Lezioni apprese
- Assicurarsi che tutte le parti coinvolte comprendano la differenza tra disponibilità elevata e ripristino di emergenza: un problema comune consiste nel confondere i due concetti e la mancata corrispondenza delle soluzioni associate.
- Discutere con gli stakeholder aziendali sulle aspettative relative agli aspetti seguenti per definire gli obiettivi del punto di ripristino (RPO) e gli obiettivi del tempo di ripristino (RTO):
- Quanto tempo di inattività può tollerare, tenendo presente che in genere, più veloce è il ripristino, maggiore è il costo.
- Il tipo di eventi imprevisti da cui vogliono essere protetti, menzionando la probabilità correlata di tale evento. Ad esempio, la probabilità che un server sia inattivo è superiore a una calamità naturale che influisce su tutti i data center in un'area.
- Qual è l'impatto che il sistema non è disponibile per l'azienda?
- Il budget delle spese operative (OPEX) per la soluzione in futuro.
- Considerare le opzioni del servizio danneggiate che gli utenti finali possono accettare. Questi possono includere:
- Avere ancora accesso ai dashboard di visualizzazione anche senza i dati più aggiornati, ovvero se le pipeline di inserimento non funzionano, gli utenti finali hanno ancora accesso ai dati.
- Accesso in lettura ma nessun accesso in scrittura.
- Le metriche RTO e RPO di destinazione possono definire la strategia di ripristino di emergenza che si sceglie di implementare:
- Attivo/Attivo.
- Attivo/passivo.
- Attivo/ridistribuire in caso di emergenza.
- Prendere in considerazione il proprio obiettivo del livello di servizio composito (SLO) per tenere conto dei tempi di inattività tollerabili.
- Assicurarsi di comprendere tutti i componenti che potrebbero influire sulla disponibilità dei sistemi, ad esempio:
- Gestione delle identità.
- Topologia di rete.
- Gestione dei segreti/delle chiavi.
- Origini dati.
- Utilità di pianificazione di automazione/processo.
- Pipeline di repository di origine e distribuzione (GitHub, Azure DevOps).
- Il rilevamento anticipato delle interruzioni è anche un modo per ridurre significativamente i valori RTO e RPO. Ecco alcuni aspetti da trattare:
- Definire l'interruzione e il modo in cui viene eseguito il mapping alla definizione di un'interruzione di Microsoft. La definizione Microsoft è disponibile nella pagina Contratto di servizio di Azure a livello di prodotto o servizio.
- Un sistema efficiente di monitoraggio e avvisi con team responsabili per esaminare le metriche e gli avvisi in modo tempestivo consente di raggiungere l'obiettivo.
- Per quanto riguarda la progettazione delle sottoscrizioni, l'infrastruttura aggiuntiva per il ripristino di emergenza può essere archiviata nella sottoscrizione originale. I servizi PaaS (Platform as a Service) come Azure Data Lake Storage Gen2 o Azure Data Factory in genere dispongono di funzionalità native che consentono il failover alle istanze secondarie in altre aree mantenendo al tempo stesso contenuto nella sottoscrizione originale. Alcuni clienti potrebbero voler prendere in considerazione la disponibilità di un gruppo di risorse dedicato per le risorse usate solo negli scenari di ripristino di emergenza a scopo di costo.
- Si noti che i limiti delle sottoscrizioni possono fungere da vincolo per questo approccio.
- Altri vincoli possono includere i controlli di progettazione e gestione per garantire che i gruppi di risorse di ripristino di emergenza non vengano usati per i flussi di lavoro business-as-usual (BAU).
- Progettare il flusso di lavoro di ripristino di emergenza in base alla criticità e alle dipendenze di una soluzione. Ad esempio, non provare a ricompilare un'istanza di Azure Analysis Services prima che il data warehouse sia operativo, perché attiva un errore. Lasciare i lab di sviluppo più avanti nel processo, ripristinare prima le soluzioni aziendali di base.
- Provare a identificare le attività di ripristino che possono essere parallelizzate tra soluzioni, riducendo il valore RTO totale.
- Se Azure Data Factory viene usato all'interno di una soluzione, non dimenticare di includere i runtime di integrazione self-hosted nell'ambito. Azure Site Recovery è ideale per tali computer.
- Le operazioni manuali devono essere automatizzate il più possibile per evitare errori umani, soprattutto quando sono sotto pressione. È consigliabile:
- Adottare il provisioning delle risorse tramite bicep, modelli arm o script di PowerShell.
