizzando Terraform e la sua configurazione associata.
Applicazione - Servizio o applicazione ospitato che serve gli utenti. In base ai contenitori Docker e agli artefatti creati da npm in HTML e JavaScript per l'interfaccia utente dell'applicazione a pagina singola.
In molti sistemi si presuppone che gli aggiornamenti delle applicazioni siano più frequenti rispetto agli aggiornamenti dell'infrastruttura. Di conseguenza, vengono sviluppate diverse procedure di aggiornamento per ognuna di esse. Con un'infrastruttura cloud pubblica, le modifiche possono verificarsi a un ritmo più rapido. È stato scelto un processo di distribuzione per gli aggiornamenti dell'applicazione e gli aggiornamenti dell'infrastruttura. Un approccio garantisce che gli aggiornamenti dell'infrastruttura e delle applicazioni siano sempre sincronizzati. Questo approccio consente di:
Un processo coerente: meno probabilità di errori se gli aggiornamenti dell'infrastruttura e dell'applicazione vengono combinati insieme in una versione, intenzionalmente o meno.
Abilita la distribuzione blu/verde: ogni aggiornamento viene distribuito usando una migrazione graduale del traffico alla nuova versione.
Distribuzione e debug più semplici dell'applicazione: l'intero ambiente non ospita mai più versioni dell'applicazione affiancate.
Semplice rollback - Il traffico può essere riportato alle versioni che eseguono la precedente release se si incontrano errori o problemi.
Eliminazione di modifiche manuali e deviazione della configurazione: ogni ambiente è una nuova distribuzione.
Per altre informazioni, vedere distribuzione e test di per carichi di lavoro cruciali in Azure: distribuzioni temporanee blu/verde
Strategia di diramazione
La base della strategia di aggiornamento è l'uso di rami all'interno del repository Git. L'architettura di riferimento usa tre tipi di rami:
| Ramo | Descrizione |
|---|---|
feature/* e fix/* |
Punti di ingresso per qualsiasi modifica. Gli sviluppatori creano questi rami e devono avere un nome descrittivo, ad esempio feature/catalog-update o fix/worker-timeout-bug. Quando le modifiche sono pronte per essere unite, viene creata una pull request per il ramo main. Almeno un revisore deve approvare tutte le richieste di pull. Con eccezioni limitate, ogni modifica proposta in un pull request deve passare attraverso la pipeline di convalida end-to-end (E2E). Gli sviluppatori devono usare la pipeline E2E per testare ed eseguire il debug delle modifiche in un ambiente completo. |
main |
Ramo in continua evoluzione e stabile. Usato principalmente per i test di integrazione. Le modifiche apportate alle main vengono apportate solo tramite richieste pull. Una politica di ramo proibisce scritture dirette. Le build notturne nell'ambiente permanente integration (int) vengono eseguite automaticamente dal branch main. Il ramo main è considerato stabile. Dovrebbe essere sicuro presupporre che in qualsiasi momento una release può essere creata da esso. |
release/* |
I rami di rilascio vengono creati solo dal ramo main. I rami seguono il formato release/2021.7.X. Le politiche di ramo vengono usate in modo che solo gli amministratori del repository siano autorizzati a creare branch release/*. Solo questi rami vengono usati per la distribuzione nell'ambiente prod. |
Per altre informazioni, vedere Distribuzione e test per carichi di lavoro cruciali in Azure: Strategia di diramazione
Hotfixes
Quando è necessario un hotfix urgente a causa di un bug o di un altro problema e non può eseguire il normale processo di rilascio, è disponibile un percorso hotfix. Gli aggiornamenti critici della sicurezza e le correzioni all'esperienza utente che non sono stati individuati durante i test iniziali sono considerati esempi validi di hotfix.
L'hotfix deve essere creato in un nuovo ramo di fix e quindi fuso in main usando un pull request normale. Invece di creare un nuovo ramo di versione, l'hotfix viene scelto selettivamente in un ramo di versione esistente. Questo ramo è già stato distribuito nell'ambiente prod. La pipeline CI/CD che ha originariamente distribuito il ramo di rilascio con tutti i test viene eseguita di nuovo e distribuisce l'hotfix come parte della pipeline.
