Comprendere i modelli di archiviazione dei dati
I sistemi aziendali moderni gestiscono volumi sempre più grandi di dati eterogenei. Questa eterogeneità significa che un singolo archivio dati non è in genere l'approccio migliore. È invece spesso preferibile archiviare tipi diversi di dati in archivi dati diversi, ognuno incentrato su un carico di lavoro o un modello di utilizzo specifico. Il termine di persistenza poliglotta viene usato per descrivere le soluzioni che usano una combinazione di tecnologie di archivio dati. È quindi importante comprendere i principali modelli di archiviazione e i relativi compromessi.
La selezione dell'archivio dati appropriato per i requisiti è una decisione di progettazione chiave. Tra i database SQL e NoSQL è possibile scegliere letteralmente centinaia di implementazioni. Gli archivi dati vengono spesso classificati in base alla struttura dei dati e ai tipi di operazioni supportati. Questo articolo descrive diversi modelli di archiviazione più comuni. Si noti che una particolare tecnologia di archiviazione dati può supportare più modelli di archiviazione. Ad esempio, un sistema di gestione di database relazionale (RDBMS) può supportare anche l'archiviazione chiave/valore o grafico. In effetti, esiste una tendenza generale per il cosiddetto supporto multimodello , in cui un singolo sistema di database supporta diversi modelli. Ma è comunque utile comprendere i diversi modelli a un livello elevato.
Non tutti gli archivi dati in una determinata categoria forniscono lo stesso set di funzionalità. La maggior parte degli archivi di dati offre funzionalità lato server per eseguire query ed elaborare i dati. A volte questa funzionalità è integrata nel motore di archiviazione dei dati. In altri casi, le funzionalità di archiviazione e elaborazione dei dati sono separate e possono essere disponibili diverse opzioni per l'elaborazione e l'analisi. Gli archivi dati supportano anche diverse interfacce di gestione e a livello di codice.
In genere, è consigliabile iniziare considerando quale modello di archiviazione è più adatto per i requisiti. Si consideri quindi un archivio dati specifico all'interno di tale categoria, in base a fattori quali set di funzionalità, costi e facilità di gestione.
Nota
Per saperne di più sull'identificazione e la verifica dei requisiti del servizio dati per l'adozione del cloud, consultare il Microsoft Cloud Adoption Framework per Azure. Analogamente, è anche possibile ottenere informazioni su la selezione di strumenti e servizi di archiviazione.
Sistemi di gestione di database relazionali
I database relazionali organizzano i dati come una serie di tabelle bidimensionali con righe e colonne. La maggior parte dei fornitori fornisce un dialetto del linguaggio SQL (Structured Query Language) per il recupero e la gestione dei dati. Un RDBMS implementa in genere un meccanismo coerente dal punto di vista transazionale conforme al modello ACID (Atomic, Consistent, Isolated, Durable) per l'aggiornamento delle informazioni.
RdBMS supporta in genere un modello di schema in scrittura, in cui la struttura dei dati viene definita in anticipo e tutte le operazioni di lettura o scrittura devono usare lo schema.
Questo modello è molto utile quando le garanzie di coerenza assoluta sono importanti, in cui tutte le modifiche sono atomiche e le transazioni lasciano sempre i dati in uno stato coerente. Tuttavia, un rdbms in genere non può aumentare orizzontalmente senza partizionare i dati in qualche modo. I dati in un sistema RDBMS devono essere normalizzati, il che non è appropriato per ogni set di dati.
Servizi di Azure
del database SQL di Azure (baseline di sicurezza) - Database di Azure per MySQL | (Baseline di Sicurezza)
- Azure Database for PostgreSQL | (baseline di sicurezza)
- database di Azure per MariaDB | (baseline di sicurezza)
Carico di lavoro
- I record vengono creati e aggiornati di frequente.
- È necessario completare più operazioni in una singola transazione.
- Le relazioni vengono applicate tramite vincoli di database.
- Gli indici vengono usati per ottimizzare le prestazioni delle query.
Tipo di dati
- I dati sono altamente normalizzati.
- Gli schemi di database sono obbligatori e applicati.
- Relazioni molti-a-molti tra entità di dati del database.
- I vincoli vengono definiti nello schema e imposti a tutti i dati nel database.
- I dati richiedono un'integrità elevata. Gli indici e le relazioni devono essere mantenuti in modo accurato.
