Esercitazione: Parte 3: Valutare un'applicazione di chat personalizzata con Azure AI Foundry SDK
In questa esercitazione si usa Azure AI SDK (e altre librerie) per valutare l'app di chat compilata nella parte 2 della serie di esercitazioni. In questa terza parte si apprenderà come:
- Creare un set di dati di valutazione
- Valutare l'app di chat con gli analizzatori di intelligenza artificiale di Azure
- Scorrere e migliorare l'app
Questa esercitazione è la terza parte di tre.
Prerequisiti
- Per compilare l'applicazione di chat, è necessario completare la parte 2 della serie di esercitazioni.
- Assicurarsi di aver completato i passaggi per aggiungere la registrazione dei dati di telemetria dalla parte 2.
Valutare la qualità delle risposte dell'app di chat
Ora che si sa che l'app di chat risponde bene alle query, inclusa la cronologia delle chat, è il momento di valutare le prestazioni in alcune metriche diverse e altri dati.
Si usa un analizzatore con un set di dati di valutazione e la get_chat_response() funzione di destinazione, quindi si valutano i risultati della valutazione.
Dopo aver eseguito una valutazione, è possibile apportare miglioramenti alla logica, ad esempio migliorare la richiesta di sistema e osservare come cambiano e migliorano le risposte dell'app di chat.
Creare un set di dati di valutazione
Usare il seguente set di dati di valutazione, che contiene domande di esempio e risposte previste (verità).
Creare un file denominato chat_eval_data.jsonl nella cartella assets .
Incollare questo set di dati nel file:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Valutare con gli analizzatori di intelligenza artificiale di Azure
Definire ora uno script di valutazione che:
- Generare un wrapper di funzione di destinazione intorno alla logica dell'app di chat.
- Caricare il set di dati
.jsonldi esempio. - Eseguire la valutazione, che accetta la funzione di destinazione e unisce il set di dati di valutazione con le risposte dell'app di chat.
- Generare un set di metriche assistite da GPT (pertinenza, allineamento e coerenza) per valutare la qualità delle risposte dell'app di chat.
- Restituisce i risultati in locale e registra i risultati nel progetto cloud.
Lo script consente di esaminare i risultati in locale, eseguendo l'output dei risultati nella riga di comando e in un file JSON.
Lo script registra anche i risultati della valutazione nel progetto cloud in modo da poter confrontare le esecuzioni di valutazione nell'interfaccia utente.
Creare un file denominato evaluate.py nella cartella principale.
Aggiungere il codice seguente per importare le librerie necessarie, creare un client di progetto e configurare alcune impostazioni:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Aggiungere codice per creare una funzione wrapper che implementa l'interfaccia di valutazione per la valutazione delle query e della risposta:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Aggiungere infine il codice per eseguire la valutazione, visualizzare i risultati in locale e fornire un collegamento ai risultati della valutazione nel portale di Azure AI Foundry:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Configurare il modello di valutazione
Poiché lo script di valutazione chiama il modello più volte, è possibile aumentare il numero di token al minuto per il modello di valutazione.
Nella parte 1 di questa serie di esercitazioni è stato creato un file con estensione env che specifica il nome del modello di valutazione, gpt-4o-mini. Provare ad aumentare il limite di token al minuto per questo modello, se è disponibile una quota. Se non si dispone di una quota sufficiente per aumentare il valore, non preoccuparti. Lo script è progettato per gestire gli errori limite.
- Nel progetto nel portale di Azure AI Foundry selezionare Modelli e endpoint.
- Selezionare gpt-4o-mini.
- Seleziona Modifica
- Se si dispone di una quota per aumentare il limite di velocità dei token al minuto, provare ad aumentarlo a 30.
- Seleziona Salva e chiudi.
