Questo articolo include un elenco di fattori da considerare quando si sposta una soluzione IoT in un ambiente di produzione.
Usare stamp di distribuzione
Gli stamp sono unità discrete dei componenti principali della soluzione che supportano un numero definito di dispositivi. Ogni copia viene definita stamp o unità di scala. Ad esempio, uno stamp può essere costituito da un popolamento di dispositivi impostati, un hub IoT, un hub eventi o un altro endpoint di routing e da un componente di elaborazione. Ogni stamp supporta un popolamento dei dispositivi definiti. È possibile scegliere il numero massimo di dispositivi che lo stamp può contenere. Con l'aumentare del popolamento dei dispositivi, vengono aggiunte istanze dello stamp anziché aumentare in modo indipendente le diverse parti della soluzione.
Se invece di aggiungere stamp, si sposta una singola istanza della soluzione IoT nell'ambiente di produzione, si potrebbero riscontrare le limitazioni seguenti:
Limiti di scalabilità: la singola istanza può riscontrare limiti di ridimensionamento. La soluzione potrebbe, ad esempio, usare servizi che prevedono limiti relativi al numero di connessioni in ingresso, ai nomi host, ai socket TCP o ad altre risorse.
Costo o scalabilità non lineare: i componenti della soluzione potrebbero non essere ridimensionati in modo lineare in base al numero di richieste effettuate o alla quantità di dati inseriti. Per alcuni componenti, invece, potrebbe verificarsi una riduzione delle prestazioni o un aumento del costo in seguito al raggiungimento di una soglia. L'aumento delle prestazioni con una maggiore capacità potrebbe non rivelarsi una strategia efficace rispetto all'aumento del numero di risorse mediante l'aggiunta di stamp.
Separazione dei clienti: potrebbe essere necessario mantenere i dati di alcuni clienti isolati da quelli di altri clienti. Analogamente, è possibile che alcuni clienti richiedano più risorse di sistema per il servizio rispetto ad altri e che se ne valuti il raggruppamento in stamp diversi.
Istanze singole e multi-tenant: potrebbero essere presenti alcuni clienti di grandi dimensioni che necessitano delle proprie istanze indipendenti della soluzione. È anche possibile avere un pool di clienti più piccoli che possono condividere una distribuzione multi-tenant.
Requisiti di distribuzione complessi: può essere necessario distribuire gli aggiornamenti nel servizio in modo controllato e distribuirli in stamp diversi in momenti diversi.
Frequenza di aggiornamento: è possibile che alcuni clienti tollerino aggiornamenti frequenti del sistema, mentre altri potrebbero essere contrari al rischio e richiedere aggiornamenti meno frequenti del servizio.
Restrizioni geografiche o geopolitiche: per ridurre la latenza o rispettare i requisiti di sovranità dei dati, è possibile distribuire alcuni clienti in aree specifiche.
Per evitare i problemi precedenti, è consigliabile raggruppare il servizio in più stamp. Gli stamp operano autonomamente l'uno dall'altro e possono essere distribuiti e aggiornati in modo indipendente. Una singola area geografica può contenere un singolo stamp oppure più stamp per consentire lo scale-out all'interno dell'area. Ogni stamp contiene un subset dei clienti.
Usare il backoff quando si verifica un errore temporaneo
Tutte le applicazioni che comunicano con servizi e risorse remoti devono essere sensibili agli errori temporanei. Questa considerazione è valida soprattutto per le applicazioni in esecuzione nel cloud, in cui la natura dell'ambiente e la connettività Internet aumentano le probabilità che si verifichino questi tipi di errore. Gli errori temporanei includono:
- Perdita momentanea della connettività di rete a componenti e servizi
- Indisponibilità temporanea di un servizio
- Timeout che si verificano quando un servizio è occupato
- Collisioni che si verificano quando i dispositivi trasmettono contemporaneamente
In molti casi questi errori si risolvono automaticamente e, se ripetuta dopo un intervallo di tempo appropriato, è probabile l'azione che abbia esito positivo. Determinare gli intervalli appropriati tra tentativi è tuttavia complesso. Le strategie più comuni usano i tipi di intervallo tra tentativi seguenti:
- Backoff esponenziale. L'applicazione attende un breve intervallo di tempo prima di ripetere il primo tentativo e aumenta in modo esponenziale il tempo di attesa prima di ogni tentativo successivo. Ad esempio, può ritentare l'operazione dopo 3 secondi, 12 secondi, 30 secondi e così via.