- I dati richiedono una coerenza assoluta. Le transazioni operano in modo da garantire che tutti i dati siano 100% coerenti per tutti gli utenti e i processi.
- Le dimensioni delle singole voci di dati sono di piccole e medie dimensioni.
Esempi
- Gestione dell'inventario
- Gestione degli ordini
- Database di reportistica
- Contabilità
Archivi chiave/valore
Un archivio chiave/valore associa ogni valore di dati a una chiave univoca. La maggior parte degli archivi chiave/valore supporta solo semplici operazioni di query, inserimento ed eliminazione. Per modificare un valore (parzialmente o completamente), un'applicazione deve sovrascrivere i dati esistenti per l'intero valore. Nella maggior parte delle implementazioni, la lettura o la scrittura di un singolo valore è un'operazione atomica.
Un'applicazione può archiviare dati arbitrari come set di valori. Tutte le informazioni sullo schema devono essere fornite dall'applicazione. L'archivio chiave/valore recupera o archivia semplicemente il valore in base alla chiave.
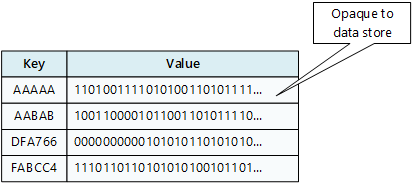
Gli archivi chiave/valore sono altamente ottimizzati per le applicazioni che eseguono ricerche semplici, ma sono meno adatti se è necessario eseguire query sui dati in archivi chiave/valore diversi. Anche gli archivi chiave/valore non sono ottimizzati per l'esecuzione di query in base al valore.
Un singolo archivio chiave/valore può essere estremamente scalabile, poiché l'archivio dati può distribuire facilmente i dati tra più nodi in computer separati.
Servizi di Azure
- Azure Cosmos DB per Tabelle e Azure Cosmos DB per NoSQL | (Baseline di sicurezza di Azure Cosmos DB)
- Cache di Azure per Redis | (baseline di sicurezza)
- Archiviazione Tabelle di Azure | (baseline di sicurezza)
Carico di lavoro
- L'accesso ai dati viene eseguito usando una singola chiave, ad esempio un dizionario.
- Non sono necessari join, blocchi o unioni.
- Non vengono usati meccanismi di aggregazione.
- Gli indici secondari in genere non vengono usati.
Tipo di dati
- Ogni chiave è associata a un singolo valore.
- Non è prevista alcuna applicazione dello schema.
- Nessuna relazione tra entità.
Esempi
- Memorizzazione nella cache dei dati
- Gestione delle sessioni
- Gestione delle preferenze utente e del profilo
- Raccomandazione del prodotto e gestione degli annunci
Database di documenti
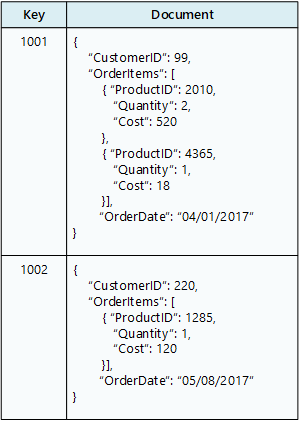
Un database di documenti archivia una raccolta di documenti , dove ogni documento è costituito da campi e dati denominati. I dati possono essere semplici valori o elementi complessi, ad esempio elenchi e sottocollezioni. I documenti vengono recuperati da chiavi univoche.
In genere, un documento contiene i dati per una singola entità, ad esempio un cliente o un ordine. Un documento può contenere informazioni che verrebbero distribuite tra diverse tabelle relazionali in un rdbms. I documenti non devono avere la stessa struttura. Le applicazioni possono archiviare dati diversi nei documenti man mano che cambiano i requisiti aziendali.
Servizio di Azure
Carico di lavoro
- Le operazioni di inserimento e aggiornamento sono comuni.
- Nessun disallineamento di impedenza tra oggetti e relazioni. I documenti possono corrispondere meglio alle strutture di oggetti usate nel codice dell'applicazione.
- I singoli documenti vengono recuperati e scritti come un singolo blocco.
- I dati richiedono un indice su più campi.
Tipo di dati
- I dati possono essere gestiti in modo denormalizzato.
- Le dimensioni dei singoli dati del documento sono relativamente piccole.
- Ogni tipo di documento può usare uno schema specifico.