- Adottare il controllo delle versioni del codice sorgente e della configurazione delle risorse.
- Usare pipeline di versione CI/CD anziché click-ops.
- Quando si dispone di un piano per il failover, è consigliabile prendere in considerazione le procedure per eseguire il fallback alle istanze primarie.
- Definire indicatori chiari e metriche per verificare che il failover sia riuscito e che le soluzioni siano in esecuzione o che la situazione sia tornata normale (nota anche come funzionalità primaria).
- Decidere se i contratti di servizio devono rimanere invariati dopo un failover o se si consente un servizio danneggiato.
- Questa decisione dipenderà notevolmente dal processo di servizio aziendale supportato. Ad esempio, il failover per un sistema di prenotazione sala avrà un aspetto molto diverso rispetto a un sistema operativo principale.
- Una definizione RTO/RPO deve essere basata su scenari utente specifici anziché a livello di infrastruttura. In questo modo è possibile ottenere una maggiore granularità sui processi e sui componenti da ripristinare prima in caso di interruzione o emergenza.
- Assicurarsi di includere i controlli della capacità nell'area di destinazione prima di procedere con un failover: se si verifica un'emergenza grave, tenere presente che molti clienti tenteranno di eseguire il failover nella stessa area abbinata contemporaneamente, causando ritardi o conflitti nel provisioning delle risorse.
- Se questi rischi sono inaccettabili, è necessario considerare una strategia di ripristino di emergenza attivo/attivo/passivo.
- È necessario creare e gestire un piano di ripristino di emergenza per documentare il processo di ripristino e i proprietari di azioni. Considerare anche che le persone potrebbero essere in congedo, quindi assicurarsi di includere contatti secondari.
- È necessario eseguire regolari esercitazioni sul ripristino di emergenza per convalidare il flusso di lavoro del piano di ripristino di emergenza, che soddisfi gli RTO/RPO necessari e per eseguire il training dei team responsabili.
- Anche i backup dei dati e della configurazione devono essere testati regolarmente per assicurarsi che siano "adatti allo scopo" per supportare eventuali attività di ripristino.
- La collaborazione anticipata con i team responsabili del provisioning di rete, identità e risorse consentirà l'accordo sulla soluzione più ottimale per quanto riguarda:
- Come reindirizzare utenti e traffico dal sito primario al sito secondario. Concetti quali il reindirizzamento DNS o l'uso di strumenti specifici come Gestione traffico di Azure possono essere valutati.
- Come fornire l'accesso e i diritti al sito secondario in modo tempestivo e sicuro.
- Durante un'emergenza, una comunicazione efficace tra le molte parti coinvolte è fondamentale per l'esecuzione efficiente e rapida del piano. Teams può includere:
- Decisori.
- Team di risposta agli eventi imprevisti.
- Utenti interni e team interessati.
- Team esterni.
- L'orchestrazione delle diverse risorse al momento giusto garantisce l'efficienza nell'esecuzione del piano di ripristino di emergenza.
Considerazioni
Antipattern
- Copiare/incollare questa serie di articoli Questa serie di articoli è progettata per fornire indicazioni ai clienti che cercano il livello di dettaglio successivo per un processo di ripristino di emergenza specifico di Azure. Di conseguenza, si basa sulle architetture di riferimento e IP Microsoft generiche anziché su qualsiasi singola implementazione di Azure specifica del cliente.
Mentre i dettagli forniti aiuteranno a supportare una solida comprensione di base, i clienti devono applicare il proprio contesto, implementazione e requisiti specifici prima di ottenere una strategia e un processo di ripristino di emergenza "adatti allo scopo".
Considerare il ripristino di emergenza come processo di sola tecnologia Gli stakeholder aziendali svolgono un ruolo fondamentale nella definizione dei requisiti per il ripristino di emergenza e nel completamento dei passaggi di convalida aziendali necessari per confermare il ripristino del servizio. Garantire che gli stakeholder aziendali siano coinvolti in tutte le attività di ripristino di emergenza fornirà un processo di ripristino di emergenza "adatto allo scopo", rappresenta il valore aziendale ed è eseguibile.
I piani di ripristino di emergenza "Impostare e dimenticare" Azure è in continua evoluzione, così come l'uso di vari componenti e servizi dei singoli clienti. Un processo di ripristino di emergenza "adatto allo scopo" deve evolversi con loro. Tramite il processo SDLC (Software Development Life Cycle) o le revisioni periodiche, i clienti devono rivedere regolarmente il piano di ripristino di emergenza. L'obiettivo è garantire la validità del piano di ripristino del servizio e che siano stati rilevati eventuali delta tra componenti, servizi o soluzioni.
