Modello di lettura di Informazioni sui documenti
Questo contenuto si applica a:![]() v4.0 (GA) | Versioni precedenti:
v4.0 (GA) | Versioni precedenti: ![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA)![]()
Nota
Per estrarre testo da immagini esterne come etichette, segnali stradali e poster, usare la funzionalità Di analisi delle immagini di Intelligenza artificiale di Azure v4.0 ottimizzata per immagini generali (non documento) con un'API sincrona ottimizzata per le prestazioni. Questa funzionalità semplifica l'incorporamento di OCR in scenari di esperienza utente in tempo reale.
Il modello Lettura OCR di Informazioni sui documenti v3.0 viene eseguito con una risoluzione superiore rispetto alla lettura di Visione di Azure AI ed estrae testo stampato e scritto a mano da documenti PDF e immagini digitalizzate. Include anche il supporto per l'estrazione di testo da documenti Microsoft Word, Excel, PowerPoint e HTML. Rileva paragrafi, righe di testo, parole, posizioni e lingue. Il modello Lettura è il motore OCR sottostante per altri modelli predefiniti di Informazioni sui documenti, come Layout, Documento generale, Fattura, Ricevuta, Documento di identità, Scheda assicurazione sanitaria, W2 oltre ai modelli personalizzati.
Che cos'è il riconoscimento ottico dei caratteri?
Il riconoscimento ottico dei caratteri (OCR) per i documenti è ottimizzato per documenti di grandi dimensioni in più formati di file e lingue globali. Include funzioni come la scansione a risoluzione più elevata delle immagini dei documenti per una migliore gestione dei testi più piccoli e densi, il rilevamento dei paragrafi e la gestione dei moduli compilabili. Le funzionalità OCR includono anche scenari avanzati come caselle a carattere singolo ed estrazione accurata dei campi chiave comunemente presenti in fatture, ricevute e altri scenari predefiniti.
Opzioni di sviluppo (v4)
Document Intelligence v4.0: 2024-11-30 (GA) supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello Lettura OCR | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Requisiti di input (v4)
Formati di file supportati:
| Modello | Immagine: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lettura | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Documento generale | ✔ | ✔ | |
| Predefinito | ✔ | ✔ | |
| Estrazione personalizzata | ✔ | ✔ | |
| Classificazione personalizzata | ✔ | ✔ | ✔ |
Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
Introduzione al modello di lettura (v4)
Provare a estrarre testo da moduli e documenti usando Document Intelligence Studio. Sono necessarie le risorse seguenti:
Una sottoscrizione di Azure: è possibile crearne una gratuitamente.
Istanza di Informazioni sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.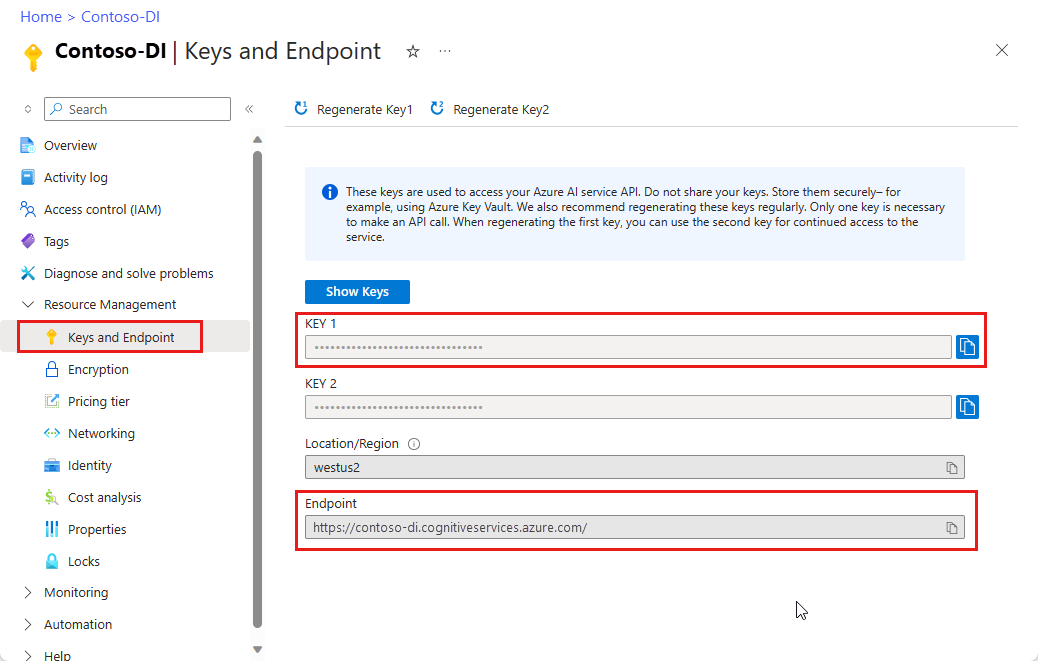
Nota
Attualmente, Document Intelligence Studio non supporta i formati di file Microsoft Word, Excel, PowerPoint e HTML.
