Questo articolo descrive le considerazioni per la gestione dei dati in un'architettura di microservizi. Poiché ogni microservizio gestisce i propri dati, l'integrità e la coerenza dei dati sono problematiche critiche.
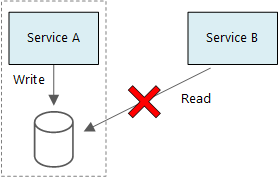
Un principio alla base dei microservizi è che ogni servizio gestisce i propri dati. Due servizi non devono condividere un archivio dati. Ogni servizio è invece responsabile del proprio archivio dati privato, a cui gli altri servizi non possono accedere direttamente.
Il motivo di questa regola è di evitare l'accoppiamento accidentale tra i servizi, come può accadere se i servizi condividono gli stessi schemi di dati sottostanti. Se viene apportata una modifica allo schema dei dati, la modifica deve essere coordinata tra ogni servizio basato su tale database. Isolando l'archivio dati di ogni servizio, è possibile limitare l'ambito della modifica e conservare la flessibilità offerta dalle distribuzioni effettivamente indipendenti. Un altro motivo è che ogni microservizio può avere i propri modelli di dati, query o modelli di lettura/scrittura. L'uso di un archivio dati condiviso limita la possibilità di ogni team di ottimizzare l'archiviazione dati per il proprio servizio specifico.
Questo approccio porta naturalmente alla persistenza poliglotta, ovvero l'uso di più tecnologie di archiviazione dei dati all'interno di una singola applicazione. Un servizio potrebbe richiedere le funzionalità dello schema in lettura di un database di documenti. Per un altro potrebbe essere necessaria l'integrità referenziale fornita da un sistema di gestione di database relazionali. Ogni team può scegliere liberamente l'opzione migliore per il proprio servizio.
Nota
La condivisione dello stesso server di database fisico è appropriata per i servizi. Il problema si verifica quando i servizi condividono lo stesso schema o leggono e scrivono nello stesso set di tabelle di database.
Problematiche
Alcune problematiche sorgono da questo approccio distribuito alle gestione dei dati. In primo luogo potrebbe verificarsi una ridondanza tra gli archivi dati, con lo stesso elemento di dati visualizzato in più punti. I dati, ad esempio, potrebbero venire memorizzati nell'ambito di una transazione, quindi memorizzati altrove per l'analisi, la creazione di report o l'archiviazione. I dati duplicati o partizionati possono causare problemi di integrità e coerenza dei dati. Quando le relazioni tra i dati si estendono su più servizi, non è possibile usare le tecniche tradizionali di gestione dati per applicare le relazioni.
La modellazione dei dati tradizionale usa la regola di "un fatto in un'unica posizione". Ogni entità viene visualizzata esattamente una volta nello schema. Le altre entità possono contenere riferimenti a essa, ma non duplicarla. L'evidente vantaggio dell'approccio tradizionale è che gli aggiornamenti vengono eseguiti in una singola posizione, evitando così problemi di coerenza dei dati. In un'architettura di microservizi è necessario considerare come gli aggiornamenti vengono propagati nei servizi e come gestire la coerenza finale quando i dati vengono visualizzati in più posizioni senza coerenza assoluta.
Approcci alla gestione dei dati
Anche se non esiste un singolo approccio valido sempre, di seguito sono elencate alcune linee guida generali per la gestione dei dati in un'architettura di microservizi.
Definire il livello di coerenza richiesto per ogni componente, preferendo la coerenza finale laddove possibile. Conoscere le posizioni del sistema in cui è necessaria la coerenza assoluta o le transazioni ACID e le posizioni in cui la coerenza finale è accettabile. Per altre indicazioni sui componenti, vedere Uso di DDD tattico per progettare microservizi .
Quando sono necessarie garanzie di coerenza assoluta, un servizio può rappresentare l'origine di dati reali per una determinata entità, esposta tramite un'API. Gli altri servizi potrebbero contenere la propria copia dei dati o un subset dei dati, che presentano la coerenza finale con i dati master, ma non sono considerati l'origine di dati reali. Si prenda ad esempio un sistema di e-commerce con un servizio ordini cliente e un servizio elementi consigliati. Il servizio elementi consigliati potrebbe essere in ascolto degli eventi dal servizio ordini, ma se un cliente richiede un rimborso, è il servizio ordini e non il servizio elementi consigliati ad avere la cronologia completa delle transazioni.
