Cos’è la diarizzazione multicanale della trascrizione della conversazione? (anteprima)
Nota
Questa funzionalità è attualmente in anteprima pubblica. Questa anteprima viene messa a disposizione senza contratto di servizio e non è consigliata per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
La diarizzazione multicanale della trascrizione della conversazione è una soluzione di riconoscimento vocale che fornisce la trascrizione in tempo reale o asincrona di qualsiasi riunione. Questa funzionalità combina il riconoscimento vocale, l'identificazione voce e l'attribuzione delle frasi per determinare chi ha detto cosa e quando, durante una riunione.
Importante
La diarizzazione multicanale della trascrizione della conversazione (anteprima) viene ritirata il 28 marzo 2025. Per altre informazioni sulla migrazione ad altre funzionalità di riconoscimento vocale, vedere Eseguire la migrazione dalla diarizzazione multicanale della trascrizione della conversazione.
Eseguire la migrazione della diarizzazione multicanale della trascrizione della conversazione
La diarizzazione multicanale della trascrizione della conversazione (anteprima) viene ritirata il 28 marzo 2025.
Per continuare a usare il riconoscimento vocale con la diarizzazione, usare invece le funzionalità seguenti:
- Riconoscimento vocale in tempo reale con diarizzazione
- Trascrizione rapida con diarizzazione
- Trascrizione batch con la diarizzazione
Queste funzionalità di riconoscimento vocale supportano solo la diarizzazione per l'audio a canale singolo. L'audio multicanale usato con la diarizzazione multicanale della trascrizione della conversazione non è supportato.
Funzionalità chiave
È possibile trovare utili le seguenti funzionalità di trascrizione delle conversazioni:
- Timestamp: ogni espressione del parlante ha un timestamp, il che permette di sapere facilmente quando è stata pronunciata una determinata frase.
- Trascrizioni leggibili: le trascrizioni hanno formattazione e punteggiatura aggiunte automaticamente per garantire che il testo corrisponda fedelmente a quanto pronunciato.
- Profili utente: i profili utente vengono generati raccogliendo campioni vocali degli utenti e inviandoli alla generazione della firma.
- Identificazione voce: i parlanti vengono identificati tramite i profili utente e a ognuno viene assegnato un identificatore voce.
- Diarizzazione multi-parlante: consente di determinare chi ha detto cosa sintetizzando il flusso audio con l’identificatore di ogni parlante.
- Trascrizione in tempo reale: vengono fornite trascrizioni in tempo reale che riportano chi sta dicendo cosa e quando, mentre si sta svolgendo la riunione.
- Trascrizione asincrona: vengono fornite trascrizioni con maggiore accuratezza usando un flusso audio multicanale.
Nota
Anche se la trascrizione conversazione non prevede un limite per il numero di parlanti nella stanza, è ottimizzata per 2-10 parlanti per sessione.
Utilizzare casi
Per rendere inclusive le riunioni per tutti, ad esempio per i partecipanti non udenti o con difficoltà uditive, è importante avere trascrizione in tempo reale. La trascrizione delle conversazioni in modalità in tempo reale acquisisce l'audio della riunione e determina chi sta dicendo cosa, consentendo a chiunque partecipi alla riunione di seguire la trascrizione e di partecipare alla riunione, senza ritardi.
I partecipanti possono concentrarsi sulla riunione e lasciare alla trascrizione delle conversazioni il compito di prendere appunti. I partecipanti possono seguire attivamente la riunione e occuparsi rapidamente dei passaggi successivi, usando la trascrizione invece di prendere appunti con la possibilità di perdersi qualcosa durante la riunione.
Funzionamento
Il diagramma seguente mostra una panoramica generale del funzionamento della funzionalità.