Per evitare problemi principali, è importante che l'hotfix contenga alcuni commit isolati che possono essere facilmente scelti e integrati nel ramo di rilascio. Se non è possibile selezionare commit isolati per l'integrazione nel ramo di versione, è un'indicazione che la modifica non è idonea come hotfix. Distribuire la modifica come nuova versione completa. Combinalo con un rollback a una versione stabile precedente fino a quando non sarà possibile rilasciare la nuova versione.
Distribuzione: ambienti
L'architettura di riferimento usa due tipi di ambienti per l'infrastruttura:
di breve durata: la pipeline di convalida E2E viene usata per distribuire ambienti di breve durata. Gli ambienti di breve durata vengono usati per ambienti di convalida o debug puri per gli sviluppatori. Gli ambienti di convalida possono essere creati dal ramo
feature/*, sottoposti a test e quindi eliminati se tutti i test hanno avuto esito positivo. Gli ambienti di debug vengono distribuiti nello stesso modo della convalida, ma non vengono eliminati immediatamente. Questi ambienti non devono esistere per più di qualche giorno e devono essere eliminati quando viene effettuato il merge della PR del feature branch corrispondente.permanente: negli ambienti permanenti sono presenti versioni
integration (int)eproduction (prod). Questi ambienti vivono continuamente e non vengono distrutti. Gli ambienti usano nomi di dominio fissi comeint.mission-critical.app. In un'implementazione reale dell'architettura di riferimento, è necessario aggiungere un ambientestaging(preprod). L'ambientestagingviene usato per distribuire e convalidare i ramireleasecon lo stesso processo di aggiornamento diprod(distribuzione Blu/Verde).Integration (int): la versione
intviene distribuita di notte dal ramomaincon lo stesso processo diprod. Il passaggio del traffico è più veloce rispetto all'unità di rilascio precedente. Invece di passare gradualmente il traffico in più giorni, come inprod, il processo perintsi completa entro pochi minuti o ore. Questo cambio più rapido garantisce che l'ambiente aggiornato sia pronto entro la mattina successiva. I vecchi francobolli vengono eliminati automaticamente se tutti i test nella pipeline risultano positivi.Production (prod): la versione
prodviene distribuita solo dalle branche direlease/*. Il passaggio del traffico utilizza procedure più granulari. Un gate di approvazione manuale è compreso tra ogni passaggio. Ogni versione crea nuovi francobolli regionali e distribuisce la nuova versione dell'applicazione ai francobolli. I francobolli esistenti non vengono toccati nel processo. La considerazione più importante perprodè che deve essere "always on". Non dovrebbero mai verificarsi tempi di inattività pianificati o non pianificati. L'unica eccezione è rappresentato dalle modifiche fondamentali apportate al livello del database. Potrebbe essere necessaria una finestra di manutenzione pianificata.
Distribuzione: risorse condivise e dedicate
Gli ambienti permanenti (int e prod) all'interno dell'architettura di riferimento hanno tipi di risorse diversi a seconda che siano condivisi con l'intera infrastruttura o dedicati a un singolo timbro. Le risorse possono essere dedicate a una versione specifica ed esistono solo fino a quando l'unità di rilascio successiva non assume il controllo.
Unità di rilascio
Un'unità di rilascio è costituita da diversi marchi regionali per ogni versione di rilascio specifica. Gli stamp contengono tutte le risorse che non sono condivise con gli altri francobolli. Queste risorse sono reti virtuali, cluster del servizio Azure Kubernetes, Hub eventi e Azure Key Vault. Azure Cosmos DB e ACR sono configurati con le origini dati di Terraform.
Risorse condivise a livello globale
Tutte le risorse condivise tra le unità di rilascio vengono definite in un modello Terraform indipendente. Queste risorse sono Frontdoor, Azure Cosmos DB, Registro Container e le aree di lavoro Log Analytics e altre risorse correlate al monitoraggio. Queste risorse vengono distribuite prima della distribuzione del primo timbro a livello di area di un'unità di rilascio. Le risorse cui si fa riferimento nei modelli Terraform per le stampe.
