Risposta delle API di analisi di documenti
In questo articolo vengono illustrati i diversi oggetti restituiti come parte della risposta di AnalyzeDocument e come usare la risposta delle API di analisi di documenti nelle applicazioni.
Richiesta di analisi di documenti
Le API di Document Intelligence analizzano immagini, PDF e altri file di documenti per estrarre e rilevare vari elementi di contenuto, layout, stile e semantici. L'operazione Analyze è un'API asincrona. L'invio di un documento restituisce un'intestazione Operation-Location contenente l'URL di cui eseguire il polling per il completamento. Al termine di una richiesta di analisi, la risposta contiene gli elementi descritti nell'estrazione dei dati del modello.
Elementi della risposta
Gli elementi di contenuto sono gli elementi di testo di base estratti dal documento.
Gli elementi di layout raggruppano gli elementi di contenuto in unità strutturali.
Gli elementi di stile descrivono il tipo di carattere e la lingua degli elementi di contenuto.
Gli elementi semantici assegnano significato agli elementi di contenuto specificati.
Tutti gli elementi di contenuto vengono raggruppati in base alle pagine, specificate in base al numero di pagina (indice 1). Vengono anche ordinati in base all'ordine di lettura che dispone gli elementi semanticamente contigui, anche se superano i limiti di riga o colonna. Quando l'ordine di lettura tra paragrafi e altri elementi di layout è ambiguo, il servizio restituisce in genere il contenuto in ordine da sinistra a destra, dall'alto in basso.
Nota
Attualmente, Document Intelligence non supporta l'ordine di lettura tra i limiti di pagina. I segni di selezione non vengono posizionati all'interno delle parole circostanti.
La proprietà di contenuto di primo livello contiene una concatenazione di tutti gli elementi di contenuto nell'ordine di lettura. Tutti gli elementi specificano la posizione nell'ordine del lettore tramite intervalli all'interno di questa stringa di contenuto. Il contenuto di alcuni elementi non è sempre contiguo.
Risposta dell'analisi
La risposta Analyze per ogni API restituisce oggetti diversi. Le risposte delle API contengono elementi dei modelli di componenti, se applicabile.
| Contenuto della risposta | Descrizione | API |
|---|---|---|
| pages | Parole, righe e intervalli riconosciuti di ogni pagina del documento di input. | Modelli Lettura, Layout, Documento generale, predefiniti e personalizzati |
| paragraphs | Contenuto riconosciuto come paragrafi. | Modelli Lettura, Layout, Documento generale, predefiniti e personalizzati |
| styles | Proprietà degli elementi di testo identificate. | Modelli Lettura, Layout, Documento generale, predefiniti e personalizzati |
| languages | Lingua identificata associata a ogni intervallo di testo estratto | Lettura |
| tables | Contenuto tabulare identificato ed estratto dal documento. Le tabelle sono correlate alle tabelle identificate dal modello di layout già sottoposto a training. Il contenuto etichettato come tabelle viene estratto come campi strutturati nell'oggetto documents. | Modelli Lettura, Layout, Documento generale, Fattura e personalizzati |
| figure | Figure (grafici, immagini) identificate ed estratte dal documento, fornendo rappresentazioni visive che facilitano la comprensione di informazioni complesse. | Il modello Layout |
| sections | Struttura gerarchica dei documenti identificata ed estratta dal documento. Sezione o sottosezione con gli elementi corrispondenti (paragrafo, tabella, figura) collegati. | Il modello Layout |
| keyValuePairs | Coppie chiave-valore riconosciute da un modello già sottoposto a training. La chiave è un intervallo di testo del documento con il valore associato. | Modelli Documento generale e Fattura |
| documents | I campi riconosciuti vengono restituiti nel dizionario fields all'interno dell'elenco dei documenti |
Modelli predefiniti, modelli personalizzati. |
Per altre informazioni sugli oggetti restituiti da ogni API, vedere Estrazione dei dati del modello.
Proprietà dell'elemento
Intervalli
Gli intervalli specificano la posizione logica di ogni elemento nell'ordine di lettura complessivo, con ogni intervallo che specifica un offset di caratteri e una lunghezza nella proprietà della stringa di contenuto di primo livello. Per impostazione predefinita, gli offset e le lunghezze dei caratteri vengono restituiti in unità di caratteri percepiti dall'utente (noti anche come grapheme clusters o elementi di testo). Per supportare ambienti di sviluppo diversi che usano unità di caratteri diverse, l'utente può specificare anche il parametro di query stringIndexIndex per restituire offset e lunghezze di intervalli in punti di codice Unicode (Python 3) o anche unità di codice UTF16 (Java, JavaScript, .NET). Per altre informazioni, vedere supporto multilingue/emoji.
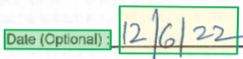
Area di delimitazione
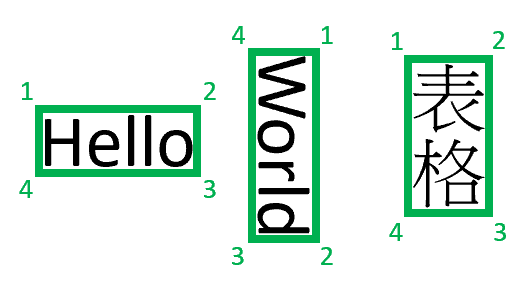
Le aree di delimitazione descrivono la posizione visiva di ogni elemento nel file. Quando gli elementi non sono visivamente contigui o attraversano pagine (tabelle), le posizioni della maggior parte degli elementi vengono descritte tramite una matrice di aree di delimitazione. Ogni area specifica il numero di pagina (indice 1) e il poligono delimitatore. Il poligono delimitatore viene descritto come una sequenza di punti, in senso orario da sinistra rispetto all'orientamento naturale dell'elemento. Per i quadrilateri, i punti del tracciato sono gli angoli in alto a sinistra, in alto a destra, in basso a destra e in basso a sinistra. Ogni punto rappresenta la relativa coordinata x, y nell'unità di pagina specificata dalla proprietà unit. In generale, l'unità di misura per le immagini è il pixel mentre per i PDF si usano i pollici.
Nota
Attualmente, Document Intelligence restituisce solo quadrilateri a 4 vertici come poligoni di delimitazione. Le versioni future possono restituire un numero diverso di punti per descrivere forme più complesse, ad esempio linee curve o immagini non rettangolari. Le aree di delimitazione vengono applicate solo ai file di cui è stato eseguito il rendering; se il file non viene sottoposto a rendering, le aree di delimitazione non vengono restituite. Il rendering dei file di formato docx/xlsx/pptx/html non viene attualmente eseguito.
Elementi di contenuto
Word
Una parola è un elemento di contenuto composto da una sequenza di caratteri. Con Document Intelligence, una parola viene definita come una sequenza di caratteri adiacenti, con le parole separate da spazi. Per le lingue che non usano separatori di spazio tra le parole, ogni carattere viene restituito come parola separata, anche se non rappresenta un'unità di parola semantica.

Opzioni di selezione
Un segno di selezione è un elemento di contenuto che rappresenta un glifo visivo che indica lo stato di una selezione. La casella di controllo è una forma comune di segni di selezione. Tuttavia, sono anche rappresentati tramite pulsanti di opzione o una cella delimitata in un modulo visivo. Lo stato di un segno di selezione può essere selezionato o deselezionato, con una rappresentazione visiva diversa per indicarlo.

Elementi di layout
A linee
Una riga è una sequenza ordinata di elementi di contenuto consecutivi separati da uno spazio visivo o di quelli immediatamente adiacenti per le lingue senza delimitatori di spazio tra le parole. Gli elementi di contenuto nello stesso piano orizzontale (riga) ma separati da più di un singolo spazio visivo vengono spesso divisi in più righe. Sebbene questa funzionalità a volte divida il contenuto semanticamente contiguo in righe separate, consente la rappresentazione del contenuto testuale diviso in più colonne o celle. Le righe nella scrittura verticale vengono rilevate nella direzione verticale.

Paragrafo
Un paragrafo è una sequenza ordinata di righe che formano un'unità logica. In genere, le righe condividono un allineamento e una spaziatura comuni. I paragrafi vengono spesso delimitati tramite rientro, spaziatura aggiunta o elenchi puntati/numerati. Il contenuto può essere assegnato solo a un singolo paragrafo. Specifici paragrafi possono anche essere associati a un ruolo funzionale nel documento. I ruoli attualmente supportati includono intestazione di pagina, piè di pagina, numero di pagina, titolo, intestazione di sezione e nota a piè di pagina.

Pagina
Una pagina è un raggruppamento di contenuto che in genere corrisponde a un lato di un foglio di carta. Una pagina sottoposta a rendering è caratterizzata dalla larghezza e dall'altezza nell'unità specificata. In generale, le immagini usano i pixel mentre i PDF usano i pollici. La proprietà angle descrive l'angolo di testo complessivo in gradi per le pagine che possono essere ruotate.
Nota
Per fogli di calcolo come Excel, ogni foglio viene mappato a una pagina. Per le presentazioni, ad esempio PowerPoint, ogni diapositiva viene mappata a una pagina. Per i formati di file senza un concetto nativo di pagine senza rendering, come i documenti HTML o Word, il contenuto principale del file viene considerato una singola pagina.
Tabella
Una tabella organizza il contenuto in un gruppo di celle in un layout a griglia. Le righe e le colonne possono essere separate visivamente da linee griglia, fasce di colori o spaziatura maggiore. La posizione di una cella di tabella viene specificata tramite i relativi indici di riga e colonna. Una cella può estendersi su più righe e colonne.
In base alla posizione e allo stile, una cella può essere classificata come contenuto generale, intestazione di riga, intestazione di colonna, intestazione di colonna all'estrema sinistra o descrizione:
Una cella di intestazione di riga è in genere la prima cella di una riga che descrive le altre celle.
Una cella di intestazione di riga è in genere la prima cella di una colonna che descrive le altre celle.
Una riga o una colonna può contenere più celle di intestazione per descrivere contenuto gerarchico.
Una cella di intestazione di colonna all'estrema sinistra è in genere la cella nella prima posizione di riga e di colonna. Può essere vuota o descrivere i valori nelle celle di intestazione nella stessa riga/colonna.
Una cella di descrizione viene in genere visualizzata nell'area superiore o inferiore di una tabella e ne descrive il contenuto generale. Tuttavia, a volte può apparire al centro di una tabella per suddividere la tabella in sezioni. In genere, le celle di descrizione si estendono su più celle in una singola riga.
Una didascalia di tabella specifica il contenuto che illustra la tabella. Una tabella può inoltre avere una didascalia associata e un set di note a piè di pagina. A differenza di una cella di descrizione, una didascalia si trova in genere all'esterno del layout della griglia. Una tabella nota a piè di pagina annota il contenuto all'interno della tabella, spesso contrassegnato con un simbolo di nota a piè di pagina spesso presente sotto la griglia della tabella.
Le tabelle layout differiscono dai campi del documento estratti dai dati tabulari. Le tabelle layout vengono estratte dal contenuto visivo tabulare nel documento senza considerare la semantica del contenuto. Infatti, alcune tabelle layout sono progettate esclusivamente per il layout visivo e non sempre contengono dati strutturati. Il metodo per estrarre dati strutturati da documenti con layout visivo diversificato, ad esempio i dettagli di una ricevuta, richiede in genere una post-elaborazione significativa. È essenziale eseguire il mapping delle intestazioni di riga o di colonna a campi strutturati con nomi di campo normalizzati. A seconda del tipo di documento, usare modelli predefiniti o eseguire il training di un modello personalizzato per estrarre tale contenuto strutturato. Le informazioni risultanti vengono esposte come campi di documento. Tali modelli sottoposti a training possono anche gestire dati tabulari senza intestazioni e dati strutturati in forme non tabulari, ad esempio la sezione di un curriculum sull'esperienza lavorativa.
Nota
A partire da 2024-07-31-preview, le aree di delimitazione per figure e tabelle coprono solo il contenuto principale ed escludono sottotitoli e note a piè di pagina associati.

Figure
Le figure (grafici, immagini) nei documenti svolgono un ruolo fondamentale nell'integrare e migliorare il contenuto testuale, fornendo rappresentazioni visive che facilitano la comprensione di informazioni complesse. L'oggetto figure rilevato dal modello Layout ha proprietà chiave come boundingRegions (le posizioni spaziali della figura nelle pagine del documento, inclusi il numero di pagina e le coordinate poligono che delineano il limite della figura), spans (dettaglia gli intervalli di testo correlati alla figura, specificando gli offset e le lunghezze all'interno del testo del documento. Questa connessione consente di associare la figura al relativo contesto testuale pertinente), elements (identificatori per elementi di testo o paragrafi all'interno del documento correlati o descrivere la figura) e caption se presente.
Quando output=figure viene specificato durante l'operazione di Analyze iniziale, il servizio genera immagini ritagliate per tutte le figure rilevate a cui è possibile accedere tramite /analyeResults/{resultId}/figures/{figureId}.
FigureId è incluso in ogni oggetto figura, seguendo una convenzione non documentata di {pageNumber}.{figureIndex} in cui figureIndex reimposta su una per pagina.
{
"figures": [
{
"id": "{figureId}",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Sezioni
L'analisi gerarchica della struttura dei documenti è fondamentale per organizzare, comprendere ed elaborare documenti estesi. Questo approccio è fondamentale per segmentare semanticamente i documenti lunghi per migliorare la comprensione, facilitare la navigazione e migliorare il recupero delle informazioni. L'avvento della Retrieval Augmented Generation (RAG) in un documento di IA generativa sottolinea il significato dell'analisi gerarchica della struttura dei documenti. Il modello Layout supporta sezioni e sottosezioni nell'output, che identifica la relazione di sezioni e oggetti all'interno di ogni sezione. La struttura gerarchica viene mantenuta in elements di ogni sezione.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Campo modulo (coppia chiave-valore)
Un campo modulo è costituito da un'etichetta di campo (chiave) e un valore. L'etichetta di campo è in genere una stringa di testo che descrive il significato del campo. Spesso compare a sinistra del valore, anche se può trovarsi anche sopra o sotto il valore. Il valore di campo contiene il valore del contenuto di un'istanza di campo specifica. Il valore può essere costituito da parole, segni di selezione e altri elementi di contenuto. Può anche essere vuoto per i campi modulo non compilati. Un tipo speciale di campo modulo ha un valore di segno di selezione con l'etichetta di campo a destra. Il campo di documento è un concetto simile ma distinto rispetto ai campi modulo generali. L'etichetta di campo (chiave) in un campo modulo generale deve essere visualizzata nel documento. Pertanto, in genere non può acquisire informazioni come il nome del commerciante in una ricevuta. I campi del documento vengono etichettati e non estraggono una chiave. I campi documento eseguono il mapping di un valore estratto solo a una chiave etichettata. Per altre informazioni, vedere i campi del documento.

Elementi di stile
Style
Un elemento di stile descrive lo stile del carattere da applicare al contenuto di testo. Il contenuto viene specificato tramite intervalli nella proprietà di contenuto globale. Attualmente, l'unico stile del carattere rilevato è se il testo è scritto a mano. Man mano che vengono aggiunti altri stili, il testo può essere descritto tramite più oggetti di stile non in conflitto. Per compattezza, tutto il testo che condivide lo stile di carattere specifico (con la stessa attendibilità) viene descritto tramite un singolo oggetto di stile.
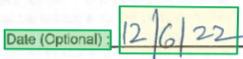
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
Lingua
Un elemento di lingua descrive la lingua rilevata per il contenuto specificato tramite intervalli nella proprietà di contenuto globale. La lingua rilevata viene specificata tramite un tag di lingua BCP-47 per indicare la lingua primaria e informazioni facoltative su scrittura e area geografica. Ad esempio, l'inglese e il cinese tradizionale vengono riconosciuti rispettivamente come "en" e zh-Hant. Le differenze di ortografia regionali per l'inglese regno unito possono causare il rilevamento del testo come en-GB. Gli elementi di lingua non riguardano il testo senza una lingua dominante (ad esempio numeri).
