Monitorare la qualità e l'utilizzo dei token di applicazioni del prompt flow distribuite
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Il monitoraggio delle applicazioni distribuite nell'ambiente di produzione è una parte essenziale del ciclo di vita delle applicazioni di intelligenza artificiale generativa. Le modifiche apportate ai dati e al comportamento dei consumatori possono influenzare l'applicazione nel tempo, portando a sistemi obsoleti che influiscono negativamente sui risultati aziendali ed espongono le organizzazioni a rischi di conformità, economici e di reputazione.
Nota
Per un modo migliorato per eseguire il monitoraggio continuo delle applicazioni distribuite (ad eccezione del flusso di richieste), valutare l'uso della valutazione online di Intelligenza artificiale di Azure.
Il monitoraggio di Azure per intelligenza artificiale relativo ad applicazioni di intelligenza artificiale generativa consente di monitorare le applicazioni nell'ambiente di produzione per controllare l'utilizzo di token, la qualità della generazione e le metriche relative al funzionamento.
Le integrazioni per il monitoraggio di una distribuzione del prompt flow consentono di:
- Raccogliere i dati di inferenza di produzione dall'applicazione del prompt flow distribuita.
- Applicare metriche di valutazione dell'intelligenza artificiale responsabile, tra cui radicamento, coerenza, scorrevolezza e pertinenza, che sono interoperabili con le metriche di valutazione del prompt flow.
- Monitorare le richieste, il completamento e l'utilizzo totale dei token in ogni distribuzione modello nel prompt flow.
- Monitorare le metriche relative al funzionamento, ad esempio il conteggio, la latenza e il tasso di errore delle richieste.
- Usare avvisi preconfigurati e impostazioni predefinite per l'esecuzione del monitoraggio su base ricorrente.
- Usare le visualizzazioni dei dati e configurare un comportamento avanzato nel portale di Azure AI Foundry.
Prerequisiti
Prima di seguire i passaggi descritti in questo articolo, assicurarsi di avere i prerequisiti seguenti:
Una sottoscrizione di Azure con un metodo di pagamento valido. Le sottoscrizioni di Azure gratuite o di valutazione non sono supportate per questo scenario. Se non si dispone di una sottoscrizione di Azure, è possibile creare un account Azure gratuito per iniziare.
Progetto Azure AI Foundry.
Un prompt flow già pronto per la distribuzione. Se non è disponibile, vedere Sviluppare un prompt flow.
I controlli degli accessi in base al ruolo di Azure vengono usati per concedere l'accesso alle operazioni nel portale di Azure AI Foundry. Per eseguire la procedura descritta in questo articolo, all'account utente deve essere assegnato il ruolo di sviluppatore di Azure per intelligenza artificiale nel gruppo di risorse. Per altre informazioni sulle autorizzazioni, vedere Controllo degli accessi in base al ruolo nel portale di Azure AI Foundry.
Requisiti per le metriche di monitoraggio
Le metriche di monitoraggio vengono generate da determinati modelli linguistici GPT all'avanguardia, configurati con istruzioni di valutazione specifiche (modelli di richiesta). Questi modelli fungono da modelli di analizzatore per le attività da sequenza a sequenza. L'uso di questa tecnica per generare metriche di monitoraggio evidenzia notevoli risultati empirici e un'elevata correlazione con la capacità di giudizio umana rispetto alle metriche di valutazione di intelligenza artificiale generativa standard. Per altre informazioni sulla valutazione del prompt flow, vedere gli articoli su come inviare test in blocco e valutare un flusso e sulle metriche di valutazione e monitoraggio per l'intelligenza artificiale generativa.
I modelli GPT che generano metriche di monitoraggio sono i seguenti. Questi modelli GPT sono supportati dal monitoraggio e configurati come risorsa OpenAI di Azure:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Metriche supportate per il monitoraggio
Per il monitoraggio sono supportate le metriche seguenti:
| Metrico | Descrizione |
|---|---|
| Allineamento | Misura il livello di allineamento delle risposte generate dal modello con le informazioni dei dati di origine (contesto definito dall'utente). |
| Pertinenza | Misura l’extent in cui le risposte generate dal modello sono pertinenti e direttamente correlate alle domande indicate. |
| Coerenza | Misura l’extent in cui le risposte generate dal modello sono coerenti e connesse logicamente. |
| Scorrevolezza | Misura la correttezza linguistica della risposta prevista fornita dall’intelligenza artificiale generativa. |
Mapping dei nomi di colonna
Quando si crea il flusso, è necessario verificare il mapping dei nomi di colonna. I nomi delle colonne di dati di input seguenti vengono usati per misurare la sicurezza e la qualità della generazione:
| Nome colonna di input | Definizione | Obbligatorio/facoltativo |
|---|---|---|
| Domanda | La richiesta originale specificata (nota anche come "input" o "domanda") | Richiesto |
| Risposta | Il completamento finale della chiamata API restituita (noto anche come "output" o "risposta") | Richiesto |
| Contesto | Tutti i dati di contesto inviati alla chiamata API, insieme alla richiesta originale. Se, ad esempio, si spera di ottenere risultati della ricerca solo da determinate fonti di informazioni o siti Web certificati, è possibile definire questo contesto nella procedura di valutazione. | Facoltativo |
Parametri richiesti per le metriche
I parametri che sono configurati nell'asset di dati determinano le metriche che è possibile produrre, in base a questa tabella:
| Metric | Domanda | Risposta | Contesto |
|---|---|---|---|
| Coerenza | Richiesto | Richiesto | - |
| Scorrevolezza | Richiesto | Richiesto | - |
| Allineamento | Richiesto | Obbligatorio | Richiesto |
| Pertinenza | Richiesto | Obbligatorio | Richiesto |
Per altre informazioni sui requisiti specifici per il mapping dei dati per ogni metrica, vedere Requisiti delle metriche di query e risposta.