Porta d'ingresso
Anche se Frontdoor è una risorsa condivisa a livello globale tra timbri, la configurazione è leggermente diversa rispetto alle altre risorse globali. Frontdoor deve essere riconfigurato dopo la distribuzione di un nuovo stamp. Frontdoor deve essere riconfigurato per passare gradualmente al traffico verso i nuovi francobolli.
La configurazione back-end di Frontdoor non può essere definita direttamente nel modello Terraform. La configurazione viene inserita con le variabili Terraform. I valori delle variabili vengono costruiti prima dell'avvio della distribuzione di Terraform.
La configurazione dei singoli componenti per la distribuzione di Frontdoor è definita come:
Frontend - L'affinità della sessione è configurata per garantire che gli utenti non passino a versioni diverse dell'interfaccia utente durante una singola sessione.
Origini - La porta d'ingresso è configurata con due tipi di gruppi di origine:
Gruppo di origine per l'archiviazione statica che serve l'interfaccia utente. Il gruppo contiene gli account di archiviazione del sito Web da tutte le unità di rilascio attualmente attive. È possibile assegnare pesi diversi alle origini di diverse unità di rilascio per spostare gradualmente il traffico in un'unità più recente. A ogni origine di un'unità di rilascio deve essere assegnato lo stesso peso.
Un gruppo di origine per l'API, ospitato nel servizio Azure Kubernetes. Se sono presenti unità di rilascio con versioni API diverse, esiste un gruppo di origine API per ogni unità di rilascio. Se tutte le unità di versione offrono la stessa API compatibile, tutte le origini vengono aggiunte allo stesso gruppo e assegnate pesi diversi.
regole di routing: esistono due tipi di regole di routing:
Regola di routing per l'interfaccia utente collegata al gruppo di origine di archiviazione dell'interfaccia utente.
Regola di routing per ogni API attualmente supportata dalle origini. Ad esempio:
/api/1.0/*e/api/2.0/*.
Se una versione introduce una nuova versione delle API back-end, le modifiche riflettono nell'interfaccia utente distribuita come parte della versione. Una versione specifica dell'interfaccia utente chiama sempre una versione specifica dell'URL dell'API. Gli utenti serviti da una versione dell'interfaccia utente usano automaticamente l'API back-end corrispondente. Sono necessarie regole di routing specifiche per diverse istanze della versione dell'API. Queste regole sono collegate ai gruppi di origine corrispondenti. Se non è stata introdotta una nuova API, tutte le regole di routing correlate all'API sono collegate al gruppo di origine singolo. In questo caso, non importa se un utente viene servito dall'interfaccia utente da una versione diversa rispetto all'API.
Distribuzione: processo di distribuzione
Una distribuzione blu/verde è l'obiettivo del processo di distribuzione. Una nuova versione dal branch release/* è distribuita nell'ambiente prod. Il traffico utente viene gradualmente spostato agli indicatori per la nuova versione.
Come primo passaggio del processo di distribuzione di una nuova versione, l'infrastruttura per la nuova unità di rilascio viene distribuita con Terraform. L'esecuzione della pipeline di distribuzione dell'infrastruttura distribuisce la nuova infrastruttura da un ramo di versione selezionato. In parallelo al provisioning dell'infrastruttura, le immagini dei container vengono create o importate e inviate al registro dei container globale condiviso. Al termine dei processi precedenti, l'applicazione viene distribuita nei francobolli. Dal punto di vista dell'implementazione, si tratta di una pipeline con più fasi dipendenti. È possibile rieseguire la stessa pipeline per le distribuzioni di correzioni urgenti.
Dopo aver distribuito e convalidato la nuova unità di rilascio, la nuova unità viene aggiunta a Frontdoor per ricevere il traffico utente.
È necessario pianificare un commutatore/parametro che distingue tra le versioni che eseguono e non introducono una nuova versione dell'API. In base a se la versione introduce una nuova versione dell'API, è necessario creare un nuovo gruppo di origine con i back-end dell'API. In alternativa, è possibile aggiungere nuovi back-end API a un gruppo di origine esistente. I nuovi account di archiviazione dell'interfaccia utente vengono aggiunti al gruppo di origine esistente corrispondente. I pesi per le nuove origini devono essere impostati in base alla divisione del traffico desiderata. È necessario creare una nuova regola di routing come descritto in precedenza che corrisponde al gruppo di origine appropriato.