Valutazioni basate su carta Mentre la simulazione end-to-end di un evento di ripristino di emergenza sarà difficile in un moderno sistema eco-sistema di dati, gli sforzi devono essere effettuati per ottenere il più vicino possibile a una simulazione completa tra i componenti interessati. Le esercitazioni pianificate regolarmente creeranno la "memoria muscolare" richiesta dall'organizzazione per poter eseguire il piano di ripristino di emergenza con sicurezza.
Affidandosi a Microsoft per eseguire tutte le operazioni all'interno dei servizi di Microsoft Azure, esiste una chiara divisione della responsabilità, ancorata dal livello di servizio cloud usato:
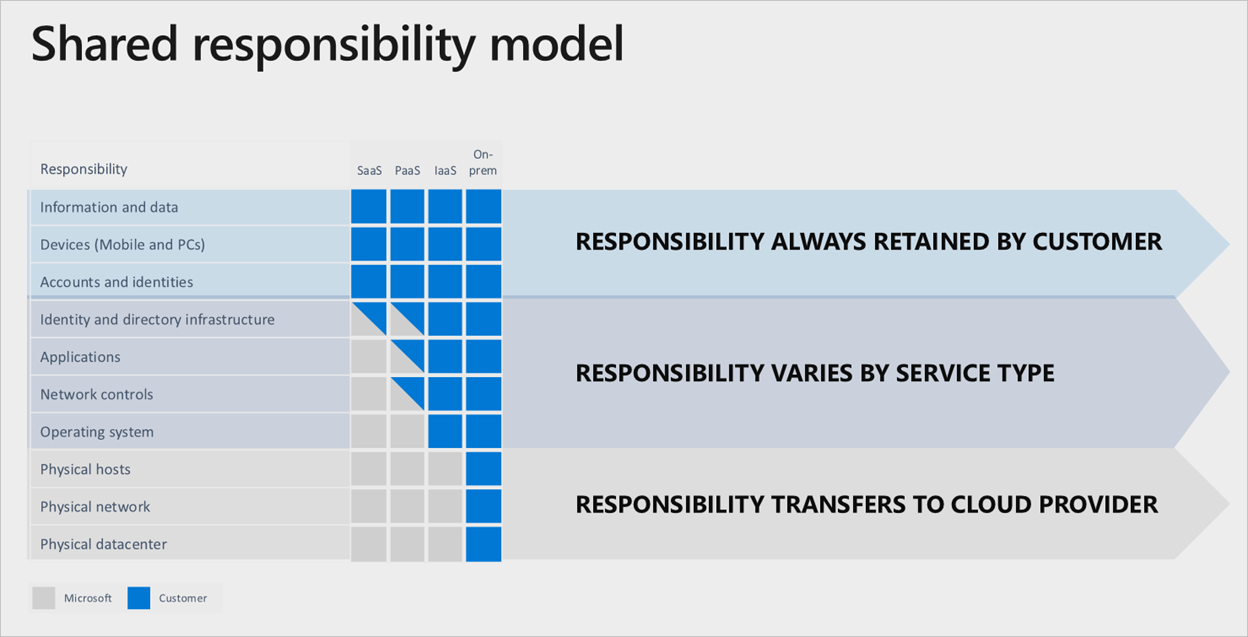 anche se viene usato uno stack SaaS (Software as a Service), il cliente manterrà comunque la responsabilità di garantire gli account, le identità e i dati siano corretti/aggiornati, insieme ai dispositivi usati per interagire con i servizi di Azure.
anche se viene usato uno stack SaaS (Software as a Service), il cliente manterrà comunque la responsabilità di garantire gli account, le identità e i dati siano corretti/aggiornati, insieme ai dispositivi usati per interagire con i servizi di Azure.
