Il successo della soluzione cloud dipende dall'affidabilità. L'affidabilità può essere definita genericamente come la probabilità che il sistema funzioni come previsto, nelle condizioni ambientali specificate, entro un periodo di tempo specificato. Per Site Reliability Engineering (SRE) si intende un set di principi e procedure per la creazione di sistemi software scalabili e altamente affidabili. SRE viene sempre più usato durante la progettazione di servizi digitali per garantire una maggiore affidabilità.
Per altre informazioni sulle strategie SRE, vedere AZ-400: Sviluppare una strategia basata su Site Reliability Engineering (SRE).
Potenziali casi d'uso
I concetti illustrati in questo articolo si applicano a:
- Servizi cloud basati su API.
- Applicazioni Web pubbliche.
- Carichi di lavoro basati su IoT o su eventi.
Architettura

Scaricare un file PowerPoint di questa architettura.
L'architettura presa in considerazione in questo caso è quella di una piattaforma API scalabile. La soluzione è costituita da più microservizi che usano un'ampia gamma di database e servizi di archiviazione, tra cui soluzioni SaaS (Software as a Service), come esempio Dynamics 365 e Microsoft 365.
Questo articolo prende in considerazione una soluzione che gestisce casi d'uso di e-commerce e marketplace di alto livello per illustrare i blocchi illustrati nel diagramma. I casi d'uso sono i seguenti:
- Esplorazione di prodotti.
- Registrazione e accesso.
- Visualizzazione di contenuto, ad esempio articoli di giornale.
- Gestione di ordini e sottoscrizioni.
Le applicazioni client, ad esempio le app Web, le app per dispositivi mobili e persino le applicazioni di servizio, utilizzano i servizi della piattaforma API tramite il percorso di accesso unificato https://api.contoso.com.
Componenti
- Frontdoor di Azure fornisce un punto di ingresso unificato protetto per tutte le richieste inviate alla soluzione. Per altre informazioni, vedere Panoramica dell'architettura di routing.
- Gestione API di Azure offre un livello di governance su tutte le API pubblicate. È possibile usare i criteri di Gestione API di Azure per applicare funzionalità aggiuntive al livello API, ad esempio restrizioni di accesso, memorizzazione nella cache e trasformazione dei dati. Gestione API supporta la scalabilità automatica nei livelli Standard e Premium.
- Il servizio Azure Kubernetes è l'implementazione di cluster Kubernetes open source in Azure. Come servizio Kubernetes ospitato, Azure gestisce attività critiche quali il monitoraggio dell'integrità e la manutenzione. Dal momento che i master Kubernetes sono gestiti da Azure, le attività di gestione e manutenzione riguardano solo i nodi agente. In questa architettura tutti i microservizi vengono distribuiti nel servizio Azure Kubernetes.
- Gateway applicazione di Azure è un servizio controller per la distribuzione di applicazioni. Opera al livello 7, il livello dell'applicazione, e include diverse funzionalità di bilanciamento del carico. Il controller di ingresso (AGIC) gateway applicazione è un'applicazione Kubernetes che consente ai clienti di servizio Azure Kubernetes (AKS) di usare il servizio di bilanciamento del carico nativo di Azure gateway applicazione L7 per esporre il software cloud a Internet. La scalabilità automatica e la ridondanza della zona sono supportate nella SKU v2.
- Archiviazione di Azure, Azure Data Lake Storage, Azure Cosmos DB e Azure SQL possono archiviare contenuto strutturato e non strutturato. È possibile creare database e contenitori Azure Cosmos DB con velocità effettiva a scalabilità automatica.
- Microsoft Dynamics 365 è un'offerta SaaS (Software as a Service) di Microsoft che offre diverse applicazioni aziendali per Customer Service, Vendite, Marketing e Finanza. In questa architettura, Dynamics 365 viene usato principalmente per la gestione dei cataloghi dei prodotti e per la gestione del servizio clienti. Le unità di scala forniscono la resilienza alle applicazioni Dynamics 365.
- Microsoft 365 (in precedenza Office 365) viene usato come sistema di gestione dei contenuti aziendale basato su Microsoft 365 SharePoint in Microsoft 365. Viene usato per creare, gestire e pubblicare contenuto, ad esempio asset multimediali e documenti.
Alternative
Dal momento che questa soluzione usa un'architettura basata su microservizi a scalabilità elevata, prendere in considerazioni queste alternative per il piano di calcolo:
- Funzioni di Azure per i servizi API serverless
- Microservizi basati su Azure Spring Apps per Java
Affidabilità appropriata
Il livello di affidabilità necessario per una soluzione dipende dal contesto aziendale. Un punto vendita al dettaglio aperto per 14 ore e con picchi di utilizzo del sistema entro tale intervallo ha requisiti diversi rispetto a quelli di un'azienda online che accetta ordini a tutte le ore. È possibile personalizzare le procedure SRE per ottenere il livello di affidabilità appropriato.
L'affidabilità viene definita e misurata usando gli obiettivi del livello di servizio (obiettivi del livello di servizio) che definiscono il livello di affidabilità di destinazione per un servizio. Il raggiungimento del livello definito è indicativo del livello di soddisfazione degli utenti. Gli obiettivi del livello di servizio possono evolversi o cambiare a seconda delle esigenze aziendali. I proprietari del servizio devono, però, misurare costantemente l'affidabilità rispetto a tali obiettivi per rilevare i problemi e adottare azioni correttive. Gli obiettivi del livello di servizio sono in genere definiti come obiettivo percentuale in un dato periodo.
Un altro termine importante da notare è l'indicatore del livello di servizio (SLI), che è la metrica usata per calcolare l'SLO. Gli indicatori del livello di servizio si basano su dati analitici derivati dai dati acquisiti durante l'utilizzo del servizio da parte del cliente. Gli indicatori del livello di servizio vengono sempre misurati dal punto di vista del cliente.
Gli obiettivi e gli indicatori del livello di servizio vanno sempre di passo e vengono in genere definiti in modo iterativo. Gli obiettivi del livello di servizio sono basati sugli obiettivi aziendali chiave, mentre gli indicatori del livello di servizio si basano sugli elementi che è possibile misurare durante l'implementazione del servizio.
La relazione tra metrica monitorata, indicatore del livello di servizio e obiettivo del livello di servizio è illustrata di seguito:
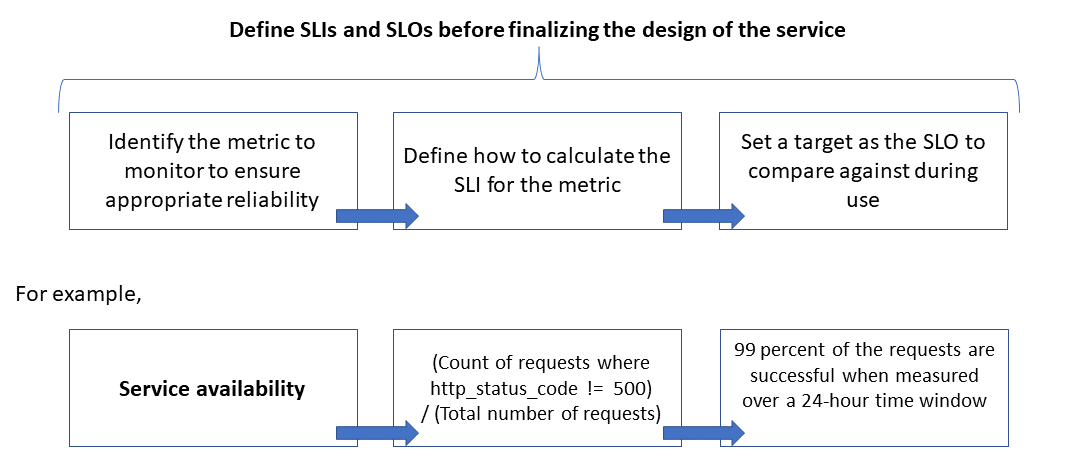
Questa relazione è illustrata in modo più dettagliato in Definire le metriche degli indicatori del livello di servizio per calcolare gli obiettivi del livello di servizio.
Modellazione delle aspettative in termini di scalabilità e prestazioni
Per un sistema software le prestazioni si riferiscono in genere alla velocità di risposta complessiva di un sistema quando si esegue un'azione entro un periodo di tempo specificato, mentre la scalabilità è la capacità del sistema di gestire carichi utente più elevati senza influire negativamente sulle prestazioni.
Un sistema è considerato scalabile se le risorse sottostanti vengono rese disponibili dinamicamente per supportare un incremento del carico. Le applicazioni cloud devono essere progettate per la scalabilità e talvolta il volume del traffico è difficile da prevedere. I picchi stagionali possono causare un aumento dei requisiti di scalabilità, soprattutto quando un servizio gestisce le richieste per più tenant.
È consigliabile progettare applicazioni in modo che le risorse cloud aumentino o diminuiscano automaticamente come necessario per soddisfare il carico. In pratica, il sistema deve adattarsi all'incremento del carico di lavoro tramite il provisioning o l'allocazione incrementale delle risorse per soddisfare la domanda. La scalabilità riguarda non solo le istanze di calcolo, ma anche altri elementi, ad esempio l'archiviazione dei dati e l'infrastruttura di messaggistica.
Questo articolo illustra come garantire l'affidabilità appropriata per un'applicazione cloud effettuando la modellazione degli scenari di carico di lavoro in termini di scalabilità e prestazioni e usando i risultati per definire i monitoraggi, gli indicatori e gli obiettivi del livello di servizio.
Considerazioni
Per indicazioni sulla creazione di applicazioni scalabili e affidabili, vedere i pilastri Affidabilità ed Efficienza delle prestazioni di Azure Well Architected Framework.
Questo articolo illustra come applicare le tecniche di scalabilità e modellazione delle prestazioni per ottimizzare l'architettura e la progettazione della soluzione. Queste tecniche identificano le modifiche ai flussi delle transazioni per un'esperienza utente ottimale. Basare le decisioni tecniche sui requisiti non funzionali della soluzione. Il processo è:
- Identificare i requisiti di scalabilità.
- Modellare il carico previsto.
- Definire gli indicatori e gli obiettivi del livello di servizio per gli scenari utente.
Nota
Azure Application Insights, incluso in Monitoraggio di Azure, è un potente strumento di gestione delle prestazioni delle applicazioni che è possibile integrare facilmente con le applicazioni per inviare dati di telemetria e analizzare le metriche specifiche dell'applicazione. Offre anche dashboard pronti per l'uso e uno strumento di esplorazione delle metriche che è possibile usare per analizzare i dati ed esplorare le esigenze aziendali.
Acquisire i requisiti di scalabilità
Presupporre queste metriche di carico di picco:
- Numero di utenti che usano la piattaforma API: 1,5 milioni
- Utenti attivi orari (30% di 1,5 milioni): 450.000
- Percentuale di carico per ogni attività:
- Esplorazione dei prodotti: 75%
- Registrazione che include la creazione del profilo e l'accesso: 10%
- Gestione di ordini e sottoscrizioni: 10%
- Visualizzazione di contenuto: 5%
Il carico produce i requisiti di scalabilità seguenti, in condizioni di carico di picco normale, per le API ospitate dalla piattaforma:
- Microservizio per prodotti: circa 500 richieste al secondo (RPS)
- Microservizio per profilo: circa 100 RPS
- Microservizio per ordini e pagamenti: circa 100 RPS
- Microservizio per contenuto: circa 50 RPS
Questi requisiti di scalabilità non prendono in considerazione i picchi stagionali e casuali e i picchi che si verificano durante eventi speciali come le promozioni marketing. Durante i picchi il requisito di scalabilità per alcune attività utente è fino a 10 volte il carico di picco normale. Tenere presenti questi vincoli e queste aspettative quando si effettuano le scelte di progettazione per i microservizi.
Definire le metriche degli indicatori del livello di servizio per calcolare gli obiettivi del livello di servizio
Le metriche dell'indicatore del livello di servizio indicano il livello in base al quale un servizio offre un'esperienza soddisfacente e possono essere espresse come il rapporto tra eventi soddisfacenti ed eventi totali.
Per un servizio API gli eventi fanno riferimento alle metriche specifiche dell'applicazione acquisite durante l'esecuzione sotto forma di dati di telemetria o dati elaborati. Nell'esempio seguente vengono usate le metriche degli indicatori del livello di servizio seguenti:
| Metrico | Description |
|---|---|
| Disponibilità | Indica se la richiesta è stata gestita dall'API |
| Latenza | Tempo necessario all'API per elaborare la richiesta e restituire una risposta |
| Velocità effettiva | Numero di richieste gestite dall'API |
| Success Rate (Percentuale di riuscita) | Numero di richieste gestite correttamente dall'API |
| Percentuale di errore | Numero di errori per le richieste gestite dall'API |
| Aggiornamento | Numero di volte in cui l'utente ha ricevuto i dati più recenti per le operazioni di lettura nell'API, nonostante l'archivio dati sottostante venga aggiornato con una certa latenza di scrittura |
Nota
Assicurarsi di identificare eventuali indicatori del livello di servizio aggiuntivi importanti per la soluzione.