- Intervalli regolari. L'applicazione attende lo stesso intervallo di tempo prima di ripetere ogni nuovo tentativo. Ad esempio, può ripetere l'operazione ogni 3 secondi.
- Tentativo immediato. In alcuni casi un errore temporaneo può avere una durata breve, quando è causato da eventi come una collisione di pacchetti di rete o un picco in un componente hardware. In questo caso, è opportuno ripetere immediatamente l'operazione perché è possibile che abbia esito positivo se l'errore si è risolto nell'intervallo di tempo necessario all'applicazione per assemblare e inviare la richiesta successiva. Tuttavia, è consigliabile non ripetere più di un tentativo immediato e, in caso di esito negativo, passare piuttosto a strategie alternative, come azioni di fallback o backoff esponenziale.
- Sequenza casuale. Tutte le precedenti strategie di ripetizione dei tentativi possono includere un elemento di randomizzazione per impedire a più istanze del client di inviare contemporaneamente nuovi tentativi.
Evitare anche gli anti-modelli seguenti:
- Le implementazioni non devono includere livelli duplicati del codice per la ripetizione dei tentativi.
- Non implementare mai un meccanismo a ciclo infinito.
- Evitare di eseguire più volte una ripetizione di tentativo immediata.
- Evitare di usare un intervallo regolare di ripetizione dei tentativi.
- Evitare che più istanze dello stesso client, o più istanze di client diversi, eseguano contemporaneamente ripetizioni di tentativi.
Usare il provisioning completamente automatico
Il provisioning rappresenta l'atto di registrare un dispositivo nell'hub IoT di Azure. Con il provisioning l'hub IoT riconosce il dispositivo e il meccanismo di attestazione usato dal dispositivo. È possibile usare il servizio Device Provisioning in hub IoT di Azure oppure effettuare il provisioning direttamente tramite le API RegistryManager dell'hub IoT. Con il servizio Device Provisioning è possibile usufruire del vantaggio dell'associazione tardiva, che consente di rimuovere e ripetere il provisioning dei dispositivi sul campo nell'hub IoT senza modificare il software del dispositivo.
L'esempio seguente illustra come implementare un flusso di lavoro di transizione da ambiente di test a ambiente di produzione tramite il servizio Device Provisioning.
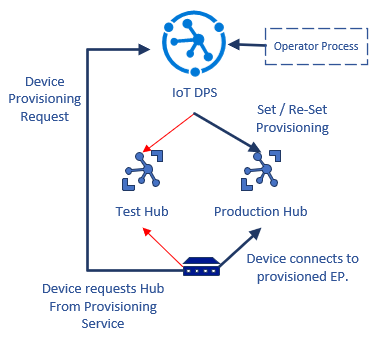
- Lo sviluppatore della soluzione collega i cloud IoT di test e di produzione al servizio di provisioning.
- Il dispositivo implementa il protocollo DPS per trovare il hub IoT, se non viene più effettuato il provisioning. Il provisioning del dispositivo viene eseguito inizialmente nell'ambiente di test.
- Dal momento che è registrato con l'ambiente di test, il dispositivo si connette e viene eseguito il test.
- Lo sviluppatore effettua nuovamente il provisioning del dispositivo nell'ambiente di produzione e lo rimuove dall'hub di test. L'hub di test rifiuta il dispositivo alla successiva riconnessione.
- Il dispositivo si connette e negozia nuovamente il flusso di provisioning. Il servizio Device Provisioning ora indirizza il dispositivo all'ambiente di produzione, quindi il dispositivo si connette ed esegue l'autenticazione.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Matthew Cosner | Principal Software Engineering Manager
- Ansley Yeo | Principal Program Manager
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.