- I documenti possono includere campi facoltativi.
- I dati del documento sono semistrutturati, ovvero i tipi di dati di ogni campo non sono definiti rigorosamente.
Esempi
- Catalogo prodotti
- Gestione dei contenuti
- Gestione dell'inventario
Database a grafo
Un database a grafo archivia due tipi di informazioni, nodi e archi. Gli archi specificano le relazioni tra i nodi. I nodi e i bordi possono avere proprietà che forniscono informazioni sul nodo o sul bordo, in modo simile alle colonne di una tabella. Gli archi possono anche avere una direzione che denota la natura della relazione.
I database a grafo possono eseguire query in modo efficiente attraverso la rete di nodi e archi e analizzare le relazioni tra entità. Il diagramma seguente mostra il database del personale di un'organizzazione strutturato come grafico. Le entità sono dipendenti e reparti, e gli archi indicano le relazioni gerarchiche e i reparti in cui lavorano.
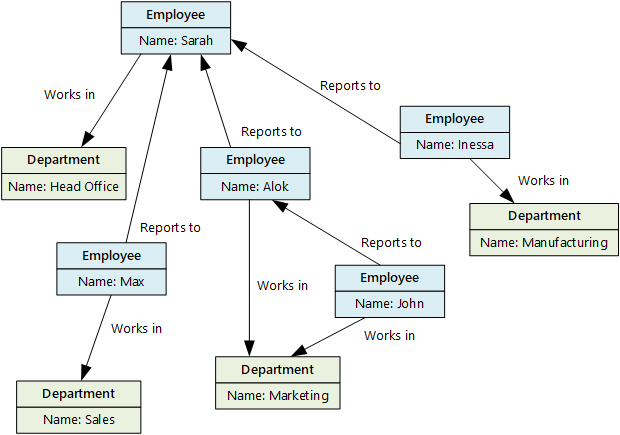
Questa struttura semplifica l'esecuzione di query, ad esempio "Trovare tutti i dipendenti che segnalano direttamente o indirettamente a Sarah" o "Chi lavora nello stesso reparto di John?" Per grafici di grandi dimensioni con molte entità e relazioni, è possibile eseguire analisi molto complesse molto rapidamente. Molti database a grafo forniscono un linguaggio di query che è possibile usare per attraversare in modo efficiente una rete di relazioni.
Servizi di Azure
Azure Cosmos DB per Apache Gremlin (Baseline di Sicurezza) - | SQL Server (baseline di sicurezza)
Carico di lavoro
- Relazioni complesse tra elementi di dati che coinvolgono molti passaggi tra elementi di dati correlati.
- La relazione tra gli elementi di dati è dinamica e cambia nel tempo.
- Le relazioni tra oggetti sono di primaria importanza, senza richiedere chiavi esterne e join per navigarle.
Tipo di dati
- Nodi e relazioni.
- I nodi sono simili alle righe della tabella o ai documenti JSON.
- Le relazioni sono altrettanto importanti dei nodi e vengono esposte direttamente nel linguaggio di query.
- Gli oggetti compositi, ad esempio una persona con più numeri di telefono, tendono a essere suddivisi in nodi separati, più piccoli, combinati con relazioni attraversabili
Esempi
- Organigrammi
- Grafi sociali
- Rilevamento delle frodi
- Motori di raccomandazione
Analisi dei dati
Gli archivi di analisi dei dati offrono soluzioni parallele massicce per l'inserimento, l'archiviazione e l'analisi dei dati. I dati vengono distribuiti tra più server per ottimizzare la scalabilità. I formati di file di dati di grandi dimensioni, ad esempio file delimitatori (CSV), parquete orc vengono ampiamente usati nell'analisi dei dati. I dati cronologici vengono in genere archiviati in repository di dati come BLOB storage o Azure Data Lake Storage Gen2, che diventano quindi accessibili da Azure Synapse, Databricks o HDInsight come tabelle esterne. Uno scenario tipico che utilizza i dati archiviati in formato Parquet per migliorare le prestazioni è descritto nell'articolo Utilizzare tabelle esterne con Synapse SQL.
Servizi di Azure
- Azure Synapse Analytics | (baseline di sicurezza)
- Azure Data Lake | (Baseline di sicurezza)
- Esplora dati di Azure | (baseline di sicurezza)
- Azure Analysis Services
- HDInsight | (baseline di sicurezza)
- Azure Databricks | (Baseline di sicurezza)
Carico di lavoro
- Analisi dei dati
- Business Intelligence aziendale
Tipo di dati
- Dati cronologici provenienti da più origini.