Ecco alcuni esempi di indicatori del livello di servizio:
- (Numero di richieste completate correttamente in meno di 1.000 ms) / (Numero di richieste)
- (Numero di risultati della ricerca che restituiscono, entro tre secondi, tutti i prodotti pubblicati nel catalogo) / (Numero di ricerche)
Dopo aver definito gli indicatori del livello di servizio, determinare gli eventi o i dati di telemetria da acquisire per misurarli. Ad esempio, per misurare la disponibilità, si acquisiscono eventi per indicare se il servizio API ha elaborato correttamente una richiesta. Per i servizi basati su HTTP l'esito positivo o negativo è indicato da codici di stato HTTP. La progettazione e l'implementazione dell'API devono fornire i codici adeguati. In generale, le metriche degli indicatori del livello di servizio costituiscono un input importante per l'implementazione dell'API.
Per i sistemi basati sul cloud è possibile ottenere alcune delle metriche usando il supporto per diagnostica e monitoraggio disponibile per le risorse. Monitoraggio di Azure è una soluzione completa per la raccolta, l'analisi e l'esecuzione di operazioni sui dati di telemetria dai servizi cloud. A seconda dei requisiti degli indicatori del livello di servizio, è possibile acquisire più dati di monitoraggio per calcolare le metriche.
Usare le distribuzioni percentili
Alcuni indicatori del livello di servizio vengono calcolati usando una tecnica di distribuzione percentile. Questa tecnica offre risultati migliori se sono presenti outlier che possono falsare altre tecniche, ad esempio le distribuzioni di medie o valori mediani.
Si consideri, ad esempio, che la metrica è la latenza delle richieste API e tre secondi corrisponde alla soglia per prestazioni ottimali. I tempi di risposta ordinati per un'ora di richieste API indicano che un numero limitato di richieste richiede più di tre secondi, mentre la maggior parte riceve risposte entro il limite definito dalla soglia. Questo è il comportamento previsto del sistema.
La distribuzione percentile è concepita per escludere gli outlier causati da problemi intermittenti. Ad esempio, se le risposte del servizio appropriate rientrano nel 90° o nel 95° percentile, l'obiettivo del livello di servizio viene considerato soddisfatto.
Scegliere i periodi di misurazione adeguati
Il periodo di misurazione per la definizione di un obiettivo del livello di servizio è molto importante. Deve acquisire l'attività, non l'inattività, affinché i risultati siano significativi per l'esperienza utente. Questa finestra può essere compresa tra cinque minuti e 24 ore a seconda di come si intende monitorare e calcolare la metrica degli indicatori del livello di servizio.
Stabilire un processo di governance per le prestazioni
Le prestazioni di un'API devono essere gestite fin dall'inizio fino a quando non viene deprecata o ritirata. È necessario predisporre un processo di governance affidabile per garantire che i problemi di prestazioni vengano rilevati e risolti in anticipo, prima di causare un'interruzione grave che influisce negativamente sulle attività aziendali.
Ecco gli elementi della governance per le prestazioni:
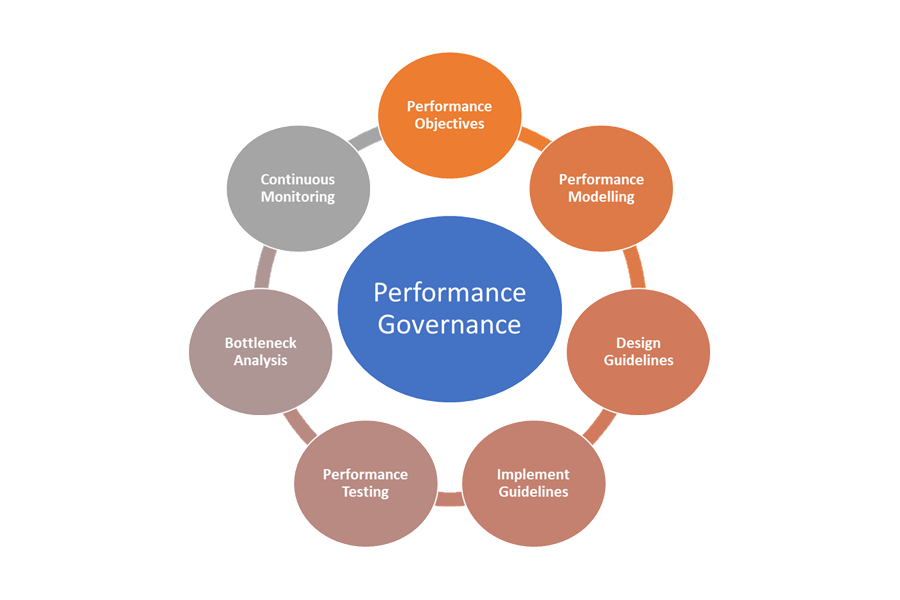
- Obiettivi per le prestazioni: definire gli obiettivi del livello di servizio per garantire prestazioni ottimali per gli scenari aziendali.
