Guida introduttiva: Introduzione alla generazione di audio OpenAI di Azure
I gpt-4o-audio-preview modelli e gpt-4o-mini-audio-preview introducono la modalità audio nell'API esistente /chat/completions . Il modello audio espande il potenziale per le applicazioni di intelligenza artificiale nelle interazioni di testo e in base alla voce e all'analisi audio. Le modalità supportate in gpt-4o-audio-preview e gpt-4o-mini-audio-preview i modelli includono: testo, audio e testo + audio.
Ecco una tabella delle modalità supportate con casi d'uso di esempio:
| Input modalità | Output modalità | Esempio di caso d'uso |
|---|---|---|
| Testo | Testo e audio | Sintesi vocale, generazione di audiobook |
| Audio | Testo e audio | Trascrizione audio, generazione di audiobook |
| Audio | Testo | Trascrizione audio |
| Testo e audio | Testo e audio | Generazione di audiobook |
| Testo e audio | Testo | Trascrizione audio |
Usando le funzionalità di generazione audio, è possibile ottenere applicazioni di intelligenza artificiale più dinamiche e interattive. I modelli che supportano input audio e output consentono di generare risposte audio vocali alle richieste e usare input audio per richiedere il modello.
Modelli supportati
Attualmente solo gpt-4o-audio-preview e gpt-4o-mini-audio-preview versione: 2024-12-17 supporta la generazione di audio.
Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
Attualmente sono supportate le voci seguenti per l'audio: Lega, Echo e Shimmer.
La dimensione massima del file audio è di 20 MB.
Nota
L'API Realtime usa lo stesso modello audio GPT-4o sottostante dell'API di completamento, ma è ottimizzato per interazioni audio in tempo reale a bassa latenza.
Supporto dell'API
Il supporto per i completamenti audio è stato aggiunto per la prima volta nella versione 2025-01-01-previewdell'API .
Distribuire un modello per la generazione di audio
Per distribuire il gpt-4o-mini-audio-preview modello nel portale di Azure AI Foundry:
- Passare alla pagina servizio Azure OpenAI nel portale di Azure AI Foundry. Assicurarsi di aver eseguito l'accesso con la sottoscrizione di Azure con la risorsa del servizio Azure OpenAI e il modello distribuito
gpt-4o-mini-audio-preview. - Selezionare il playground chat in Playgrounds (Playground) nel riquadro sinistro.
- Selezionare + Crea nuova distribuzione>Da modelli di base per aprire la finestra di distribuzione.
- Cercare e selezionare il
gpt-4o-mini-audio-previewmodello e quindi selezionare Distribuisci nella risorsa selezionata. - Nella distribuzione guidata selezionare la versione del
2024-12-17modello. - Seguire la procedura guidata per completare la distribuzione del modello.
Ora che è disponibile una distribuzione del gpt-4o-mini-audio-preview modello, è possibile interagire con esso nell'API Chat playground o completamento chat del portale di Azure AI Foundry.
Usare la generazione di audio GPT-4o
Per chattare con il modello distribuito gpt-4o-mini-audio-preview nel playground chat del portale di Azure AI Foundry, seguire questa procedura:
Passare alla pagina servizio Azure OpenAI nel portale di Azure AI Foundry. Assicurarsi di aver eseguito l'accesso con la sottoscrizione di Azure con la risorsa del servizio Azure OpenAI e il modello distribuito
gpt-4o-mini-audio-preview.Selezionare il playground chat da in Area giochi risorse nel riquadro sinistro.
Selezionare il modello distribuito
gpt-4o-mini-audio-previewdall'elenco a discesa Distribuzione .Iniziare a chattare con il modello e ascoltare le risposte audio.