Documento di esempio elaborato con Document Intelligence Studio
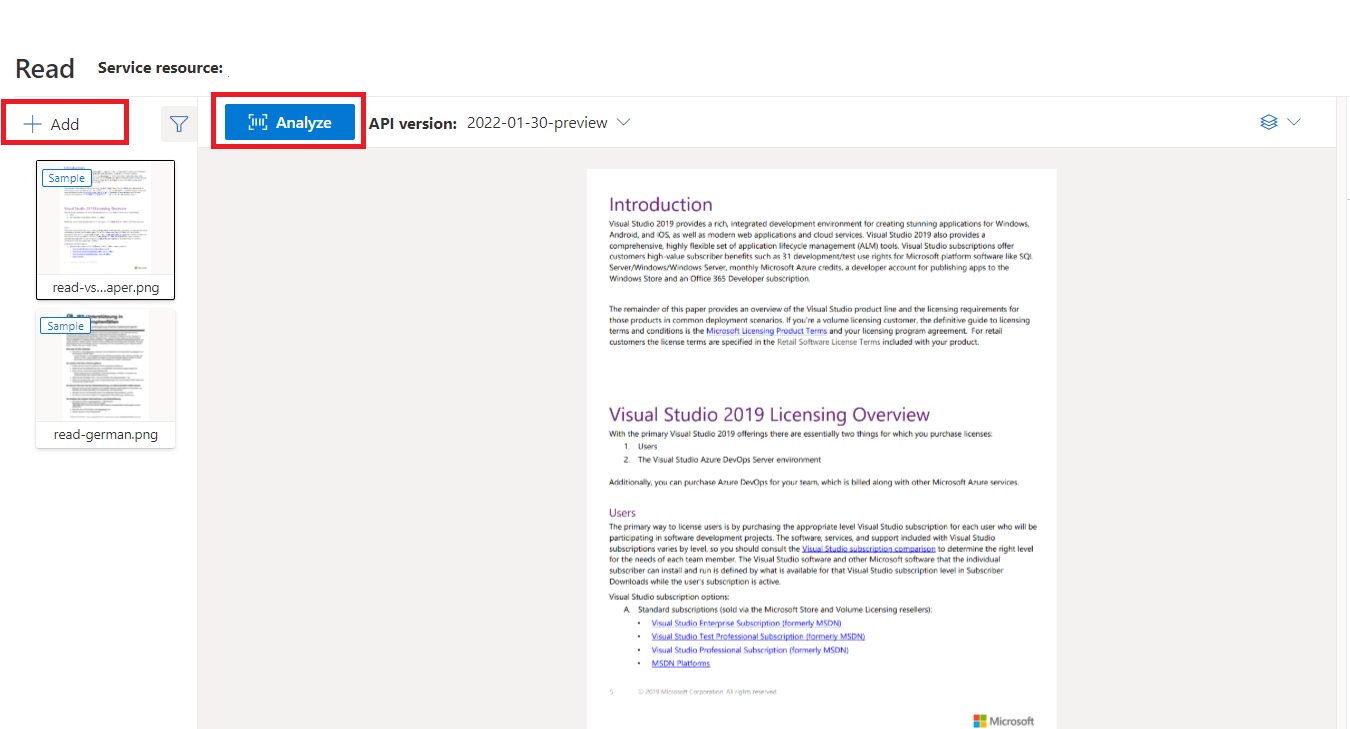
Nella home page di Document Intelligence Studio selezionare Lettura.