- Modellazione delle prestazioni: identificare transazioni e flussi di lavoro critici ed eseguire la modellazione per comprendere le implicazioni correlate alle prestazioni. Acquisire queste informazioni a un livello granulare per stime più accurate.
- Linee guida di progettazione: preparare linee guida di progettazione per le prestazioni e consigliare le modifiche appropriate da apportare al flusso di lavoro aziendale. Assicurarsi che i team siano a conoscenza di queste linee guida.
- Linee guida per l'implementazione: implementare linee guida per la progettazione delle prestazioni per i componenti della soluzione, inclusa la strumentazione per acquisire le metriche. Eseguire revisioni della progettazione per le prestazioni. È fondamentale tenere traccia di tutte queste revisioni usando gli elementi di backlog dell'architettura per i diversi team.
- Test delle prestazioni: eseguire test di carico e stress in base alla distribuzione del profilo di carico per acquisire le metriche correlate all'integrità della piattaforma. È anche possibile eseguire questi test per un carico limitato per valutare i requisiti dell'infrastruttura della soluzione.
- Analisi dei colli di bottiglia: usare l'ispezione del codice e le revisioni del codice per identificare, analizzare e rimuovere i colli di bottiglia delle prestazioni nei vari componenti. Identificare i miglioramenti della scalabilità orizzontale o verticale necessari per supportare i carichi di picco.
- Monitoraggio continuo: definire un'infrastruttura di monitoraggio continuo e avviso nell'ambito dei processi DevOps. Assicurarsi che i team interessati siano informati quando i tempi di risposta peggiorano in modo significativo rispetto ai benchmark.
- Governance per le prestazioni: definire una governance per le prestazioni costituita da processi e team ben definiti per sostenere gli obiettivi del livello di servizio per le prestazioni. Tenere traccia della conformità dopo ogni release per evitare un'eventuale riduzione delle prestazioni causata dagli aggiornamenti della build. Eseguire periodicamente revisioni allo scopo di valutare un eventuale aumento del carico per identificare gli aggiornamenti della soluzione.
Assicurarsi di ripetere i passaggi durante tutto lo sviluppo della soluzione nell'ambito del processo di elaborazione progressiva.
Tenere traccia degli obiettivi e delle aspettative per le prestazioni nel backlog
Tenere traccia degli obiettivi per le prestazioni per assicurarsi che vengano raggiunti. Acquisire storie utente dettagliate e granulari di cui tenere traccia. In questo modo i team di sviluppo considereranno prioritarie le attività di governance per le prestazioni.
Definire obiettivi del livello di servizio ottimali per la soluzione di destinazione
Ecco alcuni esempi di obiettivi del livello di servizio ottimali per la soluzione della piattaforma API in considerazione:
- Risponde al 95% di tutte le richieste di LETTURA in un giorno entro un secondo.
- Risponde al 95% di tutte le richieste di CREAZIONE e AGGIORNAMENTO in un giorno entro tre secondi.
- Risponde al 99% di tutte le richieste in un giorno entro cinque secondi senza errori.
- Risponde correttamente al 99,9% di tutte le richieste in un giorno entro cinque minuti.
- Meno dell'1% delle richieste durante la finestra di picco di un'ora restituisce un errore.
Gli obiettivi del livello di servizio possono essere personalizzati in base a requisiti specifici dell'applicazione. Devono però essere sufficientemente granulari per risultare chiari in modo tale da garantire l'affidabilità.