Eseguire lo script di valutazione
Dalla console accedere all'account Azure con l'interfaccia della riga di comando di Azure:
az loginInstallare il pacchetto necessario:
pip install azure-ai-evaluation[remote]Eseguire ora lo script di valutazione:
python evaluate.py
Interpretare l'output di valutazione
Nell'output della console viene visualizzata una risposta per ogni domanda, seguita da una tabella con metriche riepilogate. È possibile che nell'output vengano visualizzate colonne diverse.
Se non è stato possibile aumentare il limite di token al minuto per il modello, potrebbero verificarsi errori di timeout, che sono previsti. Lo script di valutazione è progettato per gestire questi errori e continuare l'esecuzione.
Nota
È anche possibile vedere molti WARNING:opentelemetry.attributes: : questi possono essere ignorati in modo sicuro e non influiscono sui risultati della valutazione.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Visualizzare i risultati della valutazione nel portale di Azure AI Foundry
Al termine dell'esecuzione della valutazione, seguire il collegamento per visualizzare i risultati della valutazione nella pagina Valutazione nel portale di Azure AI Foundry.
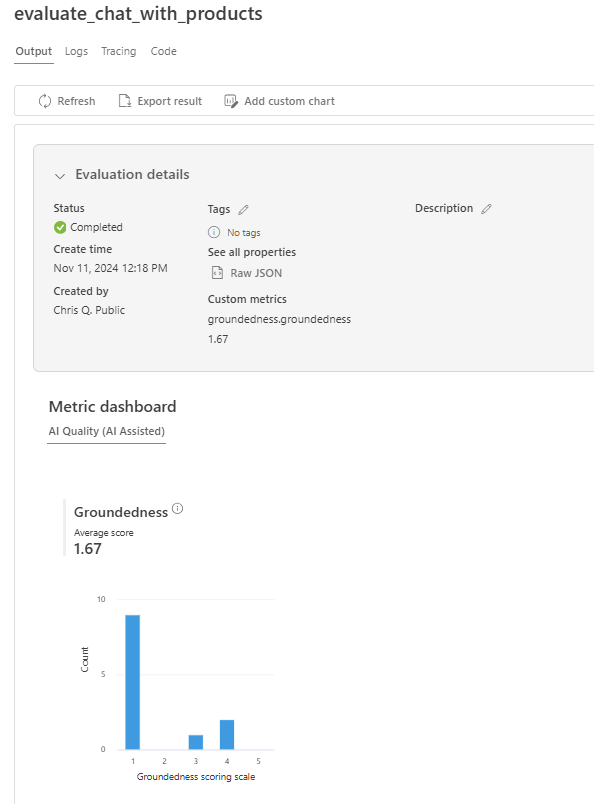
È anche possibile esaminare le singole righe e visualizzare i punteggi delle metriche per riga e visualizzare il contesto completo o i documenti recuperati. Queste metriche possono essere utili per interpretare e eseguire il debug dei risultati della valutazione.