Per le transazioni, usare modelli come Supervisione agente di pianificazione e Transazione di compensazione per mantenere i dati coerenti in più servizi. Potrebbe essere necessario archiviare dati aggiuntivi che acquisiscono lo stato di un'unità di lavoro che si estende su più servizi, per evitare un errore parziale in più servizi, ad esempio, mantenere un elemento di lavoro in una coda durevole mentre è in corso una transazione in più passi.
Archiviare solo i dati necessari per un servizio. A un servizio potrebbe essere necessario solo un subset di informazioni su un'entità di dominio. Nel contesto delimitato per il recapito, ad esempio, è necessario conoscere il cliente associato a una determinata consegna, Non è tuttavia necessario l'indirizzo di fatturazione del cliente, gestito dal contesto delimitato account. In questo caso, possono essere utili un'attenta valutazione del dominio e l'uso della progettazione basata su dominio.
Valutare se i servizi sono coerenti e a regime di controllo libero. Se due servizi si scambiano continuamente informazioni e le API risultano di conseguenza frammentate, potrebbe essere necessario ridisegnare i limiti tra i servizi, unendo i due servizi o effettuando il refactoring delle funzionalità.
Usare uno stile di architettura basato sugli eventi. In questo stile di architettura un servizio pubblica un evento quando vengono apportate modifiche alle entità o ai modelli pubblici. I servizi interessati possono sottoscrivere questi eventi. Un altro servizio, ad esempio, potrebbe usare gli eventi per creare una vista materializzata dei dati più adatta alle query.
Un servizio proprietario di eventi deve pubblicare uno schema che può essere usato per automatizzare la serializzazione e la deserializzazione degli eventi, per evitare un accoppiamento rigido tra server di pubblicazione e sottoscrittori. Si consideri lo schema JSON o un framework come Microsoft Bond, Protobuf o Avro.
Poiché in generale gli eventi possono diventare un collo di bottiglia nel sistema, prendere in considerazione la possibilità di usare l'aggregazione o l'invio in batch per ridurre il carico totale.
Esempio: scelta di archivi dati per l'applicazione di recapito tramite drone
Gli articoli precedenti di questa serie illustrano un servizio di consegna tramite drone come esempio in esecuzione. Per altre informazioni sullo scenario e sull'implementazione di riferimento corrispondente, vedere qui. Questo esempio è ideale per le industrie aeree e aerospaziali.
Per riepilogare, questa applicazione definisce diversi microservizi per la pianificazione delle consegne tramite drone. Quando un utente pianifica un nuovo recapito, la richiesta client include informazioni sulla consegna, ad esempio posizioni di ritiro e rilascio, e sul pacchetto, ad esempio dimensioni e peso. Queste informazioni definiscono un'unità di lavoro.
I diversi servizi back-end gestiscono parti differenti delle informazioni nella richiesta e hanno anche profili di lettura e scrittura differenti.
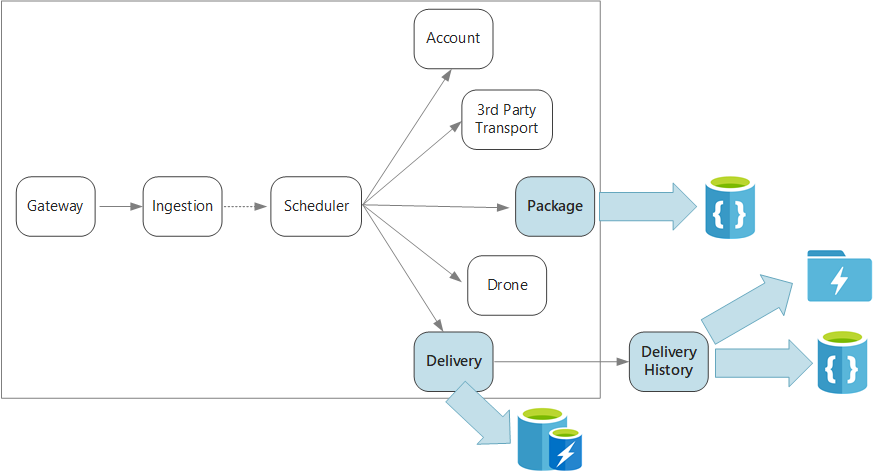
Servizio di consegna
Il servizio di recapito archivia le informazioni su ogni consegna attualmente pianificata o in corso. È in ascolto degli eventi provenienti dai droni e tiene traccia dello stato delle consegne in corso. Con gli aggiornamenti dello stato della consegna invia anche gli eventi di dominio.