Come parte dell'aggiunta della nuova unità di rilascio, i pesi delle nuove origini devono essere impostati sul traffico utente minimo desiderato. Se non vengono rilevati problemi, la quantità di traffico utente deve essere aumentata al nuovo gruppo di origine in un periodo di tempo. Per regolare i parametri di peso, è necessario eseguire di nuovo gli stessi passaggi di distribuzione con i valori desiderati.
Smontaggio dell'unità di rilascio
Come parte della pipeline di distribuzione per un'unità di rilascio, esiste una fase di eliminazione definitiva che rimuove tutti i timbri una volta che un'unità di rilascio non è più necessaria. Tutto il traffico viene spostato in una nuova versione di rilascio. Questa fase include la rimozione dei riferimenti alle unità di rilascio da Frontdoor. Questa rimozione è fondamentale per abilitare il rilascio di una nuova versione in una data successiva. Front Door deve puntare a una singola unità di rilascio per essere pronta per la versione successiva.
Liste di controllo
Nell'ambito della cadenza di rilascio, è consigliabile usare un elenco di controllo pre e post rilascio. L'esempio seguente è costituito da elementi che devono trovarsi almeno in qualsiasi elenco di controllo.
elenco di controllo del pre-rilascio - Prima di avviare un rilascio, verificare quanto segue:
Verificare che lo stato più recente del ramo
mainsia stato distribuito correttamente e testato nell'ambienteint.Aggiorna il file del registro delle modifiche tramite una pull request verso il ramo
main.Creare un ramo
release/dal ramomain.
Elenco di Controllo Post-Rilascio - Prima che i vecchi francobolli siano distrutti e i relativi riferimenti vengano rimossi da Front Door, verificare che:
I cluster non ricevono più traffico in ingresso.
I "Event Hubs" e altre code di messaggi non contengono messaggi non elaborati.
Distribuzione: limitazioni e rischi della strategia di aggiornamento
La strategia di aggiornamento descritta in questa architettura di riferimento presenta alcune limitazioni e rischi da menzionare:
Costo più elevato: quando si rilasciano gli aggiornamenti, molti dei componenti dell'infrastruttura sono attivi due volte per il periodo di rilascio.
Complessità di Frontdoor: il processo di aggiornamento in Frontdoor è complesso da implementare e gestire. La possibilità di eseguire distribuzioni blu/verde efficaci con tempo di inattività zero dipende dal corretto funzionamento.
Piccole modifiche che richiedono molto tempo: il processo di aggiornamento comporta un processo di rilascio più lungo per piccole modifiche. Questa limitazione può essere parzialmente attenuata con il processo hotfix descritto nella sezione precedente.
Distribuzione: Considerazioni sulla compatibilità futura dei dati delle applicazioni
La strategia di aggiornamento può supportare più versioni di un'API e componenti di lavoro in esecuzione simultaneamente. Poiché Azure Cosmos DB è condiviso tra due o più versioni, è possibile che gli elementi dati modificati da una versione non corrispondano sempre alla versione dell'API o dei ruoli di lavoro che lo usano. I livelli API e i processi devono implementare la progettazione della compatibilità futura. Le versioni precedenti dell'API o dei componenti di lavoro elaborano i dati inseriti da una versione successiva dell'API o del componente di lavoro. Ignora le parti che non capisce.
Collaudo
L'architettura di riferimento contiene test diversi usati in diverse fasi all'interno dell'implementazione del test.
Questi test includono:
unit test: questi test verificano che la logica di business dell'applicazione funzioni come previsto. L'architettura di riferimento contiene una suite di unit test di esempio eseguita automaticamente prima di ogni compilazione di contenitori da Azure Pipelines. Se un test ha esito negativo, la pipeline si arresta. La compilazione e la distribuzione si arrestano. Lo sviluppatore deve risolvere il problema prima che la pipeline possa essere eseguita di nuovo.
Test di Carico: Questi test consentono di valutare la capacità, la scalabilità e i potenziali colli di bottiglia per un determinato carico di lavoro o stack. L'implementazione di riferimento contiene un generatore di carico utente per creare modelli di carico sintetici che possono essere usati per simulare il traffico reale. Il generatore di carico può anche essere usato indipendentemente dall'implementazione di riferimento.
Test di fumo: Questi test identificano se l'infrastruttura e il carico di lavoro siano disponibili e funzionino come previsto. I test di fumo vengono eseguiti come parte di ogni rilascio.
test dell'interfaccia utente: questi test verificano che l'interfaccia utente sia stata distribuita e funzioni come previsto. L'implementazione corrente acquisisce solo screenshot di diverse pagine dopo la distribuzione senza alcun test effettivo.
test di inserimento degli errori: questi test possono essere automatizzati o eseguiti manualmente. I test automatizzati nell'architettura integrano Azure Chaos Studio come parte delle pipeline di distribuzione.
Per altre informazioni, vedere Distribuzione e test per carichi di lavoro cruciali in Azure: convalida e test continui
Test: framework
L'implementazione di riferimento online utilizza le capacità di test e i framework esistenti ogni volta che è possibile.
| Struttura | Prova | Descrizione |
|---|---|---|
| NUnit | Unità | Questo framework viene utilizzato per il test unitario della parte dell'implementazione .NET Core. Azure Pipelines esegue automaticamente unit test prima delle compilazioni dei contenitori. |
| JMeter con test di carico di Azure | Caricamento | Azure Load Testing è un servizio gestito usato per eseguire definizioni di test di carico di Apache JMeter. |
| Locusta | Caricamento | Locust è un framework di test di carico open source scritto in Python. |
| drammaturgo | Interfaccia utente e fumo | Playwright è una libreria open source Node.js per automatizzare Chromium, Firefox e WebKit con una singola API. La definizione di test Playwright può essere usata anche indipendentemente dall'implementazione di riferimento. |
| Azure Chaos Studio | Inserimento di errori | L'implementazione di riferimento usa Azure Chaos Studio come passaggio facoltativo nella pipeline di convalida E2E per inserire errori per la convalida della resilienza. |
Test: test di iniezione di errori e Chaos Engineering
Le applicazioni distribuite devono essere resilienti alle interruzioni del servizio e dei componenti. Il test di iniezione di errori (noto anche come Fault Injection o Chaos Engineering) è la pratica di sottoporre applicazioni e servizi a stress e errori reali.
La resilienza è una proprietà di un intero sistema e l'inserimento di errori consente di individuare i problemi nell'applicazione. La risoluzione di questi problemi consente di convalidare la resilienza delle applicazioni a condizioni inaffidabili, dipendenze mancanti e altri errori.
I test manuali e automatici possono essere eseguiti sull'infrastruttura per individuare errori e problemi nell'implementazione.
Automatico
L'architettura di riferimento integra azure Chaos Studio per distribuire ed eseguire un set di esperimenti di Azure Chaos Studio per inserire vari errori a livello di stamp. Gli esperimenti Chaos possono essere eseguiti come parte facoltativa della pipeline di distribuzione E2E. Quando vengono eseguiti i test, il test di carico facoltativo viene sempre eseguito in parallelo. Il test di carico viene usato per creare carico sul cluster per convalidare l'effetto degli errori iniettati.
Manuale
I test manuali di inserimento degli errori devono essere eseguiti in un ambiente di convalida E2E. Questo ambiente garantisce test rappresentativi completi senza rischi di interferenza da altri ambienti. La maggior parte dei fallimenti generati con i test può essere osservata direttamente nella vista Live metrics di Application Insights . Gli errori rimanenti sono disponibili nella visualizzazione Errori e nelle tabelle di log corrispondenti. Altri errori richiedono un debug più approfondito, ad esempio l'uso di kubectl per osservare il comportamento all'interno del servizio Azure Kubernetes.
Due esempi di test di iniezione degli errori effettuati sull'architettura di riferimento sono:
DNS (Domain Name Service) - inserimento degli errori basato su - un caso di test in grado di simulare più problemi. Errori di risoluzione DNS causati dall'errore di un server DNS o di DNS di Azure. I test basati su DNS consentono di simulare problemi generali di connessione tra un client e un servizio, ad esempio quando il BackgroundProcessor non riesce a connettersi a Hub eventi.