Configurare il monitoraggio per il prompt flow
Per configurare il monitoraggio per l'applicazione del prompt flow, è necessario distribuire l'applicazione del prompt flow con la raccolta dati di inferenza prima di poter configurare il monitoraggio per l'applicazione distribuita.
Distribuire l'applicazione del prompt flow con la raccolta dati di inferenza
In questa sezione si apprenderà come distribuire il prompt flow con la raccolta dati di inferenza abilitata. Per informazioni dettagliate sulla distribuzione del prompt flow, vedere Distribuire un flusso per l'inferenza in tempo reale.
Accedere ad Azure AI Foundry.
Se non si è già nel progetto, selezionarlo.
Selezionare Prompt flow (Flusso prompt) sulla barra di spostamento a sinistra.
Selezionare il prompt flow creato in precedenza.
Nota
In questo articolo si presuppone che sia già stato creato un prompt flow pronto per la distribuzione. Se non è disponibile, vedere Sviluppare un prompt flow.
Verificare che il flusso venga eseguito correttamente e che gli input e gli output necessari siano configurati per le metriche che si vogliono valutare.
Se si specificano i parametri minimi obbligatori (domanda/input e risposta/output), vengono fornite solo due metriche: coerenza e scorrevolezza. È necessario configurare il flusso come descritto nella sezione Requisiti per le metriche di monitoraggio. In questo esempio si usano
question(domanda) echat_history(contesto) come input del flusso eanswer(risposta) come output del flusso.Selezionare Distribuisci per avviare la distribuzione del flusso.
Nella finestra di distribuzione assicurarsi che sia abilitata la raccolta dati di inferenza, che consentirà di raccogliere facilmente i dati di inferenza dell'applicazione nell'archiviazione BLOB. Questa raccolta dati è richiesta per il monitoraggio.
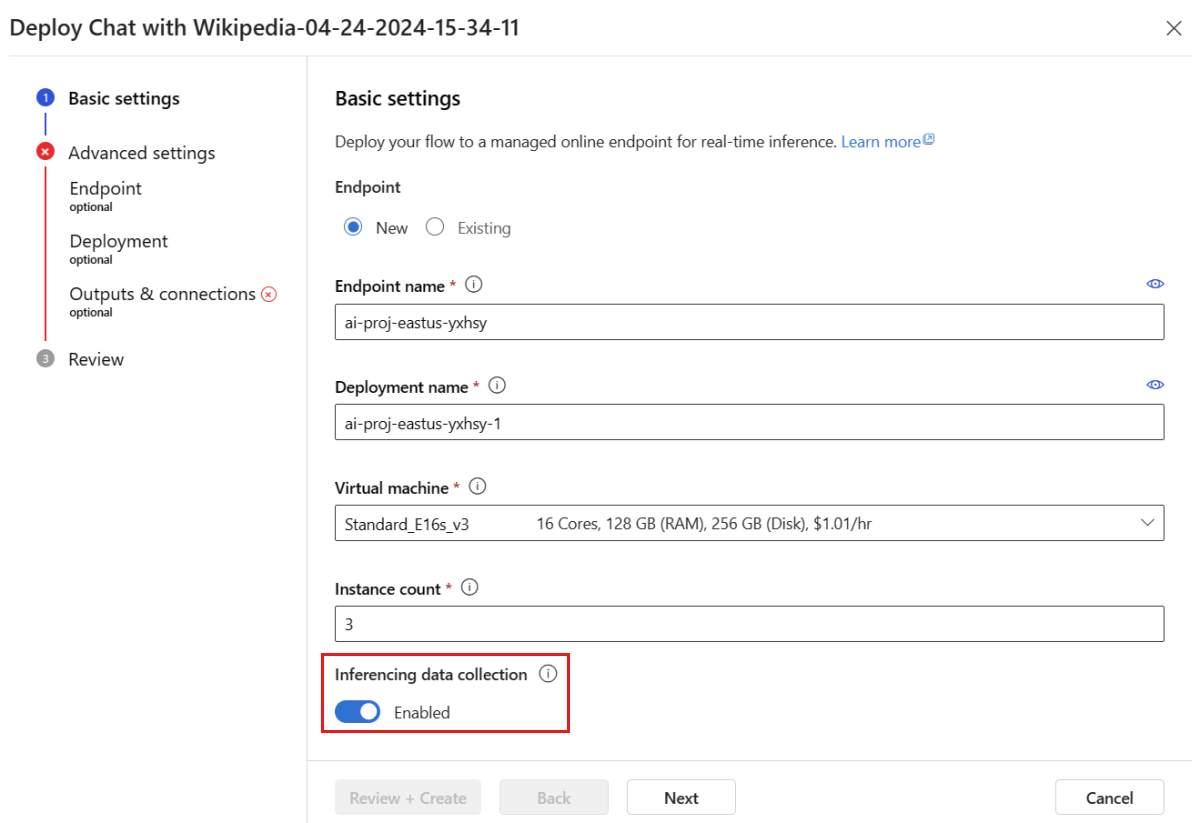
Procedere con i passaggi nella finestra di distribuzione per completare le impostazioni avanzate.