Elementi semantici
Nota
Gli elementi semantici descritti di seguito si applicano ai modelli predefiniti di Document Intelligence. I modelli personalizzati possono restituire rappresentazioni di dati diverse. Ad esempio, la data e l'ora restituite da un modello personalizzato possono essere rappresentate in un modello diverso dalla formattazione ISO 8601 standard.
Documento
Un documento è un'unità semanticamente completa. Un file può contenere più documenti, ad esempio più moduli fiscali all'interno di un file PDF o più ricevute all'interno di una singola pagina. Tuttavia, l'ordinamento dei documenti all'interno del file non influisce fondamentalmente sulle informazioni che comunica.
Nota
Attualmente, Document Intelligence non supporta più documenti in una singola pagina.
Il tipo di documento descrive i documenti che condividono un set comune di campi semantici, rappresentati da uno schema strutturato, indipendentemente dal relativo modello o layout visivo. Ad esempio, tutti i documenti di tipo "ricevuta" possono contenere il nome del commerciante, la data della transazione e il totale delle transazioni, anche se le ricevute di ristoranti e hotel spesso hanno un aspetto diverso.
Un elemento di documento include l'elenco dei campi riconosciuti tra i campi specificati dallo schema semantico del tipo di documento rilevato:
Un campo di documento può essere estratto o dedotto. I campi estratti vengono rappresentati tramite il contenuto estratto e, facoltativamente, il relativo valore normalizzato, se interpretabile.
Un campo dedotto non dispone della proprietà content e viene rappresentato solo tramite il relativo valore.
Un campo matrice non include una proprietà di contenuto. Il contenuto può essere concatenato dal contenuto degli elementi della matrice.
Un campo di oggetti contengono una proprietà di contenuto che specifica il contenuto completo che rappresenta l'oggetto, che può essere un superset dei campi secondari estratti.
Lo schema semantico di un tipo di documento viene descritto tramite i campi che contiene. Ogni schema di campo viene specificato tramite il relativo nome canonico e il tipo di valore. I tipi di valori di campo includono tipi di base (ad esempio stringa), composti (ad esempio indirizzo) e strutturati (ad esempio matrice, oggetto). Il tipo di valore di campo specifica anche la normalizzazione semantica eseguita per convertire il contenuto rilevato in una rappresentazione di normalizzazione. La normalizzazione può dipendere dalle impostazioni locali.
Tipi di base
| Tipo di valore di campo | Descrizione | Rappresentazione normalizzata | Esempio (contenuto del campo -> valore) |
|---|---|---|---|
| string | Testo normale | Uguale al contenuto | MerchantName: "Contoso" → "Contoso" |
| data | Data | ISO 8601 - AAAA-MM-GG | InvoiceDate: "5/7/2022" → "2022-05-07" |
| Ora | Ora | ISO 8601 - hh:mm:ss | TransactionTime: "9:45 PM" → "21:45:00" |
| phoneNumber | Numero di telefono | E.164 - +{CountryCode}{SubscriberNumber} | WorkPhone: "(800) 555-7676" → "+18005557676" |
| countryRegion | Paese/area geografica | ISO 3166-1 alpha-3 | CountryRegion: "Stati Uniti" → "USA" |
| selectionMark | È selezionato | "con firma" o "senza firma" | AcceptEula: ☑ → "selezionato" |
| firma | Con firma | Uguale al contenuto | LendeeSignature: {firma} → "con firma" |
| Numero | Numero a virgola mobile | Numero a virgola mobile | Quantità: "1.20" → 1.2 |
| integer | Numero intero | Numero con segno a 64 bit | Conteggio: "123" → 123 |
| boolean | Valore booleano | true/false | IsStatutoryEmployee |
Tipi composti
Valuta: importo in valuta con unità di valuta facoltativa. Un valore, ad esempio
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }Indirizzo: indirizzo analizzato. Ad esempio:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
Tipi strutturati
Matrice: elenco di campi dello stesso tipo
"Items": { "type": "array", "valueArray": [ ] }Oggetto: elenco denominato di sottocampi di tipi potenzialmente diversi
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
Passaggi successivi
Provare a elaborare moduli e documenti personalizzati con Document Intelligence Studio.
Completare un Guida introduttiva a Document Intelligence e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.