È possibile analizzare il documento di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare Analizza opzioni:

Lingue e impostazioni locali supportate (v4)
Vedere la pagina Lingue supportate - modelli di analisi dei documenti per un elenco completo delle lingue supportate.
Estrazione dei dati (v4)
Nota
Microsoft Word e il file HTML sono supportati nella versione 4.0. Le funzionalità seguenti non sono attualmente supportate:
- Nessun angolo, larghezza/altezza e unità restituiti con ogni oggetto pagina.
- Nessun poligono di delimitazione o area di delimitazione per ogni oggetto rilevato.
- Nessun intervallo di pagine (
pages) come parametro restituito. - Nessun oggetto
lines.
Pdf ricercabili
La funzionalità PDF ricercabile consente di convertire un PDF analogico, ad esempio file PDF a immagini digitalizzate, in un PDF con testo incorporato. Il testo incorporato consente la ricerca di testo avanzato all'interno del contenuto estratto del PDF sovrapponendo le entità di testo rilevate sopra i file di immagine.
Importante
- Attualmente, solo il modello
prebuilt-readOCR di lettura supporta la funzionalità PDF ricercabile. Quando si usa questa funzionalità, specificare comemodelIdprebuilt-read. Altri tipi di modello restituiscono un errore per questa versione di anteprima. - Il PDF ricercabile è incluso nel
2024-11-30modello gaprebuilt-readsenza costi aggiuntivi per la generazione di un output PDF ricercabile.
Usare pdf ricercabili
Per usare il PDF ricercabile, effettuare una richiesta POST usando l'operazione Analyze e specificare il formato di output come pdf:
POST {endpoint}/documentintelligence/documentModels/prebuilt-read:analyze?_overload=analyzeDocument&api-version=2024-11-30&output=pdf
{...}
202
Eseguire il polling per il completamento dell'operazione di Analyze. Una volta completata l'operazione, eseguire una richiesta GET per recuperare il formato PDF dei risultati dell'operazione Analyze.
Al termine, il PDF può essere recuperato e scaricato come application/pdf. Questa operazione consente il download diretto della forma di testo incorporata del PDF anziché del codice JSON con codifica Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET {endpoint}/documentintelligence/documentModels/prebuilt-read/analyzeResults/{resultId}/pdf?api-version=2024-11-30
URI Parameters
Name In Required Type Description
endpoint path True
string
uri
The Document Intelligence service endpoint.
modelId path True
string
Unique document model name.
Regex pattern: ^[a-zA-Z0-9][a-zA-Z0-9._~-]{1,63}$
resultId path True
string
uuid
Analyze operation result ID.
api-version query True
string
The API version to use for this operation.
Responses
Name Type Description
200 OK
file
The request has succeeded.
Media Types: "application/pdf", "application/json"
Other Status Codes
DocumentIntelligenceErrorResponse
An unexpected error response.
Media Types: "application/pdf", "application/json"
Security
Ocp-Apim-Subscription-Key
Type: apiKey
In: header
OAuth2Auth
Type: oauth2
Flow: accessCode
Authorization URL: https://login.microsoftonline.com/common/oauth2/authorize
Token URL: https://login.microsoftonline.com/common/oauth2/token
Scopes
Name Description
https://cognitiveservices.azure.com/.default
Examples
Get Analyze Document Result PDF
Sample request
HTTP
HTTP
Copy
GET https://myendpoint.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-invoice/analyzeResults/3b31320d-8bab-4f88-b19c-2322a7f11034/pdf?api-version=2024-11-30
Sample response
Status code:
200
JSON
Copy
"{pdfBinary}"
Definitions
Name Description
DocumentIntelligenceError
The error object.