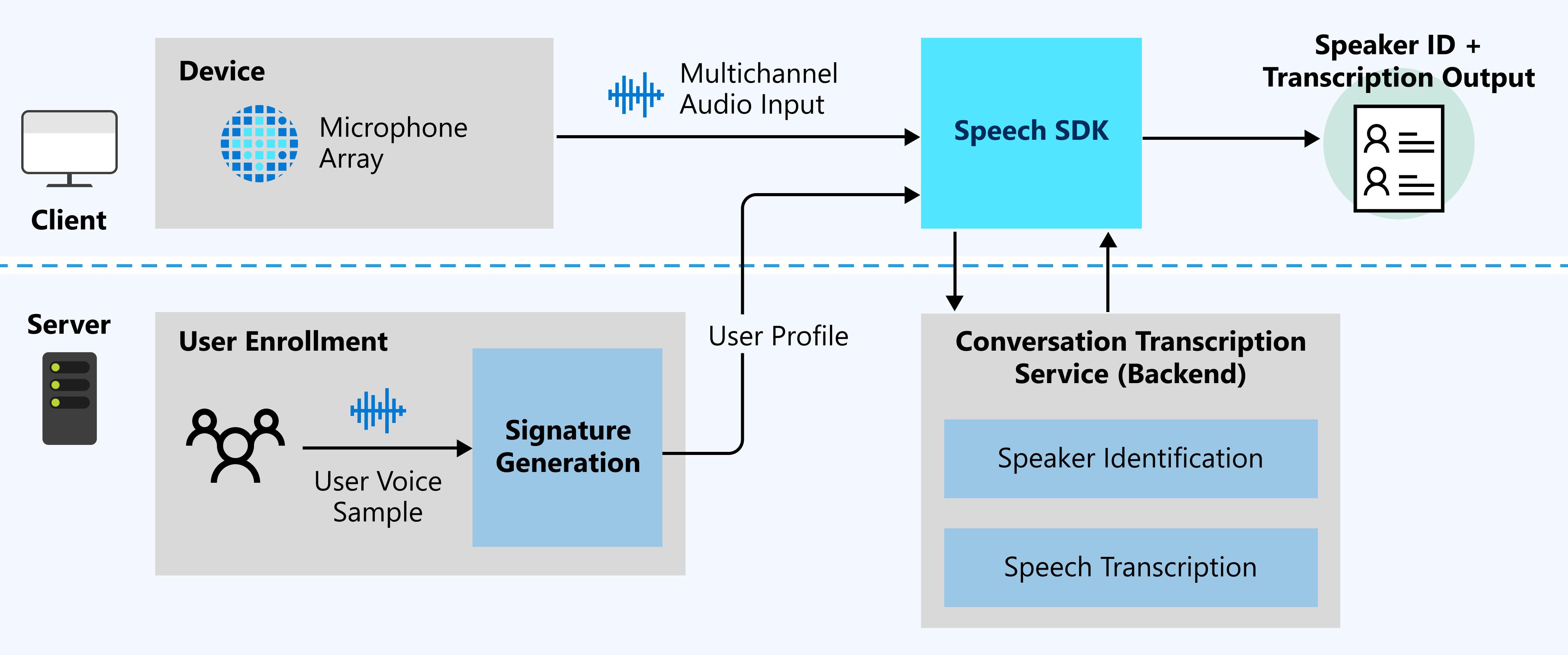
Input previsti
La trascrizione delle conversazioni usa due tipi di input:
- Flusso audio multicanale: per informazioni dettagliate sulle specifiche e sulla progettazione, vedere Raccomandazioni sulla matrice di microfoni.
- Campioni vocali utenti: la trascrizione delle conversazioni richiede i profili degli utente della conversazione in anticipo per l'identificazione della voce. Raccogliere registrazioni audio da ogni utente e quindi inviare le registrazioni al servizio di generazione della firma per convalidare l'audio e generare i profili utente.
I campioni vocali degli utenti per le firme vocali sono necessari per l'identificazione della voce. I parlanti che non hanno campioni vocali vengono riconosciuti come non identificati. I parlanti non identificati possono comunque essere differenziati quando la proprietà DifferentiateGuestSpeakers è abilitata (vedere l'esempio seguente). L'output della trascrizione mostra quindi i parlanti come, ad esempio, Guest_0 e Guest_1, invece di riconoscerli con nomi di parlanti specifici pre-registrati.
config.SetProperty("DifferentiateGuestSpeakers", "true");
In tempo reale o asincrono
Le sezioni seguenti forniscono maggiori dettagli sulle modalità di trascrizione che è possibile scegliere.
In tempo reale
I dati audio vengono elaborati in tempo reale per restituire l'identificatore voce e la trascrizione. Selezionare questa modalità se il requisito della soluzione di trascrizione consiste nel fornire ai partecipanti alla riunione una visualizzazione della trascrizione in tempo reale della riunione in corso. Ad esempio, la creazione di un'applicazione per rendere le riunioni più accessibili ai partecipanti non udenti o con difficoltà uditive è un caso d'uso ideale per la trascrizione in tempo reale.
Asincrona
I dati audio vengono elaborati in batch per restituire l'identificatore voce e la trascrizione. Selezionare questa modalità se il requisito della soluzione di trascrizione consiste nel fornire un'accuratezza maggiore, senza la visualizzazione della trascrizione in tempo reale. Ad esempio, se si vuole creare un'applicazione per consentire ai partecipanti alla riunione di recuperare facilmente le riunioni perse, usare la modalità di trascrizione asincrona per ottenere risultati di trascrizione ad alta accuratezza.
In tempo reale più asincrono
I dati audio vengono elaborati in tempo reale per restituire l'identificatore voce e la trascrizione, inoltre, è richiesta una trascrizione ad alta accuratezza tramite l'elaborazione asincrona. Selezionare questa modalità se l'applicazione ha bisogno di una trascrizione in tempo reale e allo stesso tempo di una trascrizione più accurata da poter usare dopo la riunione.
Supporto di lingua e area geografica
Attualmente, la trascrizione delle conversazioni supporta tutte le lingue di riconoscimento vocale nelle aree seguenti: centralus, eastasia, eastus, westeurope.