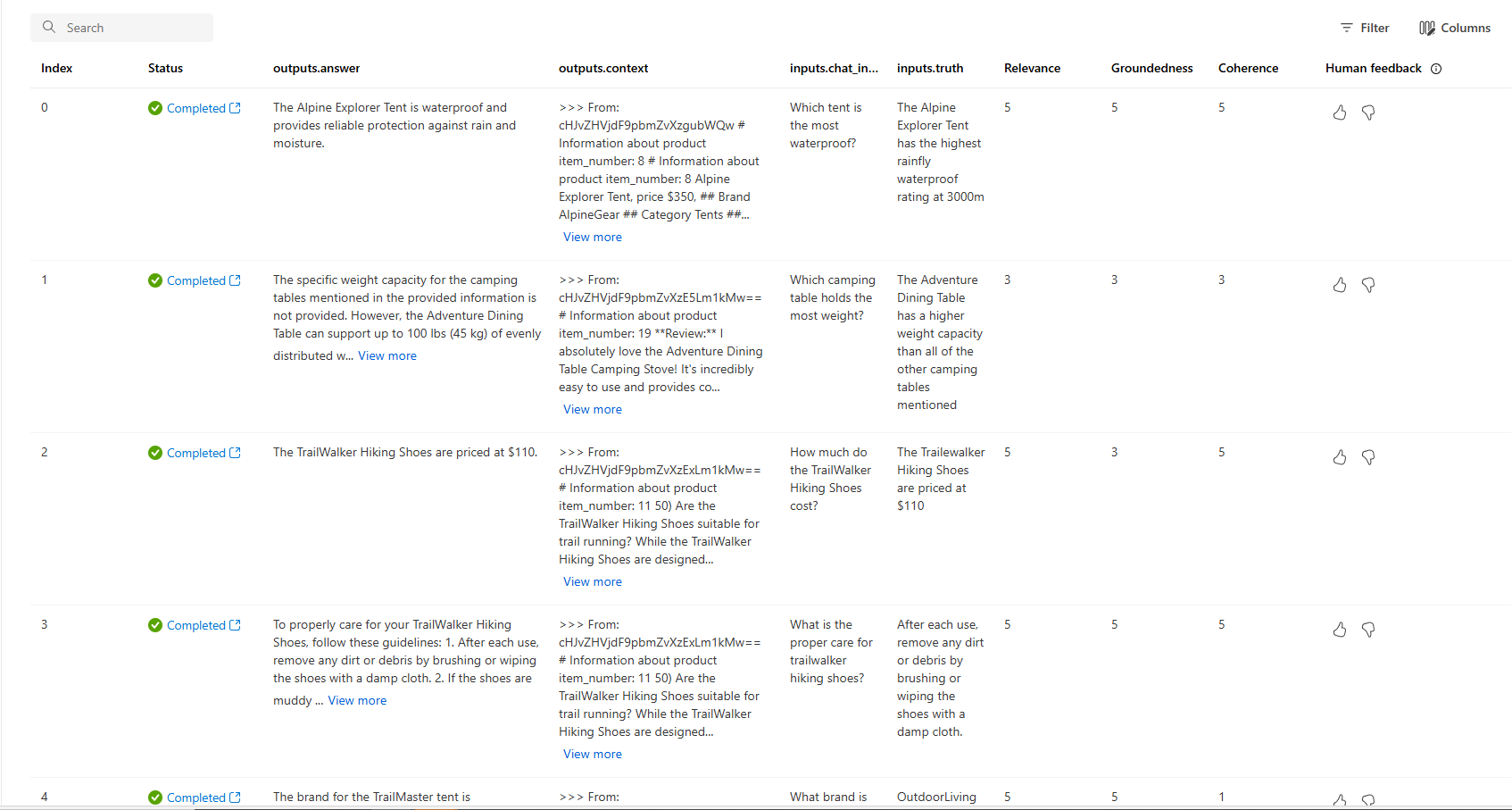
Per altre informazioni sui risultati della valutazione nel portale di Azure AI Foundry, vedere Come visualizzare i risultati della valutazione nel portale di Azure AI Foundry.
Eseguire l'iterazione e migliorare
Si noti che le risposte non sono ben a terra. In molti casi, il modello risponde con una domanda anziché una risposta. Questo è il risultato delle istruzioni del modello di richiesta.
- Nel file asset/grounded_chat.prompty trovare la frase "Se la domanda è correlata all'attrezzatura all'aperto/campeggio e all'abbigliamento ma vago, chiedere domande chiare invece di fare riferimento a documenti."
- Modificare la frase in "Se la domanda è correlata all'attrezzatura all'aperto/campeggio e all'abbigliamento, ma vago, cercare di rispondere in base ai documenti di riferimento, quindi porre domande chiare".
- Salvare il file ed eseguire nuovamente lo script di valutazione.
Provare altre modifiche al modello di richiesta o provare modelli diversi per vedere in che modo le modifiche influiscono sui risultati della valutazione.
Pulire le risorse
Per evitare di incorrere in costi di Azure superflui, è necessario eliminare le risorse create in questo avvio rapido, se non sono più richieste. Per gestire le risorse, è possibile usare il portale di Azure.