Negli scenari a host singolo è possibile modificare il file
hostslocale per sovrascrivere la risoluzione DNS. In un ambiente più ampio con più server dinamici come AKS, un filehostsnon è fattibile. le zone DNS private di Azure possono essere usate come alternativa agli scenari di errore di test.Hub eventi di Azure e Azure Cosmos DB sono due dei servizi di Azure usati nell'implementazione di riferimento che possono essere usati per inserire errori basati su DNS. La risoluzione DNS di Event Hubs può essere modificata con una zona DNS privata di Azure collegata alla rete virtuale di uno degli stamps. Azure Cosmos DB è un servizio replicato a livello globale con endpoint a livello di area specifici. La manipolazione dei record DNS per tali endpoint può simulare un errore per un'area specifica e testare il failover dei client.
Blocco del firewall - la maggior parte dei servizi di Azure supporta le restrizioni di accesso basate su firewall, reti virtuali e/o indirizzi IP. Nell'infrastruttura di riferimento queste restrizioni vengono usate per limitare l'accesso ad Azure Cosmos DB o a Hub eventi. Una procedura semplice consiste nel rimuovere le regole esistenti di Consenti o aggiungere nuove regole di Blocca . Questa procedura può simulare errori di configurazione del firewall o interruzioni del servizio.
I servizi di esempio seguenti nell'implementazione di riferimento possono essere testati con un test del firewall:
Servizio Risultato Key Vault Quando l'accesso a Key Vault è stato bloccato, l'effetto più diretto è stato il fallimento dell'avvio di nuovi pod. Il driver CSI di Key Vault, che recupera i segreti durante l'avvio del pod, non riesce a svolgere i suoi compiti e impedisce l'avvio dello stesso. È possibile osservare i messaggi di errore corrispondenti con kubectl describe po CatalogService-deploy-my-new-pod -n workload. I pod esistenti continuano a funzionare, anche se viene osservato lo stesso messaggio di errore. I risultati del controllo periodico degli aggiornamenti dei segreti generano il messaggio di errore. Anche se non è stato eseguito il test, l'esecuzione di una distribuzione non funziona mentre Key Vault non è accessibile. Le attività di Terraform e dell'Azure CLI nella pipeline fanno richieste a Key Vault.Hub eventi Quando l'accesso a Hub eventi è bloccato, i nuovi messaggi inviati dal CatalogService e HealthService hanno esito negativo. Il recupero dei messaggi da BackgroundProcess fallisce lentamente, portando a un errore totale entro pochi minuti.Azure Cosmos DB La rimozione dei criteri firewall esistenti per una rete virtuale comporta l'inizio dei malfunzionamenti del servizio di monitoraggio con un breve ritardo. Questa procedura simula solo un caso specifico, un'interruzione completa di Azure Cosmos DB. La maggior parte dei casi di errore che si verificano a livello di area viene mitigata automaticamente con il failover trasparente del client in un'area diversa di Azure Cosmos DB. Il test di iniezione dei guasti basato su DNS descritto in precedenza risulta essere un test più significativo per Azure Cosmos DB. Registro dei contenitori (ACR) Quando l'accesso al Registro Azure Container (ACR) viene bloccato, la creazione di nuovi pod scaricati e memorizzati nella cache in precedenza su un nodo AKS funziona ancora. La creazione funziona ancora grazie al flag di distribuzione K8s pullPolicy=IfNotPresent. I nodi non possono generare un nuovo pod e hanno esito negativo immediatamente con erroriErrImagePullse il nodo non esegue il pull e memorizza nella cache un'immagine prima del blocco.kubectl describe podvisualizza il messaggio di403 Forbiddencorrispondente.Bilanciamento del carico di ingresso di Azure Kubernetes La modifica delle regole in ingresso per HTTP(S) (porte 80 e 443) nel gruppo di sicurezza di rete gestito di AKS a Nega provoca il mancato raggiungimento del traffico dell'utente o del probe di integrità al cluster. Il test di questo fallimento è difficile individuare la causa principale, simulata come blocco tra i percorsi di rete di Front Door e un marcatore regionale. Front Door rileva immediatamente questo errore e toglie il token dalla rotazione.