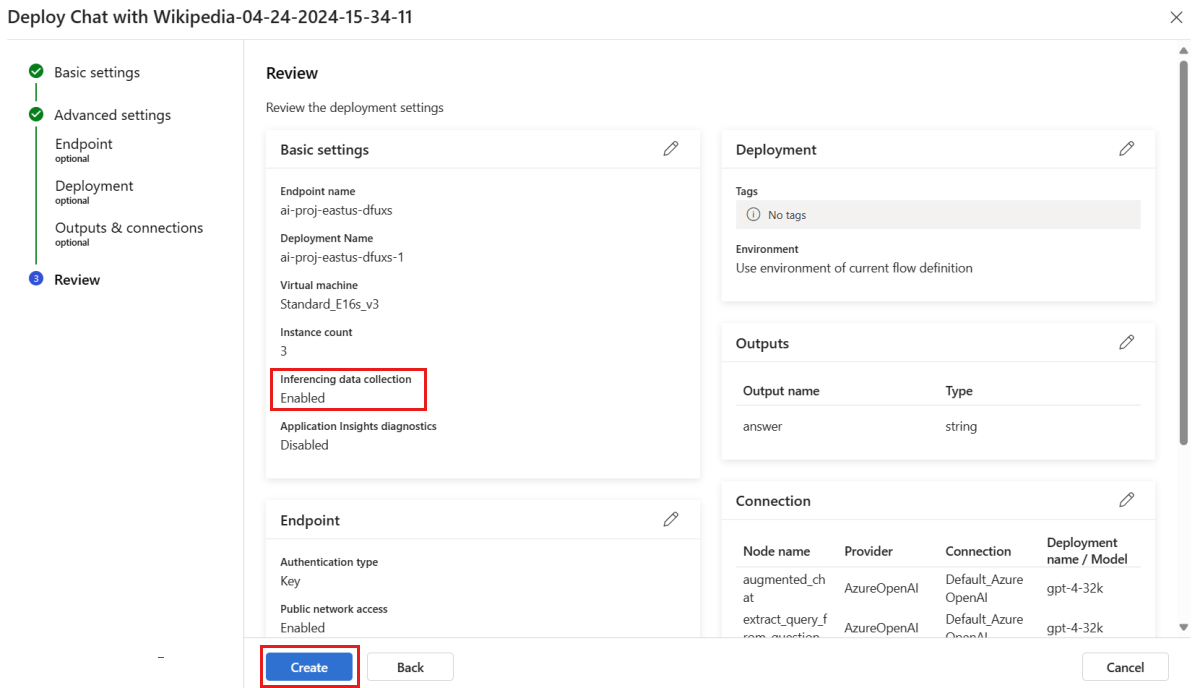
Nella pagina "Verifica" esaminare la configurazione della distribuzione e selezionare Crea per distribuire il flusso.
Nota
Per impostazione predefinita, tutti gli input e gli output dell'applicazione del prompt flow distribuita vengono raccolti nell'archiviazione BLOB. Quando la distribuzione viene richiamata dagli utenti, i dati vengono raccolti e usati dal monitoraggio.
Selezionare la scheda Test nella pagina di distribuzione e testare la distribuzione per assicurarsi che funzioni correttamente.
Nota
Per il monitoraggio è necessario che almeno un punto dati provenga da un'origine diversa dalla scheda Test nella distribuzione. È consigliabile usare l'API REST disponibile nella scheda Utilizzo per inviare richieste di campionamento alla distribuzione. Per altre informazioni su come inviare richieste di campionamento alla distribuzione, vedere Creare una distribuzione online.




Configurare il monitoraggio
In questa sezione viene illustrato come configurare il monitoraggio per l'applicazione del prompt flow distribuita.
Dalla barra di spostamento a sinistra passare a Modelli e endpoint personali>.
Selezionare la distribuzione del prompt flow creata.
Selezionare Abilita nella casella Abilita monitoraggio della qualità della generazione.