Ambito e strategia degli eventi
Ambito eventi di emergenza
Diversi eventi avranno un ambito di impatto diverso e, pertanto, una risposta diversa. Il diagramma seguente illustra questa situazione per un evento di emergenza: 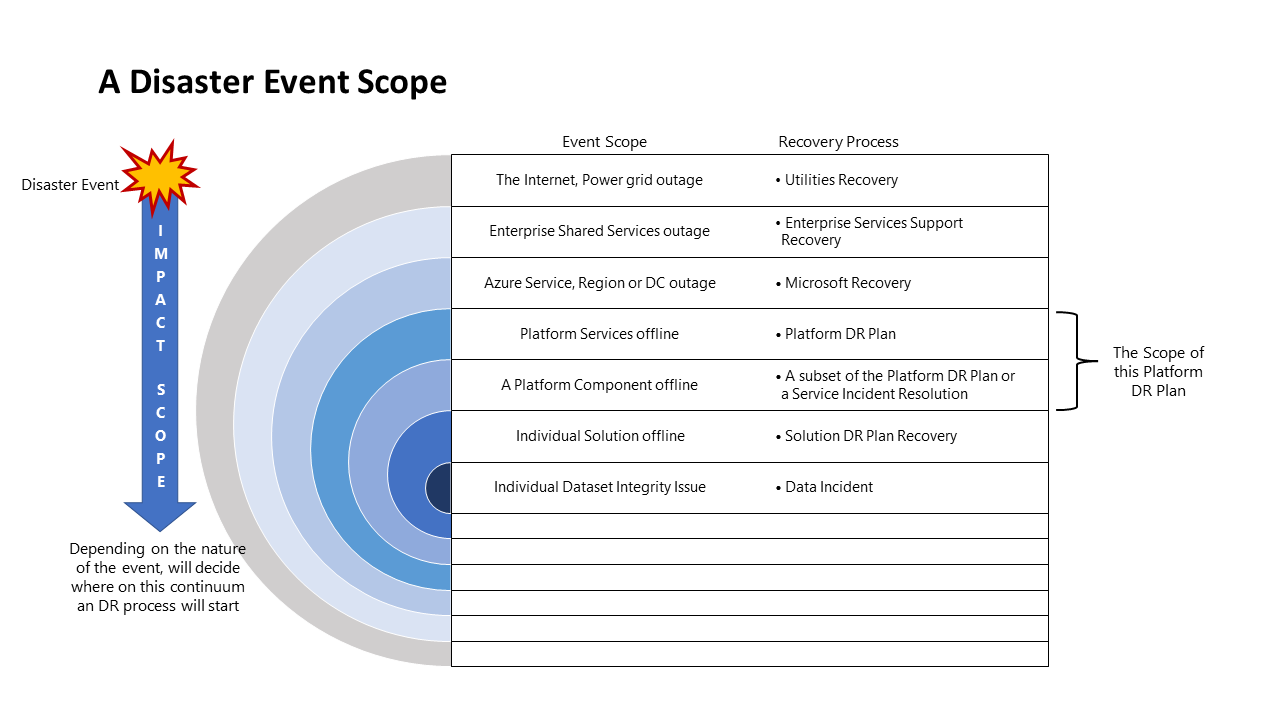
Opzioni di strategia di emergenza
Esistono quattro opzioni generali per una strategia di ripristino di emergenza:
- Attendere Microsoft : come suggerisce il nome, la soluzione è offline fino al ripristino completo dei servizi nell'area interessata da Microsoft. Una volta ripristinata, la soluzione viene convalidata dal cliente e quindi aggiornata per il ripristino del servizio.
- Ridistribuire in caso di emergenza : la soluzione viene ridistribuita manualmente in un'area disponibile da zero, dopo l'emergenza.
- Riserva ad accesso frequente (attivo/passivo): viene creata una soluzione ospitata secondaria in un'area alternativa e i componenti vengono distribuiti per garantire una capacità minima. Tuttavia, i componenti non ricevono il traffico di produzione. I servizi secondari nell'area alternativa possono essere "disattivati" o eseguiti a un livello di prestazioni inferiore fino a quando non si verifica un evento di ripristino di emergenza.
- Riserva a caldo (attivo/attivo): la soluzione è ospitata in una configurazione attiva/attiva in più aree. La soluzione ospitata secondaria riceve, elabora e gestisce i dati come parte del sistema più ampio.
Impatto sulla strategia di ripristino di emergenza
Anche se il costo operativo attribuito ai livelli più elevati di resilienza del servizio spesso domina la decisione di progettazione chiave (KDD) per una strategia di ripristino di emergenza. Ci sono altre considerazioni importanti.
Nota
L'ottimizzazione dei costi è uno dei cinque pilastri dell'eccellenza dell'architettura con Azure Well-Architected Framework. Il suo obiettivo è ridurre le spese non necessarie e migliorare l'efficienza operativa.