Misurare gli obiettivi del livello di servizio iniziali basati sui dati dei log
I log di monitoraggio vengono creati automaticamente quando il servizio API è in uso. Si supponga che per una settimana di dati venga visualizzato quanto segue:
- Richieste: 123.456
- Richieste riuscite: 123,204
- Latenza al 90° percentile: 497 ms
- Latenza al 95° percentile: 870 ms
- Latenza al 99° percentile: 1.024 ms
Questi dati generano gli indicatori del livello di servizio iniziali seguenti:
- Disponibilità = (123.204 / 123.456) = 99,8%
- Latenza = almeno il 90% delle richieste è stato evaso entro 500 ms
- Latenza = circa il 98% delle richieste è stato evaso entro 1.000 ms
Presupporre che, durante la pianificazione, l'obiettivo del livello di servizio ottimale per la latenza preveda che il 90% delle richieste vengano elaborate entro 500 ms con una percentuale di successo del 99% nell'arco di una settimana. Con i dati di log è possibile identificare facilmente se l'obiettivo del livello di servizio è stato soddisfatto. Se si esegue questo tipo di analisi per alcune settimane, è possibile iniziare a individuare le tendenze relative alla conformità degli obiettivi del livello di servizio.
Indicazioni per la mitigazione dei rischi tecnici
Usare l'elenco di controllo seguente delle procedure consigliate per ridurre i rischi per scalabilità e prestazioni:
- Progettare tenendo presenti scalabilità e prestazioni.
- Assicurarsi di acquisire i requisiti di scalabilità per ogni scenario utente e carico di lavoro, inclusi stagionalità e picchi.
- Eseguire la modellazione delle prestazioni per identificare i vincoli di sistema e i colli di bottiglia
- Gestire il debito tecnico.
- Analizzare in modo esauriente le metriche delle prestazioni.
- Provare a usare gli script per eseguire strumenti come K6.io, Poite e JMeter nell'ambiente di gestione temporanea di sviluppo con una gamma di carichi utente, ad esempio da 50 a 100 RPS. Questo consentirà di fornire informazioni nei log per il rilevamento dei problemi di progettazione e implementazione.
- Integrare gli script di test automatizzati come parte dei processi di distribuzione continua per rilevare le interruzioni di compilazione.
- Adottare un approccio orientato alla produzione.
- Modificare le soglie di scalabilità automatica come indicato dalle statistiche sull'integrità.
- Preferire le tecniche di ridimensionamento orizzontale rispetto a quelle di ridimensionamento verticale.
- Essere proattivi con il ridimensionamento per gestire la stagionalità.
- Preferire la distribuzione basata su anello.
- Usare i budget degli errori per sperimentare.
Prezzi
Affidabilità, efficienza delle prestazioni e ottimizzazione dei costi vanno di pari passo. I servizi di Azure usati nell'architettura consentono di ridurre i costi, perché vengono dimensionati automaticamente per soddisfare carichi utente variabili.
Per il servizio Azure Kubernetes è possibile iniziare con macchine virtuali di dimensioni standard per il pool di nodi. È quindi possibile monitorare i requisiti delle risorse durante lo sviluppo o l'uso in produzione e adattarli di conseguenza.
L'ottimizzazione dei costi è uno dei pilastri di Microsoft Azure Well-Architected Framework. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi. Per stimare il costo dei prodotti e delle configurazioni di Azure, usare il calcolatore prezzi di Azure.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Subhajit Chatterjee | Principal Software Engineer
Passaggi successivi
- Documentazione Azure
- Microsoft Azure Well-Architected Framework
- Stile dell'architettura dei microservizi
- Progettare per aumentare il numero di istanze
- Scegliere un servizio di calcolo di Azure per l'applicazione
- Architettura di microservizi nel servizio Azure Kubernetes
- Che cos'è Frontdoor di Azure?
- Informazioni su Gestione API
- Che cos'è il Controller in ingresso del gateway applicazione?
- Servizio Azure Kubernetes
- Gateway applicazione con scalabilità automatica e ridondanza della zona versione 2
- Ridimensionare automaticamente un cluster per soddisfare le richieste delle applicazioni nel servizio Azure Kubernetes (AKS)
- Creare contenitori e database di Azure Cosmos DB con velocità effettiva con scalabilità automatica
- Documentazione di Microsoft Dynamics 365
- Documentazione di Microsoft 365
- Documentazione sulla progettazione dell'affidabilità del sito
- AZ-400: Sviluppare una strategia SRE (Site Reliability Engineering)
- Applicazione Web di base con ridondanza della zona