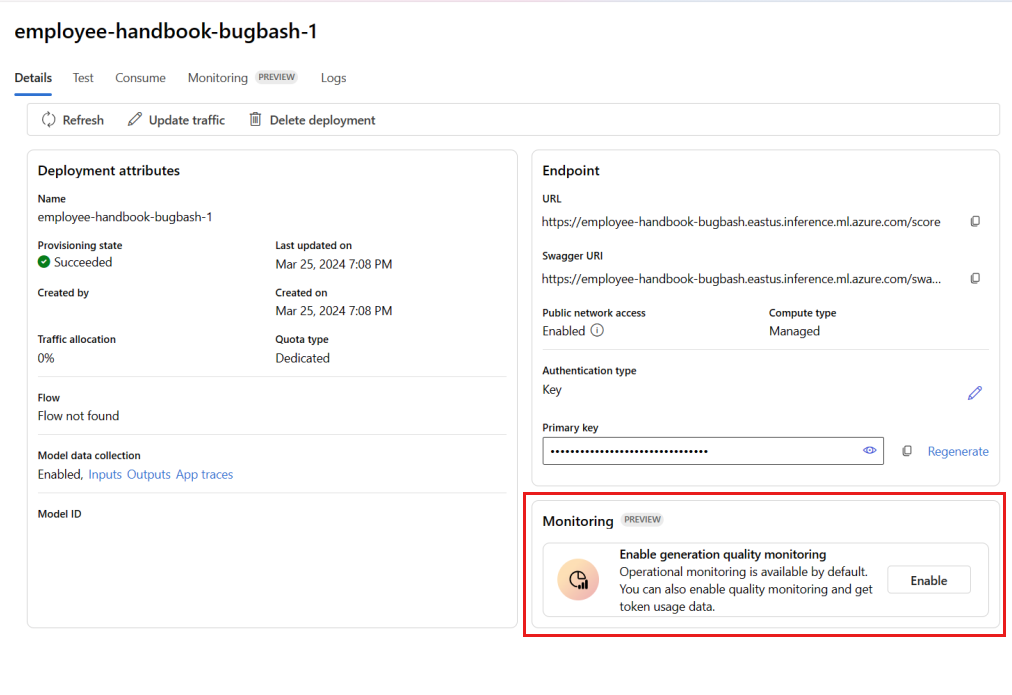
Iniziare a configurare il monitoraggio selezionando le metriche desiderate.
Verificare che il mapping dei nomi di colonna corrisponda a quello definito in Mapping dei nomi di colonna.
Selezionare la connessione OpenAI di Azure e la distribuzione da usare per eseguire il monitoraggio dell'applicazione del prompt flow.
Selezionare Opzioni avanzate per visualizzare altre opzioni da configurare.
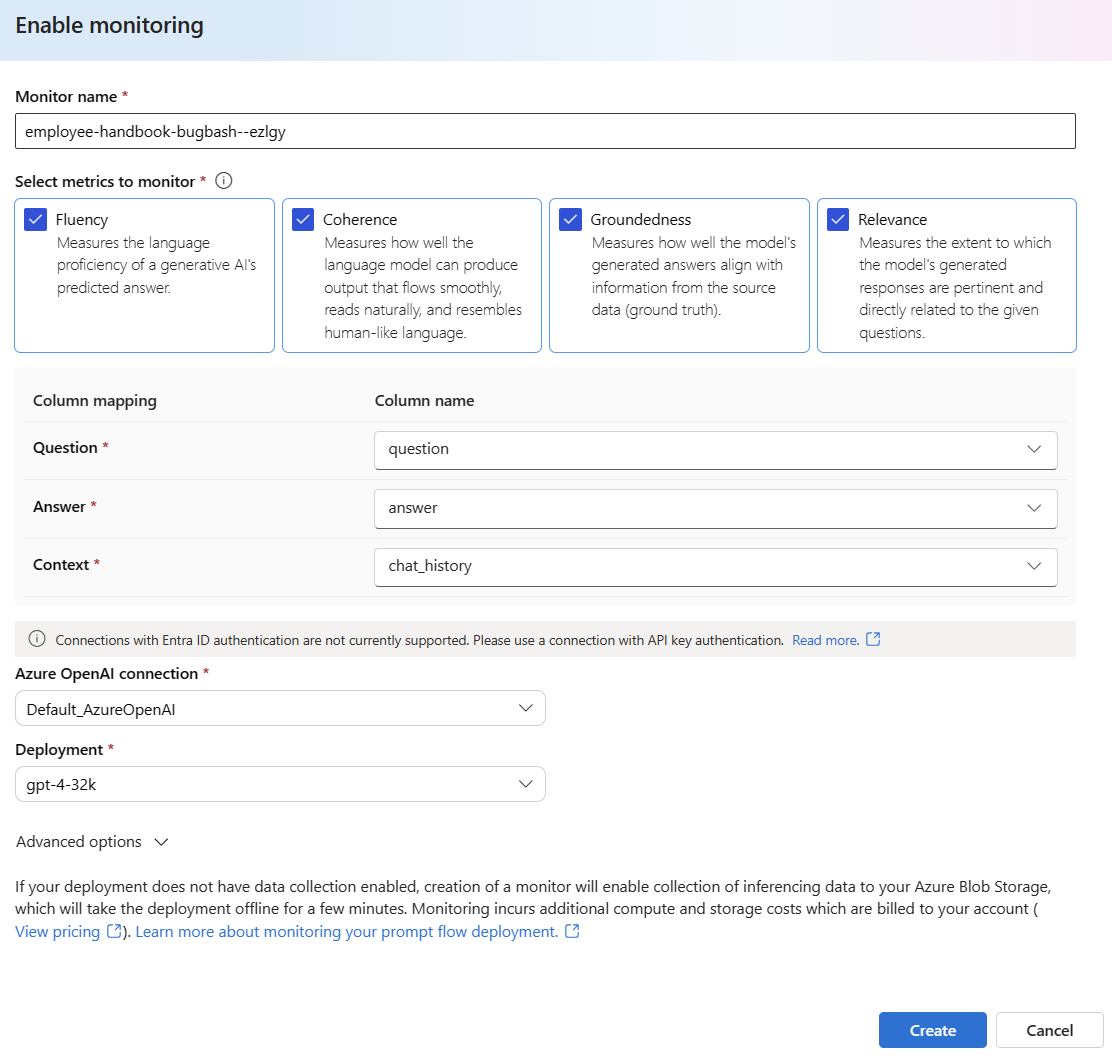
Modificare la frequenza di campionamento, le soglie per le metriche configurate e specificare gli indirizzi di posta elettronica che devono ricevere gli avvisi quando il punteggio medio per una determinata metrica scende al di sotto della soglia.
Nota
Se la raccolta dati non è abilitata per la distribuzione, la creazione di un monitoraggio abiliterà la raccolta dati di inferenza nell'archiviazione BLOB di Azure e la distribuzione risulterà offline per alcuni minuti.
Selezionare Crea per creare il monitoraggio.



Utilizzare i risultati del monitoraggio
Una volta creato, il monitoraggio verrà eseguito ogni giorno per calcolare le metriche relative all'utilizzo dei token e alla qualità della generazione.
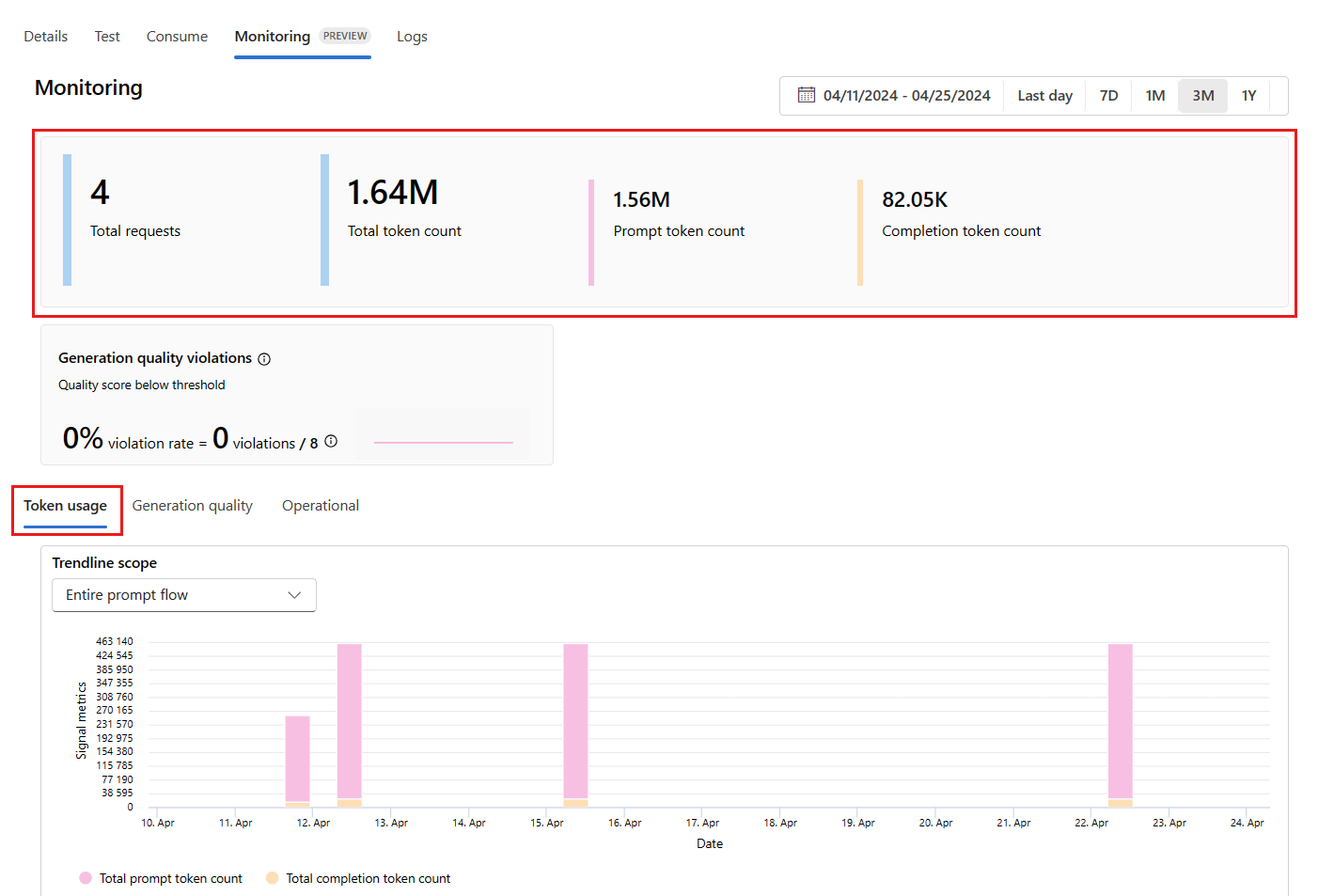
Passare alla scheda Monitoraggio (anteprima) dall'interno della distribuzione per visualizzare i risultati del monitoraggio. In tale scheda è visualizzata una panoramica dei risultati di monitoraggio relativi alla finestra temporale selezionata. È possibile usare la selezione data per modificare la finestra temporale monitorata. In questa panoramica sono disponibili le metriche seguenti:
- Numero totale delle richieste: numero totale delle richieste inviate alla distribuzione durante la finestra temporale selezionata.
- Numero totale di token: numero totale di token usati dalla distribuzione durante la finestra temporale selezionata.
- Numero totale di richieste: numero totale di richieste usate dalla distribuzione durante la finestra temporale selezionata.
- Numero di token di completamento: numero di token di completamento usati dalla distribuzione durante la finestra temporale selezionata.
Visualizzare le metriche nella scheda Utilizzo token (questa scheda è selezionata per impostazione predefinita). In tale scheda è possibile visualizzare l'utilizzo dei token dell'applicazione nel corso del tempo. È anche possibile visualizzare la distribuzione di richieste e token di completamento nel corso del tempo. È possibile modificare l'ambito della linea di tendenza per monitorare tutti i token nell'intera applicazione o l'utilizzo di token relativi a una distribuzione specifica (ad esempio gpt-4) usati nell'applicazione.
Passare alla scheda Qualità della generazione per monitorare la qualità dell'applicazione nel corso del tempo. Le metriche seguenti sono illustrate nel grafico temporale:
- Conteggio delle violazioni: il conteggio delle violazioni relative a una determinata metrica, ad esempio la scorrevolezza, corrisponde alla somma delle violazioni nella finestra temporale selezionata. Viene rilevata una violazione relativa a una metrica quando si calcolano le metriche (con cadenza predefinita giornaliera) e il valore calcolato per la metrica scende al di sotto del valore soglia impostato.
- Punteggio medio: il punteggio medio per una determinata metrica, ad esempio la scorrevolezza, corrisponde alla somma dei punteggi di tutte le istanze (o richieste) diviso per il numero di istanze (o richieste) nella finestra temporale selezionata.
La scheda Violazioni della qualità di generazione mostra il tasso di violazioni nella finestra temporale selezionata. Il tasso di violazioni corrisponde al numero di violazioni diviso per il numero totale di possibili violazioni. È possibile modificare le soglie per le metriche nelle impostazioni. Per impostazione predefinita, le metriche vengono calcolate ogni giorno. Anche questa frequenza può essere modificata nelle impostazioni.
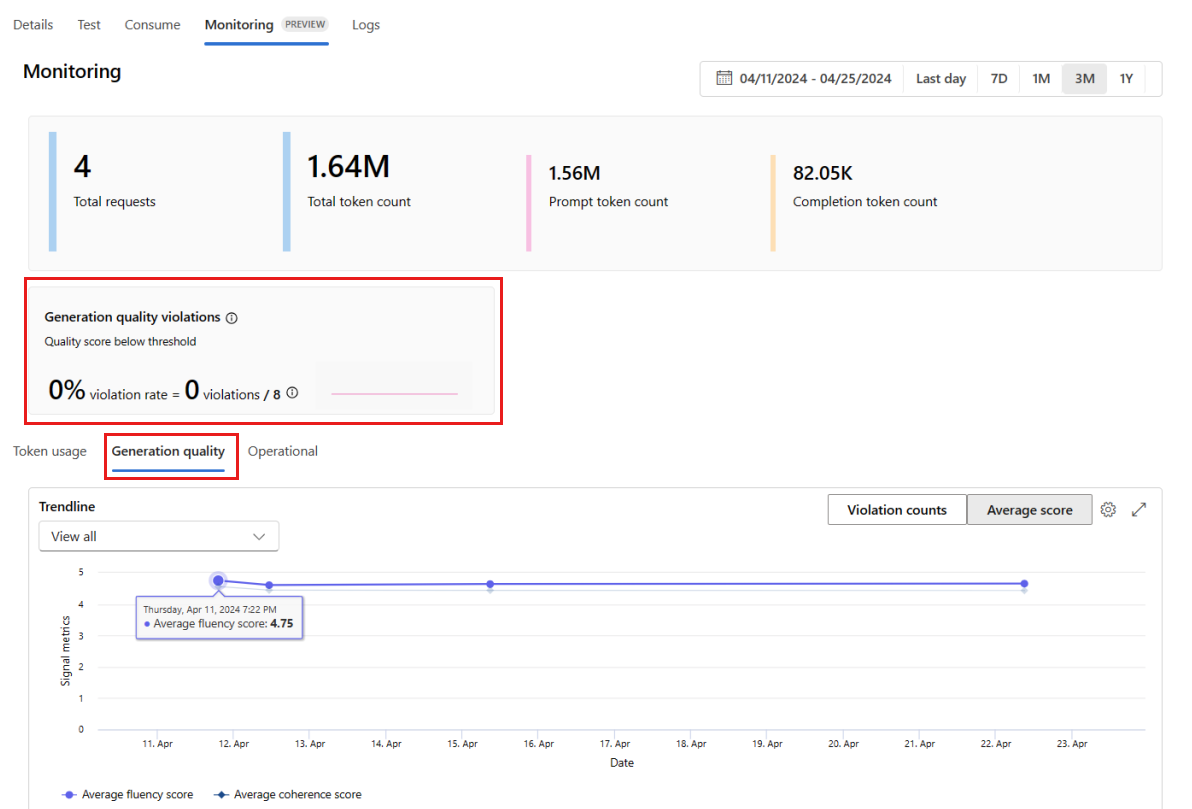
Nella scheda Monitoraggio (anteprima) è anche possibile visualizzare una tabella completa di tutte le richieste campionate inviate alla distribuzione durante la finestra temporale selezionata.
Nota
Il monitoraggio imposta la frequenza di campionamento predefinita al 10%. Questo significa che se alla distribuzione vengono inviate 100 richieste, 10 vengono campionate e usate per calcolare le metriche della qualità della generazione. È possibile regolare la frequenza di campionamento nelle impostazioni.
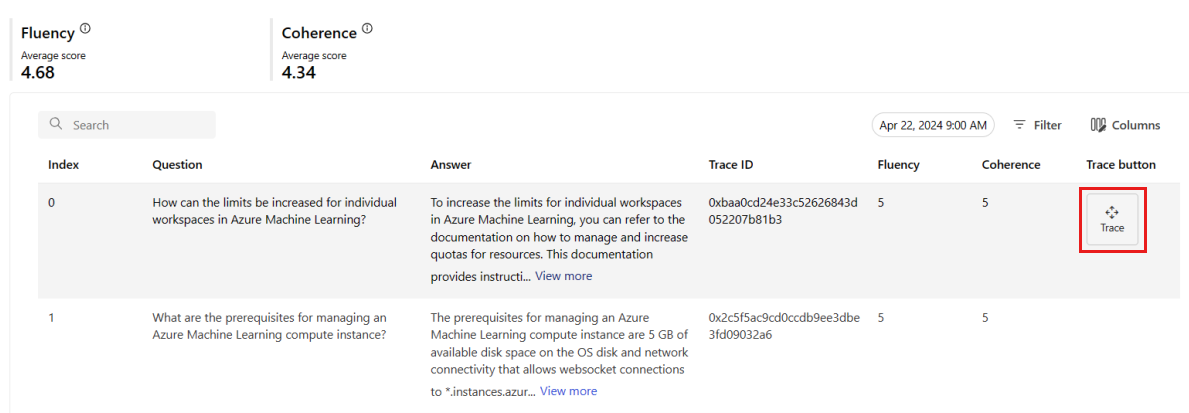
Selezionare il pulsante Traccia a destra di una riga nella tabella per visualizzare i dettagli di traccia per una determinata richiesta. Questa vista fornisce dettagli completi sulla traccia della richiesta all'applicazione.
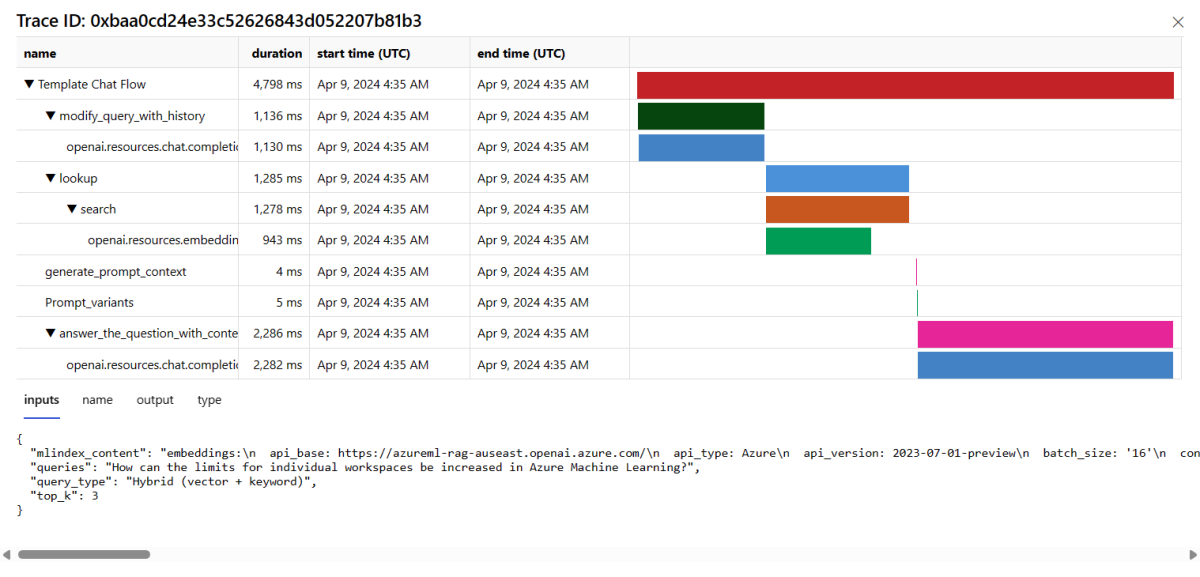
Chiudere la vista Traccia.
Passare alla scheda Funzionamento per visualizzare le metriche di funzionamento per la distribuzione near real-time. Sono supportate le metriche di funzionamento seguenti:
- Conteggio richieste
- Latenza
- Percentuale di errore
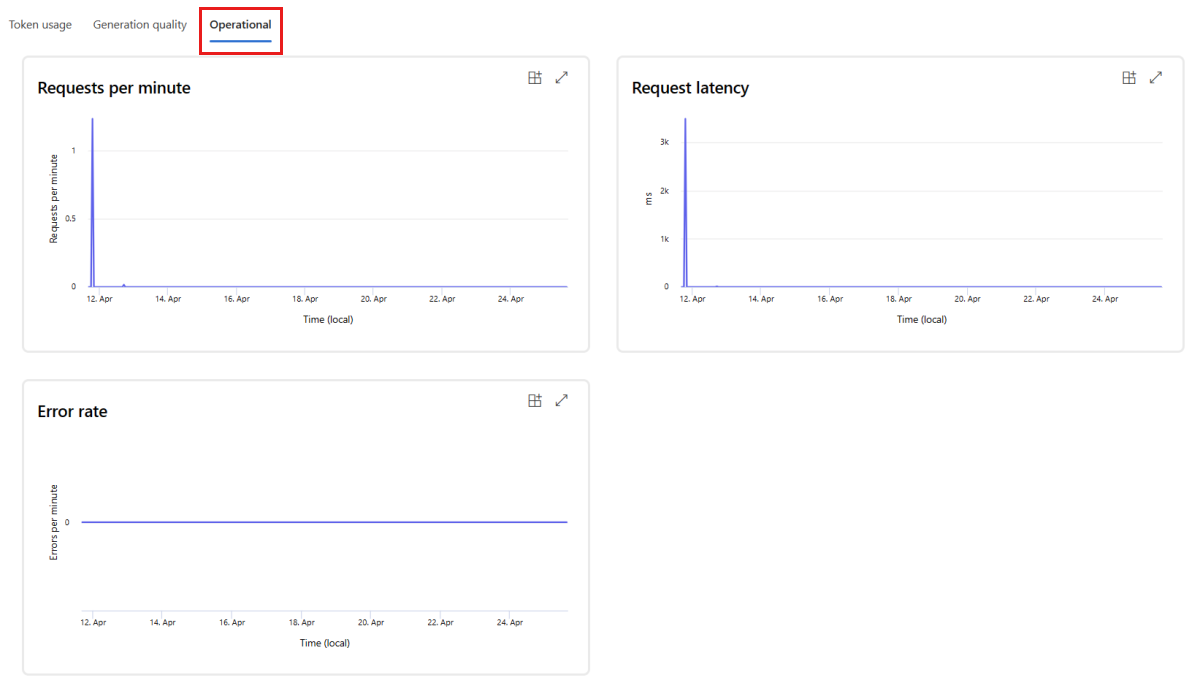





I risultati nella scheda Monitoraggio (anteprima) della distribuzione forniscono informazioni dettagliate per migliorare in modo proattivo le prestazioni dell'applicazione del prompt flow.
Configurazione avanzata del monitoraggio con SDK v2
Il monitoraggio supporta anche opzioni di configurazione avanzate con l'SDK v2. Sono supportati gli scenari che seguono:
Abilitare il monitoraggio relativo all'utilizzo dei token
Se si intende solo abilitare il monitoraggio dell'utilizzo dei token per l'applicazione del prompt flow distribuita, è possibile adattare lo script seguente al proprio scenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Abilitare il monitoraggio per la qualità della generazione
Se si intende solo abilitare il monitoraggio della qualità della generazione per l'applicazione del prompt flow distribuita, è possibile adattare lo script seguente al proprio scenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Dopo aver creato il monitoraggio dall'SDK, è possibile usare i risultati del monitoraggio nel portale di Azure AI Foundry.
Contenuto correlato
- Altre informazioni sulle operazioni che è possibile eseguire in Azure AI Foundry.
- Risposte alle domande frequenti nell'articolo Domande frequenti su Azure per intelligenza artificiale.