- In genere denormalizzato in uno schema "stella" o "fiocco di neve", costituito da tabelle dei fatti e dimensioni.
- In genere vengono caricati con nuovi dati in base a una pianificazione.
- Le tabelle delle dimensioni includono spesso più versioni storiche di un'entità, denominate dimensione a modifica lenta.
Esempi
- Data warehouse aziendale
Famiglia di colonne del database
Un database della famiglia di colonne organizza i dati in righe e colonne. Nella sua forma più semplice, un database della famiglia di colonne può apparire molto simile a un database relazionale, almeno concettualmente. La reale potenza di un database a colonne-famiglia risiede nell'approccio denormalizzato alla strutturazione dei dati sparsi.
Si può pensare a un database a famiglie di colonne come un contenitore di dati in forma tabellare con righe e colonne, ma le colonne sono suddivise in gruppi noti come famiglie di colonne. Ogni famiglia di colonne contiene un set di colonne correlate logicamente insieme e vengono in genere recuperate o modificate come unità. Altri dati a cui si accede separatamente possono essere archiviati in famiglie di colonne separate. All'interno di una famiglia di colonne, è possibile aggiungere dinamicamente nuove colonne e le righe possono essere di tipo sparse, ovvero una riga non deve avere un valore per ogni colonna.
Il diagramma seguente mostra un esempio con due famiglie di colonne, Identity e Contact Info. I dati per una singola entità hanno la stessa chiave di riga in ogni famiglia di colonne. Questa struttura, in cui le righe per qualsiasi oggetto specificato in una famiglia di colonne possono variare in modo dinamico, è un importante vantaggio dell'approccio della famiglia di colonne, rendendo questa forma di archivio dati particolarmente adatta per l'archiviazione di dati strutturati e volatili.

A differenza di un archivio chiave/valore o di un database di documenti, la maggior parte dei database della famiglia di colonne archivia i dati in ordine di chiave, invece di calcolare un hash. Molte implementazioni consentono di creare indici su colonne specifiche in una famiglia di colonne. Gli indici consentono di recuperare i dati in base al valore delle colonne anziché alla chiave di riga.
Le operazioni di lettura e scrittura per una riga sono in genere atomiche con una singola famiglia di colonne, anche se alcune implementazioni forniscono atomicità nell'intera riga, che si estende su più famiglie di colonne.
Servizi di Azure
- Azure Cosmos DB per Apache Cassandra | (Baseline di Sicurezza)
- HBase in HDInsight | (baseline di sicurezza)
Carico di lavoro
- La maggior parte dei database della famiglia di colonne esegue operazioni di scrittura estremamente rapidamente.
- Le operazioni di aggiornamento ed eliminazione sono rare.
- Progettato per fornire velocità effettiva elevata e accesso a bassa latenza.
- Supporta un facile accesso a un determinato insieme di campi all'interno di un record molto più grande.
- Scalabilità massiccia.
Tipo di dati
- I dati vengono archiviati in tabelle costituite da una colonna chiave e da una o più famiglie di colonne.
- Le colonne specifiche possono variare in base alle singole righe.
- È possibile accedere alle singole celle tramite i comandi get e put
- Vengono restituite più righe usando un comando di scansione.
Esempi
- Consigli
- Personalizzazione
- Dati dei sensori
- Telemetria
- Messaggistica
- Analisi dei social media
- Analisi Web
- Monitoraggio delle attività
- Dati meteo e di altre serie temporali
Database del motore di ricerca
Un database del motore di ricerca consente alle applicazioni di cercare informazioni contenute in archivi dati esterni. Un database del motore di ricerca può indicizzare volumi elevati di dati e fornire l'accesso quasi in tempo reale a questi indici.
Gli indici possono essere multidimensionali e possono supportare ricerche senza testo in grandi volumi di dati di testo. L'indicizzazione può essere eseguita usando un modello pull, attivato dal database del motore di ricerca o usando un modello push, avviato dal codice dell'applicazione esterna.