DocumentIntelligenceErrorResponse
Error response object.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
DocumentIntelligenceError
The error object.
Name Type Description
code
string
One of a server-defined set of error codes.
details
DocumentIntelligenceError[]
An array of details about specific errors that led to this reported error.
innererror
DocumentIntelligenceInnerError
An object containing more specific information than the current object about the error.
message
string
A human-readable representation of the error.
target
string
The target of the error.
DocumentIntelligenceErrorResponse
Error response object.
Name Type Description
error
DocumentIntelligenceError
Error info.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
Name Type Description
code
string
One of a server-defined set of error codes.
innererror
DocumentIntelligenceInnerError
Inner error.
message
string
A human-readable representation of the error.
In this article
URI Parameters
Responses
Security
Examples
200 OK
Content-Type: application/pdf
Parametro Pages
La raccolta di pagine è un elenco di pagine all'interno del documento. Ogni pagina viene rappresentata in sequenza all'interno del documento e include l'angolo di orientamento che indica se la pagina viene ruotata e la larghezza e l'altezza (dimensioni in pixel). Le unità di pagina nell'output del modello vengono calcolate come illustrato:
| Formato file | Unità di pagina calcolata | Pagine totali |
|---|---|---|
| Immagini (JPEG/JPG, PNG, BMP, HEIF) | Ogni immagine = 1 unità di pagina | Totale immagini |
| Ogni pagina nel PDF = 1 unità di pagina | Totale pagine nel PDF | |
| TIFF | Ogni immagine nel file TIFF = 1 unità di pagina | Totale immagini nel TIFF |
| Word (DOCX) | Fino a 3.000 caratteri = 1 unità di pagina, immagini incorporate o collegate non supportate | Totale pagine fino a 3.000 caratteri ciascuna |
| Excel (XLSX) | Ogni foglio di lavoro = 1 unità di pagina, immagini incorporate o collegate non supportate | Totale fogli di lavoro |
| PowerPoint (PPTX) | Ogni diapositiva = 1 unità di pagina, immagini incorporate o collegate non supportate | Diapositive totali |
| HTML | Fino a 3.000 caratteri = 1 unità di pagina, immagini incorporate o collegate non supportate | Totale pagine fino a 3.000 caratteri ciascuna |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Usare le pagine per l'estrazione di testo
Per i documenti PDF a più pagine di grandi dimensioni, usare il parametro di query pages per indicare numeri di pagina o intervalli di pagine specifici per l'estrazione di testo.
Estrazione di paragrafi
Il modello Lettura OCR in Informazioni sui documenti estrae tutti i blocchi di testo identificati nella raccolta paragraphs come oggetto di primo livello in analyzeResults. Ogni voce di questa raccolta rappresenta un blocco di testo e include il testo estratto come contente le coordinate del polygon delimitatore. Le informazioni span puntano al frammento di testo all'interno della proprietà di primo livello content che contiene il testo completo del documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Estrazione di testo, righe e parole
Il modello Lettura OCR estrae il testo in stile stampato e scritto a mano come lines e words. Il modello restituisce le coordinate del polygon delimitatore e confidence per le parole estratte. La raccolta styles include qualsiasi stile scritto a mano per le righe, se rilevato insieme agli intervalli che puntano al testo associato. Questa funzionalità si applica alle lingue scritte a mano supportate.
Per Microsoft Word, Excel, PowerPoint e HTML, Document Intelligence Read model v3.1 e versioni successive estrae tutto il testo incorporato così come è. I testi vengono estratti come parole e paragrafi. Le immagini incorporate non sono supportate.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Estrazione dello stile scritto a mano
La risposta include la classificazione di ogni riga di testo come stile di scrittura manuale o no, insieme a un punteggio di attendibilità. Per ulteriori informazioni, vedere Supporto per le lingue scritte a mano. L'esempio seguente mostra un frammento JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Se è stata abilitata la funzionalità di componente aggiuntivo tipo di carattere/stile, si ottiene anche il risultato del tipo di carattere/stile come parte dell'oggetto styles.