È previsto che gli utenti controllino spesso lo stato di una consegna mentre sono in attesa del pacchetto. Il servizio di recapito richiede quindi un archivio dati che evidenzi la velocità effettiva (lettura e scrittura) nell'archiviazione a lungo termine. Il servizio di recapito non esegue nemmeno query o analisi complesse, ma si limita a recuperare lo stato più recente di una determinata consegna. Il team del servizio di distribuzione ha scelto cache di Azure per Redis per ottenere prestazioni di lettura/scrittura elevate. Il ciclo di vita delle informazioni archiviate in Redis è relativamente breve. Dopo che una consegna viene portata a termine, il relativo record viene archiviato nel servizio cronologia di recapito.
Servizio cronologia di consegna
Il servizio cronologia di recapito è in ascolto degli eventi relativi allo stato di una consegna dal servizio di recapito. Memorizza questi dati in una risorsa di archiviazione a lungo termine. Per questi dati cronologici esistono due diversi casi d'uso con requisiti di archiviazione dati diversi.
Il primo scenario consiste nell'aggregazione dei dati a scopo di analisi, per ottimizzare il business o migliorare la qualità del servizio. Si noti che il servizio cronologia di recapito non esegue l'analisi effettiva dei dati, ma è responsabile solo dell'inserimento e dell'archiviazione. Per questo scenario, la risorsa di archiviazione deve essere ottimizzata per l'analisi dei dati in un set di dati di grandi dimensioni, con un approccio basato sullo schema in lettura per gestire svariate origini dati. Azure Data Lake Store è l'ideale per questo scenario. Data Lake Store è un file system Apache Hadoop compatibile con HDFS (Hadoop Distributed File System) le cui prestazioni sono ottimizzate per gli scenari di analisi dei dati.
Nell'altro scenario si consente agli utenti di cercare la cronologia di un recapito che è stato completato. Azure Data Lake non è ottimizzato per questo scenario. Per prestazioni ottimali, Microsoft consiglia di archiviare i dati relativi alle serie temporali in Data Lake in cartelle partizionate per data. Vedere Ottimizzazione delle prestazioni di Azure Data Lake Store. Tale struttura non è tuttavia l'ideale per la ricerca dei singoli record per ID. A meno di non conoscere anche il timestamp, una ricerca per ID richiede l'analisi dell'intera raccolta. Di conseguenza, il servizio Cronologia recapito archivia anche un subset dei dati cronologici in Azure Cosmos DB per una ricerca più rapida. I record non devono rimanere in Azure Cosmos DB per un periodo illimitato. Le consegne meno recenti possono essere archiviate, ad esempio dopo un mese. eseguendo un processo batch occasionale. L'archiviazione dei dati meno recenti può ridurre i costi per Cosmos DB mantenendo comunque i dati disponibili per la creazione di report cronologici da Data Lake.
Servizio confezionamento
Il servizio pacchetto archivia le informazioni su tutti i pacchetti. I requisiti di archiviazione per il pacchetto sono:
- Archiviazione a lungo termine.
- Possibilità di gestire un volume elevato di pacchetti, che richiede un velocità effettiva di scrittura elevata.
- Supporto di query semplici per ID pacchetto. Nessun join o requisito complesso per l'integrità referenziale.
Poiché i dati del pacchetto non sono relazionali, è appropriato un database orientato ai documenti e Azure Cosmos DB può ottenere una velocità effettiva elevata usando raccolte partizionate. Il team che lavora nel servizio pacchetto ha familiarità con lo stack MEAN (MongoDB, Express.js, AngularJS e Node.js), in modo da selezionare l'API MongoDB per Azure Cosmos DB. Ciò consente loro di sfruttare l'esperienza esistente con MongoDB, ottenendo al tempo stesso i vantaggi di Azure Cosmos DB, che è un servizio di Azure gestito.
Passaggi successivi
Informazioni sui modelli di progettazione che consentono di attenuare alcune problematiche comuni in un'architettura di microservizi.