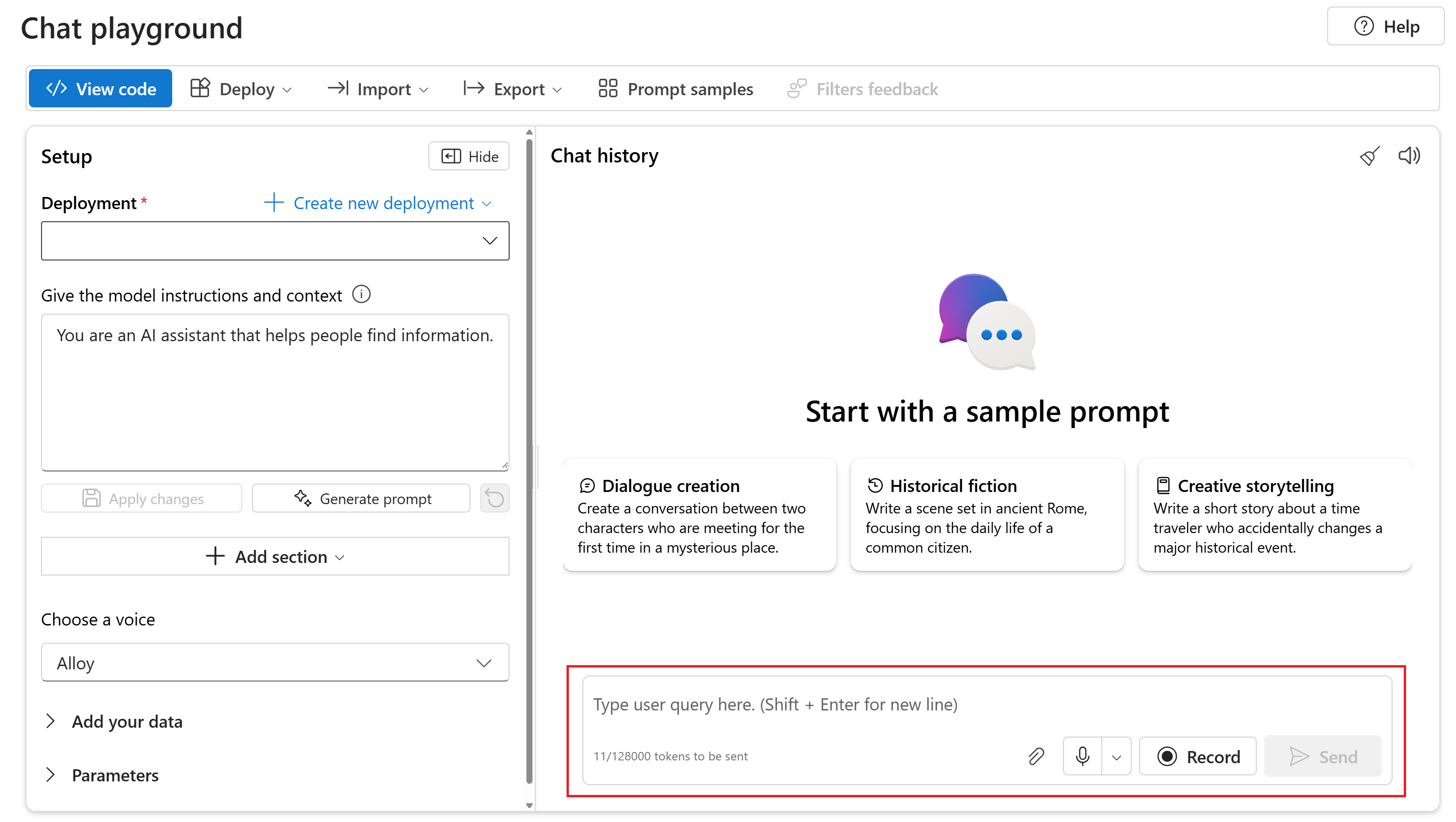
È possibile:
- Registra richieste audio.
- Allegare file audio alla chat.
- Immettere le richieste di testo.

Documentazione di riferimento | Codice sorgente della libreria | Pacchetto (npm) | Esempi
I gpt-4o-audio-preview modelli e gpt-4o-mini-audio-preview introducono la modalità audio nell'API esistente /chat/completions . Il modello audio espande il potenziale per le applicazioni di intelligenza artificiale nelle interazioni di testo e in base alla voce e all'analisi audio. Le modalità supportate in gpt-4o-audio-preview e gpt-4o-mini-audio-preview i modelli includono: testo, audio e testo + audio.
Ecco una tabella delle modalità supportate con casi d'uso di esempio:
| Input modalità | Output modalità | Esempio di caso d'uso |
|---|---|---|
| Testo | Testo e audio | Sintesi vocale, generazione di audiobook |
| Audio | Testo e audio | Trascrizione audio, generazione di audiobook |
| Audio | Testo | Trascrizione audio |
| Testo e audio | Testo e audio | Generazione di audiobook |
| Testo e audio | Testo | Trascrizione audio |
Usando le funzionalità di generazione audio, è possibile ottenere applicazioni di intelligenza artificiale più dinamiche e interattive. I modelli che supportano input audio e output consentono di generare risposte audio vocali alle richieste e usare input audio per richiedere il modello.
Modelli supportati
Attualmente solo gpt-4o-audio-preview e gpt-4o-mini-audio-preview versione: 2024-12-17 supporta la generazione di audio.
Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
Attualmente sono supportate le voci seguenti per l'audio: Lega, Echo e Shimmer.
La dimensione massima del file audio è di 20 MB.
Nota
L'API Realtime usa lo stesso modello audio GPT-4o sottostante dell'API di completamento, ma è ottimizzato per interazioni audio in tempo reale a bassa latenza.
Supporto dell'API
Il supporto per i completamenti audio è stato aggiunto per la prima volta nella versione 2025-01-01-previewdell'API .
Prerequisiti
- Una sottoscrizione di Azure: creare un account gratuitamente
- Node.js supporto LTS o ESM.
- Una risorsa OpenAI di Azure creata in una delle aree supportate. Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
- È quindi necessario distribuire un
gpt-4o-mini-audio-previewmodello con la risorsa OpenAI di Azure. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
Prerequisiti di Microsoft Entra ID
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, è necessario:
- Installare l'interfaccia della riga di comando di Azure usata per l'autenticazione senza chiave con Microsoft Entra ID.
- Assegnare il ruolo
Cognitive Services Userall'account utente. È possibile assegnare ruoli nella portale di Azure in Controllo di accesso (IAM)>Aggiungere un'assegnazione di ruolo.
Impostazione
Creare una nuova cartella
audio-completions-quickstartper contenere l'applicazione e aprire Visual Studio Code in tale cartella con il comando seguente:mkdir audio-completions-quickstart && code audio-completions-quickstartpackage.jsonCreare con il comando seguente:npm init -yAggiornare in
package.jsonECMAScript con il comando seguente:npm pkg set type=moduleInstallare la libreria client OpenAI per JavaScript con:
npm install openaiPer l'autenticazione senza chiave consigliata con Microsoft Entra ID, installare il
@azure/identitypacchetto con:npm install @azure/identity
Recuperare le informazioni sulle risorse
È necessario recuperare le informazioni seguenti per autenticare l'applicazione con la risorsa OpenAI di Azure:
| Nome variabile | Valore |
|---|---|
AZURE_OPENAI_ENDPOINT |
Questo valore è disponibile nella sezione Chiavi ed endpoint quando si esamina la risorsa dal portale di Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Questo valore corrisponderà al nome personalizzato scelto per la distribuzione quando è stato distribuito un modello. Questo valore è disponibile in Distribuzioni di modelli di gestione>risorse nella portale di Azure. |
OPENAI_API_VERSION |
Altre informazioni sulle versioni api. |
Altre informazioni sull'autenticazione senza chiave e sull'impostazione delle variabili di ambiente.
Attenzione
Per usare l'autenticazione senza chiave consigliata con l'SDK, assicurarsi che la AZURE_OPENAI_API_KEY variabile di ambiente non sia impostata.
Generare audio dall'input di testo
Creare il
to-audio.jsfile con il codice seguente:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Accedere ad Azure con il comando seguente:
az loginEseguire il file JavaScript.
node to-audio.js
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio dall'input di testo
Lo script genera un file audio denominato dog.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt: "È un recupero d'oro un buon cane di famiglia?"
Generare audio e testo dall'input audio
Creare il
from-audio.jsfile con il codice seguente:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Accedere ad Azure con il comando seguente:
az loginEseguire il file JavaScript.
node from-audio.js
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio e testo dall'input audio
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Genera anche un file audio denominato analysis.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt.
Generare audio e usare completamenti chat a più turni
Creare il
multi-turn.jsfile con il codice seguente:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Accedere ad Azure con il comando seguente:
az loginEseguire il file JavaScript.
node multi-turn.js
Attendere qualche istante per ottenere la risposta.
Output per i completamenti della chat a più turni
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Quindi, rende un completamento della chat a più turni per riepilogare brevemente l'input audio parlato.
Codice sorgente della libreria | Pacchetto | Esempi
I gpt-4o-audio-preview modelli e gpt-4o-mini-audio-preview introducono la modalità audio nell'API esistente /chat/completions . Il modello audio espande il potenziale per le applicazioni di intelligenza artificiale nelle interazioni di testo e in base alla voce e all'analisi audio. Le modalità supportate in gpt-4o-audio-preview e gpt-4o-mini-audio-preview i modelli includono: testo, audio e testo + audio.
Ecco una tabella delle modalità supportate con casi d'uso di esempio:
| Input modalità | Output modalità | Esempio di caso d'uso |
|---|---|---|
| Testo | Testo e audio | Sintesi vocale, generazione di audiobook |
| Audio | Testo e audio | Trascrizione audio, generazione di audiobook |
| Audio | Testo | Trascrizione audio |
| Testo e audio | Testo e audio | Generazione di audiobook |
| Testo e audio | Testo | Trascrizione audio |
Usando le funzionalità di generazione audio, è possibile ottenere applicazioni di intelligenza artificiale più dinamiche e interattive. I modelli che supportano input audio e output consentono di generare risposte audio vocali alle richieste e usare input audio per richiedere il modello.
Modelli supportati
Attualmente solo gpt-4o-audio-preview e gpt-4o-mini-audio-preview versione: 2024-12-17 supporta la generazione di audio.
Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
Attualmente sono supportate le voci seguenti per l'audio: Lega, Echo e Shimmer.
La dimensione massima del file audio è di 20 MB.
Nota
L'API Realtime usa lo stesso modello audio GPT-4o sottostante dell'API di completamento, ma è ottimizzato per interazioni audio in tempo reale a bassa latenza.
Supporto dell'API
Il supporto per i completamenti audio è stato aggiunto per la prima volta nella versione 2025-01-01-previewdell'API .
Usare questa guida per iniziare a generare audio con Azure OpenAI SDK per Python.
Prerequisiti
- Una sottoscrizione di Azure. Crearne una gratuitamente.
- Python 3.8 o versioni successive. È consigliabile usare Python 3.10 o versione successiva; è comunque necessario avere almeno Python 3.8. Se non è installata una versione appropriata di Python, seguire le istruzioni riportate in Esercitazione di Vs Code Python, che descrive il modo più semplice per installare Python nel sistema operativo.
- Una risorsa OpenAI di Azure creata in una delle aree supportate. Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
- È quindi necessario distribuire un
gpt-4o-mini-audio-previewmodello con la risorsa OpenAI di Azure. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
Prerequisiti di Microsoft Entra ID
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, è necessario:
- Installare l'interfaccia della riga di comando di Azure usata per l'autenticazione senza chiave con Microsoft Entra ID.
- Assegnare il ruolo
Cognitive Services Userall'account utente. È possibile assegnare ruoli nella portale di Azure in Controllo di accesso (IAM)>Aggiungere un'assegnazione di ruolo.
Impostazione
Creare una nuova cartella
audio-completions-quickstartper contenere l'applicazione e aprire Visual Studio Code in tale cartella con il comando seguente:mkdir audio-completions-quickstart && code audio-completions-quickstartCreare un ambiente virtuale. Se Python 3.10 o versione successiva è già installato, è possibile creare un ambiente virtuale usando i comandi seguenti:
L'attivazione dell'ambiente Python implica che quando si esegue
pythonopipdalla riga di comando, si usa l'interprete Python contenuto nella cartella.venvdell'applicazione. Per uscire dall'ambiente virtuale Python è possibile usare il comandodeactivate. Potrà poi essere riattivato successivamente, quando necessario.Suggerimento
È consigliabile creare e attivare un nuovo ambiente Python da usare per installare i pacchetti necessari per questa esercitazione. Non installare pacchetti nell'installazione globale di Python. È consigliabile usare sempre un ambiente virtuale o conda durante l'installazione di pacchetti Python. In caso contrario, è possibile interrompere l'installazione globale di Python.
Installare la libreria client OpenAI per Python con:
pip install openaiPer l'autenticazione senza chiave consigliata con Microsoft Entra ID, installare il
azure-identitypacchetto con:pip install azure-identity
Recuperare le informazioni sulle risorse
È necessario recuperare le informazioni seguenti per autenticare l'applicazione con la risorsa OpenAI di Azure:
| Nome variabile | Valore |
|---|---|
AZURE_OPENAI_ENDPOINT |
Questo valore è disponibile nella sezione Chiavi ed endpoint quando si esamina la risorsa dal portale di Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Questo valore corrisponderà al nome personalizzato scelto per la distribuzione quando è stato distribuito un modello. Questo valore è disponibile in Distribuzioni di modelli di gestione>risorse nella portale di Azure. |
OPENAI_API_VERSION |
Altre informazioni sulle versioni api. |
Altre informazioni sull'autenticazione senza chiave e sull'impostazione delle variabili di ambiente.
Generare audio dall'input di testo
Creare il
to-audio.pyfile con il codice seguente:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Eseguire il file Python.
python to-audio.py
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio dall'input di testo
Lo script genera un file audio denominato dog.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt: "È un recupero d'oro un buon cane di famiglia?"
Generare audio e testo dall'input audio
Creare il
from-audio.pyfile con il codice seguente:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Eseguire il file Python.
python from-audio.py
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio e testo dall'input audio
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Genera anche un file audio denominato analysis.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt.
Generare audio e usare completamenti chat a più turni
Creare il
multi-turn.pyfile con il codice seguente:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Eseguire il file Python.
python multi-turn.py
Attendere qualche istante per ottenere la risposta.
Output per i completamenti della chat a più turni
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Quindi, rende un completamento della chat a più turni per riepilogare brevemente l'input audio parlato.
I gpt-4o-audio-preview modelli e gpt-4o-mini-audio-preview introducono la modalità audio nell'API esistente /chat/completions . Il modello audio espande il potenziale per le applicazioni di intelligenza artificiale nelle interazioni di testo e in base alla voce e all'analisi audio. Le modalità supportate in gpt-4o-audio-preview e gpt-4o-mini-audio-preview i modelli includono: testo, audio e testo + audio.
Ecco una tabella delle modalità supportate con casi d'uso di esempio:
| Input modalità | Output modalità | Esempio di caso d'uso |
|---|---|---|
| Testo | Testo e audio | Sintesi vocale, generazione di audiobook |
| Audio | Testo e audio | Trascrizione audio, generazione di audiobook |
| Audio | Testo | Trascrizione audio |
| Testo e audio | Testo e audio | Generazione di audiobook |
| Testo e audio | Testo | Trascrizione audio |
Usando le funzionalità di generazione audio, è possibile ottenere applicazioni di intelligenza artificiale più dinamiche e interattive. I modelli che supportano input audio e output consentono di generare risposte audio vocali alle richieste e usare input audio per richiedere il modello.
Modelli supportati
Attualmente solo gpt-4o-audio-preview e gpt-4o-mini-audio-preview versione: 2024-12-17 supporta la generazione di audio.
Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
Attualmente sono supportate le voci seguenti per l'audio: Lega, Echo e Shimmer.
La dimensione massima del file audio è di 20 MB.
Nota
L'API Realtime usa lo stesso modello audio GPT-4o sottostante dell'API di completamento, ma è ottimizzato per interazioni audio in tempo reale a bassa latenza.
Supporto dell'API
Il supporto per i completamenti audio è stato aggiunto per la prima volta nella versione 2025-01-01-previewdell'API .
Prerequisiti
- Una sottoscrizione di Azure. Crearne una gratuitamente.
- Python 3.8 o versioni successive. È consigliabile usare Python 3.10 o versione successiva; è comunque necessario avere almeno Python 3.8. Se non è installata una versione appropriata di Python, seguire le istruzioni riportate in Esercitazione di Vs Code Python, che descrive il modo più semplice per installare Python nel sistema operativo.
- Una risorsa OpenAI di Azure creata in una delle aree supportate. Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
- È quindi necessario distribuire un
gpt-4o-mini-audio-previewmodello con la risorsa OpenAI di Azure. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
Prerequisiti di Microsoft Entra ID
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, è necessario:
- Installare l'interfaccia della riga di comando di Azure usata per l'autenticazione senza chiave con Microsoft Entra ID.
- Assegnare il ruolo
Cognitive Services Userall'account utente. È possibile assegnare ruoli nella portale di Azure in Controllo di accesso (IAM)>Aggiungere un'assegnazione di ruolo.
Impostazione
Creare una nuova cartella
audio-completions-quickstartper contenere l'applicazione e aprire Visual Studio Code in tale cartella con il comando seguente:mkdir audio-completions-quickstart && code audio-completions-quickstartCreare un ambiente virtuale. Se Python 3.10 o versione successiva è già installato, è possibile creare un ambiente virtuale usando i comandi seguenti:
L'attivazione dell'ambiente Python implica che quando si esegue
pythonopipdalla riga di comando, si usa l'interprete Python contenuto nella cartella.venvdell'applicazione. Per uscire dall'ambiente virtuale Python è possibile usare il comandodeactivate. Potrà poi essere riattivato successivamente, quando necessario.Suggerimento
È consigliabile creare e attivare un nuovo ambiente Python da usare per installare i pacchetti necessari per questa esercitazione. Non installare pacchetti nell'installazione globale di Python. È consigliabile usare sempre un ambiente virtuale o conda durante l'installazione di pacchetti Python. In caso contrario, è possibile interrompere l'installazione globale di Python.
Installare la libreria client OpenAI per Python con:
pip install openaiPer l'autenticazione senza chiave consigliata con Microsoft Entra ID, installare il
azure-identitypacchetto con:pip install azure-identity
Recuperare le informazioni sulle risorse
È necessario recuperare le informazioni seguenti per autenticare l'applicazione con la risorsa OpenAI di Azure:
| Nome variabile | Valore |
|---|---|
AZURE_OPENAI_ENDPOINT |
Questo valore è disponibile nella sezione Chiavi ed endpoint quando si esamina la risorsa dal portale di Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Questo valore corrisponderà al nome personalizzato scelto per la distribuzione quando è stato distribuito un modello. Questo valore è disponibile in Distribuzioni di modelli di gestione>risorse nella portale di Azure. |
OPENAI_API_VERSION |
Altre informazioni sulle versioni api. |
Altre informazioni sull'autenticazione senza chiave e sull'impostazione delle variabili di ambiente.
Generare audio dall'input di testo
Creare il
to-audio.pyfile con il codice seguente:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Eseguire il file Python.
python to-audio.py
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio dall'input di testo
Lo script genera un file audio denominato dog.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt: "È un recupero d'oro un buon cane di famiglia?"
Generare audio e testo dall'input audio
Creare il
from-audio.pyfile con il codice seguente:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Eseguire il file Python.
python from-audio.py
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio e testo dall'input audio
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Genera anche un file audio denominato analysis.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt.
Generare audio e usare completamenti chat a più turni
Creare il
multi-turn.pyfile con il codice seguente:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-mini-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Eseguire il file Python.
python multi-turn.py
Attendere qualche istante per ottenere la risposta.
Output per i completamenti della chat a più turni
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Quindi, rende un completamento della chat a più turni per riepilogare brevemente l'input audio parlato.
Documentazione di riferimento | Codice sorgente della libreria | Pacchetto (npm) | Esempi
I gpt-4o-audio-preview modelli e gpt-4o-mini-audio-preview introducono la modalità audio nell'API esistente /chat/completions . Il modello audio espande il potenziale per le applicazioni di intelligenza artificiale nelle interazioni di testo e in base alla voce e all'analisi audio. Le modalità supportate in gpt-4o-audio-preview e gpt-4o-mini-audio-preview i modelli includono: testo, audio e testo + audio.
Ecco una tabella delle modalità supportate con casi d'uso di esempio:
| Input modalità | Output modalità | Esempio di caso d'uso |
|---|---|---|
| Testo | Testo e audio | Sintesi vocale, generazione di audiobook |
| Audio | Testo e audio | Trascrizione audio, generazione di audiobook |
| Audio | Testo | Trascrizione audio |
| Testo e audio | Testo e audio | Generazione di audiobook |
| Testo e audio | Testo | Trascrizione audio |
Usando le funzionalità di generazione audio, è possibile ottenere applicazioni di intelligenza artificiale più dinamiche e interattive. I modelli che supportano input audio e output consentono di generare risposte audio vocali alle richieste e usare input audio per richiedere il modello.
Modelli supportati
Attualmente solo gpt-4o-audio-preview e gpt-4o-mini-audio-preview versione: 2024-12-17 supporta la generazione di audio.
Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
Attualmente sono supportate le voci seguenti per l'audio: Lega, Echo e Shimmer.
La dimensione massima del file audio è di 20 MB.
Nota
L'API Realtime usa lo stesso modello audio GPT-4o sottostante dell'API di completamento, ma è ottimizzato per interazioni audio in tempo reale a bassa latenza.
Supporto dell'API
Il supporto per i completamenti audio è stato aggiunto per la prima volta nella versione 2025-01-01-previewdell'API .
Prerequisiti
- Una sottoscrizione di Azure: creare un account gratuitamente
- Node.js supporto LTS o ESM.
- TypeScript installato a livello globale.
- Una risorsa OpenAI di Azure creata in una delle aree supportate. Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
- È quindi necessario distribuire un
gpt-4o-mini-audio-previewmodello con la risorsa OpenAI di Azure. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
Prerequisiti di Microsoft Entra ID
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, è necessario:
- Installare l'interfaccia della riga di comando di Azure usata per l'autenticazione senza chiave con Microsoft Entra ID.
- Assegnare il ruolo
Cognitive Services Userall'account utente. È possibile assegnare ruoli nella portale di Azure in Controllo di accesso (IAM)>Aggiungere un'assegnazione di ruolo.
Impostazione
Creare una nuova cartella
audio-completions-quickstartper contenere l'applicazione e aprire Visual Studio Code in tale cartella con il comando seguente:mkdir audio-completions-quickstart && code audio-completions-quickstartpackage.jsonCreare con il comando seguente:npm init -yAggiornare in
package.jsonECMAScript con il comando seguente:npm pkg set type=moduleInstallare la libreria client OpenAI per JavaScript con:
npm install openaiPer l'autenticazione senza chiave consigliata con Microsoft Entra ID, installare il
@azure/identitypacchetto con:npm install @azure/identity
Recuperare le informazioni sulle risorse
È necessario recuperare le informazioni seguenti per autenticare l'applicazione con la risorsa OpenAI di Azure:
| Nome variabile | Valore |
|---|---|
AZURE_OPENAI_ENDPOINT |
Questo valore è disponibile nella sezione Chiavi ed endpoint quando si esamina la risorsa dal portale di Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Questo valore corrisponderà al nome personalizzato scelto per la distribuzione quando è stato distribuito un modello. Questo valore è disponibile in Distribuzioni di modelli di gestione>risorse nella portale di Azure. |
OPENAI_API_VERSION |
Altre informazioni sulle versioni api. |
Altre informazioni sull'autenticazione senza chiave e sull'impostazione delle variabili di ambiente.
Attenzione
Per usare l'autenticazione senza chiave consigliata con l'SDK, assicurarsi che la AZURE_OPENAI_API_KEY variabile di ambiente non sia impostata.
Generare audio dall'input di testo
Creare il
to-audio.tsfile con il codice seguente:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Creare il file per eseguire la
tsconfig.jsontranspile del codice TypeScript e copiare il codice seguente per ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile da TypeScript a JavaScript.
tscAccedere ad Azure con il comando seguente:
az loginEseguire il codice con il comando seguente:
node to-audio.js
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio dall'input di testo
Lo script genera un file audio denominato dog.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt: "È un recupero d'oro un buon cane di famiglia?"
Generare audio e testo dall'input audio
Creare il
from-audio.tsfile con il codice seguente:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Creare il file per eseguire la
tsconfig.jsontranspile del codice TypeScript e copiare il codice seguente per ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile da TypeScript a JavaScript.
tscAccedere ad Azure con il comando seguente:
az loginEseguire il codice con il comando seguente:
node from-audio.js
Attendere qualche istante per ottenere la risposta.
Output per la generazione di audio e testo dall'input audio
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Genera anche un file audio denominato analysis.wav nella stessa directory dello script. Il file audio contiene la risposta pronunciata al prompt.
Generare audio e usare completamenti chat a più turni
Creare il
multi-turn.tsfile con il codice seguente:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Creare il file per eseguire la
tsconfig.jsontranspile del codice TypeScript e copiare il codice seguente per ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile da TypeScript a JavaScript.
tscAccedere ad Azure con il comando seguente:
az loginEseguire il codice con il comando seguente:
node multi-turn.js
Attendere qualche istante per ottenere la risposta.
Output per i completamenti della chat a più turni
Lo script genera una trascrizione del riepilogo dell'input audio parlato. Quindi, rende un completamento della chat a più turni per riepilogare brevemente l'input audio parlato.
Pulire le risorse
Se si vuole ripulire e rimuovere una risorsa OpenAI di Azure, è possibile eliminare la risorsa. Prima di eliminare la risorsa, è necessario eliminare i modelli distribuiti.
Contenuto correlato
- Altre informazioni sui tipi di distribuzione OpenAI di Azure.
- Altre informazioni sulle quote e i limiti di Azure OpenAI.