Passaggi successivi v4.0
Completare un argomento di avvio rapido di Informazioni sui documenti:
Esplorare l'API REST:
Trovare altri esempi in GitHub:
Nota
Per estrarre testo da immagini esterne come etichette, segnali stradali e poster, usare la funzionalità Di analisi delle immagini di Intelligenza artificiale di Azure v4.0 ottimizzata per immagini generali (non documento) con un'API sincrona ottimizzata per le prestazioni. Questa funzionalità semplifica l'incorporamento di OCR in scenari di esperienza utente in tempo reale.
Il modello Lettura OCR di Informazioni sui documenti v3.0 viene eseguito con una risoluzione superiore rispetto alla lettura di Visione di Azure AI ed estrae testo stampato e scritto a mano da documenti PDF e immagini digitalizzate. Include anche il supporto per l'estrazione di testo da documenti Microsoft Word, Excel, PowerPoint e HTML. Rileva paragrafi, righe di testo, parole, posizioni e lingue. Il modello Lettura è il motore OCR sottostante per altri modelli predefiniti di Informazioni sui documenti, come Layout, Documento generale, Fattura, Ricevuta, Documento di identità, Scheda assicurazione sanitaria, W2 oltre ai modelli personalizzati.
Che cos'è l'OCR per i documenti?
Il riconoscimento ottico dei caratteri (OCR) per i documenti è ottimizzato per documenti di grandi dimensioni in più formati di file e lingue globali. Include funzioni come la scansione a risoluzione più elevata delle immagini dei documenti per una migliore gestione dei testi più piccoli e densi, il rilevamento dei paragrafi e la gestione dei moduli compilabili. Le funzionalità OCR includono anche scenari avanzati come caselle a carattere singolo ed estrazione accurata dei campi chiave comunemente presenti in fatture, ricevute e altri scenari predefiniti.
Opzioni di sviluppo
Informazioni sui documenti v3. 1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello Lettura OCR | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Informazioni sui documenti v3.0 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello Lettura OCR | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Requisiti di input
Formati di file supportati:
| Modello | Immagine: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lettura | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Documento generale | ✔ | ✔ | |
| Predefinito | ✔ | ✔ | |
| Estrazione personalizzata | ✔ | ✔ | |
| Classificazione personalizzata | ✔ | ✔ | ✔ |
Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
Introduzione al modello di lettura
Provare a estrarre testo da moduli e documenti usando Document Intelligence Studio. Sono necessarie le risorse seguenti:
Una sottoscrizione di Azure: è possibile crearne una gratuitamente.
Istanza di Informazioni sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.
Nota
Attualmente, Document Intelligence Studio non supporta i formati di file Microsoft Word, Excel, PowerPoint e HTML.
Documento di esempio elaborato con Document Intelligence Studio
Nella home page di Document Intelligence Studio selezionare Lettura.
È possibile analizzare il documento di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare Analizza opzioni:
Lingue e impostazioni locali supportate
Vedere la pagina Lingue supportate - modelli di analisi dei documenti per un elenco completo delle lingue supportate.
Estrazione dei dati
Nota
Microsoft Word e il file HTML sono supportati nella versione 4.0. Le funzionalità seguenti non sono attualmente supportate:
- Nessun angolo, larghezza/altezza e unità restituiti con ogni oggetto pagina.
- Nessun poligono di delimitazione o area di delimitazione per ogni oggetto rilevato.
- Nessun intervallo di pagine (
pages) come parametro restituito. - Nessun oggetto
lines.
PDF ricercabile
La funzionalità PDF ricercabile consente di convertire un PDF analogico, ad esempio file PDF a immagini digitalizzate, in un PDF con testo incorporato. Il testo incorporato consente la ricerca di testo avanzato all'interno del contenuto estratto del PDF sovrapponendo le entità di testo rilevate sopra i file di immagine.
Importante
- Attualmente, solo il modello
prebuilt-readOCR di lettura supporta la funzionalità PDF ricercabile. Quando si usa questa funzionalità, specificare comemodelIdprebuilt-read. Altri tipi di modello restituiscono un errore. - Il PDF ricercabile è incluso nel
2024-11-30prebuilt-readmodello senza costi aggiuntivi per la generazione di un output PDF ricercabile.- Il PDF ricercabile supporta attualmente solo i file PDF come input.