La ricerca può essere esatta o approssimativa. Una ricerca fuzzy trova i documenti che corrispondono a un set di termini e calcola la loro corrispondenza. Alcuni motori di ricerca supportano anche l'analisi linguistica che può restituire corrispondenze in base a sinonimi, espansioni di genere (ad esempio, corrispondenza dogs a pets) e stemming (parole corrispondenti con la stessa radice).
Servizio di Azure
Carico di lavoro
- Indici di dati da più origini e servizi.
- Le query sono ad hoc e possono essere complesse.
- La ricerca di testo integrale è obbligatoria.
- È necessaria una query self-service ad hoc.
Tipo di dati
- Testo semistrutturato o non strutturato
- Testo con riferimento a dati strutturati
Esempi
- Cataloghi di prodotti
- Ricerca nel sito
- Registrazione
Database di serie temporali
I dati delle serie temporali sono un set di valori organizzati in base all'ora. I database time series raccolgono in genere grandi quantità di dati in tempo reale da un numero elevato di origini. Gli aggiornamenti sono rari e le eliminazioni vengono spesso effettuate in blocco. Anche se i record scritti in un database time series sono in genere di piccole dimensioni, è spesso presente un numero elevato di record e le dimensioni totali dei dati possono crescere rapidamente.
Servizio di Azure
Carico di lavoro
- I record vengono in genere accodati in sequenza in ordine di tempo.
- Una percentuale schiacciante di operazioni (95-99%) sono scritture.
- Gli aggiornamenti sono rari.
- Le eliminazioni avvengono in blocco e sono effettuate su blocchi o record contigui.
- I dati sono letti in sequenza in ordine crescente o decrescente, spesso in parallelo.
Tipo di dati
- Un timestamp viene usato come chiave primaria e meccanismo di ordinamento.
- I tag possono definire informazioni aggiuntive sul tipo, l'origine e altre informazioni sulla voce.
Esempi
- Monitoraggio e telemetria degli eventi.
- Sensore o altri dati IoT.
Archiviazione oggetti
L'archiviazione di oggetti è ottimizzata per l'archiviazione e il recupero di oggetti binari di grandi dimensioni (immagini, file, flussi video e audio, oggetti dati e documenti dell'applicazione di grandi dimensioni, immagini del disco della macchina virtuale). In questo modello vengono usati anche file di dati di grandi dimensioni, ad esempio file delimitatore (CSV), parquete ORC. Gli archivi oggetti possono gestire grandi quantità di dati non strutturati.
Servizio di Azure
- Archiviazione Blob di Azure | (Baseline di Sicurezza)
- Azure Data Lake Storage Gen2 | (baseline di sicurezza)
Carico di lavoro
- Identificato per chiave.
- Il contenuto è in genere un asset, ad esempio un delimitatore, un'immagine o un file video.
- Il contenuto deve essere durevole ed esterno a qualsiasi livello applicazione.
Tipo di dati
- Le dimensioni dei dati sono grandi.
- Il valore è opaco.
Esempi
- Immagini, video, documenti di office, PDF
- HTML statico, JSON, CSS
- File di log e controllo
- Backup del database
File condivisi
A volte, l'uso di semplici file flat può essere il mezzo più efficace per archiviare e recuperare informazioni. L'uso di condivisioni file consente l'accesso ai file in una rete. Data la sicurezza e i meccanismi di controllo di accesso simultanei appropriati, la condivisione dei dati in questo modo può consentire ai servizi distribuiti di fornire un accesso ai dati altamente scalabile per l'esecuzione di operazioni di base e di basso livello, ad esempio semplici richieste di lettura e scrittura.
Servizio di Azure
Carico di lavoro
- Migrazione da app esistenti che interagiscono con il file system.
- Richiede l'interfaccia SMB.
Tipo di dati
- File in un set gerarchico di cartelle.
- Accessibile con librerie di I/O standard.
Esempi
- File obsoleti
- Contenuto condiviso accessibile tra diverse macchine virtuali o istanze di app
Grazie a questa comprensione dei diversi modelli di archiviazione dei dati, il passaggio successivo consiste nel valutare il carico di lavoro e l'applicazione e decidere quale archivio dati soddisfa le esigenze specifiche. Usare l'albero delle decisioni di archiviazione dei dati per facilitare questo processo.
Passaggi successivi
- soluzioni e servizi di archiviazione cloud di Azure
- Esaminare le opzioni di archiviazione
- Introduzione all'Archiviazione di Azure
- Introduzione ad Azure Data Explorer