Lo scenario di ripristino di emergenza per questo esempio ha funzionato è un'interruzione completa dell'area di Azure che influisce direttamente sull'area primaria che ospita contoso Data Platform.
Per questo scenario di interruzione, l'impatto relativo sulle quattro strategie di ripristino di emergenza di alto livello sono: 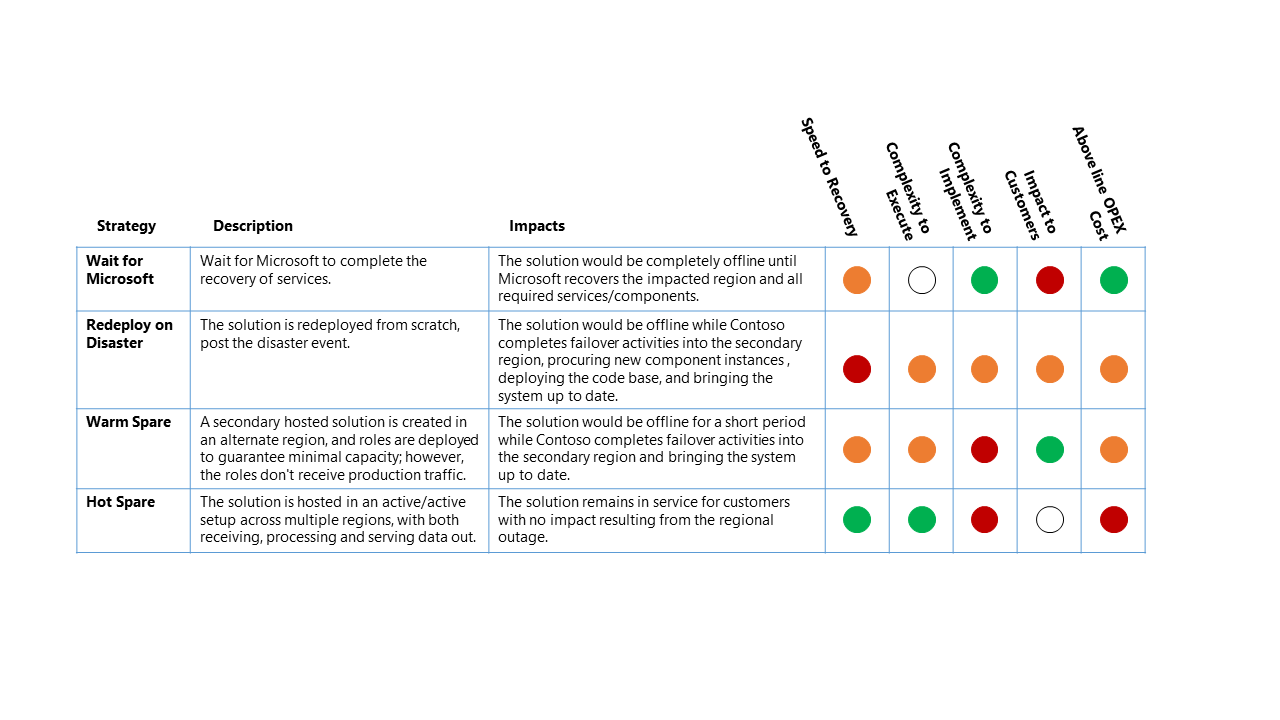
Chiave di classificazione
- Obiettivo del tempo di ripristino (RTO): tempo trascorso previsto dall'evento di emergenza al ripristino del servizio della piattaforma.
- Complessità da eseguire: complessità per l'esecuzione delle attività di ripristino da parte dell'organizzazione.
- Complessità da implementare: complessità per l'organizzazione per implementare la strategia di ripristino di emergenza.
- Impatto sui clienti: impatto diretto per i clienti del servizio piattaforma dati dalla strategia di ripristino di emergenza.
- Costo OPEX sopra riportato: il costo aggiuntivo previsto dall'implementazione di questa strategia, ad esempio l'aumento della fatturazione mensile per Azure per componenti aggiuntivi e risorse aggiuntive necessarie per il supporto.
Nota
La tabella precedente deve essere letta come confronto tra le opzioni: una strategia con un indicatore verde è migliore per tale classificazione rispetto a un'altra strategia con un indicatore giallo o rosso.
Passaggi successivi
Dopo aver appreso le raccomandazioni correlate allo scenario, è possibile apprendere come distribuire questo scenario