Usare un PDF ricercabile
Per usare il PDF ricercabile, effettuare una richiesta POST usando l'operazione Analyze e specificare il formato di output come pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Eseguire il polling per il completamento dell'operazione di Analyze. Una volta completata l'operazione, eseguire una richiesta GET per recuperare il formato PDF dei risultati dell'operazione Analyze.
Al termine, il PDF può essere recuperato e scaricato come application/pdf. Questa operazione consente il download diretto della forma di testo incorporata del PDF anziché del codice JSON con codifica Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Pagine
La raccolta di pagine è un elenco di pagine all'interno del documento. Ogni pagina viene rappresentata in sequenza all'interno del documento e include l'angolo di orientamento che indica se la pagina viene ruotata e la larghezza e l'altezza (dimensioni in pixel). Le unità di pagina nell'output del modello vengono calcolate come illustrato:
| Formato file | Unità di pagina calcolata | Pagine totali |
|---|---|---|
| Immagini (JPEG/JPG, PNG, BMP, HEIF) | Ogni immagine = 1 unità di pagina | Totale immagini |
| Ogni pagina nel PDF = 1 unità di pagina | Totale pagine nel PDF | |
| TIFF | Ogni immagine nel file TIFF = 1 unità di pagina | Totale immagini nel TIFF |
| Word (DOCX) | Fino a 3.000 caratteri = 1 unità di pagina, immagini incorporate o collegate non supportate | Totale pagine fino a 3.000 caratteri ciascuna |
| Excel (XLSX) | Ogni foglio di lavoro = 1 unità di pagina, immagini incorporate o collegate non supportate | Totale fogli di lavoro |
| PowerPoint (PPTX) | Ogni diapositiva = 1 unità di pagina, immagini incorporate o collegate non supportate | Diapositive totali |
| HTML | Fino a 3.000 caratteri = 1 unità di pagina, immagini incorporate o collegate non supportate | Totale pagine fino a 3.000 caratteri ciascuna |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Selezionare le pagine per l'estrazione di testo
Per i documenti PDF a più pagine di grandi dimensioni, usare il parametro di query pages per indicare numeri di pagina o intervalli di pagine specifici per l'estrazione di testo.
Paragrafi
Il modello Lettura OCR in Informazioni sui documenti estrae tutti i blocchi di testo identificati nella raccolta paragraphs come oggetto di primo livello in analyzeResults. Ogni voce di questa raccolta rappresenta un blocco di testo e include il testo estratto come contente le coordinate del polygon delimitatore. Le informazioni span puntano al frammento di testo all'interno della proprietà di primo livello content che contiene il testo completo del documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Testo, righe e parole
Il modello Lettura OCR estrae il testo in stile stampato e scritto a mano come lines e words. Il modello restituisce le coordinate del polygon delimitatore e confidence per le parole estratte. La raccolta styles include qualsiasi stile scritto a mano per le righe, se rilevato insieme agli intervalli che puntano al testo associato. Questa funzionalità si applica alle lingue scritte a mano supportate.
Per Microsoft Word, Excel, PowerPoint e HTML, Document Intelligence Read model v3.1 e versioni successive estrae tutto il testo incorporato così come è. I testi vengono estratti come parole e paragrafi. Le immagini incorporate non sono supportate.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Stile scritto a mano per le righe di testo
La risposta include la classificazione di ogni riga di testo come stile di scrittura manuale o no, insieme a un punteggio di attendibilità. Per ulteriori informazioni, vedere Supporto per le lingue scritte a mano. L'esempio seguente mostra un frammento JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Se è stata abilitata la funzionalità di componente aggiuntivo tipo di carattere/stile, si ottiene anche il risultato del tipo di carattere/stile come parte dell'oggetto styles.
Passaggi successivi
Completare un argomento di avvio rapido di Informazioni sui documenti:
Esplorare l'API REST:
Trovare altri esempi in GitHub: